图像分割论文学习小记录1——FastInst(CVPR23)
图像分割论文学习小记录1——FastInst(CVPR23)
目录
图像分割论文学习小记录1——FastInst(CVPR23)
学习前言:
什么是FastInst
研究背景与意义
研究意义
贡献
网络结构分析
Lightweight pixel decoder
Instance activation-guided queries
Ground truth mask-guided learning
Loss function
实验结果
参考链接:
学习前言:
Mask2former或Oneformer这类模型算法的推理速度都很难达到实时,这篇论文提出的方法据说可以达到实时的实例分割效果,一起来看看实现这种实时效果的网络结构的独特之处吧!

标题:FastInst: A Simple Query-Based Model for Real-Time Instance Segmentation
Paper: https://arxiv.org/pdf/2303.08594.pdf
Code: https://github.com/junjiehe96/FastInst
什么是FastInst
本文提出了 FastInst,一个简单、有效的基于 query 的实时实例分割框架, 展示了基于 query 的模型也能在高效实例分割算法设计方面的强大潜力。
FastInst 可以以实时速度( 32.5 FPS)运行,同时在 COCO test-dev 上产生超过 40 的 AP( 40.5 AP)。
它遵循最近提出的 Mask2Former 的 meta 架构。
关键设计包括 instance activation-guided queries、双路径更新策略和 ground truth mask-guided learning
实现了使用更轻的 pixel decoders 、更少的 Transformer 解码器层,同时获得更好的性能。
实验表明,FastInst 在速度和准确性方面优于大多数最先进的实时模型,包括强大的全卷积baselines。
研究背景与意义
Mask R-CNN 等主流方法遵循先检测而后分割的设计。但这些方法会生成大量重复的 region proposals,造成冗余,增加了计算成本。
为了提高其效率,出现了许多建立在全卷积网络 (FCN) 上的单阶段方法,不需要生成 region proposals,端到端地分割对象。
这种方法提高了推理速度,但是,密集的预测,导致传统的单阶段方法仍然依赖于手动设计的后处理步骤,如非极大值抑制 NMS。
随着 DETR 在目标检测方向的成功,基于 query 的单阶段实例分割方法应运而生。它不使用卷积,而是利用多功能且强大的注意力机制结合一系列可学习的 query 来推断目标类别和分割的 mask。例如,Mask2Former 通过在主干之上添加像素解码器和掩蔽注意力变换器解码器来简化实例分割的工作流程。与以前的方法不同,Mask2Former 不需要额外的手工设计部分,例如训练目标的分配和 NMS 后处理。
Mask2Former 也有其自身的问题:
- (1)它需要大量的解码器层来解码目标的 query ,因为它的 query 是静态学习的,需要一个漫长的过程来进行更新;
- (2) 它依赖于一个重像素解码器,例如多尺度可变形注意力转换器 ( MSDeformAttn ),因为它的目标分割掩码直接取决于像素解码器的输出,将其用作区分不同对象的逐像素 embedding 特征;
- (3) masked attention限制了每个 query 的感受野,可能导致Transformer decoder陷入次优的query更新过程。
Mask2Former 取得了性能出色,但其在快速、高效实例分割方面的优势还没有得到很好的验证,这对于许多现实世界的应用程序(例如自动驾驶汽车和机器人技术)来说至关重要。
研究意义
实际上,缺乏先验知识以及引入高计算复杂度的注意力机制,使得基于 query 的模型的效率普遍不尽如人意。因此,有效的实时实例分割基准仍然由基于卷积的模型作为主导。
本文提出 FastInst 来填补这一空白,FastInst 是一种简洁有效的基于 query 的实时实例分割框架。在单个 V100 GPU 上进行了评估,在 COCO test-dev 上以实时速度执行,即 32.5 FPS,同时产生超过 40 的 AP,即 40.5 AP。
贡献
模型遵循 Mask2Former 的 meta 架构,
本文为了实现高效的实时实例分割,提出了三个关键技术:
- 实例激活引导查询( instance activation-guided queries),
它从底层特征图中动态选择具有高语义的像素 embedding 作为 Transformer 解码器的初始 query。与静态可学习查询相比,这些选择的 query 包含丰富的潜在目标 embedding 信息,减少了 Transformer 解码器的迭代更新成本。
- 在 Transformer 解码器中采用双路径架构
其中 query 特征和像素特征交替进行更新。这样的设计增强了像素特征的表示能力,免于繁重的像素解码器设计。此外,它在 query 特征和像素特征之间进行了直接通信,从而加快了迭代更新收敛速度,并有效降低了对解码器层数的依赖。
- 引入了ground truth mask-guided learning
为了防止掩蔽注意力陷入次优查询更新过程,引入了ground truth mask-guided learning。随后用最后一层二分匹配 GT 真值掩码替换标准掩码注意力中使用的掩码,将其输入到 Transformer 解码器,并使用固定的匹配分配来监督输出。该引导策略允许每个 query 在训练期间查看其目标预测对象的整个区域,并帮助掩蔽注意力关注更合适的前景区域。

网络结构分析
FastInst整体框架结构如下图:
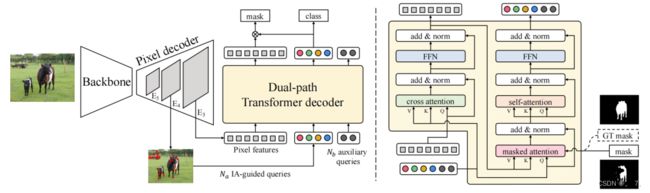
FastInst 由三个模块组成:backbone、pixel decoder 和 Transformer decoder。
Backbone 和 pixel decoder 用于提取和细化多尺度特征。
首先将输入图像 经过 backbone 得到三个特征图 、 和 ,它们的分辨率分别为输入图像的 1/8、1/16 和 1/32。再通过 1×1 卷积层将这三个特征映射投影到具有 256 个通道的特征映射,将它们输入到pixel decoder。

Lightweight pixel decoder
多尺度上下文特征图对于图像分割至关重要。但是,复杂的多尺度特征金字塔网络增加了计算代价。
与直接使用来自像素解码器的基础特征图的先前方法不同,本文使用 Transformer 解码器中的精细像素特征来生成分割掩码。这种设置降低了像素解码器对大量上下文聚合的要求。
为了在准确性和速度之间取得更好的权衡,这里使用一种称为 PPM-FPN 的变体而不是 vanilla FPN ,它在 之后采用金字塔池化模块来扩大感受野以提高性能。
Instance activation-guided queries
能够提高Transformer 解码器中查询迭代的效率。

Dual-path Transformer decoder
减少了对重像素解码器的依赖

Ground truth mask-guided learning
这种引导学习允许每个 query 在训练期间看到其目标预测对象的整个区域,有助于掩蔽注意力关注到更合适的前景区域。

Loss function

实验结果
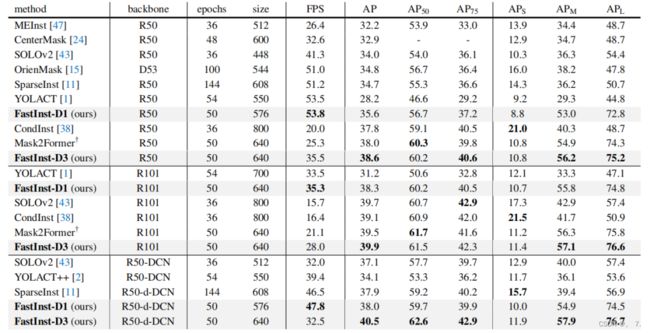
作者在 COCO 数据集上与其他方法进行了对比,在准确性和速度的权衡上达到了最优
参考链接:
实例分割新SOTA!FastInst:激发query的强大潜力(CVPR23)