PyTorch深度学习(26)网络结构Swin-Transformer
Swin Transformer:Hierarchical Vision Transformer using Shifted Windows
ICCV 2021
论文地址:0
源码地址:https://gitbub.com/microsoft/Swin-Transformer
网络整体框架
Swin-Transformer feature map具有层次性,类似CNN中构建层次图 应用于segmentation、detection

PatchPartition


×2是因为需要堆叠两个结构,其中不同点在W-MSA和SW-MSA

Patch Merging
用于下采样;相同位置像素取出,深度(channel)方向进行拼接concat,channel方向进行LayerNorm处理,通过Linear对每个深度方向进行线性映射
相比输入图像,高和宽缩小为原来的一半,深度channel变为2倍

W-MSA详解
multi-head Self-Attention
每个像素都会与所有像素进行信息沟通
Window Multi-head self-attention
将特征图分为不同窗口,对每个window继续multi-head self-attention,window之间没有通信
目的:减少计算量;缺点:窗口之间无法进行信息交互(感受野变小,对预测结果有影响)
MSA模块计算量
![]()
公式推导:
![]()
MSA模块中,每个像素(token,patch),都要通过Wq,Wk,Wv生成对应的query(q),key(k),value(v)。假设q,k,v的向量长度与feature map的深度C保持一致,对应所有像素生成Q的过程如下式:
![]()
![]() 所有像素(token)拼接在一起得到的矩阵(一共hw个像素,每个像素深度为C)
所有像素(token)拼接在一起得到的矩阵(一共hw个像素,每个像素深度为C)
![]() 生成query的变换矩阵
生成query的变换矩阵
![]() 所有像素通过
所有像素通过![]() 得到的query拼接后的矩阵
得到的query拼接后的矩阵
根据矩阵运算的计算量公式得到生成Q的计算量为hw×C×C,生成k、v同理,总共3hwC×C
Q和K转置相乘,对应计算量为![]() :
:
![]()
忽略÷![]() 及softmax计算量,得到
及softmax计算量,得到![]() ,乘以V,对应计算量为
,乘以V,对应计算量为![]() :
:
![]()
对应单头Self-attention模块,总共
![]()
多头注意力模块仅比单头注意力模块的计算量多最后一个融合矩阵Wo的计算量![]()
![]()
总共加起来为:![]()
W-MSA模块计算量
![]()
其中:
- h——feature map的高度
- w——feature map的宽度
- C——feature map的深度
- M——每个窗口(Windows)的大小
首先将feature map划分为一个个窗口(windows),假设每个窗口宽高为M,总共有![]() 个窗口,对每个窗口使用多头注意力机制模块,计算高为H,宽为W,深度为C的feature map的计算量为
个窗口,对每个窗口使用多头注意力机制模块,计算高为H,宽为W,深度为C的feature map的计算量为![]() ,每个窗口高和宽为M:
,每个窗口高和宽为M:
![]()
又因为有![]() 个窗口,则:
个窗口,则:
![]()
SW-MSA详解 shift window Multi-head self attention
目的:实现不同window之间信息交互
融合不同window之间的信息
问题:计算量增加了,所以需要对划分区域进行如下操作:
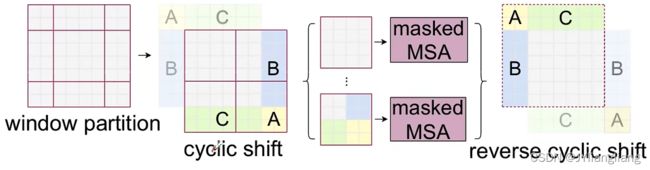
将ABC三个部分移动,形成cycllc shift,左上角4×4不动,其他部分进行合并也形成4×4
新的问题:不是相邻的两个区域,合并计算会有问题
不相邻区域分开计算,因此论文中提出masked MSA,加上蒙版
例如:像素0,与每个像素对于经过![]() 后,得到
后,得到![]()
不是相邻区域的像素点2、3,进行操作![]()
softmax得到对应![]() ,即不相邻区域像素全为0
,即不相邻区域像素全为0
最后进行加权求和操作
使用shift windows multi-head attention,效果提升明显,即窗体之间的信息交互是非常重要的
注意:全部计算完后需要将数据挪回原来的位置
Relative Position Bias详解 相对位置偏移
![]()
- 当使用abs.pos. 绝对的位置编码,效果下降
- rel.pos. 相对位置偏置,效果提升
对于特征图匹配后的相对位置索引,在行向量上进行展平
| 蓝色 | 橙色 |
| 红色 | 绿色 |
蓝色q和所有k匹配时相对位置索引
| 蓝色(0, 0) | (0, -1) |
| (-1, 0) | (-1,-1) |
橙色q和所有k匹配时相对位置索引
| (0, 1) | 橙色(0, 0) |
| (-1, 1) | (-1,0) |
红色q和所有k匹配时相对位置索引
| (1, 0) | (1, -1) |
| 红色(0, 0) | (0,-1) |
绿色q和所有k匹配时相对位置索引
| (1, 1) | (1, 0) |
| (0, 1) | 绿色(0,0) |
| (0, 0) | (0, -1) | (-1, 0) | (-1, -1) |
| (0, 1) | (0, 0) | (-1, 1) | (-1, 0) |
| (1, 0) | (1, -1) | (0, 0) | (0, -1) |
| (1, 1) | (1, 0) | (0, 1) | (0, 0) |
将二元坐标转化为一元坐标的过程:偏移从0开始,行列标加上M-1,行标乘上2M-1,行列标相加
最终得到:relative position index
| 4 | 3 | 1 | 0 |
| 5 | 4 | 2 | 1 |
| 7 | 6 | 4 | 3 |
| 8 | 7 | 5 | 4 |
对应relative position bias table 元素个数为(2M-1)×(2M-1)
| 0.1 | 0.2 | 0.3 | 0.8 | 0.1 | 0.6 | 0.4 | 0.4 | 0.7 |
模型详细配置参数

Drop Path
将深度学习模型中的多分支结构随机“删除”
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
# keep_prob 保留比例 drop_prob随机删除比例
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output