AI 大模型
随着人工智能技术的迅猛发展,AI 大模型逐渐成为推动人工智能领域提升的关键因素,大模型已成为了引领技术浪潮研究和应用方向。大模型 即 大规模预训练模型,通常是指那些在大规模数据上进行了预训练的具有庞大规模和复杂结构的人工智能模型,它们具有数以亿计的参数和深层次的神经网络架构,被广泛称为大模型。这些模型通过学习海量数据和深度神经网络的优化,在各种任务上取得了令人瞩目的成果。
目录
- 一. 大模型简介
- 二. 大模型的训练
- 三. 大模型的发展历程
-
- 1. 多层感知机
- 2. 循环神经网络
- 3. 卷积神经网络
- 4. 长短时记忆网络
- 5. 深度学习复兴
- 6. Transformer 模型
- 7. 大模型兴起
- 四. 大模型的经典实例
-
- 1. OpenAI GPT 大模型组
- 2. Google PaLM 大模型组
- 3. 百度文心大模型组
- 4. 讯飞星火认知大模型
- 5. 阿里通义大模型
- 6. 清华开源大模型 ChatGLM
一. 大模型简介
大模型是指具有大量参数和计算资源的深度学习模型,通常包括数十亿甚至数百亿个参数,并且需要强大的硬件加速器(如图形处理单元或专用的 AI 芯片)来进行训练和推断。大模型使用大量的多媒体数据资源作为输入,并通过复杂的数学运算和优化算法来完成大规模的训练,以学习和理解到输入数据的模式和特征。这些模式和特征最终通过大模型中庞大的参数进行表征,以获得与输入数据和模型设计相匹配的能力,最终来实现更复杂、更广泛的任务,如语音识别、自然语言处理、计算机视觉等。
大模型的训练过程一般采用 预训练 + 微调 两阶段策略。在预训练阶段,模型通过大规模无标签数据进行学习,学习到一种通用表示。在微调阶段,模型使用有标签数据对模型进行细化训练,以适应具体的任务和领域。这种在大规模数据上进行预训练,再在具体任务上进行微调,能够让大模型适应不同的应用场景。
大模型的优点如下:
- 庞大数量的参数:大模型通常拥有数以亿计的参数,这些参数可以存储模型的知识和经验,更多的参数意味着模型具有更强大的学习能力和表示能力,能够更好地捕捉数据中的复杂模式和特征,以便进行推理和预测;
- 上下文理解和生成:大模型能够理解和生成更具上下文和语义的内容,通过 注意力机制、上下文编码器 等关键技术来学习和训练大量的语言、图像等输入数据,可以从复杂的真实场景中提取有用的信息;
- 强大的泛化能力:大模型通过在大规模数据上进行训练,具有强大的泛化能力。它们从大量的数据中学习到广泛的特征和模式,并且能够在未学习过、未见过的数据上也同样表现良好;
- 计算资源需求大:大模型需要强大的计算资源来进行参数优化和推理,这需要具备出色的并行计算能力的 GPU、TPU 处理器集群,这使得训练和使用这些模型成为一项具有挑战性的任务;
- 迁移学习能力强:大模型在一个或多个领域上进行预训练,并能够将学到的知识迁移到新任务或新领域中。这种迁移学习能力使得模型在新任务上的学习速度更快,同时也提高了模型在未知领域中的性能;
- 多领域应用:大模型应用领域广泛,可应用于多个领域,并解决多种任务,如自然语言处理、计算机视觉、语音识别等。大模型不仅在单一模态领域中有很强的表现,更能够进行跨模态的任务处理;
大模型具有诸多优点的同时也存在一些挑战和限制,如训练时间长、计算资源需求大、模型复杂度高、通用泛化能力受限等等。此外,由于其庞大的参数规模,大模型可能面临可解释性和隐私等方面的诸多挑战。
二. 大模型的训练
目前常用的深度学习框架,例如 Pytorch 和 Tensorflow,显然没有办法满足超大规模模型训练的需求。于是微软基于 Pytroch 开发了 DeepSpeed,腾讯基于 Pytroch 开发了派大星 PatricStar,达摩院同基于 Tensoflow 开发了分布式框架 Whale。像是华为昇腾的 MindSpore、百度的 PaddlePaddle,还有国内的追一科技 OneFlow 等厂商,对超大模型训练进行了深度的跟进与探索,基于原生的 AI 框架支持超大模型训练。1


三. 大模型的发展历程
AI 大模型的发展可以追溯到早期的人工神经网络和机器学习算法,但真正的突破始于 深度学习 的兴起和计算能力的提升。 AI 大模型的发展历程其实就是深度学习的发展过程,以下是AI大模型发展的一些重要里程碑2:
1. 多层感知机
多层感知机 (Multi-Layer Perceptron, MLP) 是 20 世纪 80 年代出现的最早的深度学习模型之一。这是一种基本的前馈神经网络模型,由多个神经网络层组成,每层包含多个神经元,每个神经元与前一层的所有神经元相连,逐层传递信息进行训练和推理,开始引入了多层结构和非线性激活函数,从而扩展了模型的表达能力。MLP 的工作原理是通过权重和偏置参数对输入数据进行线性组合和非线性激活,以学习和表示输入数据之间的复杂关系。通过反向传播算法,MLP 可以根据预定义的损失函数进行训练和优化,以使其输出尽可能地接近目标值。
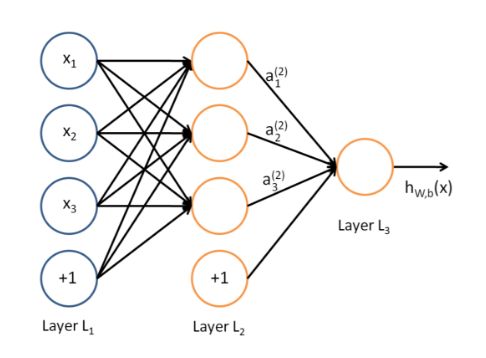
MLP 在机器学习和模式识别领域中被广泛应用,尤其是在分类和回归任务中。它的扩展和改进形式:卷积神经网络 (CNN) 和循环神经网络 (RNN),已经成为深度学习中的核心模型。
尽管 MLP 是深度学习的基础,但它在处理复杂的非线性问题和大规模数据时存在一些限制,随着深度学习的发展,MLP 逐渐被更强大和灵活的模型所取代。
2. 循环神经网络
循环神经网络 (Recurrent Neural Networks, RNN) 是在 1986 年由 Rumelhart 和 McClelland 提出的一种能够处理序列数据的神经网络模型,其基本概念是引入了循环连接,使得网络可以对先前的信息进行记忆和利用。该记忆机制允许信息在时间上进行传递,从而更好地捕捉序列中的上下文信息,能够从序列数据中获取上下文依赖关系。
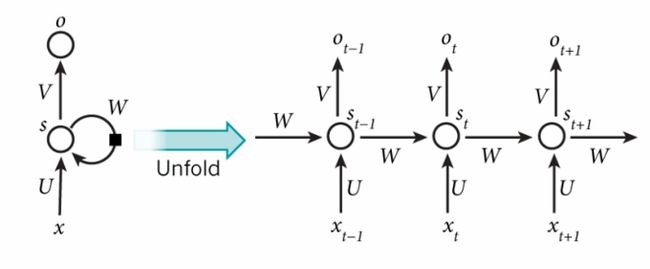
RNN 在网络中引入循环连接,使得网络的输出不仅依赖于当前输入,还依赖于之前的输入和隐藏状态。其关键组成部分是隐藏状态,它可以看作是网络对之前输入的记忆。隐藏状态在每个时间步都会被更新,并传递给下一个时间步。RNN 的循环连接使得网络可以对序列数据进行建模,能够捕捉序列中的时序信息和依赖关系。这使得RNN在自然语言处理、语音识别、机器翻译等任务中具有很好的表现。
然而,传统的 RNN 在处理长序列时存在梯度消失和梯度爆炸的问题,导致难以捕捉长距离的依赖关系。
3. 卷积神经网络
卷积神经网络 (Convolutional Neural Networks, CNN) 是在 1989 年由 Yann LeCun 等人提出的一种专门用于处理具有网格结构数据(如图像、语音和时间序列)的深度学习模型。卷积神经网络通过卷积和池化运算来有效提取图像特征,被广泛研究和应用于图像处理和计算机视觉任务中。
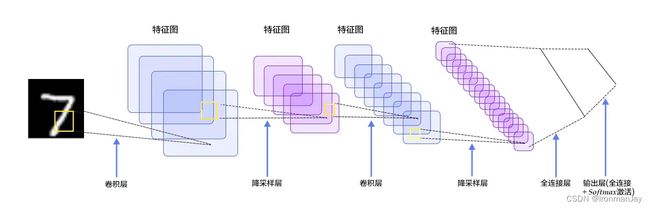
卷积神经网络设计灵感来自于生物视觉系统中的神经机制:它利用卷积操作和池化操作来有效地捕捉输入数据的局部特征,并通过多层堆叠的卷积层和全连接层进行特征提取和分类。CNN 的基本组件包括卷积层、激活函数、池化层和全连接层。卷积层使用一组可学习的滤波器对输入数据进行卷积操作,以提取空间特征;激活函数引入非线性变换,增强模型的表达能力;池化层通过减少特征图的尺寸和数量来降低计算复杂度,并保留重要的特征;全连接层将汇集的特征映射转化为模型的最终输出。
CNN 在计算机视觉领域中取得了巨大的成功,主要应用于图像分类、目标检测和图像分割等任务。它通过共享权重和局部连接的方式,减少了参数量,提高了模型的效率和泛化能力。
4. 长短时记忆网络
长短时记忆网络 (Long Short-Term Memory, LSTM) 是在 1997 年由 Hochreiter 和 Schmidhuber 提出的一种门控循环神经网络 (Gated Recurrent Neural Network, GRU) 的变体,用于解决传统 RNN 中的梯度消失和梯度爆炸问题,并能够更好地 捕捉长距离的依赖关系。LSTM 的基本概念是引入了引入了三个门控单元:遗忘门、输入门和输出门3,通过控制信息的流动和记忆的更新,有效地处理长序列数据。

LSTM 通过门控机制的引入,能够在时间上灵活地控制信息的流动和记忆的更新,从而更好地捕捉长距离的依赖关系。这使得 LSTM 在自然语言处理、语音识别、机器翻译等任务中取得了很好的表现。
5. 深度学习复兴
2012 年开始,随着计算能力的提升和大规模数据集的可用性,深度学习经历了一次复兴。人们开始使用更深、更复杂的神经网络结构,如深层卷积神经网络和长短期记忆网络 (Long Short-Term Memory),在图像识别、语音识别和自然语言处理等领域取得了突破性进展。主要表现如下:
- 2012 年,Hinton 等人提出的 AlexNet 在 ILSVRC 图像分类竞赛中大获成功,将错误率降低到以前方法的一半以上。AlexNet 采用了深度卷积神经网络,并引入了 ReLU 激活函数和 Dropout 正则化技术;
- 2014 年,Google 的研究团队提出的 GoogLeNet 在 ILSVRC 竞赛中获得胜利,引入了 Inception 模块,使得网络更加深层和宽广;
- 2015 年,DeepMind 的 AlphaGo 击败围棋世界冠军李世石,引起广泛关注。AlphaGo 使用了深度强化学习方法,结合了深度卷积神经网络和蒙特卡洛树搜索算法;
深度学习的复兴得益于数据的丰富和计算能力的提升,以及对深度神经网络结构和训练算法的改进。这些突破使得深度学习成为当今人工智能领域最为热门和有效的方法之一。
6. Transformer 模型
Transformer 模型4 是在 2017 年由 Vaswani 等人提出的一种新型的神经网络架构,它引入了自注意力机制,允许模型同时处理输入序列中的所有位置信息,而无需使用循环神经网络或卷积神经网络。这一架构的创新极大地改善了序列到序列任务的性能,为后续的自然语言处理模型奠定了基础。
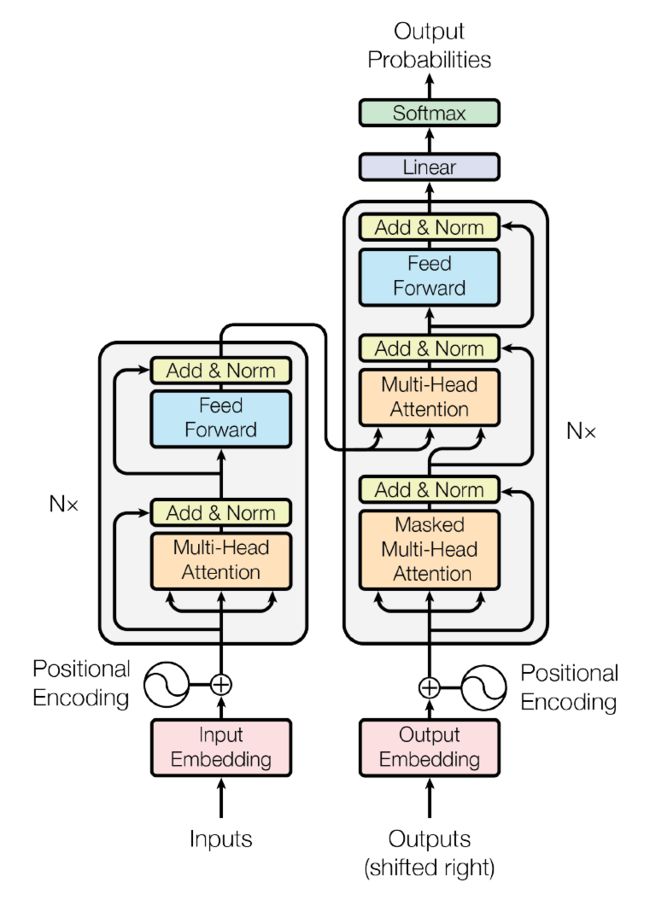
Transformer 模型是自然语言处理和机器学习领域的一个重大创新,改变了处理序列数据的方式,为各种自然语言处理任务提供了强大的工具,并推动了这些领域的快速发展。它的成功也激发了对更强大的模型和更高级的自然语言理解的不断探索。
7. 大模型兴起
Transformer 模型的成功启发了大规模预训练模型的兴起,如 BERT、GPT、XLNet 等。这些模型通过在海量文本数据上进行预训练,学习到了丰富的语言表示,为各种 NLP 任务提供了强大的基础。在不同任务上微调之后,这些模型在自然语言处理等领域取得了突破性的成果。
随着硬件和计算能力的不断提升,近几年来更加庞大的大模型不断涌现,其表现能力也在不断的刷新着人们的视野。2022 年推出的 ChatGPT 仅仅用了两个月就突破了 1 亿活跃用户,其在自然语言理解和生成上的绝佳表现让人们看到了通用人工智能的希望。随之而来的持续出现各大模型的不断涌现。
四. 大模型的经典实例
当前人工智能领域涌现出了许多强大的 AI 大模型,下面列举出一些目前备受瞩目的 AI 大模型5。
1. OpenAI GPT 大模型组
ChaGPT 是 OpenAI 于 2022 年 11 月发布,其在自然语言的理解和生成上的卓越表现使得在短短两个月的时间用户突破 1 亿大关。ChaGPT 是基于 GPT (Generative Pre-trained Transformer) 架构开发的大型语言模型,为对话式交互提供更好的支持和响应,并在社交对话、问题回答和一般性对话等场景中展现出优秀的表现。
OpenAI 的目标是通过不断改进和提升这些大型语言模型,使其能更好地理解和生成人类语言,并更好地服务于用户需求。除此之外,OpenAI 还开发了 CLIP、DALL-E、Five、Whisper、Codex 等多模态大模型组。
2. Google PaLM 大模型组
PaLM (Pretraining and Fine-tuning Language Model) 是在 2020 年由 Google Research 团队发布的一种用于自然语言处理任务的预训练和微调模型。它的第二个版本,最新的大型语言模型 PaLM 2 于 2023 年 5 月在 Google I/O 开发者大会上推出,凭借改进的数学、逻辑和推理技能,可以帮助生成、解释和调试 20 多种编程语言的代码。
为了满足更多的使用场景,PaLM2 提供了4个模型:Gecko、Otter、Bison、Unicorn,其中最小的 Gecko 模型可以在移动端运行,并计划在下一代 Android 系统中集成。
3. 百度文心大模型组
百度于 2023 年 3 月正式发布了 AI 大模型文心一言,基于百度智能云技术构建的大模型,文心一言被广泛集成到百度的所有业务中。并且推出了文心 NLP 大模型、文心 CV 大模型、文心跨模态大模型、文心生物计算大模型、文心行业大模型。百度还提供了多样化的大模型 API 服务,可通过零代码调用大模型能力,自由探索大模型技术如何满足用户需求。
4. 讯飞星火认知大模型
科大讯飞于 2023 年 5 月正式发布了星火认知大模型,其具有 7 大核心能力,即文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力、多模态能力。
5. 阿里通义大模型
阿里通义大模型覆盖语言、听觉、多模态等领域,致力于实现接近人类智慧的通用智能,让 AI 从 “单一感官” 到 “五官全开”,分别在 2023 年 4 月和 6 月推出了通义千问和通义听悟。
6. 清华开源大模型 ChatGLM
GLM-130B 是清华智谱 AI 开源项目,其目的是训练出开源开放的高精度千亿中英双语模型,能够让更多研发者用上千亿参数模型。并且在 2023 年 3 月开源了更精简的低门槛大模型 ChatGLM-6B,这是一个具有 62 亿参数的中英文双语语言模型,在 6 月份,推出了二代开源模型 ChatGLM2-6B,具有更强大的性能、更长的上下文、更高效的推理、更开放的开源协议。
以上这些大模型只是当前众多 AI 大模型中的一小部分,随着技术的不断进步和研究的不断推进,我们可以期待更多更强大的 AI 大模型的涌现。
技术干货|什么是大模型?超大模型?Foundation Model? ↩︎
【大模型】—AI大模型总体概述 ↩︎
如何从RNN起步,一步一步通俗理解LSTM ↩︎
Transformer 模型详解 ↩︎
【大模型】—AI大模型总体概述 ↩︎