数据结构初级<带头双向循环链表>
本文已收录至《数据结构(C/C++语言)》专栏,欢迎大家 点赞 + 收藏 + 关注 !
目录
前言
正文
带头双向循环链表的存储结构
带头双向循环链表的操作函数
带头双向循环链表的实现
新节点创建函数ListNewNode(LTDataType x)
头节点创建函数ListNode* ListCreate()
表空判断函数bool ListEmpty(ListNode* pHead)
打印表函数void ListPrint(ListNode* pHead)
头部节点插入函数(头插)void ListPushFront(ListNode* pHead, LTDataType x)
尾部节点插入函数(尾插)void ListPopBack(ListNode* pHead)
头部节点删除函数(头删)void ListPopFront(ListNode* pHead)
尾部节点删除函数(尾删)void ListPopBack(ListNode* pHead)
节点查找函数ListNode* ListFind(ListNode* pHead, LTDataType x)
指定节点位置插入函数void ListInsert(ListNode* pos, LTDataType x)
指定节点位置删除函数void ListErase(ListNode* pos)
链表销毁函数void ListDestory(ListNode* pHead)
总结
前言
前面我们介绍了线性表的两种基础结构顺序结构和链式结构,并且在链式结构中有两种常用的链表,一种是单链表,另一种是带头双向循环链表,本节我们就介绍单链表的满BUFF版,带头双向循环链表。
正文
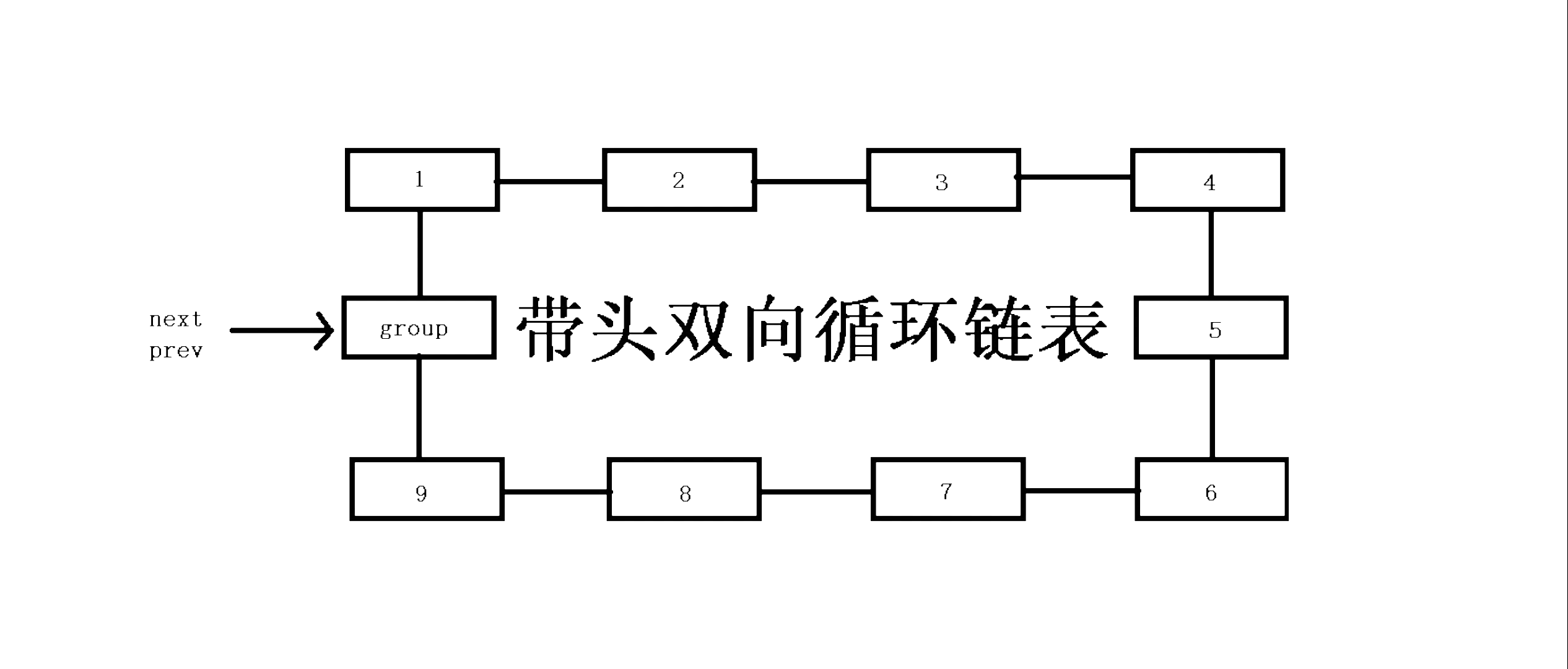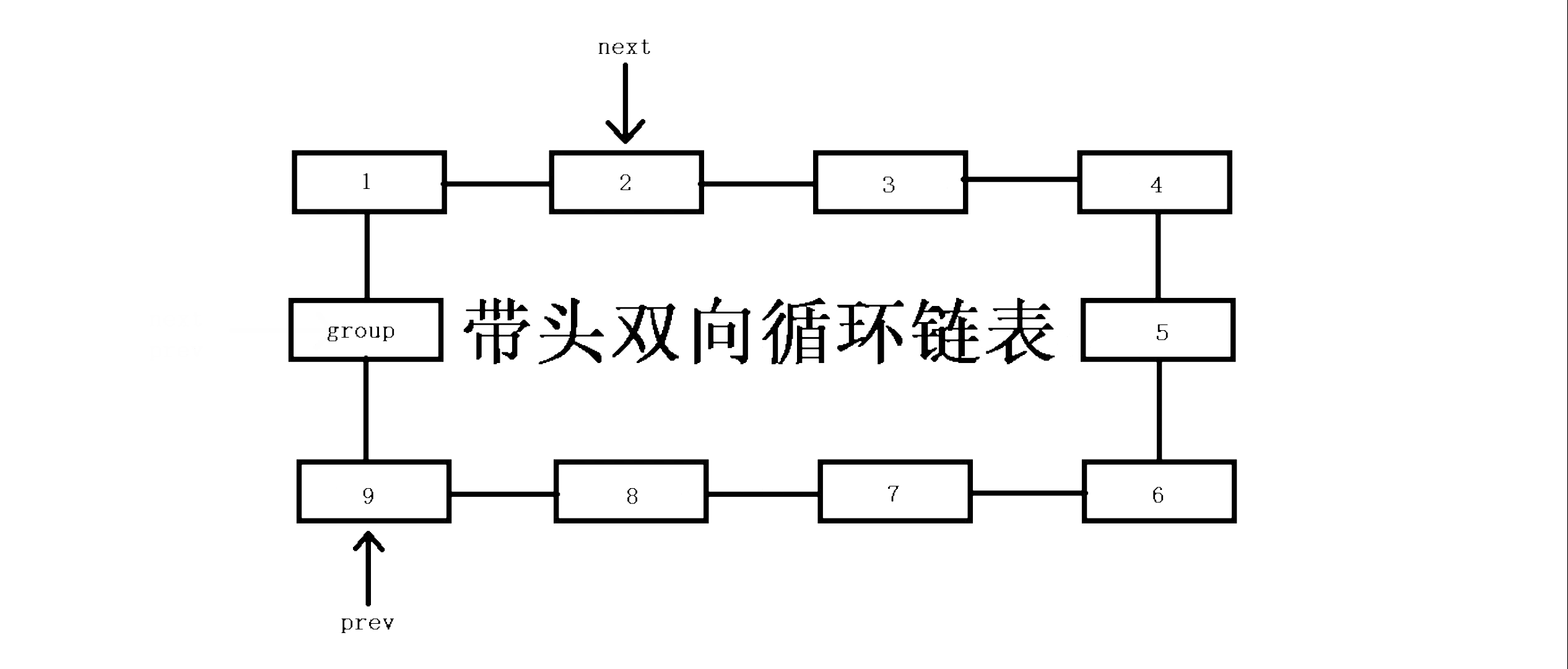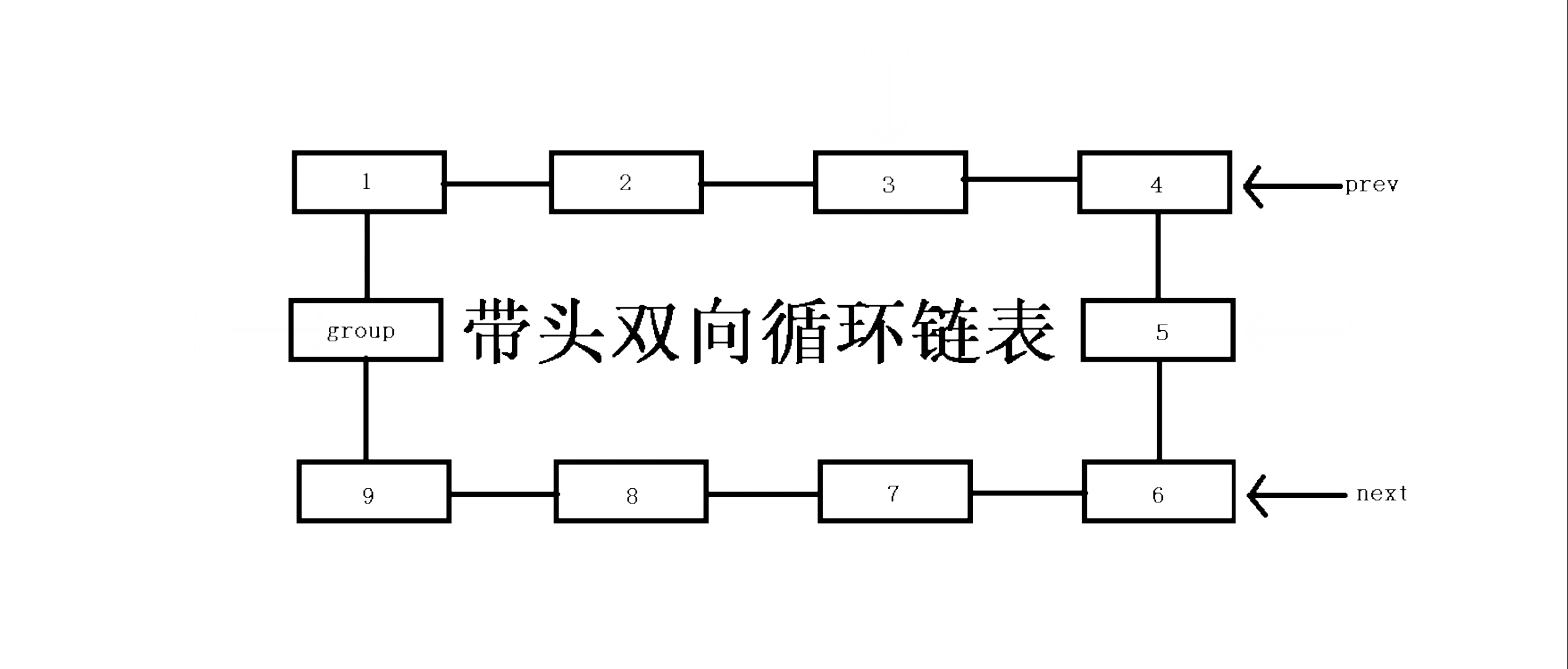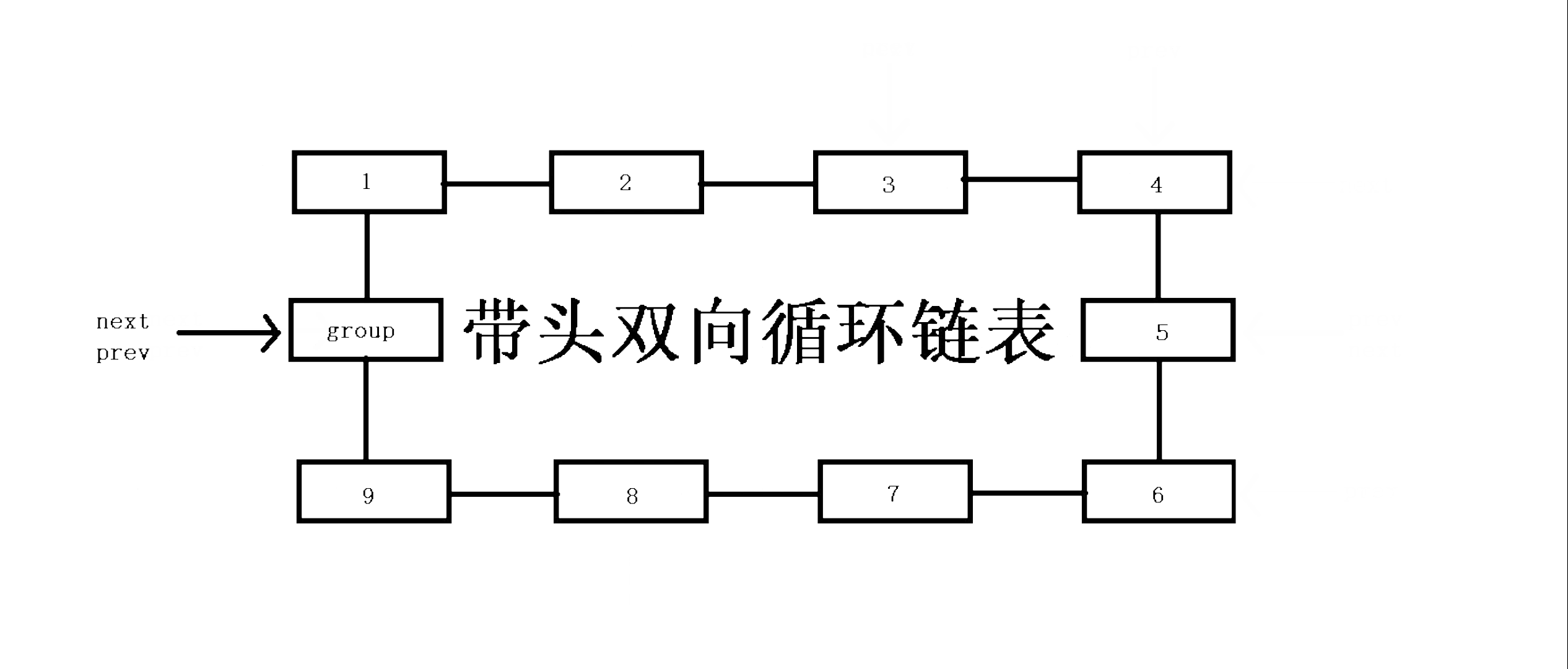
带头双向循环链表,是修复了单链表相对于顺序表某些缺陷的一种特殊链式结构,使其操作上效率更高,更方便储存和使用!带头双向循环链表的结构相对于单链表结构更复杂,实现上也有很多需要注意的事,但是这种结构也为我们带来了非常多的方便之处,例如尾删和尾插!
带头双向循环链表的存储结构
typedef int LTDataType;重定义数据类型int为LTDataType typedef struct ListNode//重定义结构体类型为ListNode { LTDataType data;//数据域data struct ListNode* next;//后继指针 struct ListNode* prev;//前驱指针 }ListNode;
带头双向循环链表的操作函数
// 双向链表创建并返回头结点地址 ListNode* ListCreate(); //双向链表新节点的创建申请 ListNode* ListNewNode(LTDataType x); //双向链表空判断 bool ListEmpty(ListNode* pHead); // 双向链表销毁 void ListDestory(ListNode* pHead); // 双向链表打印 void ListPrint(ListNode* pHead); // 双向链表尾插 void ListPushBack(ListNode* pHead, LTDataType x); // 双向链表尾删 void ListPopBack(ListNode* pHead); // 双向链表头插 void ListPushFront(ListNode* pHead, LTDataType x); // 双向链表头删 void ListPopFront(ListNode* pHead); // 双向链表查找 ListNode* ListFind(ListNode* pHead, LTDataType x); // 双向链表在pos位置进行插入 void ListInsert(ListNode* pos, LTDataType x); // 双向链表删除pos位置的节点 void ListErase(ListNode* pos);
带头双向循环链表的实现
新节点创建函数ListNewNode(LTDataType x)
对于新节点的创建,我们使用malloc申请一个ListNode空间大小的内存空间,创建完成后检查是否申请草稿,并初始化data为x,next和prev指针初始化为NULL防止野指针,最后返回所申请节点的地址。
//双向链表新节点的申请 ListNode* ListNewNode(LTDataType x) { ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));//申请一个ListNode空间 if (!newnode)//检查空间申请是否成功 { perror("malloc fail\n"); exit(-1); } newnode->data = x;//初始化为指定值x newnode->next = NULL;//置空next和prev指针 newnode->prev = NULL; return newnode;//返回节点地址 }
头节点创建函数ListNode* ListCreate()
我们链表的名字中既然提到带头,那么就有一个哨兵节点(头节点),这个节点与链表节点的数据类型相同但是不存储任何数据,作为一个单独的节点。
这样做的好处在于,链表为空时指针不为空,只是哨兵节点下没有指向任何节点,这样就不需要传递二级指针进行解引用操作了,因为不会对头指针进行任何操作,除非是销毁哨兵节点,而且这样的设计对于尾插和头插会非常方便,不需要判断特殊情况,减少代码量。
对于申请一个哨兵节点,我们调用节点申请函数ListNewNode(LTDataType x)申请一个节点将data域初始化为-1,next指针和prev指针都指向自己,这样方便判断链表为空而且也符合循环链表的性质!最后返回头节点的地址。
//申请一个哨兵节点 ListNode* ListCreate() { ListNode* newnode = ListNewNode(-1);//申请一个data为-1的节点作为头节点 newnode->prev = newnode;//前驱指针指向自己 newnode->next = newnode;//后继指针指向自己 return newnode;//返回头节点地址 }
表空判断函数bool ListEmpty(ListNode* pHead)
对于删除函数,一般进行删除前需要判断是否表空,我们创建一个函数进行判断,如果表空返回true,不为空返回false,方便其他函数调用。
判断表空的条件很简单,因为我们有一个头节点,所有表空时头节点的前驱和后继指针都指向自己,此时链表就为空!
//双向链表表空判断 bool ListEmpty(ListNode* pHead) { return (pHead->prev == pHead->next) &&(pHead->next == pHead) ? true : false; //如果前驱指针等于后继指针且都指向自己则表示空 //为空返回false,否则返回true }
打印表函数void ListPrint(ListNode* pHead)
对于带头双向循环链表的打印,我们使用for循环从第一个节点开始打印,既然是带头链表,那么第一个节点应该是pHead->next,而不是pHead,这里我们定义一个迭代变量cur去遍历全链表,直到下一个节点是哨兵节点就结束!
//打印表函数 void ListPrint(ListNode* pHead) { if (pHead)//如果地址不为空则打印 { printf("Guard-");//打印一个头 for (ListNode* cur = pHead->next; cur != pHead; cur = cur->next) { printf("%d-", cur->data);//迭代打印变量 } printf("NULL\n");//末尾打印一个NULL表示结束 } else//如果哨兵节点异常则反馈 { perror("Guard Error\n"); } }
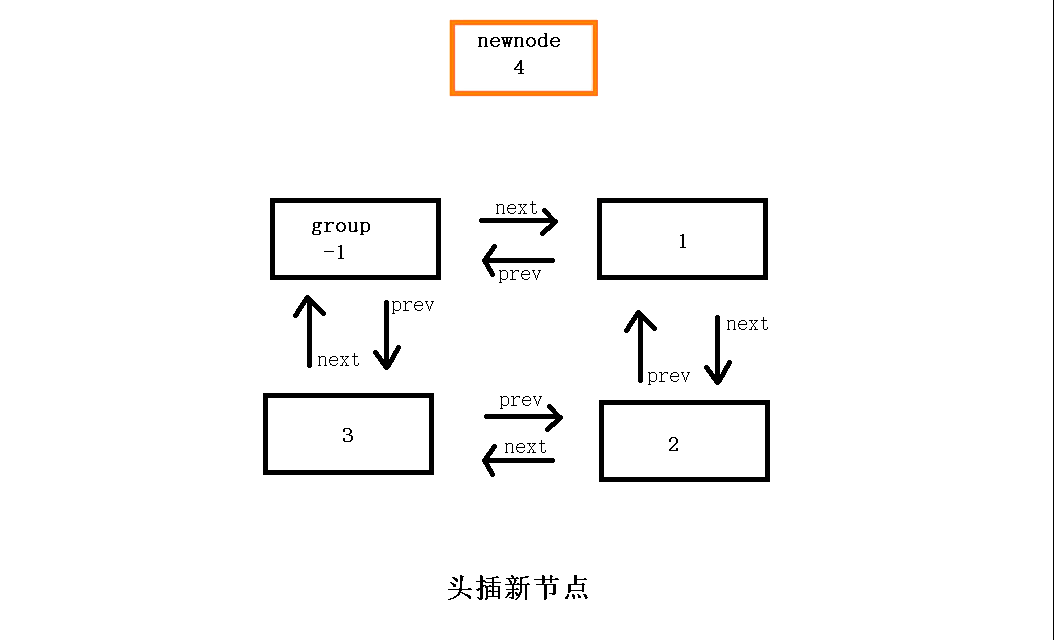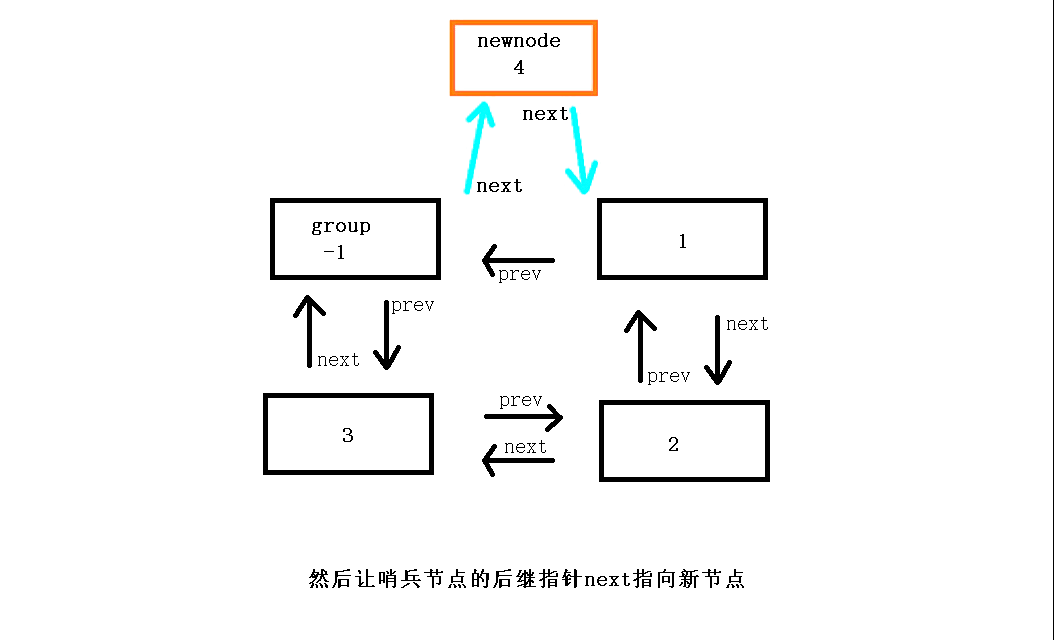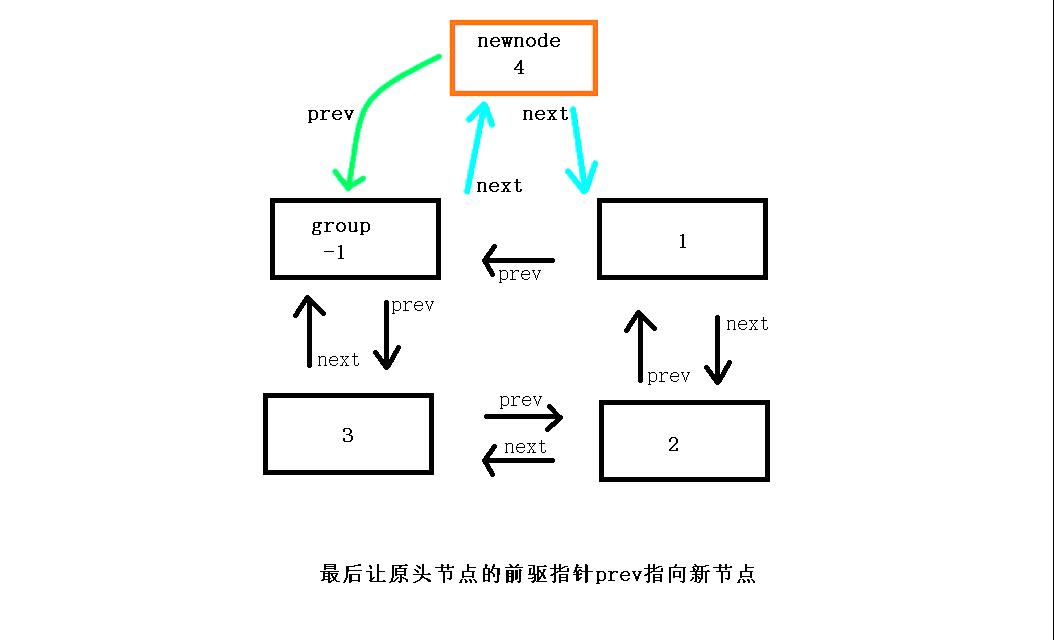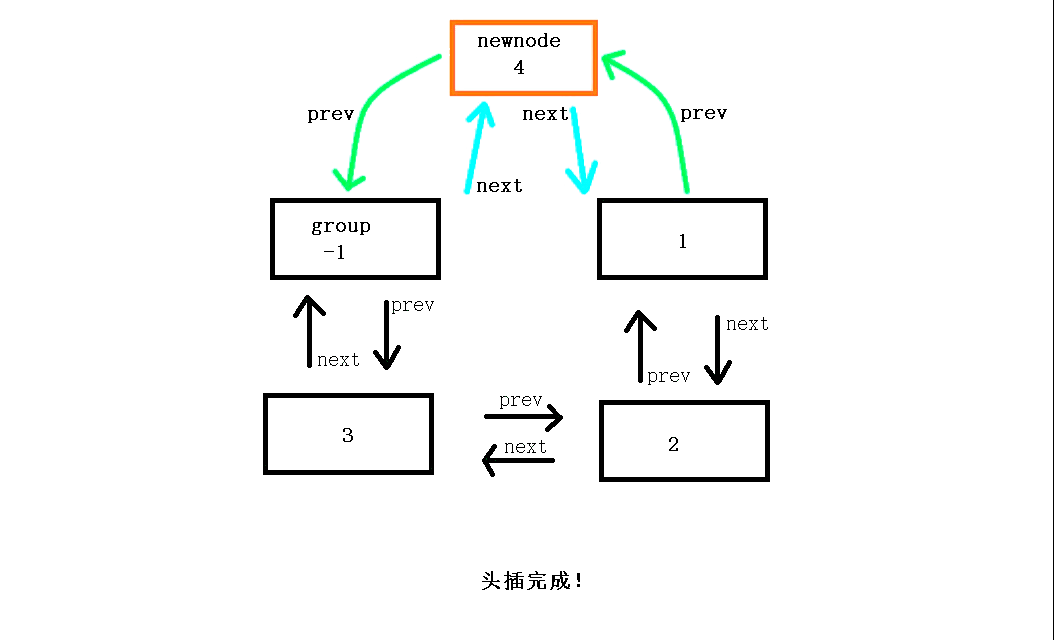
头部节点插入函数(头插)void ListPushFront(ListNode* pHead, LTDataType x)
对于在链表进行头插,首先申请一个新节点并定义变量保存原头节点的地址(这样更方便操作,不容易混乱),如果链表为空则直接插入,如果不为空则插在第一个节点的前面,而在插入时,与单链表不同,在链接时新节点的next指向链表的第一个节点,然后哨兵节点的next指向新节点,新节点的prev指向哨兵节点,原第一个节点(原头节点)的prev指向现在的新节点完成头插。
// 双向链表头插 void ListPushFront(ListNode* pHead, LTDataType x) { assert(pHead); ListNode* newnode = ListNewNode(x);//申请一个新节点 ListNode* Headnode = pHead->next;//保存原头节点 newnode->next = Headnode;//新节点的后继指针next指向原头节点 pHead->next = newnode;//哨兵节点的后继指针next指向新节点 newnode->prev = pHead;//新节点的前驱指针prev指向哨兵节点 Headnode->prev = newnode;//原头节点的前驱指针prev指向新节点 }
尾部节点插入函数(尾插)void ListPopBack(ListNode* pHead)
对于在链表尾部的插入,区别于单链表的是我们不需要找尾,直接对哨兵节点的prev指针操作即可,这就是双链表的好处,在端点处的操作时间复杂度为O(1),我们仍然是申请一个data值为x的新节点并定义一个变量保存尾节点,然后让新节点的后继指针next指向哨兵节点,原尾节点的后继指针next指向新节点,新节点的前驱指针prev指向原尾节点,哨兵节点的前驱指针prev指向新节点,新节点成为尾节点!
// 双向链表尾插 void ListPushBack(ListNode* pHead, LTDataType x) { assert(pHead); ListNode* newnode = ListNewNode(x);//申请一个新节点 ListNode* Tailnode = pHead->prev;//保存原尾节点 newnode->next = pHead;//新节点的后继指针next指向哨兵节点 Tailnode->next = newnode;//原尾节点的后继指针next指向新节点 pHead->prev = newnode;//哨兵节点的前驱指针指向新节点 newnode->prev = Tailnode;//新节点的前驱指针指向原尾节点 }
头部节点删除函数(头删)void ListPopFront(ListNode* pHead)
对于链表的头删,我们定义一个临时变量存储即将删除的原头节点地址,然后链接哨兵节点和头节点之后的节点,就能完全剥离原头节点,然后free释放即可!但是在删除之前要检查链表是否为空,不为空才执行删除。
// 双向链表头删 void ListPopFront(ListNode* pHead) { assert(pHead);//检查是否为空指针 if(!ListEmpty(pHead))//检查链表是否为空 { ListNode* freenode = pHead->next;//将要删除的节点保存下来 pHead->next = freenode->next;//哨兵节点的后继指针next指向原头节点的后继(第二个节点) freenode->next->prev = pHead;//原头节点后继节点的前驱指针prev指向哨兵节点 free(freenode);//释放原头节点 freenode = NULL;//置空指针 } }
尾部节点删除函数(尾删)void ListPopBack(ListNode* pHead)
对于尾部删除函数,与头删一样,先保存即将删除的尾节点,然后链接被删除的尾节点的前驱和后继节点,剥离这个尾节点free释放即可,这里仍然需要检查链表是否为空!
//双链表的尾删 void ListPopBack(ListNode* pHead) { assert(pHead);//检查是否为空指针 if(!ListEmpty(pHead))//检查链表是否为空 { ListNode* freenode = pHead->prev;//将要删除的节点保存下来 pHead->prev = freenode->prev;//哨兵节点的前驱指针prev指向尾节点的前驱节点 freenode->prev->next = pHead;//尾节点的前驱节点的后继指针next指向哨兵节点 free(freenode);//释放尾节点 freenode = NULL;//指针置空 } }
通过前面的对链表头部和尾部的增删操作可以发现,我们只要知道双向带头循环链表的任意一个节点就能去到任何节点,可以对任何节点进行操作,因为该链表既能倒着遍历也能顺着遍历且是一个闭环结构,是一种非常完美的链式结构。
节点查找函数ListNode* ListFind(ListNode* pHead, LTDataType x)
节点查找函数的功能说通过遍历链表来查找节点并返回节点地址,该函数主要是用来辅助指定删除和指定插入函数的,与单链表不同的是,这里的查找既可以顺着走也可以倒着走,于是我们使用一个类似于折半的原理,一个指针顺着走,一个指针倒着走,同时开始查找,直到两个指针找到了就返回该地址,如果两指针相遇则没找到,返回NULL。
// 双向链表查找 ListNode* ListFind(ListNode* pHead, LTDataType x)//双指针查找 { assert(pHead); for (ListNode *curnext = pHead->next, *curprev = pHead->prev; //初始化前驱指针和后继指针 (curnext->prev != curprev && curnext->prev!=curprev->next) || curnext->prev == pHead; //相遇条件(奇数个节点会相遇,偶数个节点会错过,分情况处理) curnext = curnext->next, curprev=curprev->prev)//两指针反方向迭代 { if (curnext->data == x)//对比节点的data是否等于x,如果等于就返回 { return curnext; } else if (curprev->data == x) { return curprev; } } return NULL;//如果迭代结束还没有找到则返回NULL }
指定节点位置插入函数void ListInsert(ListNode* pos, LTDataType x)
该函数需要搭配查找函数ListNode* ListFind(ListNode* pHead, LTDataType x)使用,我们前面总结过,我们只需要知道任意一个节点,就能就行任何操作,在单链表中,如果我们需要将节点插入在某个指定节点的前面,我们在接收了pos指针之后还需要遍历到这个指针的前一个节点,但是带头双向循环链表不需要,我们知道这个节点之后,只需要将新节点链入对应位置前后节点即可。
操作与前面的尾插和头插相同,先让新节点的后继指针next指向pos,然后让新节点的前驱指针prev指向pos节点的前驱,再让pos的前驱节点的后继指针next指向新节点,最后pos的前驱指针prev指向新节点,完成链入!
// 双向链表在pos的前面进行插入(相当于在当前位置插入) void ListInsert(ListNode* pos, LTDataType x) { if (pos)//pos不为空说明找到了 { ListNode* newnode = ListNewNode(x);//申请新节点 newnode->prev = pos->prev;//新节点的前驱指向pos节点的前驱 newnode->next = pos;//新节点的后继等于pos pos->prev->next = newnode;//pos的前驱的后继节点指向新节点 pos->prev = newnode;//pos前驱指向新节点 } else { printf("没有此位置!\n"); } }有了指定位置插入函数,那么我们的头插和尾插可以写的更简便!
头插函数优化:
// 双向链表头插-调用任意插入函数 void ListPushFront(ListNode* pHead, LTDataType x) { assert(pHead); ListInsert(pHead->next, x);//在头节点前插入新节点-头插 }尾插函数优化:
// 双向链表尾插-调用任意插入函数 void ListPushBack(ListNode* pHead, LTDataType x) { assert(pHead); ListInsert(pHead, x);//在哨兵节点位置插入新节点-即尾插 }
指定节点位置删除函数void ListErase(ListNode* pos)
指定位置删除函数同样需要调用查找函数对节点就行查找,然后剥离节点,链接被删节点的前驱和后继即可!
// 双向链表删除pos位置的节点 void ListErase(ListNode* pos) { if (pos)//如果pos为NULL,要么位置错误,要么链表为空 { ListNode* posprev = pos->prev;//定义变量保存被删节点的前驱节点 ListNode* posnext = pos->next;//定义变量保存被删节点的后继节点 posnext->prev = posprev;//被删节点的前驱节点和后继节点相互链接 posprev->next = posnext; free(pos);//释放pos位置节点 } else { printf("表空或位置错误!\n"); } }有了指定位置删除函数,我们的头删和尾删也可以就行优化!
头删函数优化:
// 双向链表头删 void ListPopFront(ListNode* pHead) { if (ListEmpty(pHead))//判断链表是否为空 { ListErase(pHead->next);//删除头节点 } }尾删函数优化:
// 双向链表尾删 void ListPopBack(ListNode* pHead) { if (ListEmpty(pHead))//判断链表是否为空 { ListErase(pHead->prev);//删除尾节点 } }
链表销毁函数void ListDestory(ListNode* pHead)
链表销毁函数与单链表的销毁相差无几,定义一个变量通过迭代逐一销毁所有节点,在销毁前也需要定义一个变量保存下一个节点的地址,但是哨兵节点需要最后单独销毁!直接free释放哨兵节点地址的内存即可!
// 双向链表销毁 void ListDestory(ListNode* pHead) { assert(pHead); for (ListNode *cur = pHead->next,*curnext= cur->next; //初始化变量,cur保存头节点地址,curnext保存头节点的下一个节点的地址 cur != pHead; cur = curnext, curnext = cur->next) { free(cur); } free(pHead);//最后释放哨兵节点 }
总结
本次我们介绍了数据结构中的线性表的链式结构中非常完美的带头双向循环链表,介绍了关于带头双向循环链表增删查改等各种操作。相信到这里大家对带头双向循环链表已经有了一定的认识,这种链表放大了链式结构的优势,使得代码的执行效率更高!线性表的学习到这里还没有结束,后面还会介绍两种特殊的线性表“栈和队列”,敬请期待!
本次带头双向循环链表的知识分享就暂时先到这里啦,喜欢的读者可以多多点赞收藏和关注!
如果文章中有瑕疵,还请各位大佬细心点评和留言,我将立即修补错误,谢谢!
博客中的所有代码合集:双向带头循环链表博客

其他文章阅读推荐
数据结构初级<时间和空间复杂度>_ARMCSKGT的博客-CSDN博客
数据结构初级<线性表之顺序表>_ARMCSKGT的博客-CSDN博客
数据结构初级<线性表之链表>_ARMCSKGT的博客-CSDN博客
欢迎读者多多浏览多多支持!