「干货」常用深度学习图像/视频标注工具及数据集资料汇总
“大数据时代”,数据为王!无论是数据挖掘还是目前大热的深度学习领域都离不开“大数据”。
对于监督学习算法而言,数据决定了任务的上限,而算法只是在不断逼近这个上限。世界上最遥远的距离就是我们用同一个模型,但是却有不同的任务。但是数据标注是个耗时耗力的工作。
在深度学习领域,培训数据对培训结果具有重要影响。在计算机视觉领域,除了开放数据集之外,许多应用场景还需要专门的数据集来进行迁移学习或端到端培训。这种情况需要大量的训练数据,并采集这些数据,方法有如下几种:
- 人工数据标注
- 自动数据标注
- 外包数据标注
手动数据标记的优点是标记结果相对可靠。自动数据标签通常需要进行二次审查以避免程序错误。外包数据标签通常面临数据泄漏和丢失的风险。手动数据注释工具,尤其是图像数据注释工具,可以根据其软件属性分为客户端和WEB端注释工具。建议您使用客户端注释工具或离线WEB端注释工具。在线WEB端注释工具面临数据丢失的风险。请仔细使用!
十大常用工具
1.LabelImg
主页地址:https://github.com/tzutalin/labelImg
下载以后根据作者提供的安装指南即可安装,如果安装不上怎么办,不用这么麻烦,下面这个地址提供了直接下载的地址,下载预编译exe即可:
https://github.com/zhaobai62/labelImg
支持VOC2012格式与tfrecord自动生成!
2.LabelImg
主页地址:https://github.com/wkentaro/labelme
支持对象检测、图像语义分割数据标注,实现语言为Python与QT。
支持导出VOC与COCO格式数据实例分割
强烈推荐,实例分割都可以用它标注!

3.RectLabel
https://rectlabel.com/
支持导出YOLO、KITTI、COCOJSON与CSV格式
读写Pascal VOC格式的XML文件
4.OpenCV/CVAT
官方主页:https://github.com/opencv/cvat
高效的计算机视觉注释工具,支持图像分类,对象检测框,图像语义分割,案例分割数据标注在线注释工具。支持图像和视频数据注释,最重要的是支持本地部署,无需担心数据泄露!

5.VOTT
官方主页:https://github.com/microsoft/VoTT
Microsoft发布了一个基于WEB的可视化数据注释工具,用于本地部署。
支持图像和视频数据注释
支持CNTK / Pascal VOC格式的出口
支持导出TFRecord,CSV,VoTT格式
目前,主要分支版本是V1和V2版本。
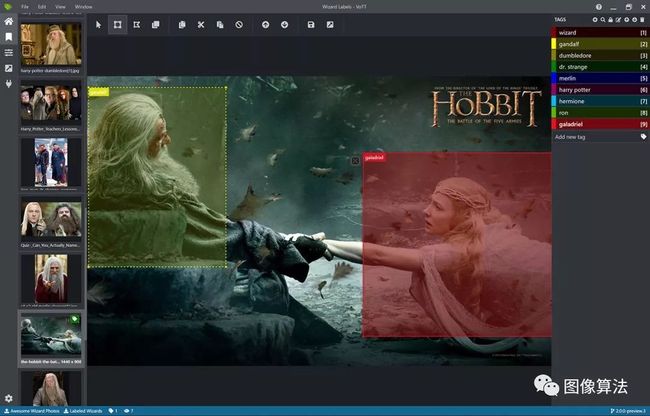
6.LableBox
官方主页:https://github.com/Labelbox/Labelbox
WEB模式下的标记工具
提供自定义注释API支持
纯JS + HTML支持
7.VIA-VGG Image Annotator
http://www.robots.ox.ac.uk/~vgg/software/via/
VGG发布的图像标准工具
基于WEB方式的标注工具

8.PixelAnnotationTool
开源主页:https://github.com/abreheret/PixelAnnotationTool
图像语义分割和实例分割是标记的工件。交互式标记算法的思想是基于OpenCV中的分水岭算法。支持,可以直接下载编译后的二进制文件,下载地址如下:
https://github.com/abreheret/PixelAnnotationTool/releases

9.point-cloud-annotation-tool
官方地址:https://github.com/springzfx/point-cloud-annotation-tool
3D点云数据注释工件
支持3D BOX盒子生成
支持KITTI-bin格式数据

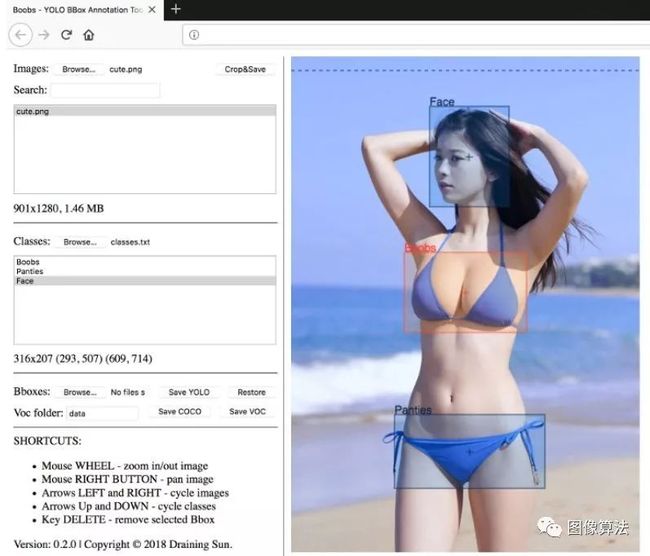
10.Boobs
https://github.com/drainingsun/boobs
独有的YOLO BBox注释工具支持YOLO格式的图像数据标准
还支持VOC / COCO格式的数据导出
基于WEB模式的注释工具
支持下载用于本地部署的zip包
没有服务器端支持,直接浏览器支持可以通过打开胸部来启动数据注释。
MNIST

深度学习领域的“Hello World!”,入门必备!MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集,每个样本图像的宽高为28*28。此数据集是以二进制存储的,不能直接以图像格式查看,不过很容易找到将其转换成图像格式的工具。
最早的深度卷积网络LeNet便是针对此数据集的,当前主流深度学习框架几乎无一例外将MNIST数据集的处理作为介绍及入门第一教程,其中Tensorflow关于MNIST的教程非常详细。
数据集大小:~12MB
下载地址:
http://yann.lecun.com/exdb/mnist/index.html
Imagenet

MNIST将初学者领进了深度学习领域,而Imagenet数据集对深度学习的浪潮起了巨大的推动作用。深度学习领域大牛Hinton在2012年发表的论文《ImageNet Classification with Deep Convolutional Neural Networks》在计算机视觉领域带来了一场“革命”,此论文的工作正是基于Imagenet数据集。
Imagenet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
1)Total number of non-empty synsets: 21841
2)Total number of images: 14,197,122
3)Number of images with bounding box annotations: 1,034,908
4)Number of synsets with SIFT features: 1000
5)Number of images with SIFT features: 1.2 million
Imagenet数据集是目前深度学习图像领域应用得非常多的一个领域,关于图像分类、定位、检测等研究工作大多基于此数据集展开。Imagenet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。
与Imagenet数据集对应的有一个享誉全球的“ImageNet国际计算机视觉挑战赛(ILSVRC)”,以往一般是google、MSRA等大公司夺得冠军,今年(2016)ILSVRC2016中国团队包揽全部项目的冠军。
Imagenet数据集是一个非常优秀的数据集,但是标注难免会有错误,几乎每年都会对错误的数据进行修正或是删除,建议下载最新数据集并关注数据集更新。
数据集大小:~1TB(ILSVRC2016比赛全部数据)
下载地址:
http://www.image-net.org/about-stats
COCO

COCO(Common Objects in Context)是一个新的图像识别、分割和图像语义数据集,它有如下特点:
1)Object segmentation
2)Recognition in Context
3)Multiple objects per image
4)More than 300,000 images
5)More than 2 Million instances
6)80 object categories
7)5 captions per image
8)Keypoints on 100,000 people
COCO数据集由微软赞助,其对于图像的标注信息不仅有类别、位置信息,还有对图像的语义文本描述,COCO数据集的开源使得近两三年来图像分割语义理解取得了巨大的进展,也几乎成为了图像语义理解算法性能评价的“标准”数据集。
Google开源的开源了图说生成模型show and tell就是在此数据集上测试的,想玩的可以下下来试试哈。
数据集大小:~40GB
下载地址:http://mscoco.org/
PASCAL VOC

PASCAL VOC挑战赛是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。PASCAL VOC图片集包括20个目录:人类;动物(鸟、猫、牛、狗、马、羊);交通工具(飞机、自行车、船、公共汽车、小轿车、摩托车、火车);室内(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。PASCAL VOC挑战赛在2012年后便不再举办,但其数据集图像质量好,标注完备,非常适合用来测试算法性能。
数据集大小:~2GB
下载地址:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
CIFAR

CIFAR-10包含10个类别,50,000个训练图像,彩色图像大小:32x32,10,000个测试图像。CIFAR-100与CIFAR-10类似,包含100个类,每类有600张图片,其中500张用于训练,100张用于测试;这100个类分组成20个超类。图像类别均有明确标注。CIFAR对于图像分类算法测试来说是一个非常不错的中小规模数据集。
数据集大小:~170MB
下载地址:
http://www.cs.toronto.edu/~kriz/cifar.html
Open Image
![]()
过去几年机器学习的发展使得计算机视觉有了快速的进步,系统能够自动描述图片,对共享的图片创造自然语言回应。其中大部分的进展都可归因于 ImageNet 、COCO这样的数据集的公开使用。谷歌作为一家伟大的公司,自然也要做出些表示,于是乎就有了Open Image。
Open Image是一个包含~900万张图像URL的数据集,里面的图片通过标签注释被分为6000多类。该数据集中的标签要比ImageNet(1000类)包含更真实生活的实体存在,它足够让我们从头开始训练深度神经网络。
谷歌出品,必属精品!唯一不足的可能就是它只是提供图片URL,使用起来可能不如直接提供图片方便。
此数据集,笔者也未使用过,不过google出的东西质量应该还是有保障的。
数据集大小:~1.5GB(不包括图片)
下载地址:
https://github.com/openimages/dataset
Youtube-8M
![]()
Youtube-8M为谷歌开源的视频数据集,视频来自youtube,共计8百万个视频,总时长50万小时,4800类。为了保证标签视频数据库的稳定性和质量,谷歌只采用浏览量超过1000的公共视频资源。为了让受计算机资源所限的研究者和学生也可以用上这一数据库,谷歌对视频进行了预处理,并提取了帧级别的特征,提取的特征被压缩到可以放到一个硬盘中(小于1.5T)。
此数据集的下载提供下载脚本,由于国内网络的特殊原因,下载此数据经常断掉,不过还好下载脚本有续传功能,过一会儿重新连接就能再连上。可以写一个脚本检测到下载中断后就sleep一段时间然后再重新请求下载,这样就不用一直守着了。(截至发文,断断续续的下载,笔者表示还没下完呢……)
数据集大小:~1.5TB
下载地址:https://research.google.com/youtube8m/
如果以上数据集还不能满足你的需求的话,不妨从下面找找吧。
1.深度学习数据集收集网站
http://deeplearning.net/datasets/**
收集大量的各深度学习相关的数据集,但并不是所有开源的数据集都能在上面找到相关信息。
2、Tiny Images Dataset
http://horatio.cs.nyu.edu/mit/tiny/data/index.html
包含8000万的32x32图像,CIFAR-10和CIFAR-100便是从中挑选的。
3、CoPhIR
http://cophir.isti.cnr.it/whatis.html
雅虎发布的超大Flickr数据集,包含1亿多张图片。
4、MirFlickr1M
http://press.liacs.nl/mirflickr/Flickr数据集中挑选出的100万图像集。
5、SBU captioned photo dataset
http://dsl1.cewit.stonybrook.edu/~vicente/sbucaptions/Flickr的一个子集,包含100万的图像集。
6、NUS-WIDE
http://lms.comp.nus.edu.sg/research/NUS-WIDE.htmFlickr中的27万的图像集。
7、Large-Scale Image Annotation using Visual Synset(ICCV 2011)
http://cpl.cc.gatech.edu/projects/VisualSynset/机器标注的一个超大规模数据集,包含2亿图像。
8、SUN dataset
http://people.csail.mit.edu/jxiao/SUN/包含13万的图像的数据集。
9、MSRA-MM
http://research.microsoft.com/en-us/projects/msrammdata/ 包含100万的图像,23000视频;微软亚洲研究院出品,质量应该有保障。
关注微信公众号:“图像算法”或者微信搜索imalg_cn 可获取更多资源