【哈夫曼树及其应用 c语言】
哈夫曼树目录
- 一、问题描述
- 二、实现功能
- 三、输入和输出内容
-
- (1)输入内容
- (2)输出内容
- 四、函数清单
- 五、 算法设计
-
- (1)==构造哈夫曼树==
- (2)==哈夫曼编码==
- (3)==哈夫曼译码==
- 六、代码如下
- 七、运行结果
一、问题描述
实际生活中,比上等长的
ASCLL编码和等长3位编码,我们为了尽可能压缩文件大小会选择使用不等长编码,这样,被浪费的空间就可以有效利用起来。
而不等长编码中的前缀编码(任意编码都不是其他任何编码的前缀(最左子串))可以保证我们对压缩文件进行解码不会产生二义性,确保正确的解码;
所以我们会选择使用最优前缀编码——哈夫曼编码来压缩文件,它既能使数据文件压缩后的二进制文件的长度最短,又能防止产生二义性。
利用哈夫曼树来进行哈夫曼编码,进而通过编码后的内容来进行译码。
要解决的问题具体描述如下:
欲发一封内容为 AABBCAB ……(共长 100 字符,其中:A 、 B 、 C 、 D 、 E 、 F 分别有 7 、 9 、 12 、 22 、 23、 27 个)的电报报文,实现哈夫曼编码和译码。
二、实现功能
(1)构造哈夫曼树——从森林中选取两个最小的权值合并,重复操作,直到森林中只含一颗树为止。
(2)进行哈夫曼编码——通过二级指针来动态分配编码空间,生成哈夫曼编码表。
(3)求出平均编码长度——在生成哈夫曼编码表的过程中求出每个编码的长度和权值的乘积,最后与权值总和相除。
(4)输入一串二进制编码进行译码——在编码完成的前提下从根结点遍历到叶子结点,从而找到其中的字符。
三、输入和输出内容
(1)输入内容
(1)叶子结点的个数:n。
(2)哈夫曼树结构体中的数据(字符)和权值:HT[i].data,HT[i].weight。
(3)判断前提是否满足的整数x:0为否,其它数字为是。
(4)选择功能的序号(1,2,3,4)和二进制编码。
(2)输出内容
(1)功能选择的详细列表和输入有误时的提示信息。
(2)哈夫曼树和哈夫曼编码表的构造结果。
(3)根据哈夫曼编码表译出的字符信息。

四、函数清单
| 功能 | 形式参数设置 | 形式参数意义 |
|---|---|---|
| (1)选择森林中两个最小值并返回 | void Select(HuffmanTree &HT,int k,int &s1,int &s2) |
改变主函数HT,s1和s2的数值。 |
| (2)无 | void str_length(HuffmanTree &HT,char str[]) |
改变主函数HT[i].data的数值。 |
| (3)构造哈夫曼树HT | void CreateHuffmanTree(HuffmanTree &HT,int n) |
获取叶子结点的个数n,改变HT[i]中的各个数值。 |
| (4)创建哈夫曼编码表(前缀编码) | void CreateHuffmancode(HuffmanTree HT,Huffmancode &HC,int n,int &wpl) |
将字符编码链式存储在HC[i]中,并改变主函数带权路径长度(wpl)的值。 |
| (5)求平均编码长度 | float averagecode(HuffmanTree HT,int wpl,int n) |
通过带权路径长度(wpl)求出平均编码长度并返回一个浮点值。 |
| (6)哈夫曼译码 | void decode(HuffmanTree HT,char a[],char b[],int n) |
通过a数组到b数组的转换实现二进制编码的译码。 |
五、 算法设计
(1)构造哈夫曼树
我们需要利用哈夫曼树来进行哈夫曼编码,那么哈夫曼树又有什么特点?
| 哈夫曼树的特点如下: |
|---|
1)没有度为1的结点(每个非叶子结点都是由两个最小值的结点构成) |
2)n个叶子结点的哈夫曼树总共有2n-1个结点( n 0 n0 n0:叶结点总数; n 1 n1 n1:只有一个儿子的结点总数;n2:有2个儿子的结点总数; n 2 = n 0 − 1 n2=n0-1 n2=n0−1; N = n 0 + n 1 + n 2 = 2 n − 1 N=n0+n1+n2=2n-1 N=n0+n1+n2=2n−1) |
| 3)哈夫曼树的任意非叶结点的左右子树交换后仍是哈夫曼树; |
与哈夫曼树有关的概念:
路径: 树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
路径长度:路径上的分枝数目称作路径长度。
树的路径长度:从树根到每一个结点的路径长度之和。
结点的带权路径长度:在一棵树中,如果其结点上附带有一个权值,通常把该结点的路径长度与该结点上的权值之积称为该结点的带权路径长度。
步骤:
1)初始化:
首先动态申请2n个单元;然后循环2n-1次,从1号单元开始,依次将1至2n-1所有单元的双亲、左孩子、右孩子的下标都初始化为0;
最后再循环n次,输入前n个单元中叶子结点的权值。
2)创建树:
循环n-1次,通过n-1次的选择、删除与合并来创建哈夫曼树。
选择是从当前森林中选择双亲为0且权值最小的两个树根结点s1和s2;删除是将结点s1和s2的双亲改为非0;合并就是将s1和s2的权值和作为一个新结点的权值依次存入到数组的第n+1个之后的单元中,同时记录这个新节点左孩子的下标为s1,右孩子的下标为s2。
代码如下:
void CreateHuffmanTree(HuffmanTree &HT,int n){ //构造哈夫曼树HT
int m,i,s1,s2;
char str[n];
if(n<=1)
{printf("结点个数过少,不需要构造\n");
return;}
m=2*n-1;
HT=new HTNode[m+1];
for(i=1;i<=m;++i){
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
HT[i].data=0;
}//将1~m号单元中的双亲,左孩子,右孩子,数据(字符的0为空格)的下标都初始化为0
printf("请输入数据(字符串形式,禁止输入空格):\n");
scanf("%s",str);
i=0;
while(str[i]!='\0'){
i++;
}
while(i!=n)
{//判断数据是否输入错误,不能有空格的字符串形式,输入错误重新输入
i=0;
printf("数据输入有误,请重新输入:");
scanf("%s",str);
while(str[i]!='\0'){
i++;
}
}
str_length(HT,str);
printf("请依次输入权值(整数形式):\n");
for(i=1;i<=n;++i){
scanf("%d",&HT[i].weight);//输入前n个单元中叶子结点的权值
}
/*---初始化完成,下面构造哈夫曼树---*/
for(i=n+1;i<=m;++i)//n-1次选择
{
Select(HT,i-1,s1,s2);//从前n个parent是0的找最小两个权值
HT[s1].parent=i;
HT[s2].parent=i;//将找过的parent置为i(删除)
HT[i].lchild=s1;
HT[i].rchild=s2;//s1,与s2分别作为i的左右孩子
HT[i].weight=HT[s1].weight+HT[s2].weight;//结点i的权值为s1,s2权值之和
}
printf("(~ ̄▽ ̄)~构造哈夫曼树完成\n\n");
printf("下面输出哈夫曼树构造结果:\n\n");
printf("结点i data weight parent lchild rchild\n");
for(i=1;i<=m;i++){
printf(" %d %c %d %d %d %d\n",i,HT[i].data,HT[i].weight,HT[i].parent,HT[i].lchild,HT[i].rchild);
}
}
(2)哈夫曼编码
什么是哈夫曼编码?
对一棵具有n个叶子的哈夫曼树,若对树中的每个
左分支赋予0,右分支赋予1,则从根到每个叶子的路径上,各分支的赋值分别构成多个二进制串,该二进制串就称为哈夫曼编码;
其基本思想为出现次数较多的字符编以较短的编码。
根据哈夫曼树求哈夫曼编码步骤:
1)分配存储n个字符编码的编码表空间HC,长度为n+1;分配临时存储每个字符编码的动数组空间cd, cd[n-1]置为"\0’。
2)逐个求解n个字符的编码,循环n次,执行以下操作:
●设置变量start用于记录编码在cd中存放的位置,start初始时指向最后,即编码结束符位置n-1;
●设置变量c用于记录从叶子结点向上回溯至根结点所经过的结点下标,c初始时为当前待编码字符的下标i, f用于记录i的双亲结点的下标;
●从叶子结点向上回溯至根结点,求得字符i的编码,当f没有到达根结点时,
| 循环执行以下操作: |
|---|
| ➢回溯一次start向前指一个位置,即-start; |
| ➢若结点c是f的左孩子,则生成代码0,否则生成代码1,生成的代码0 或1保存在cd[start]中; |
| ➢继续向上回溯,改变c和f的值。 |
●根据数组cd的字符串长度为第i个字符编码分配空间HC[i],然后将数组cd中的编码复制到HC[i]中。
3)释放临时空间cd。
voidCreateHuffmancode(HuffmanTree HT,Huffmancode &HC,int n,int &wpl){//创建哈夫曼编码表(前缀编码)
代码如下:
void CreateHuffmancode(HuffmanTree HT,Huffmancode &HC,int n,int &wpl){//创建哈夫曼编码表(前缀编码)
int i,start,c,f;
HC=new char*[n+1];//分配储存n个字符编码的编码表空间
char *cd=new char[n];//堆区开辟动态数组空间
cd[n-1]='\0';//编码结束符
for(i=1;i<=n;++i)
{//数组的第0号单元不用,逐个求字符编码
start=n-1;//start开始指向最后,即编码结束符位置
c=i;
f=HT[i].parent;//f指向结点c的双亲
while(f!=0)//从叶子结点开始回溯,直到根结点
{
--start;//回溯一次,start向前指向一个位置
if(HT[f].lchild==c) cd[start]='0';//结点c是f的左孩子,则cd[start] = 0;
else cd[start]='1';//否则c是f的右孩子,cd[start] = 1
c=f;
f=HT[f].parent;//继续向上回溯
}
HC[i]=new char[n-start];//为第i个字符编码分配空间
wpl+=HT[i].weight*(n-start);//求带权路径长度
strcpy(HC[i],&cd[start]);//把求得编码的首地址从cd[start]复制到HC的当前行中
}
delete cd;
}
(3)哈夫曼译码
步骤:
依次读入输入的二进制编码,从哈夫曼树的根结点出发,若当前
读入0,则走向左孩子,否则走向右孩子。一旦到达某一叶子HT[i]时便译出相应的字符编码HC[i]。然后重新从根出发继续译码,直至二进制编码读取完毕。
代码如下:
void decode(HuffmanTree HT,char a[],char b[],int n)//哈夫曼解码
{
int q = 2*n-1;//q初始化为根结点的下标
int k = 0;//记录存储译出字符数组的下标
int i = 0;
for (i = 0 ; a[i] != '\0';i++){
if (a[i]=='0')
{
q=HT[q].lchild;//左孩子的下标值赋给q,把HT[q]的左孩子作为新的根结点
}
else if (a[i] == '1')
{
q=HT[q].rchild;
}
if (HT[q].lchild == 0 && HT[q].rchild == 0)//判断HT[q]是否为叶子结点
{
b[k++] = HT[q].data;//把下标为q的字符赋给字符数组b[]
q=2*n-1;//继续下一个字符
}
}
b[k] = '\0';
/*译码完成之后,用来记录译出字符的数组由于没有结束符
输出的时候会报错,故紧接着把一个结束符加到数组最后*/
}
程序调试中的问题和解决办法:
问题一:
在输入字符数据HT[i].data时,程序运行结果不对?
经检验,函数
scanf( )从标准输入设备(键盘)读取输入的信息,不会直接赋值给变量,而是先储存到一个缓冲区中;
scanf()中格式化字符串里:
1)参数%d,会忽略缓冲区开头的空白符(空格、回车、制表符等)(无论有几个);
2)参数%c,直接读取缓冲区的第一个字符(无论这个字符是什么); 所以计算机对于输入的回车键进行了读入,导致程序运行出错。
解决办法:
将最后输入的回车键删除后再赋给HT[i].data;
简要代码如下:
int i;
for(i=1;str[i-1]!=‘\0’;i++) {
HT[i].data=str[i-1];
}
问题二:
如何增加程序的健壮性呢?此程序的建立有层次性,如何将功能划分出来进行单独操作呢?
解决办法:
考虑到直观和独立操作,我使用了switch和if进行判断,通过一系列语句进行判断,如果没有执行前提,就需要执行完前提才能实现所选功能。
六、代码如下
#include七、运行结果
哈夫曼树:
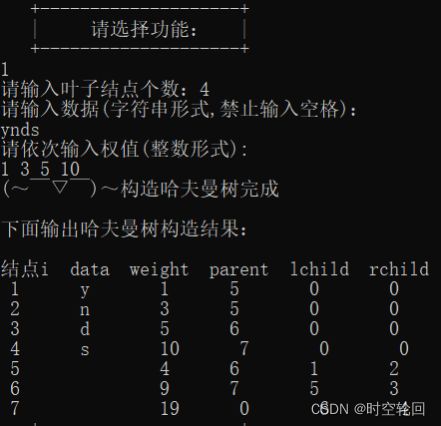
哈夫曼编码表并求平均编码长度:

哈夫曼译码:
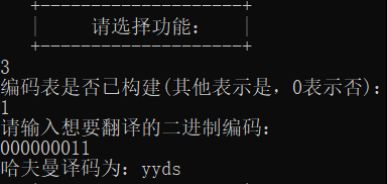
参考文献:
[1]《数据结构》 主编:严蔚敏 2013年9月第1版 人民邮电出版社