CVPR21目标检测新框架:不再是YOLO,而是只需要一层特征(干货满满,建议收藏)...
计算机视觉研究院专栏
作者:Edison_G
今天分享的内容,在其他各平台估计都有陆续分享,今天我们“计算机视觉研究院”从我们自己的角度来分析下YOLOF框架,看看他值不值得被CVPR2021录取。
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2103.09460.pdf
1
前言

自毕业以来,也接触了各种各样的目标检测框架。从刚开始见证TensorFlow崛起到Pytorch占有人工智能半壁江山,到现在的MMDetection、OneFlow、MindSpore等自主学习框架,也证明了中国的人工智能技术在不断飞速发展!

目标检测框架中,最为熟悉的应该是YOLO系列,从2018年Yolov3年提出的两年后,在原作者声名放弃更新Yolo算法后,俄罗斯的Alexey大神扛起了Yolov4的大旗,然后不久又出现了Yolov5。
当然,在公司中实际做项目的时候,很多应用场景中的第一步,都是进行目标检测任务,比如人脸识别、多目标追踪、REID等场景。因此目标检测是计算机视觉领域及应用中非常重要的一部分。
2
背景及YoloF的引出
先给大家提供下前期yolo的地址:
YoloV1论文地址:https://arxiv.org/pdf/1506.02640.pdf
YoloV2(Yolo9000)论文地址:https://arxiv.org/pdf/1612.08242.pdf
Yolov3论文地址:https://arxiv.org/pdf/1804.02767.pdf
Tiny YOLOv3代码地址:https://github.com/yjh0410/yolov2-yolov3_PyTorch
Yolov4论文地址:https://arxiv.org/pdf/2004.10934.pdf
Yolov5代码地址:https://github.com/ultralytics/yolov5
YOLObile论文地址:https://arxiv.org/pdf/2009.05697.pdf
YoloF的模型比之前的模型复杂了不少,可以通过改变模型结构的大小来权衡速度与精度。YoloV3的先验检测系统将分类器或定位器重新用于执行检测任务。他们将模型应用于图像的多个位置和尺度。此外,相对于其它目标检测方法,YoloV3将一个单神经网络应用于整张图像,该网络将图像划分为不同的区域,因而预测每一块区域的边界框和概率,这些边界框会通过预测的概率加权。模型相比于基于分类器的系统有一些优势。它在测试时会查看整个图像,所以它的预测利用了图像中的全局信息。与需要数千张单一目标图像的R-CNN不同,它通过单一网络评估进行预测。这令YoloV3非常快,一般它比R-CNN快1000倍、比Fast R-CNN快100倍。
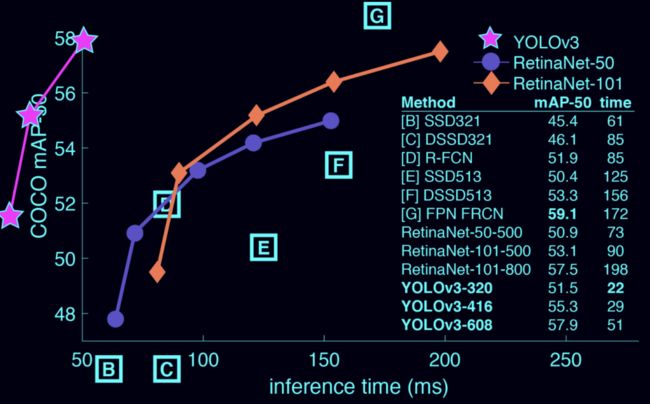
而今天分享的YOLOF框架,主要对单阶段目标检测中的FPN进行了重思考并指出FPN的成功之处在于它对目标检测优化问题的分而治之解决思路而非多尺度特征融合。从优化的角度出发,作者引入了另一种方式替换复杂的特征金字塔来解决该优化问题:从而可以仅仅采用一级特征进行检测。
3
新框架详解
在目前先进的目标检测框架网络中,出现频率最多的还是特征金字塔网络(Feature Pyramid Network,FPN),是一个不可或缺的组成部分。

研究者认为FPN主要有2个作用:
多尺度特征融合,提高特征丰富程度;
使用divide-and-conquer,将目标检测任务按照目标尺寸大小,分成若干个检测子任务。
为了探索FPN的上述2个作用对检测器性能的贡献程度,研究者做了实验,将检测器抽象成如下图所示个3个组成部分。

上图,Encoder主要处理Backbone提取的特征,将处理结果传输给Decoder,用于分类和回归。
以RetinaNet-ResNet50为基线方案,将检测任务分解为三个关键部分:主干网络、Encoder及Decoder。下图给出了不同部分的Flops对比:
相比SiMoEncoder,MiMoEncoder带来显著的内存负载问题(134G vs 6G);
基于MiMoEncoder的检测器推理速度明显要慢于SiSoEncoder检测器(13FPS vs 34FPS);
这个推理速度的变慢主要是因为高分辨率特征部分的目标检测导致,即C3特征部分。

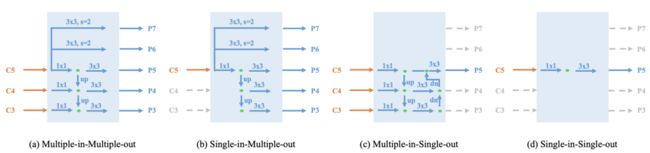
通过上述实验,可知使用Backbone输出的单一特征和分治法,就可以构建一个良好的目标检测框架网络。但是使用Single-in-Multiple-out的结构会使得模型变得更大和复杂,因为Encoder要输出多个特征。
基于上述发现,研究者提出了YOLOF(You Only Look One-level Feature)网络,在YOLOF中,Encoder只用到了Backbone输出的C5特征,同时避免使用Single-in-Multiple-out的SiMo复杂结构,而是使用了Single-in-Single-out的SiSo结构以减少计算量。
YOLOF框架草图如下所示:

YOLOF框架中关键的组件主要是膨胀编码器(Dilated Encoder)和均匀匹配(Uniform Matching),给整个检测带来了可观的改进。下面详细说说:
Dilated Encoder
关键组件1
使用Dilated Encoder模块代替FPN 。SiSo Encoder只使用了Backbone中的C5特征作为输入,C5特征感受野仅仅覆盖有限的尺度范围,当目标尺度与感受野尺度不匹配时就导致了检测性能的下降。为使得SiSo Encoder可以检测所有目标,作者需要寻找一种方案生成具有可变感受野的输出特征,以补偿多级特征的缺失。

在C5特征的基础上,研究者采用空洞卷积方式提升其感受野。尽管其覆盖的尺度范围可以在一定程度上扩大,但它仍无法覆盖所有的目标尺度。以上图(b)为例,相比图(a),它的感受野尺度朝着更大尺度进行了整体的偏移。然后,研究者对原始尺度范围与扩大后尺度范围通过相加方式进行组合,因此得到了覆盖范围更广的输出特征????,见上图(c)。
Dilated Encoder的结构如下图所示:

Uniform Matching
关键组件2
一般anchor和目标的GT的最大IoU超过0.5,则该anchor为positive anchor,positive anchor的定义对于目标检测中的优化问题尤其重要。在anchor-based的检测中,positive anchor的定义策略主要受anchor与真实框之间的IoU决定,研究者称之为Max-IoU matching。
在MiMo Encoder中,anchor在多级特征上以稠密方式进行预定义,同时按照尺度生成特征级的positive anchor。在分而治之的机制下,Max-IoU matching使得每个尺度下的真实框可以生成充分数量的positive anchor。然而,当研究者采用SiSo Encoder时,anchor的数量会大量的减少(比如从100K减少到5K),导致了稀疏anchor。稀疏anchor进一步导致了采用Max-IoU matching时的不匹配问题。
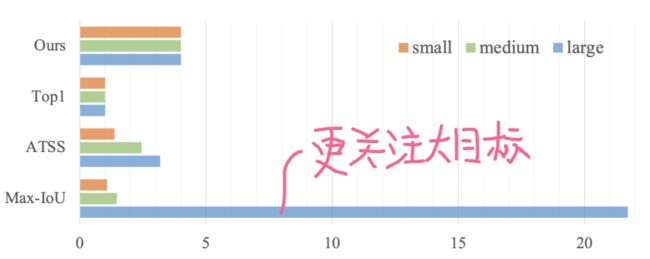
以上图为例,大的目标框包含更多的positive anchor,这就导致了positive anchor的不平衡问题,进而导致了检测器更多关注于大目标而忽视了小目标。
为解决上述positive anchor不平衡问题,研究者就提出了Uniform Matching策略:对于每个目标框采用k近邻anchor作为positive anchor,确保了所有的目标框能够以相同数量的positive anchor进行均匀匹配。positive anchor的平衡确保了所有的目标框都参与了训练且贡献相等。在实现方面,参考了Max-IoU matching,演技组对Uniform matching中的IoU阈值进行设置以忽略大IoU (>0.7)的negative anchor和小IoU (<0.15) positive anchor。
4
实验及可视化

上表给出了新框架与RetineNet在COCO数据集上的性能对比。从中可以看到:
YOLOF取得了与改进版RetinaNet+相当的性能,同时减少了57%的计算量,推理速度快了2.5倍;
当采用相同主干网络时,由于仅仅采用C5特征,YOLOF在小目标检测方面要比RetinaNet+弱一些(低3.1),但在大目标检测方面更优(高3.3);
当YOLOF采用ResNeXt作为主干网络时,它可以取得与RetinaNet在小目标检测方面相当的性能且推理速度同样相当;
多尺度测试辅助,新框架取得了47.1mAP的指标,且在小目标方面取得了极具竞争力的性能31.8mAP。
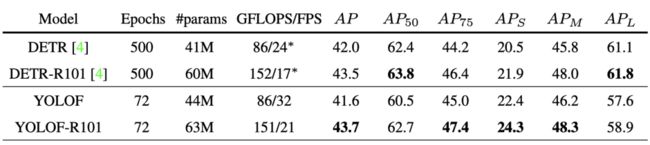
上表展示了新框架与DETR的性能对比。从中可以看到:
YOLOF取得了与DETR相匹配的的性能;
相比DETR,YOLOF可以从更深的网络中收益更多,比如ResNet50时低0.4,在ResNet10时多了0.2;
在小目标检测方面,YOLOF要优于DETR;
在收敛方面,YOLOF要比DETR快7倍,这使得YOLOF更适合于作为单级特征检测器的基线。
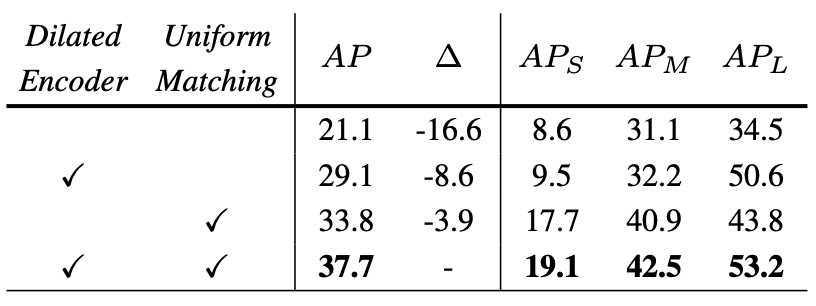
上表展示了,使用 ResNet-50 使用Dilated Encoder和Uniform Matching的效果。这两个组件将原始单级检测器提高了 16.6 mAP。请注意,上表中 21.1 mAP 的结果不是错误。由于YOLOF中解码器的设计,它的性能略低于带有SiSo编码器的检测器,其分类头中只有两个卷积层。
© THE END
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
????
计算机视觉研究院活动:七夕粉丝回馈,Pytorch书籍免费送
深度学习模型部署:落实产品部署前至关重要的一件事!
Yolo利息的王者:高效且更精确的目标检测框架(附源代码)
腾讯优图出品:P2P网络的人群检测与计数
利用TRansformer进行端到端的目标检测及跟踪(附源代码)
细粒度特征提取和定位用于目标检测(附论文下载)
特别小的目标检测识别(附论文下载)
目标检测 | 基于统计自适应线性回归的目标尺寸预测