Acwing算法基础课学习笔记
Acwing学习笔记
-
-
- 第一章 基础算法
-
- 快速排序
- 归并排序
- 二分查找
- 前缀和与差分
- 差分
- 位运算
- 离散化
- 第二章 数据结构
-
- 单链表
- 双链表
- 栈
- 队列
- 单调栈
- 单调队列
- KMP算法
- Trie
- 并查集
- 堆
- 哈希表
- 第三章 搜索与图论
-
- DFS
- BFS
- 树与图的深度优先遍历
- 树与图的广度优先遍历
- 拓扑排序
- 图论
-
- 朴素dijkstra
- 堆优化版dijkstra
- bellman-ford
- spfa(求最短路)
- spfa(判断负环)
- Floyd
- 最小生成树
-
- Prim求最小生成树
- Kruskal 求最小生成树
- 二分图
-
- 染色法判断二分图
- 二分图最大匹配
- 第四章 数学知识
-
- 质数
- 第五章 动态规划
-
- 背包问题
-
- 01背包问题
- 第六章 贪心
-
- 区间问题:
- Hufman树:
- 排序不等式 :
- 绝对值不等式:
- 推公式:
-
第一章 基础算法
快速排序
- AcWing 785. 快速排序
给定你一个长度为 n 的整数数列。
请你使用快速排序对这个数列按照从小到大进行排序。
并将排好序的数列按顺序输出。
输入格式
输入共两行,第一行包含整数 n。
第二行包含 n 个整数(所有整数均在 1∼ 1 0 9 10^9 109 范围内),表示整个数列。
输出格式
输出共一行,包含 n 个整数,表示排好序的数列。
数据范围:1≤n≤100000
输入样例:
5
3 1 2 4 5
输出样例:
1 2 3 4 5
解析:
- 找到一个值x作为划分点,这个值可以是
q[l],q[r], q[l+r/2],也可以是区间的随机值 - 定义两个指针
i,j,分别指向区间的两侧 - 当指针i指向的值q[i] > x时,指针i向右移动一位;指针j指向的值q[j] > x,指针j向左移动一位
- 对于任意时刻,都存在q[l,i] 的值小于等于x,区间q[j,r]的值大于等于x
- 当i和j各找到一个不符合条件的值的时候,交换i,j指向的值
- 递归对两个子区间进行排序
代码:
class Quick_sort:
def qs(self,nums,l,r):
if l == r:return # 当区间为1时,退出递归
x = nums[l + r >> 1] # 选择一个用于划分区间的值
i = l - 1 # 将左指针指向l的左侧
j = r + 1 # 将右指针指向r的右侧
while i < j:
i += 1 # 先向左移动一次i;目的:交换i和j的值后不需要单独移动一次i和j
while nums[i] < x: i += 1 # 当i指向的值不小于x的时候,停止循环
j -= 1 # 先向右移动一次j
while nums[j] > x: j -= 1 # 当j指向的值不大于x的时候,停止循环
if i < j: # i小于j的时候才进行交换,此时找到的值就满足nums[i] >= x和nums[j] <= x
nums[i], nums[j] = nums[j], nums[i]
# 递归处理子区间
# 此处选择区间存在边界情况:
# 1.如果选择[l,j][j+1,r]时,x的取值就不能包含右端点;x = nums[l + r >> 1]
# 2.如果选择[l,i-1][i,r]时,x的取值就不能包含左端点;x = nums[l + r + 1 >> 1]
self.qs(nums,l,j)
self.qs(nums,j+1,r)
def main(self):
n = int(input())
self.line = list(map(int,input().split()))
self.qs(self.line,0,n-1)
for i in self.line:
print(i, end=' ')
if __name__ == '__main__':
quicksort = Quick_sort()
quicksort.main()
- AcWing 786. 第k个数
给定一个长度为 n 的整数数列,以及一个整数 k,请用快速选择算法求出数列从小到大排序后的第 k 个数。
输入格式
第一行包含两个整数 n 和 k。
第二行包含 n 个整数(所有整数均在 1∼ 1 0 9 10^9 109 范围内),表示整数数列。
输出格式
输出一个整数,表示数列的第 k 小数。
数据范围
1≤n≤100000,
1≤k≤n
输入样例:
5 3
2 4 1 5 3
输出样例:
3
解析:
- 找到一个值x作为划分点,这个值可以是
q[l],q[r], q[l+r/2],也可以是区间的随机值 - 定义两个指针
i,j,分别指向区间的两侧 - 当指针i指向的值q[i] > x时,指针i向右移动一位;指针j指向的值q[j] > x,指针j向左移动一位
- 对于任意时刻,都存在q[l,i] 的值小于等于x,区间q[j,r]的值大于等于x
- 当i和j各找到一个不符合条件的值的时候,交换i,j指向的值
- 计算左区间的长度:
sl = j - l + 1(或者:l = i - l) - 如果k小于等于sl,则第k小的数在左区间,递归处理左区间即可;反之递归处理右区间
class Quickcheck:
def quickcheck(self,l,r,k):
if l == r:return self.nums[l] # 当区间只剩下一个数的时候,这个数就是第k小的数
x = self.nums[l + r >> 1] # 选取任意一个值作为分界点,小于这个值的点划分到左区间,大于这个值的点划分到右区间
i,j = l-1,r+1
while i < j:
i += 1
while self.nums[i] < x:i += 1
j -= 1
while self.nums[j] > x:j -= 1
if i < j:self.nums[i],self.nums[j] = self.nums[j],self.nums[i]
# 左区间长度为j - l + 1,如果选则[l,i-1][i,r]作为划分点的话,左区间的长度就为sl = i - l(此时x不能取到左端点)
sl = j - l + 1
if sl >= k: return self.quickcheck(l,j,k)
else:return self.quickcheck(j+1,r,k-sl)
def main(self):
n,k = map(int,input().split())
self.nums = list(map(int,input().split()))
print(self.quickcheck(0,n-1,k))
if __name__ == '__main__':
quickcheck = Quickcheck()
quickcheck.main()
归并排序
- AcWing 787. 归并排序
给定你一个长度为 n 的整数数列。请你使用归并排序对这个数列按照从小到大进行排序。并将排好序的数列按顺序输出。
输入格式
输入共两行,第一行包含整数 n。
第二行包含 n 个整数(所有整数均在 1 ∼ 1 0 9 1∼10^9 1∼109 范围内),表示整个数列。
输出格式
输出共一行,包含 n 个整数,表示排好序的数列。
数据范围
1≤n≤100000
输入样例:
5
3 1 2 4 5
输出样例:
1 2 3 4 5
解析:
- 找到区间的中点mid = l + r >> 1
- 对左右区间进行递归排序
- 定义两个指针i,j,分别指向左右区间的起点
- 对两个区间的每个值进行比较大小,需要定义一个额外的结果数组,用来存放排序后的值
- 当i指向的值小于j指向的值,就将i指向的值加入到结果数组中,并将指针i向后移动一位
- 当j指向的值小于等于i指向的值,就将j指向的值加入到结果数组中,并将指针j想左移动一位
- 对于任意时刻,指针j指向的值都满足大于等于i指向的值
- 判断i和j是否移动到子数组的末尾,如果没有移动到末尾,则说明子数组中存在剩余元素,直接加入到结果列表中即可
class Mergesort:
def mergesort(self,nums):
if len(nums) == 1:return # 当区间长度为1时直接返回
mid = len(nums) >> 1 # 获取区间的中点
L = nums[:mid] # 将当前区间以中点划分左右两个区间
R = nums[mid:]
self.mergesort(L) # 对左右区间进行递归排序
self.mergesort(R)
i = j = k = 0 # 定义三个指针,分别指向左区间、右区间、结果数组的起点
while i < len(L) and j < len(R): # 边界条件
if L[i] < R[j]: # 如果左区间的值小于右区间的值,就将左区间的值加入到结果数组中
nums[k] = L[i]
i += 1
else: # 反之将右区间的值加入到结果数组中
nums[k] = R[j]
j += 1
k += 1
while i < len(L): # 判断左右区间是否还有剩余元素,处理剩余元素
nums[k] = L[i]
k += 1
i += 1
while j < len(R):
nums[k] = R[j]
k += 1
j += 1
return nums
def main(self):
int(input())
nums = list(map(int,input().split()))
res = self.mergesort(nums)
for i in res:
print(i, end=' ')
if __name__ == '__main__':
mergesort = Mergesort()
mergesort.main()
- AcWing 788. 逆序对的数量
给定一个长度为 n 的整数数列,请你计算数列中的逆序对的数量。
逆序对的定义如下:对于数列的第 i 个和第 j 个元素,
如果满足 i
输入格式
第一行包含整数 n,表示数列的长度。
第二行包含 n 个整数,表示整个数列。
输出格式
输出一个整数,表示逆序对的个数。
数据范围
1≤n≤100000,
数列中的元素的取值范围 [1, 1 0 9 10^9 109]。
输入样例:
6
2 3 4 5 6 1
输出样例:
5
解析:
- 找到区间的中点mid,mid将整个区间划分为
[:mid][mid:]两个区间 - 分别递归处理两个区间
- 当逆序对a,b同时出现在左区间或者右区间,直接在递归处理的时候加上返回值即可
- 当逆序对a,b一个在左区间一个在右区间,需要分情况讨论
- 当q[i] > q[j] 时,q[i]之后的所有数都对q[j]构成逆序对
class Reverse_order:
def mergesort(self,nums):
if len(nums) == 1:return 0 # 区间长度为1,这个区间就不存在逆序对
mid = len(nums) >> 1
left = nums[:mid] # mid将原始区间划分为左右两个子区间
right = nums[mid:]
res = 0
res += self.mergesort(left) # 递归处理左右区间
res += self.mergesort(right)
i = j = k = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:nums[k] = left[i]; k += 1; i += 1
# 当left[i] > right[j]:说明left区间中[i:mid)的数都与right[j]构成逆序对
else:nums[k] = right[j];k += 1;j += 1;res += mid - i
while i < len(left):nums[k] = left[i]; i += 1;k += 1
while j < len(right):nums[k] = right[j]; j += 1;k += 1
return res
def main(self):
n = int(input())
nums = list(map(int,input().split()))
res = self.mergesort(nums)
print(res)
if __name__ == '__main__':
reverseorder = Reverse_order()
reverseorder.main()
二分查找
- AcWing 789. 数的范围
给定一个按照升序排列的长度为 n 的整数数组,以及 q 个查询。
对于每个查询,返回一个元素 k 的起始位置和终止位置(位置从 0 开始计数)。
如果数组中不存在该元素,则返回 -1 -1。
输入格式
第一行包含整数 n 和 q,表示数组长度和询问个数。
第二行包含 n 个整数(均在 1∼10000 范围内),表示完整数组。
接下来 q 行,每行包含一个整数 k,表示一个询问元素。
输出格式
共 q 行,每行包含两个整数,表示所求元素的起始位置和终止位置。
如果数组中不存在该元素,则返回 -1 -1。
数据范围
1≤n≤100000
1≤q≤10000
1≤k≤10000
输入样例:
6 3
1 2 2 3 3 4
3
4
5
输出样例:
3 4
5 5
-1 -1
思路:
能够进行二分的充要条件是,区间存在二段性(不一定是单调性)
- 找到区间的中点mid
- 判断目标值落在哪个区间,更新区间的端点为目标区间,这样每次缩小区间长度为原来的一半
class Binary_search:
def binarysearch(self,nums,target):
"""
找到第一个大于等于目标值的索引值
:param nums:
:param target:
:return:
"""
l,r = 0,len(nums) - 1
while l < r:
mid = l + r>> 1
if nums[mid] >= target:r = mid
else:l = mid + 1
return l
def binarysearch2(self,nums,target):
"""
找到第一个小于等于目标值的索引值
:param nums:
:param target:
:return:
"""
l,r = 0,len(nums) - 1
while l < r:
mid = l + r + 1>> 1
if nums[mid] <= target: l = mid # 如果这里取的是l,mid计算就需要取l+r+1>>1
else:r = mid - 1
return r
def main(self):
n,q = map(int,input().split())
nums = list(map(int,input().split()))
for i in range(q):
k = int(input())
left = self.binarysearch(nums,k)
right = self.binarysearch2(nums,k)
if nums[left] != k:print(-1,-1)
else:print(left,right)
if __name__ == '__main__':
binarysearch = Binary_search()
binarysearch.main()
前缀和与差分
AcWing 795. 前缀和(一维前缀和)
输入一个长度为 n 的整数序列。
接下来再输入 m 个询问,每个询问输入一对 l,r。
对于每个询问,输出原序列中从第 l 个数到第 r 个数的和。
输入格式
第一行包含两个整数 n 和 m。
第二行包含 n 个整数,表示整数数列。
接下来 m 行,每行包含两个整数 l 和 r,表示一个询问的区间范围。
输出格式
共 m 行,每行输出一个询问的结果。
数据范围
1≤l≤r≤n,
1≤n,m≤100000,
−1000≤数列中元素的值≤1000
输入样例:
5 3
2 1 3 6 4
1 2
1 3
2 4
输出样例:
3
6
10
class Prefixsum:
def main(self):
n,m = map(int,input().split())
nums = list(map(int,input().split()))
nums = [0] + nums
for i in range(1,n+1):
nums[i] += nums[i-1]
for j in range(m):
l,r = map(int,input().split())
print(nums[r] - nums[l-1])
if __name__ == '__main__':
perfixsum = Prefixsum()
perfixsum.main()
AcWing 796. 子矩阵的和(二维前缀和)
输入一个 n 行 m 列的整数矩阵,再输入 q 个询问,
每个询问包含四个整数 x1,y1,x2,y2,表示一个子矩阵的左上角坐标和右下角坐标。
对于每个询问输出子矩阵中所有数的和。
输入格式
第一行包含三个整数 n,m,q。
接下来 n 行,每行包含 m 个整数,表示整数矩阵。
接下来 q 行,每行包含四个整数 x1,y1,x2,y2,表示一组询问。
输出格式
共 q 行,每行输出一个询问的结果。
数据范围
1≤n,m≤1000,
1≤q≤200000,
1≤x1≤x2≤n,
1≤y1≤y2≤m,
−1000≤矩阵内元素的值≤1000
输入样例:
3 4 3
1 7 2 4
3 6 2 8
2 1 2 3
1 1 2 2
2 1 3 4
1 3 3 4
输出样例:
17
27
21
解析:
- 二维前缀和: p r e f i x [ x 3 , y 3 ] = p r e f i x [ x 2 , y 3 ] + p r e f i x [ x 3 , y 2 ] − p r e f i x [ x 2 , y 2 ] + n u m s [ x 3 , y 3 ] prefix[x3,y3] = prefix[x2,y3] + prefix[x3,y2] - prefix[x2,y2] + nums[x3,y3] prefix[x3,y3]=prefix[x2,y3]+prefix[x3,y2]−prefix[x2,y2]+nums[x3,y3]
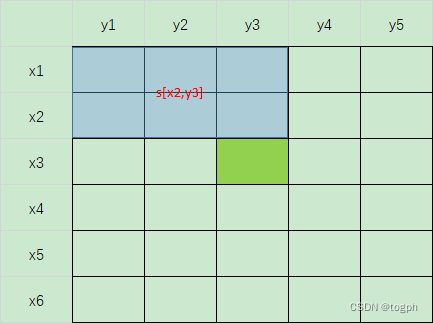


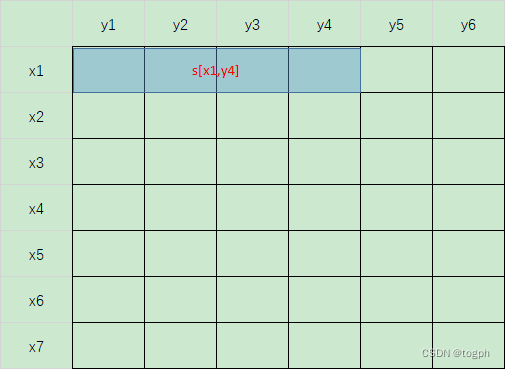
- 二维区间和: p r e f i x [ x 2 , y 2 , x 4 , y 4 ] = p r e f i x [ x 4 , y 4 ] − p r e f i x [ x 4 , y 1 ] − p r e f i x [ x 1 ] [ y 4 ] + p r e f i x [ x 1 , y 1 ] prefix[x2,y2,x4,y4] = prefix[x4,y4] - prefix[x4,y1] - prefix[x1][y4] + prefix[x1,y1] prefix[x2,y2,x4,y4]=prefix[x4,y4]−prefix[x4,y1]−prefix[x1][y4]+prefix[x1,y1]



class Prefixsum_arr:
def __init__(self):
N = 1010
self.prefix = [[0] * N for _ in range(N)]
def prefixsum(self,nums,n,m):
for i in range(1,n+1):
for j in range(1,m+1):
self.prefix[i][j] = self.prefix[i-1][j] + self.prefix[i][j-1] - self.prefix[i-1][j-1] + nums[i-1][j-1]
def main(self):
n,m,q = map(int,input().split())
nums = []
for i in range(n):
line = list(map(int,input().split()))
nums.append(line)
self.prefixsum(nums,n,m)
for j in range(q):
x1,y1,x2,y2 = map(int,input().split())
res = self.prefix[x2][y2] - self.prefix[x2][y1-1] - self.prefix[x1-1][y2] + self.prefix[x1-1][y1-1]
print(res)
if __name__ == '__main__':
prefixsum = Prefixsum_arr()
prefixsum.main()
差分
AcWing 797. 差分(一维差分)
输入一个长度为 n 的整数序列。
接下来输入 m 个操作,每个操作包含三个整数 l,r,c,表示将序列中 [l,r] 之间的每个数加上 c。
请你输出进行完所有操作后的序列。
输入格式
第一行包含两个整数 n 和 m。
第二行包含 n 个整数,表示整数序列。
接下来 m 行,每行包含三个整数 l,r,c,表示一个操作。
输出格式
共一行,包含 n 个整数,表示最终序列。
数据范围
1≤n,m≤100000,
1≤l≤r≤n,
−1000≤c≤1000,
−1000≤整数序列中元素的值≤1000
输入样例:
6 3
1 2 2 1 2 1
1 3 1
3 5 1
1 6 1
输出样例:
3 4 5 3 4 2
解析:
差分:可以看做是前缀和的逆运算,
给定一个原数组a:a[1],a[2],a[3]...a[n];
构造一个数组b:b[1],b[2],b[3]...b[i];
使得 a[i] = b[1] + b[2]+ b[3] +...+ b[i]
a数组就是b数组的前缀和,b数组就是a数组的差分数组
b数组构造方式如下:
a[0] = 0;
b[1] = a[1] - a[0];
b[2] = a[2] - a[1];
b[3] = a[3] - a[2];
...
b[n] = a[n] - a[n-1];
- 差分数组的作用:
- 给定区间
[l,r],让我们把a数组中的[l,r]区间中的每一个数都加上c,暴力做法需要对区间进行遍历,再对区间[l,r]增加一个c - 差分数组,只需要在
s[l] += c,s[r+1] -= c,就可使得原数组在区间[l,r]上增加c
class Differenc:
def __init__(self):
N = 100010
self.nums = [0] * N # 差分数组
def insert(self,l,r,c):
# 在差分数组区间l加上c,区间r+1减去c,使得原数组在区间[l,r]内增加c
self.nums[l] += c
self.nums[r+1] -= c
def main(self):
n,m = map(int,input().split())
nums = list(map(int,input().split()))
for i in range(1,n+1):
self.insert(i,i,nums[i-1]) # 求差分数组
for i in range(m):
l,r,c = map(int,input().split())
# 将差分数组的l位置增加c,r+1位置减去c
self.nums[l] += c
self.nums[r+1] -= c
for i in range(1,n+1):
# 对差分数组求一遍前缀和,得到原数组
self.nums[i] += self.nums[i-1]
print(self.nums[i],end=' ')
if __name__ == '__main__':
difference = Differenc()
difference.main()
AcWing 798. 差分矩阵(二维差分)
输入一个 n 行 m 列的整数矩阵,再输入 q 个操作,每个操作包含五个整数 x1,y1,x2,y2,c,其中 (x1,y1) 和 (x2,y2) 表示一个子矩阵的左上角坐标和右下角坐标。每个操作都要将选中的子矩阵中的每个元素的值加上 c。
请你将进行完所有操作后的矩阵输出。
输入格式
第一行包含整数 n,m,q。
接下来 n 行,每行包含 m 个整数,表示整数矩阵。
接下来 q 行,每行包含 5 个整数 x1,y1,x2,y2,c,表示一个操作。
输出格式
共 n 行,每行 m 个整数,表示所有操作进行完毕后的最终矩阵。
数据范围
1≤n,m≤1000,
1≤q≤100000,
1≤x1≤x2≤n,
1≤y1≤y2≤m,
−1000≤c≤1000,
−1000≤矩阵内元素的值≤1000
输入样例:
3 4 3
1 2 2 1
3 2 2 1
1 1 1 1
1 1 2 2 1
1 3 2 3 2
3 1 3 4 1
输出样例:
2 3 4 1
4 3 4 1
2 2 2 2
解析:
与一维差分数组类似,要使得特定区间a[x1,y1,x2,y2]内的值增加c,我们只需要在差分数组b[x1,y1] 加上c,b[x1,y2+1]减去c,b[x2+1,y1]减去c,b[x2+1,y2+1]加上c,再对差分数组求一遍前缀和,就可得到原数组的区间a[x1,y1,x2,y2]内的值增加c
b[x1][y1] += c;
b[x1][y2+1] -= c;
b[x2+1][y1] -= c;
b[x2+1][y2+1] += c;
class Difference2:
def __init__(self):
N = 1010
self.arr = [[0] * N for _ in range(N)] # 差分数组
def insert(self,x1,y1,x2,y2,c):
self.arr[x1][y1] += c
self.arr[x1][y2+1] -= c
self.arr[x2+1][y1] -= c
self.arr[x2+1][y2+1] += c
def main(self):
n, m, q = map(int,input().split())
for i in range(1,n+1):
nums = list(map(int,input().split()))
nums = [0] + nums
for j in range(1,m+1):
self.insert(i,j,i,j,nums[j])
for i in range(q):
x1, y1, x2, y2, c = map(int,input().split())
self.insert(x1,y1,x2,y2,c)
for i in range(1,n+1):
for j in range(1,m+1):
# 求二维数组的前缀和
self.arr[i][j] += (self.arr[i-1][j] + self.arr[i][j-1] - self.arr[i-1][j-1])
print(self.arr[i][j],end=' ')
print()
if __name__ == '__main__':
difference2 = Difference2()
difference2.main()
AcWing 799. 最长连续不重复子序列
给定一个长度为 n 的整数序列,请找出最长的不包含重复的数的连续区间,输出它的长度。
输入格式
第一行包含整数 n。
第二行包含 n 个整数(均在 0∼105 范围内),表示整数序列。
输出格式
共一行,包含一个整数,表示最长的不包含重复的数的连续区间的长度。
数据范围
1 ≤ n ≤ 1 0 5 1≤n≤10^5 1≤n≤105
输入样例:
5
1 2 2 3 5
输出样例:
3
思路:
- 定义两个指针i,j,i指针往右移动
- 开一个数组
count用于存放每个数出现的频次,以数组中每个数的值为索引,数组count中的值为这个数出现的频次 - 当这个数的频次大于1,就说明当前数出现了重复次数。并且出现重复次数是因为当前i指向的元素的加入
- 向右移动指针j,直到频次大于1的元素的频次降到1
class Double_pointer:
def __init__(self):
N = 100010
self.nums = [0] * N
def main(self):
n = int(input())
nums = list(map(int,input().split()))
j = res = 0
for i in range(n):
self.nums[nums[i]] += 1
while self.nums[nums[i]] > 1:
self.nums[nums[j]] -= 1
j += 1
res = max(res,i - j + 1)
print(res)
if __name__ == '__main__':
double = Double_pointer()
double.main()
AcWing 800. 数组元素的目标和
给定两个升序排序的有序数组 A 和 B,以及一个目标值 x。数组下标从 0 开始。
请你求出满足 A[i]+B[j]=x 的数对 (i,j)。
数据保证有唯一解。
输入格式
第一行包含三个整数 n,m,x,分别表示 A 的长度,B 的长度以及目标值 x。
第二行包含 n 个整数,表示数组 A。
第三行包含 m 个整数,表示数组 B。
输出格式
共一行,包含两个整数 i 和 j。
数据范围
数组长度不超过 1 0 5 10^5 105。
同一数组内元素各不相同。
1 ≤ 数组元素 ≤ 1 0 9 1≤数组元素≤10^9 1≤数组元素≤109
输入样例:
4 5 6
1 2 4 7
3 4 6 8 9
输出样例:
1 1
解析:
- 由于两个数组都是升序排列,可以定义两个指针i,j,指针i指向第一个数组的首位,j指向第二个数组的末尾
- 当i和j指向的两个数的和大于目标值,就将j向左移动一位
- 当i和j指向的两个数的和小于目标值,就将i向右移动一位
- 当i和j指向的两个数的和等于目标值,返回当前的i和j的值并结束循环
class Double_pointer2:
def main(self):
n, m, target = map(int,input().split())
nums1 = list(map(int,input().split()))
nums2 = list(map(int,input().split()))
i = 0
j = m - 1
while i < n and j >= 0:
if nums1[i] + nums2[j] == target:
print(i,j)
break
elif nums1[i] + nums2[j] > target:
j -= 1
else:i += 1
if __name__ == '__main__':
double2 = Double_pointer2()
double2.main()
AcWing 2816. 判断子序列
给定一个长度为 n 的整数序列 a 1 , a 2 , … , a n a_1,a_2,…,a_n a1,a2,…,an以及一个长度为 m 的整数序列 b 1 , b 2 , … , b m b_1,b_2,…,b_m b1,b2,…,bm。
请你判断 a 序列是否为 b 序列的子序列。
子序列指序列的一部分项按原有次序排列而得的序列,例如序列 a 1 , a 3 , a 5 {a_1,a_3,a_5} a1,a3,a5 是序列 a 1 , a 2 , a 3 , a 4 , a 5 {a_1,a_2,a_3,a_4,a_5} a1,a2,a3,a4,a5的一个子序列。
输入格式
第一行包含两个整数 n,m。
第二行包含 n 个整数,表示 a 1 , a 2 , … , a n a_1,a_2,…,a_n a1,a2,…,an。
第三行包含 m 个整数,表示 b 1 , b 2 , … , b m b_1,b_2,…,b_m b1,b2,…,bm。
输出格式
如果 a 序列是 b 序列的子序列,输出一行 Yes。
否则,输出 No。
数据范围
1 ≤ n ≤ m ≤ 1 0 5 , 1≤n≤m≤10^5, 1≤n≤m≤105,
− 1 0 9 ≤ a i , b i ≤ 1 0 9 −10^9≤a_i,b_i≤10^9 −109≤ai,bi≤109
输入样例:
3 5
1 3 5
1 2 3 4 5
输出样例:
Yes
解析:
- 定义两个指针i,j,分别指向两个数组的首位置
- 如果指针j指向的值与指针i指向的值相等,就将指针i向后移动一位
- 当j移动到数组末尾时,i的值等于子串长度时,匹配成功,否则匹配失败
class Double_pointer:
def main(self):
n, m = map(int,input().split())
nums1 = list(map(int,input().split()))
nums2 = list(map(int,input().split()))
i = 0
for j in range(m):
while i < n and nums2[j] == nums1[i]:
i+= 1
if i == n:print("Yes")
else:print("No")
if __name__ == '__main__':
dounle3 = Double_pointer()
dounle3.main()
位运算
AcWing 801. 二进制中1的个数
给定一个长度为 n 的数列,请你求出数列中每个数的二进制表示中 1 的个数。
输入格式
第一行包含整数 n。
第二行包含 n 个整数,表示整个数列。
输出格式
共一行,包含 n 个整数,其中的第 i 个数表示数列中的第 i 个数的二进制表示中 1 的个数。
数据范围
1≤n≤100000,
0 ≤ 数列中元素的值 ≤ 1 0 9 0≤数列中元素的值≤10^9 0≤数列中元素的值≤109
输入样例:
5
1 2 3 4 5
输出样例:
1 1 2 1 2
解析:
算法1:lowbit()
原码(x): 十进制数据的二进制表现形式就是原码,原码最左边的一个数字就是符号位,0为正,1为负。
反码(~x):正数的反码是其本身(等于原码),负数的反码是符号位保持不变,其余位取反。
补码(-x):正数的补码是其本身,负数的补码等于其反码 +1。因为反码不能解决负数跨零(类似于 -6 + 7)的问题,
所以补码出现了。
- lowbit计算二进制表示中的最低位的1的位置
原理:原码 & 补码 ,例如十进制12,原码为:0b1100;反码为:0b0100(即0b0011 + 1)
0b1100 & 0b0100 = 0b0100 - 计算x中1的个数,当x不为0时,每次循环减去一个lowbit(x),循环的次数就是x的二进制表示中1的个数
class Count1:
def lowbit(self,x):
"""
获取x的二进制中最低位1
:param x:
:return:
"""
return x & -x
def main(self):
n = int(input())
nums = list(map(int,input().split()))
for i in range(n):
res = 0
k = nums[i]
while k:
k -= self.lowbit(k)
res += 1
print(res,end=' ')
if __name__ == '__main__':
count1 = Count1()
count1.main()
class Count2:
def main(self):
n = int(input())
nums = list(map(int,input().split()))
for i in range(n):
res = 0
k = nums[i]
while k:
res += k & 1
k >>= 1
print(res,end=' ')
if __name__ == '__main__':
count2 = Count2()
count2.main()
离散化
AcWing 802. 区间和
假定有一个无限长的数轴,数轴上每个坐标上的数都是 0。
现在,我们首先进行 n 次操作,每次操作将某一位置 x 上的数加 c。
接下来,进行 m 次询问,每个询问包含两个整数 l 和 r,你需要求出在区间 [l,r] 之间的所有数的和。
输入格式
第一行包含两个整数 n 和 m。
接下来 n 行,每行包含两个整数 x 和 c。
再接下来 m 行,每行包含两个整数 l 和 r。
输出格式
共 m 行,每行输出一个询问中所求的区间内数字和。
数据范围
− 1 0 9 ≤ x ≤ 1 0 9 , −10^9≤x≤10^9, −109≤x≤109,
1 ≤ n , m ≤ 1 0 5 , 1≤n,m≤10^5, 1≤n,m≤105,
− 1 0 9 ≤ l ≤ r ≤ 1 0 9 , −10^9≤l≤r≤10^9, −109≤l≤r≤109,
− 10000 ≤ c ≤ 10000 −10000≤c≤10000 −10000≤c≤10000
输入样例:
3 3
1 2
3 6
7 5
1 3
4 6
7 8
输出样例:
8
0
5
解析:
- 将所有的插入和查询操作的索引值全部加入到一个索引数组中
- 对索引数组进行排序并去重,得到的新数组就是离散化后的数组
- 将插入操作和查询操作用一个二维数组存储,add数组存储的是每个插入操作的原始索引值和插入的数值,query数组存储的是每个查询操作的原始[l,r]值
- 开一个新的数组用来存放离散化后的值,这个值插入的位置就是离散化后的索引值对应的位置
- 查询操作处理类似,将查询操作的原始索引值转换为新的索引值,利用新的索引值在新的数组中去查找对应区间的值
- 离散化操作:由于离散化数组是排序去重的数组,存在单调性,可利用二分去查找大于等于当前值的第一个位置,查找出来的值可根据实际情况去确定是否需要做加1处理,这里由于是计算前缀和,前缀和的下标从1开始,所以这里将查询出来的下标直接加1
- 利用前缀和去计算区间和
class Discretization:
def __init__(self):
N = 300010 # 这里需要设置3倍空间,n次插入和m次查询的上界
self.add = []
self.query = []
self.alls_index = []
self.nums = [0] * N
self.prefix = [0] * N
def find(self,nums,x):
"""
查找离散化后,新的索引值
:param nums:离散化后的数组
:param x:需要查询的索引值
:return: 离散化后对应的新的索引值
"""
l = 0
r = len(nums) - 1
while l < r:
mid = l + r >> 1
if nums[mid] >= x:r = mid
else: l = mid + 1
return l + 1 # 由于计算的前缀和,所以索引需要从1开始,这里返回的索引值加上了1
def unique(self,nums):
"""
对数组进行排序并去重
:param nums: 待排序去重的数组
:return: 排序去重后的数组
"""
nums.sort()
i = 1
for j in range(1,len(nums)):
if nums[j] != nums[j-1]:
nums[i] = nums[j]
i += 1
return nums[:i]
def main(self):
n,m = map(int,input().split())
for i in range(n):
x,c = map(int,input().split())
self.add.append([x,c])
self.alls_index.append(x)
for j in range(m):
l,r = map(int,input().split())
self.query.append([l,r])
self.alls_index.append(l)
self.alls_index.append(r)
# 对所有的索引数组进行排序并去重
index = self.unique(self.alls_index)
# 处理插入操作,并将离散化后的值插入到新的数组nums中
for x,c in self.add:
new_x = self.find(index,x)
self.nums[new_x] += c
# 求一遍前缀和
for i in range(1,len(index)+1):
self.prefix[i] = self.prefix[i-1] + self.nums[i]
# 处理离散化后的区间和查询操作
for l,r in self.query:
new_l = self.find(index,l)
new_r = self.find(index,r)
print(self.prefix[new_r] - self.prefix[new_l-1])
if __name__ == '__main__':
discretization = Discretization()
discretization.main()
AcWing 803. 区间合并
给定 n 个区间 [ l i , r i ] [l_i,r_i] [li,ri],要求合并所有有交集的区间。
注意如果在端点处相交,也算有交集。
输出合并完成后的区间个数。
例如:
[1,3] 和 [2,6] 可以合并为一个区间 [1,6]。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含两个整数 l 和 r。
输出格式
共一行,包含一个整数,表示合并区间完成后的区间个数。
数据范围
1 ≤ n ≤ 100000 , 1≤n≤100000, 1≤n≤100000,
− 1 0 9 ≤ l i ≤ r i ≤ 1 0 9 −10^9≤l_i≤r_i≤10^9 −109≤li≤ri≤109
输入样例:
5
1 2
2 4
5 6
7 8
7 9
输出样例:
3
解析:
- 读取所有区间,对所有区间按左边界值进行从大到小排序
- 定义一个最小的边界值,来作为初始边界( e d = − 2 e 9 ed = -2e9 ed=−2e9)
- 依次遍历所有区间,当当前区间的左边界大于上一个区间的右边界时,说明两个区间不存在交点,就将当前区间加入到结果列表中
- 特判:如果ed未被更新过,说明区间为空
class Solution:
def main(self):
n = int(input())
zone = list()
for i in range(n):
line = list(map(int,input().split()))
zone.append(line)
zone.sort(key=lambda x:x[0])
# 定义一个初始右边界
ed = -2e9
res = []
for l,r in zone:
if l > ed:
# 如果当前区间的左端点小于上一个区间的右边界,
# 则说明两个区间不存在相交,将当前区间加入到结果列表中
ed = r
res.append([l,ed])
else:
# 如果两个区间相交,就取较大的右边界值取更新新的右边界
ed = max(ed,r)
if ed == -2e9:print(0) # 如果n=0,说明ed没有被更新过,直接返回0
else:print(len(res))
if __name__ == '__main__':
solution = Solution()
solution.main()
第二章 数据结构
单链表
AcWing 826. 单链表
实现一个单链表,链表初始为空,支持三种操作:
向链表头插入一个数;删除第 k 个插入的数后面的数;在第 k 个插入的数后插入一个数。现在要对该链表进行 M 次操作,进行完所有操作后,从头到尾输出整个链表。
注意:
题目中第 k 个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n 个数依次为:第 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:
H x,表示向链表头插入一个数 x。
D k,表示删除第 k 个插入的数后面的数(当 k 为 0 时,表示删除头结点)。
I k x,表示在第 k 个插入的数后面插入一个数 x(此操作中 k 均大于 0)。
输出格式
共一行,将整个链表从头到尾输出。
数据范围
1≤M≤100000
所有操作保证合法。
输入样例:
10
H 9
I 1 1
D 1
D 0
H 6
I 3 6
I 4 5
I 4 5
I 3 4
D 6
输出样例:
6 4 6 5
- 模板(C++)
// head存储链表头,e[]存储节点的值,ne[]存储节点的next指针,idx表示当前用到了哪个节点
int head, e[N], ne[N], idx;
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 在链表头插入一个数a
void insert(int a)
{
e[idx] = a, ne[idx] = head, head = idx ++ ;
}
// 将头结点删除,需要保证头结点存在
void remove()
{
head = ne[head];
}
- Python代码
class Solution:
def __init__(self):
N = 100010
self.e = [0] * N
self.ne = [0] * N
self.head = -1
self.idx = 1
def add_to_head(self,x):
"""
在头结点后面插入一个数
head --> -1
head --> x --> -1
:param x:
:return:
"""
self.e[self.idx] = x # 先存储需要插入的值
self.ne[self.idx] = self.head # 将当前节点的next指针指向头结点指向的节点
self.head = self.idx # 将头结点改向
self.idx += 1 # 将idx+1,说明当前节点已经被使用
def add_behind_k(self,k,x):
"""
在第k个节点后插入
head --> x1 --> k --> -1
head --> x1 --> k --> x --> -1
:param k:
:param x:
:return:
"""
self.e[self.idx] = x # 先存储需要插入的节点的值
self.ne[self.idx] = self.ne[k] # 将当前节点的next指针指向节点k指向的节点
self.ne[k] = self.idx # 将节点k的指向改向
self.idx += 1
def remove_k(self,k):
"""
head --> x1 --> k --> x2 --> x3 --> -1
head --> x1 --> k --> x3 --> -1
:param k:
:return:
"""
if k == 0:self.head = self.ne[self.head] # 如果k等于0,说明需要删除头结点
else:self.ne[k] = self.ne[self.ne[k]] # 删除节点k后面的节点就是将节点k的next指针指向next的next
def main(self):
M = int(input())
for i in range(M):
line = input().split()
if line[0] == "H":
x = int(line[1])
self.add_to_head(x)
elif line[0] == "I":
k,x = int(line[1]),int(line[2])
self.add_behind_k(k,x)
else:
k = int(line[1])
self.remove_k(k)
# 遍历链表,从链表的头结点开始遍历
idx = self.head
while ~idx: # 如果idx等于-1,说明已经遍历到节点末尾,则跳出循环
print(self.e[idx],end=' ')
idx = self.ne[idx] # 逐个移动节点
if __name__ == '__main__':
solution = Solution()
solution.main()
双链表
AcWing 827. 双链表
实现一个双链表,双链表初始为空,支持 5 种操作:
在最左侧插入一个数;
在最右侧插入一个数;
将第 k 个插入的数删除;
在第 k 个插入的数左侧插入一个数;
在第 k 个插入的数右侧插入一个数
现在要对该链表进行 M 次操作,进行完所有操作后,从左到右输出整个链表。
注意:
题目中第 k 个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n 个数依次为:第 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:
L x,表示在链表的最左端插入数 x。
R x,表示在链表的最右端插入数 x。
D k,表示将第 k 个插入的数删除。
IL k x,表示在第 k 个插入的数左侧插入一个数。
IR k x,表示在第 k 个插入的数右侧插入一个数。
输出格式
共一行,将整个链表从左到右输出。
数据范围
1≤M≤100000
所有操作保证合法。
输入样例:
10
R 7
D 1
L 3
IL 2 10
D 3
IL 2 7
L 8
R 9
IL 4 7
IR 2 2
输出样例:
8 7 7 3 2 9
- 模板(C++)
// e[]表示节点的值,l[]表示节点的左指针,r[]表示节点的右指针,idx表示当前用到了哪个节点
int e[N], l[N], r[N], idx;
// 初始化
void init()
{
//0是左端点,1是右端点
r[0] = 1, l[1] = 0;
idx = 2;
}
// 在节点a的右边插入一个数x
void insert(int a, int x)
{
e[idx] = x;
l[idx] = a, r[idx] = r[a];
l[r[a]] = idx, r[a] = idx ++ ;
}
// 删除节点a
void remove(int a)
{
l[r[a]] = l[a];
r[l[a]] = r[a];
}
- Python代码
class Solution:
def __init__(self):
N = 100010
self.e = [0] * N
self.left = [0] * N
self.right = [0] * N
self.left[1] = 0 # 初始化节点,节点0-->1; 0<--1;节点0表示头结点,节点1表示尾节点
self.right[0] = 1
self.idx = 2 # 0和1已经占用两个节点,所以idx从2开始
def add_right_behind_k(self,k,x):
"""
在节点k的右边插入节点
0 --> x1 --> k --> 1
0 <-- x1 <-- k <-- 1
0 --> x1 --> k --> x --> 1
0 <-- x1 <-- k <-- x <-- 1
:param k: 在节点k后面插入节点
:param x: 插入的节点的值
:return:
"""
self.e[self.idx] = x # 先将当前节点的值存储
self.right[self.idx] = self.right[k] # 当前节点的右指针指向节点k的右节点
self.left[self.idx] = k # 当前节点的左指针指向节点k
self.left[self.right[k]] = self.idx # 节点k的右节点的左指针指向当前节点
self.right[k] = self.idx #节点k的右指针指向当前节点
self.idx += 1
def remove(self,k):
"""
删除第k个插入的节点
1 --> x1 --> k --> x2 --> 0
1 <-- x1 <-- k <-- x2 <-- 0
:param k:
:return:
"""
# 将节点k的左边的节点的右指针指向节点k的右节点
# 将节点k的右边的节点的左指针指向节点k的左节点
self.right[self.left[k]] = self.right[k]
self.left[self.right[k]] = self.left[k]
def main(self):
m = int(input())
for i in range(m):
line = input().split()
op = line[0]
if op == "L":
x = int(line[1])
self.add_right_behind_k(0,x)
elif op == "R":
x = int(line[1])
self.add_right_behind_k(self.left[1], x)
elif op == "D":
# 由于插入的时候idx是从2开始的,所以节点k需要+1
k = int(line[1]) + 1
self.remove(k)
elif op == "IL":
k,x = int(line[1]) + 1,int(line[2])
self.add_right_behind_k(self.left[k],x)
else:
k, x = int(line[1]) + 1, int(line[2])
self.add_right_behind_k(k, x)
# 取出头结点的右指针,依次遍历节点,当遍历到节点为1时,说明已经遍历到链表的末尾
idx = self.right[0]
while idx != 1:
print(self.e[idx],end=' ')
idx = self.right[idx]
if __name__ == '__main__':
solution = Solution()
solution.main()
栈
AcWing 828. 模拟栈
实现一个栈,栈初始为空,支持四种操作:
push x – 向栈顶插入一个数 x;
pop – 从栈顶弹出一个数;
empty – 判断栈是否为空;
query – 查询栈顶元素。
现在要对栈进行 M 个操作,其中的每个操作 3 和操作 4 都要输出相应的结果。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令为 push x,pop,empty,query 中的一种。
输出格式
对于每个 empty 和 query 操作都要输出一个查询结果,每个结果占一行。
其中,empty 操作的查询结果为 YES 或 NO,query 操作的查询结果为一个整数,表示栈顶元素的值。
数据范围
1 ≤ M ≤ 100000 , 1≤M≤100000, 1≤M≤100000,
1 ≤ x ≤ 1 0 9 1≤x≤10^9 1≤x≤109
所有操作保证合法。
输入样例:
10
push 5
query
push 6
pop
query
pop
empty
push 4
query
empty
输出样例:
5
5
YES
4
NO
- 模板(C++)
int stk[N], tt = 0; // tt表示栈顶
stk[ ++ tt] = x; // 向栈顶插入一个数
tt -- ; // 从栈顶弹出一个数
stk[tt]; // 栈顶的值
if (tt > 0) // 判断栈是否为空,如果 tt > 0,则表示不为空
{
}
- python代码
class Stack:
def __init__(self):
N = 100010
self.tt = -1 # 定义一个指针,指向-1
self.stack = [0] * N
def push(self,x):
self.tt += 1 # 先移动指针,再将值加入到栈中
self.stack[self.tt] = x
def pop(self):
self.tt -= 1 # 从栈顶弹出一个元素
def empty(self):
if self.tt < 0 :return "YES" # 如果指针小于0,说明栈为空
else: return "NO"
def query(self):
return self.stack[self.tt] # tt指向的值就是栈顶元素
def main(self):
M = int(input())
for i in range(M):
line = input().split()
op = line[0]
if op == "push":
x = int(line[1])
self.push(x)
elif op == "pop":
self.pop()
elif op == "empty":
print(self.empty())
else:
print(self.query())
if __name__ == '__main__':
stack = Stack()
stack.main()
AcWing 3302. 表达式求值
给定一个表达式,其中运算符仅包含 +,-,*,/(加 减 乘 整除),可能包含括号,请你求出表达式的最终值。
注意:
- 数据保证给定的表达式合法。
- 题目保证符号
-只作为减号出现,不会作为负号出现,例如,-1+2,(2+2)*(-(1+1)+2)之类表达式均不会出现。 - 题目保证表达式中所有数字均为正整数。
- 题目保证表达式在中间计算过程以及结果中,均不超过 2 31 − 1 2^{31−1} 231−1。
- 题目中的整除是指向 0 取整,也就是说对于大于 00 的结果向下取整,例如 5/3=1,对于小于 0 的结果向上取整,例如 5/(1−4)=−1。
- C++和Java中的整除默认是向零取整;Python中的整除
//默认向下取整,因此Python的eval()函数中的整除也是向下取整,在本题中不能直接使用。
输入格式
共一行,为给定表达式。
输出格式
共一行,为表达式的结果。
数据范围
表达式的长度不超过 1 0 5 10^5 105。
输入样例:
(2+2)*(1+1)
输出样例:
8
def cacl(nums,ops):
"""
:param nums: 数值栈,存放中缀表达式中的数值
:param ops: 运算符栈,存放中缀表达式中的运算符
:return: None
"""
b = nums.pop() # 栈中弹出的第一个元素为操作的第二个元素
a = nums.pop() # 栈中弹出的第二个元素为操作的第一个元素
c = ops.pop() # 弹出运算符
if c == "+":x = a + b
elif c == "-":x = a - b
elif c == "*": x = a * b
else:x = int(a / b)
nums.append(x) # 将运算结果添加到栈中
def main():
weight = {'+':1,'-':1,'*':2,'/':2} # 定义运算符优先级权重
nums = [] # 定义一个栈存放数值
ops = [] # 定义一个栈存放运算符
s = input()
i = 0
while i < (len(s)):
ch = s[i]
if ch.isdigit(): # 如果当前位置是数值
x = 0
j = i
while j < len(s) and s[j].isdigit(): # 循环获取当前位置的相邻数值
x = x * 10 + int(s[j])
j += 1
i = j - 1 # 退出循环时需要将j所在的位置赋值给i,由于i在最后还会再+1,所以此处需要将j的值-1
nums.append(x) # 将获取到的数值添加到栈中
elif ch == '(':ops.append(ch) # 如果当前遍历到左括号,就将左括号入栈
elif ch == ')': # 遍历到右括号就需要将栈中左括号后的元素进行计算
while ops[-1] != '(': # 如果栈顶不为左括号,则需要继续进行计算
cacl(nums,ops)
ops.pop() # 计算完成后栈顶为左括号,需要将左括号弹出
else:
# 如果运算符栈不为空,且栈顶不为左括号,栈顶符号的权重值大于等于入栈符号的权重值,则将栈顶取出进行计算
while (len(ops) and ops[-1] != '(' and weight[ops[-1]] >= weight[ch]):
cacl(nums,ops)
ops.append(ch) # 计算完成后将元算符入栈
i += 1
while len(ops): # 如果运算符栈不为空,循环遍历计算
cacl(nums,ops)
print(nums[-1])
main()
队列
AcWing 829. 模拟队列
实现一个队列,队列初始为空,支持四种操作:
push x – 向队尾插入一个数 x;
pop – 从队头弹出一个数;
empty – 判断队列是否为空;
query – 查询队头元素。
现在要对队列进行 M 个操作,其中的每个操作 3 和操作 4 都要输出相应的结果。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令为 push x,pop,empty,query 中的一种。
输出格式
对于每个 empty 和 query 操作都要输出一个查询结果,每个结果占一行。
其中,empty 操作的查询结果为 YES 或 NO,query 操作的查询结果为一个整数,表示队头元素的值。
数据范围
1 ≤ M ≤ 100000 , 1≤M≤100000, 1≤M≤100000,
1 ≤ x ≤ 1 0 9 , 1≤x≤10^9, 1≤x≤109,
所有操作保证合法。
输入样例:
10
push 6
empty
query
pop
empty
push 3
push 4
pop
query
push 6
输出样例:
NO
6
YES
4
- 模板(C++)
- 普通队列
int q[N], hh = 0, tt = -1; // hh 表示队头,tt表示队尾
q[ ++ tt] = x; // 向队尾插入一个数
hh ++ ; // 从队头弹出一个数
q[hh]; // 队头的值
if (hh <= tt) // 判断队列是否为空,如果 hh <= tt,则表示不为空
{
}
- 循环队列
int q[N], hh = 0, tt = 0; // hh 表示队头,tt表示队尾的后一个位置
q[tt ++ ] = x; // 向队尾插入一个数
if (tt == N) tt = 0; // 当队尾指针移动到末尾位置时,将队尾指针重头开始移动
hh ++ ; // 从队头弹出一个数
if (hh == N) hh = 0;
q[hh]; // 队头的值
if (hh != tt) // 判断队列是否为空,如果hh != tt,则表示不为空
{
}
class Queue:
def __init__(self):
N = 100010
self.que = [0] * N
self.hh = 0 # 队首指针
self.tt = -1 # 队尾指针
def push(self,x):
"""
向队尾加入一个元素
:param x:
:return:
"""
self.tt += 1
self.que[self.tt] = x
def pop(self):
self.hh += 1 # 从队首弹出一个元素
def empty(self):
if self.hh <= self.tt:return "NO" #如果hh指针小于等于tt指针,说明队列中还存在元素
else:return "YES"
def query(self):
return self.que[self.hh] # 查询队首元素
def main(self):
M = int(input())
for i in range(M):
line = input().split()
op = line[0]
if op == "push":
x = int(line[1])
self.push(x)
elif op == "pop":
self.pop()
elif op == "empty":
print(self.empty())
else:
print(self.query())
if __name__ == '__main__':
que = Queue()
que.main()
单调栈
AcWing 830. 单调栈
给定一个长度为 N 的整数数列,输出每个数左边第一个比它小的数,如果不存在则输出 −1。
输入格式
第一行包含整数 N,表示数列长度。
第二行包含 N 个整数,表示整数数列。
输出格式
共一行,包含 N 个整数,其中第 i 个数表示第 i 个数的左边第一个比它小的数,如果不存在则输出 −1。
数据范围
1 ≤ N ≤ 1 0 5 1≤N≤10^5 1≤N≤105
1 ≤ 数列中元素 ≤ 1 0 9 1≤数列中元素≤10^9 1≤数列中元素≤109
输入样例:
5
3 4 2 7 5
输出样例:
-1 3 -1 2 2
// 常见模型:找出每个数左边离它最近的比它大/小的数
int tt = 0;
for (int i = 1; i <= n; i ++ )
{
while (tt && check(stk[tt], i)) tt -- ;
stk[ ++ tt] = i;
}
- 解析:
- 找到每个数左边第一个比它小的数
- 利用单调栈,当栈顶元素的值大于当前元素的值就将栈顶元素弹出
- 如果栈为空,则说明当前数的左侧不存在比当前值小的数
- 打印栈顶元素
- 将当前值加入到栈中
class Stack:
def __init__(self):
N = 100010
self.stack = [0] * N
self.tt = 0
def main(self):
n = int(input())
nums = list(map(int,input().split()))
for i in range(n):
while self.tt and self.stack[self.tt] >= nums[i]:self.tt -= 1
if not self.tt:print(-1,end=' ') # 栈为空,当前数左侧不存在比当前数小的数
else:print(self.stack[self.tt],end=' ') # 栈不为空,栈顶就是比当前值小的数
self.tt += 1 # 将当前值入栈
self.stack[self.tt] = nums[i]
if __name__ == '__main__':
stack = Stack()
stack.main()
单调队列
AcWing 154. 滑动窗口
给定一个大小为 n ≤ 1 0 6 n≤10^6 n≤106 的数组。
有一个大小为 k 的滑动窗口,它从数组的最左边移动到最右边。
你只能在窗口中看到 k 个数字。
每次滑动窗口向右移动一个位置。
以下是一个例子:
该数组为 [1 3 -1 -3 5 3 6 7],k 为 3。
| 窗口位置 | 最小值 | 最大值 |
|---|---|---|
| [1 3 -1] -3 5 3 6 7 | -1 | 3 |
| 1 [3 -1 -3] 5 3 6 7 | -3 | 3 |
| 1 3 [-1 -3 5] 3 6 7 | -3 | 5 |
| 1 3 -1 [-3 5 3] 6 7 | -3 | 5 |
| 1 3 -1 -3 [5 3 6] 7 | 3 | 6 |
| 1 3 -1 -3 5 [3 6 7] | 3 | 7 |
你的任务是确定滑动窗口位于每个位置时,窗口中的最大值和最小值。
输入格式
输入包含两行。
第一行包含两个整数 n 和 k,分别代表数组长度和滑动窗口的长度。
第二行有 n 个整数,代表数组的具体数值。
同行数据之间用空格隔开。
输出格式
输出包含两个。
第一行输出,从左至右,每个位置滑动窗口中的最小值。
第二行输出,从左至右,每个位置滑动窗口中的最大值。
输入样例:
8 3
1 3 -1 -3 5 3 6 7
输出样例:
-1 -3 -3 -3 3 3
3 3 5 5 6 7
- 模板(C++)
// 常见模型:找出滑动窗口中的最大值/最小值
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}
- Python代码
class Sliding:
def getmax(self):
"""
单调递减队列
:return:
"""
N = 1000010
hh = 0
tt = -1
que = [0] * N
for i in range(self.n):
# 当队列不为空,并且队列的队首坐标值小于窗口大小,需要将队首元素滑出窗口
if hh <= tt and que[hh] < i - self.k + 1:hh += 1
# 当队列不为空,队尾索引值对应的元素小于等于当前元素值,就将队尾弹出
while hh <= tt and self.nums[que[tt]] <= self.nums[i]: tt -= 1
# 将当前索引加入到队列中
tt += 1
que[tt] = i
# 如果i大于等于窗口宽度,队首索引对饮的元素就是当前窗口中的最大值
if i >= self.k -1:print(self.nums[que[hh]],end = ' ')
def getmin(self):
N = 1000010
hh = 0
tt = -1
que = [0] * N
for i in range(self.n):
if hh <= tt and que[hh] < i - self.k + 1: hh += 1
while hh <= tt and self.nums[que[tt]] >= self.nums[i]: tt -= 1
tt += 1
que[tt] = i
if i >= self.k - 1: print(self.nums[que[hh]], end=' ')
def main(self):
self.n,self.k = map(int,input().split())
self.nums = list(map(int,input().split()))
self.getmin()
print()
self.getmax()
if __name__ == '__main__':
sliding = Sliding()
sliding.main()
KMP算法
AcWing 831. KMP字符串
给定一个字符串 S,以及一个模式串 P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模式串 P 在字符串 S 中多次作为子串出现。
求出模式串 P 在字符串 S 中所有出现的位置的起始下标。
输入格式
第一行输入整数 N,表示字符串 P 的长度。
第二行输入字符串 P。
第三行输入整数 M,表示字符串 S 的长度。
第四行输入字符串 S。
输出格式
共一行,输出所有出现位置的起始下标(下标从 0 开始计数),整数之间用空格隔开。
数据范围
1 ≤ N ≤ 1 0 5 1≤N≤10^5 1≤N≤105
1 ≤ M ≤ 1 0 6 1≤M≤10^6 1≤M≤106
输入样例:
3
aba
5
ababa
输出样例:
0 2
- 解析
- 核心思想:当模式串P与模板串S进行匹配时,发生不匹配的情况后,模式串最多能够回退到什么位置进行下一次匹配
- next数组:记录模式串中每个坐标对应的最长公共前后缀长度
- 求next数组:
// 计算next数组,模式串长度为n,计算下标从2开始
for (int i = 2, j = 0; i <= n; i ++ )
{ // 当j不为0时,i与j+1不匹配就将j回退
while (j && p[i] != p[j + 1]) j = ne[j];
// 匹配后就将j向后移动一位
if (p[i] == p[j + 1]) j ++ ;
// 用next[i]记录当前j走到了哪里
ne[i] = j;
}
class KMP:
def __init__(self):
N = 100010
self.ne = [0] * N # 存储next数组
def calne(self,str):
"""
计算next数组
:param str: str模式串的下标从1开始
:return:
"""
j = 0
for i in range(2,len(str)): # 模式串从下标为2开始(下标为2表示子串长度为2,长度为1时不存在前后缀)
# 当j不为0,如果模式串的第i位和j+1不匹配,就将j回退到ne[j]
while j and str[i] != str[j+1]:j = self.ne[j]
# 如果第i位和第j+1位匹配,就将j向后移动一位
if str[i] == str[j+1]: j +=1
# next[i] 记录的是当前j已经走到哪里了 // 记录最长公共前后缀的长度
self.ne[i] = j
def main(self):
n = int(input())
p = '0' + input() # 将模式串和匹配串下标都从1开始
m = int(input())
s = '0' + input()
self.calne(p)
j = 0
# 匹配时,下标也从1开始
for i in range(1,m+1):
while j and s[i] != p[j+1]: j = self.ne[j]
if s[i] == p[j+1]:j += 1
if j == n: # 当j匹配到末尾时,说明已经完成一轮匹配,输出当前匹配的初始坐标
print(i - j,end=' ')
j = self.ne[j] # 将j移动到next[j]的位置开始下一轮匹配
if __name__ == '__main__':
kmp = KMP()
kmp.main()
Trie
- 高效的存储和查找字符串集合的数据结构
self.son[p][cur]: 表示当前节点的子节点- 插入操作时:如果当前节点不存在子节点,就进行插入,如果存在就将p移动到
self.son[p][cur]
AcWing 835. Trie字符串统计
维护一个字符串集合,支持两种操作:
I x 向集合中插入一个字符串 x;
Q x 询问一个字符串在集合中出现了多少次。
共有 N 个操作,所有输入的字符串总长度不超过 1 0 5 10^5 105,字符串仅包含小写英文字母。
输入格式
第一行包含整数 N,表示操作数。
接下来 N 行,每行包含一个操作指令,指令为 I x 或 Q x 中的一种。
输出格式
对于每个询问指令 Q x,都要输出一个整数作为结果,表示 x 在集合中出现的次数。
每个结果占一行。
数据范围
1 ≤ N ≤ 2 ∗ 1 0 4 1≤N≤2∗10^4 1≤N≤2∗104
输入样例:
5
I abc
Q abc
Q ab
I ab
Q ab
输出样例:
1
0
1
- 模板
int son[N][26], cnt[N], idx;
// 0号点既是根节点,又是空节点
// son[][]存储树中每个节点的子节点
// cnt[]存储以每个节点结尾的单词数量
// 插入一个字符串
void insert(char *str)
{
int p = 0; // 从根节点开始遍历
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx; // 如果当前节点不存在就加入到trie树中
p = son[p][u]; // 插入完成后将节点p移动到当前节点
}
cnt[p] ++ ; // 记录当前字符串的末尾位置
}
// 查询字符串出现的次数
int query(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) return 0; // 如果当前字母不在trie树中就直接返回0
p = son[p][u];
}
return cnt[p];
}
- Python代码
class Trie:
def __init__(self):
N = 100010
self.son = [[0] * 26 for _ in range(N)] # trie树
self.idx = 0 # 标记当前字母存储到哪个节点
self.cnt = [0] * N # 标记当前字母是否是单词结尾字母
def insert(self,strs):
"""
向trie树中插入一个字符串
:param strs:
:return:
"""
n = len(strs)
p = 0 # 从根节点开始遍历。根节点为0
for i in range(n):
cur = ord(strs[i]) - ord('a') # 遍历字符串中的每个字符,并转换为Unicode
if not self.son[p][cur]: # 如果当前字符不存在trie树中,就将当前字符加入到trie树中
self.idx += 1
self.son[p][cur] = self.idx # trie树中加入当前节点
p = self.son[p][cur] # 移动遍历节点p
self.cnt[p] += 1 # 当前字符串遍历完成后,标记结尾字符
def query(self,strs):
"""
查询trie树中是否存在字符串strs
:param strs:
:return:
"""
n = len(strs)
p = 0
for i in range(n):
cur = ord(strs[i]) - ord('a')
if not self.son[p][cur]:return 0 # 如果查询到当前字符不存在trie树中,直接return 0
p = self.son[p][cur] # 移动当前节点
return self.cnt[p]
def main(self):
n = int(input())
for i in range(n):
line = input().split()
op = line[0]
strs = line[1]
if op == "I":self.insert(strs)
else:
res = self.query(strs)
print(res)
if __name__ == '__main__':
trie = Trie()
trie.main()
AcWing 143. 最大异或对
在给定的 N 个整数 A 1 , A 2 … … A N A_1,A_2……A_N A1,A2……AN中选出两个进行 xor(异或)运算,得到的结果最大是多少?
输入格式
第一行输入一个整数 N。
第二行输入 N 个整数 A 1 ~ A N A_1~A_N A1~AN。
输出格式
输出一个整数表示答案。
数据范围
1 ≤ N ≤ 1 0 5 , 1≤N≤10^5, 1≤N≤105,
0 ≤ A i < 2 3 1 0≤Ai<2^31 0≤Ai<231
输入样例:
3
1 2 3
输出样例:
3
class Trie2:
def __init__(self):
N = 31 * 100010 # 一共存储节点数为31 * 100000个(最大为31位,最多为100000个数)
self.son = [[0] * 2 for _ in range(N)] # 每个节点存储两个子节点,0/1,1表示当前位为1
self.idx = 0 # 节点索引,类似链表中的self.idx
def insert(self,x):
p = 0 # 从根节点开始遍历
# 从高位到地位进行存储,求异或值最大,位数越高异或值越大
for i in range(31,-1,-1):
cur = (x >> i & 1) # 取出当前位的二进制值
if not self.son[p][cur]: # 将当前位的值存储到trie树中
self.idx += 1
self.son[p][cur] = self.idx
p = self.son[p][cur]
def query(self,x):
p = 0
res = 0
for i in range(31,-1,-1):
cur = (x >> i & 1)
if self.son[p][cur ^ 1]: # 如果存在与当前位异或的值,就取当前位的异或
res += (1 << i) # res 加上当前位的值(实际值等于将1左移i位)
p = self.son[p][cur ^ 1] # 将节点p移动到异或分支
else:
p = self.son[p][cur]
return res
def main(self):
n = int(input())
nums = list(map(int,input().split()))
res = 0
for i in range(n):
self.insert(nums[i])
for j in range(n):
res = max(res,self.query(nums[j]))
print(res)
if __name__ == '__main__':
trie2 = Trie2()
trie2.main()
并查集
- 将两个集合合并
- 查询两个元素是否在一个集合中
- 特点:
- 将每个集合用一个树形结构来维护
- 每个集合的编号是根节点的编号
- 对于每一个点都存储当前节点的父节点是谁
- 查询当前节点属于哪一个集合:先找到它的父节点,如果它的父节点不是根节点就继续往上找,直到找到根节点
- 初始化每个节点的父节点都指向自身
- 如何判断是否是根节点:p[x] == x
- 如何求集合的编号:while p[x] != x: x = p[x]
- 如何合并连个集合:px是集合x的编号,py是集合y的编号,p[x] = y就可将两个集合合并
AcWing 836. 合并集合
一共有 n 个数,编号是 1∼n,最开始每个数各自在一个集合中。
现在要进行 m 个操作,操作共有两种:
M a b,将编号为 a 和 b 的两个数所在的集合合并,如果两个数已经在同一个集合中,则忽略这个操作;
Q a b,询问编号为 a 和 b 的两个数是否在同一个集合中;
输入格式
第一行输入整数 n 和 m。
接下来 m 行,每行包含一个操作指令,指令为 M a b 或 Q a b 中的一种。
输出格式
对于每个询问指令 Q a b,都要输出一个结果,如果 a 和 b 在同一集合内,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1 ≤ n , m ≤ 1 0 5 1≤n,m≤10^5 1≤n,m≤105
输入样例:
4 5
M 1 2
M 3 4
Q 1 2
Q 1 3
Q 3 4
输出样例:
Yes
No
Yes
class Solution:
def __init__(self):
N = 100010
self.p = [i for i in range(N)]
def find(self,x):
"""
查找当前节点属于哪个集合
:param x:
:return:
"""
if x != self.p[x]:
self.p[x] = self.find(self.p[x])
return self.p[x]
def main(self):
n,m = map(int,input().split())
for i in range(m):
line = input().split()
op = line[0]
a = int(line[1])
b = int(line[2])
fa = self.find(a)
fb = self.find(b)
if op == "M":
if fa != fb:self.p[fa] = fb
else:
if fa == fb:print("Yes")
else:print("No")
if __name__ == '__main__':
solution = Solution()
solution.main()
AcWing 837. 连通块中点的数量
- 维护每个集合中 点的数量:在合并的时候合并两个根节点的节点数即可:
size[find(b)] += size[find(a)]
给定一个包含 n 个点(编号为 1∼n)的无向图,初始时图中没有边。
现在要进行 m 个操作,操作共有三种:
C a b,在点 a 和点 b 之间连一条边,a 和 b 可能相等;
Q1 a b,询问点 a 和点 b 是否在同一个连通块中,a 和 b 可能相等;
Q2 a,询问点 a 所在连通块中点的数量;
输入格式
第一行输入整数 n 和 m。
接下来 m 行,每行包含一个操作指令,指令为 C a b,Q1 a b 或 Q2 a 中的一种。
输出格式
对于每个询问指令 Q1 a b,如果 a 和 b 在同一个连通块中,则输出 Yes,否则输出 No。
对于每个询问指令 Q2 a,输出一个整数表示点 a 所在连通块中点的数量
每个结果占一行。
数据范围
1 ≤ n , m ≤ 1 0 5 1≤n,m≤10^5 1≤n,m≤105
输入样例:
5 5
C 1 2
Q1 1 2
Q2 1
C 2 5
Q2 5
输出样例:
Yes
2
3
class Solution:
def __init__(self):
N = 100010
self.p = [i for i in range(N)] # 初始化每个节点的父节点都指向自身
self.size = [1] * N # 初始化设置每个集合都包含自身一个节点
def find(self,x):
if x != self.p[x]:
self.p[x] = self.find(self.p[x])
return self.p[x]
def main(self):
n,m = map(int,input().split())
for i in range(m):
line = input().split()
op = line[0]
if op == "C":
a = int(line[1])
b = int(line[2])
if a == b:continue #如果a和b相等,跳出当前循环
fa = self.find(a)
fb = self.find(b)
if fa != fb:
self.p[fa] = self.p[fb]
# 额外维护每个集合中的节点数,当两个节点不属于同一个集合的时候,就将两个集合的节点数在合并的时候累加
self.size[fb] += self.size[fa]
elif op == "Q1":
a = int(line[1])
b = int(line[2])
fa = self.find(a)
fb = self.find(b)
if fa != fb:print("No")
else:print("Yes")
else:
a = int(line[1])
fa = self.find(a)
print(self.size[fa])
if __name__ == '__main__':
solution = Solution()
solution.main()
AcWing 240. 食物链
- 维护每个节点到根节点的距离
int find(int x)
{
if (p[x] != x)
{
int t = find(p[x]);
d[x] += d[p[x]]; // 路径压缩过程中不断维护当前节点到根节点的距离
p[x] = t;
}
return p[x];
}
动物王国中有三类动物 A,B,C,这三类动物的食物链构成了有趣的环形。
A 吃 B,B 吃 C,C 吃 A。
现有 N 个动物,以 1∼N 编号。
每个动物都是 A,B,C 中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这 N 个动物所构成的食物链关系进行描述:
第一种说法是 1 X Y,表示 X 和 Y 是同类。
第二种说法是 2 X Y,表示 X 吃 Y。
此人对 N 个动物,用上述两种说法,一句接一句地说出 K 句话,这 K 句话有的是真的,有的是假的。
当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
当前的话与前面的某些真的话冲突,就是假话;
当前的话中 X 或 Y 比 N 大,就是假话;
当前的话表示 X 吃 X,就是假话。
你的任务是根据给定的 N 和 K 句话,输出假话的总数。
输入格式
第一行是两个整数 N 和 K,以一个空格分隔。
以下 K 行每行是三个正整数 D,X,Y,两数之间用一个空格隔开,其中 D 表示说法的种类。
若 D=1,则表示 X 和 Y 是同类。
若 D=2,则表示 X 吃 Y。
输出格式
只有一个整数,表示假话的数目。
数据范围
1≤N≤50000,
0≤K≤100000
输入样例:
100 7
1 101 1
2 1 2
2 2 3
2 3 3
1 1 3
2 3 1
1 5 5
输出样例:
3
class Solution:
def __init__(self):
N = 100010
self.p = [i for i in range(N)]
self.dis = [0] * N # 存储每个节点到根节点的距离
def find(self,x):
if x != self.p[x]:
fx = self.find(self.p[x])
self.dis[x] += self.dis[self.p[x]]
self.p[x] = fx
return self.p[x]
def main(self):
n,k = map(int,input().split())
res = 0
for i in range(k):
op,a,b = map(int,input().split())
if a > n or b > n:res += 1
else:
fa = self.find(a)
fb = self.find(b)
if op == 1:
# 性质1:a,b到根节点的距离同余3
# 如果a和b在同一个集合中,判断a和b到根的距离是否同余3
if fa == fb and (self.dis[a] - self.dis[b]) % 3:
res += 1
elif fa != fb:
self.p[fa] = fb
self.dis[fa] = self.dis[b] - self.dis[a]
else:
if fa == fb and (self.dis[a] - self.dis[b] - 1) % 3:
res += 1
elif fa != fb:
self.p[fa] = fb
self.dis[fa] = self.dis[b] - self.dis[a] + 1 # 节点合并的时候更新每个节点到根节点的距离
print(res)
if __name__ == '__main__':
solution = Solution()
solution.main()
堆
- 堆的特点:小根堆:根节点小于等于它的子节点;大根堆:根节点大于等于它的子节点
- 堆的存储:可用一维数组存储堆,堆是一颗完全二叉树
- 手写小根堆的up(x)操作:如果当前节点的值小于根节点的值,就交换当前节点的值与根节点的值
- 手写小根堆的down(x)操作:如果当前节点的值大与它的子节点的值,就将当前节点的值与三个节点中最小的值交换
- 堆的几个常见操作:
| 序号 | 操作 | 实现 |
|---|---|---|
| 1 | 插入一个数x | heap[++size] = x;up(size) |
| 2 | 求堆中的最小值 | heap[1] |
| 3 | 删除堆中的最小值 | heap[1] = heap[size];size --;down(1) |
| 4 | 删除堆中的任意一个元素 | heap[k] = heap[size];size --;up(k);down(k) |
| 5 | 修改任意一个元素 | heap[k] = x;up(k);down(k) |
- 删除堆中的一个元素,先将需要删除的元素与堆的末尾元素交换位置,再将堆的size–,执行一遍down和up操作;这里down和up操作至多只会执行一个
AcWing 838. 堆排序
输入一个长度为 n 的整数数列,从小到大输出前 m 小的数。
输入格式
第一行包含整数 n 和 m。
第二行包含 n 个整数,表示整数数列。
输出格式
共一行,包含 m 个整数,表示整数数列中前 m 小的数。
数据范围
1 ≤ m ≤ n ≤ 1 0 5 , 1≤m≤n≤10^5, 1≤m≤n≤105,
1 ≤ 数列中元素 ≤ 1 0 9 1≤数列中元素≤10^9 1≤数列中元素≤109
输入样例:
5 3
4 5 1 3 2
输出样例:
1 2 3
class Heap:
def __init__(self):
N = 100010
self.heap = [0] * N
def down(self,x):
"""
:param x:
:return:
"""
# 找到当前三个节点的最小值
mini = x
# 如果存在左子节点,如果左子节点小于根节点的值,就将最小节点的索引记为左子结点
if x * 2 <= self.idx and self.heap[mini] > self.heap[x * 2]: mini = x * 2
if x * 2 + 1 <= self.idx and self.heap[mini] > self.heap[x * 2 + 1]: mini = x * 2 + 1
if x != mini: # 如果x不是最小节点,就进行交换
self.heap[mini],self.heap[x] = self.heap[x], self.heap[mini] # 交换后,节点x达到稳定状态
self.down(mini) # 递归堆原来最小的节点进行down
def create(self,n):
"""
建堆:从n/2位置开始建堆,可以在O(n)时间复杂度建堆
:param n:
:return:
"""
cnt = n >> 1
for i in range(cnt,0,-1):
self.down(i) # 对n/2 - 0的所有节点进行一遍down操作,得到的堆就是小根堆
def main(self):
n,m = map(int,input().split())
nums = list(map(int,input().split()))
for i in range(1,n+1):
self.heap[i] = nums[i-1]
self.idx = n
self.create(self.idx)
for j in range(m):
res = self.heap[1] # 取出堆顶元素,堆顶元素就是当前堆的最小值
print(res,end=' ')
self.heap[1],self.heap[self.idx] = self.heap[self.idx],self.heap[1]
self.idx -= 1
self.down(1)
if __name__ == '__main__':
heap = Heap()
heap.main()
AcWing 839. 模拟堆
维护一个集合,初始时集合为空,支持如下几种操作:
I x,插入一个数 x;PM,输出当前集合中的最小值;DM,删除当前集合中的最小值(数据保证此时的最小值唯一);D k,删除第 k个插入的数;C k x,修改第 k个插入的数,将其变为 x;
现在要进行 N 次操作,对于所有第 2 个操作,输出当前集合的最小值。
输入格式
第一行包含整数 N。
接下来 N 行,每行包含一个操作指令,操作指令为 I x,PM,DM,D k 或 C k x 中的一种。
输出格式
对于每个输出指令 PM,输出一个结果,表示当前集合中的最小值。
每个结果占一行。
数据范围
1 ≤ N ≤ 1 0 5 1≤N≤10^5 1≤N≤105
− 1 0 9 ≤ x ≤ 1 0 9 −10^9≤x≤10^9 −109≤x≤109
数据保证合法。
输入样例:
8
I -10
PM
I -10
D 1
C 2 8
I 6
PM
DM
输出样例:
-10
6
- 理解hp与ph数组,以及为什么需要它们
- 堆h[i]只能存放数据,不能存放当前数字是第几个插入的数,所以需要ph[k] = i来指明,第k个数字在h[]中的索引值为i
- 在执行交换操作的时候,可以直接交换数字,swap(h[a],h[b])
但是对于 p h [ k 1 ] = a 和 p h [ k 2 ] = b ph[k_1] = a和ph[k_2] = b ph[k1]=a和ph[k2]=b来说,a和b是它们存放的值,不 能通过值来找下标,也就是找不k_1,k_2是多少 - 于是引入hp[a] = k_2,hp[b] = k_2,则可以实现反向的操作
- 形象理解heap_swap中的次序是任意的
h[]:房间号无直接实际意义,里边住着犯人
ph[]:花名册,狱警所有,写明了几号犯人住在哪个房间号里,用于抓某些人
(但是狱警无权过问每个号里住的是谁)
hp[]:住户册,监狱所有,写明了哪个房间号里住的是几号,用于管理监狱
(但是监狱没必要知道哪个犯人住在哪里)
heap_swap:已知两个犯人住的地方,交换它们住的地方,并且让狱警和管理 处都知道这件事情
swap(h[a], h[b]):两个人换地方住
swap(hp[a], hp[b]):监狱管理处翻房间号,把里边存放的犯人号交换
swap(ph[hp[a]], ph[hp[b]]):狱警:先申请查住户册,看这两个地方住的谁,再在花名册下写下来,这两个人位置换了
h[a] = 10, h[b] = 20 swap: h[a] = 20,h [b] = 10
hp[a] = 1 ,hp[b] = 2 swap:hp[a] = 2 ,hp[b] = 1
ph[1] = a ,ph[2] = b swap:ph[1] = b ,ph[2] = a
//这种不变形也很像线代中:代表交换的初等矩阵,进行逆运算之后,仍然是该初等矩阵
class heap:
def main(self):
n = int(input())
self.heap = [0] * 100010 # 记录堆中的元素
self.hp = [0] * 100010 # 记录堆中元素到第几个插入的映射
self.ph = [0] * 100010 # 记录第几个插入的元素到堆的映射
self.cnt = 0 # 记录堆中的位置
self.idx = 0 # 记录第几个插入的元素
for i in range(n):
line = input().split()
op = line[0]
if op == 'I':
u = int(line[1])
self.cnt += 1
self.idx += 1
self.ph[self.idx] = self.cnt
self.hp[self.cnt] = self.idx
self.heap[self.cnt] = u
self.up(self.cnt) # 将元素插入到对的最后一个位置,并进行up操作
elif op == 'PM':
print(self.heap[1])
elif op == 'DM':
self.swap(1,self.cnt) # 删除堆中的堆顶元素:将堆顶元素与堆尾元素交换,将堆大小减一
self.cnt -= 1
self.down(1) # 交换后对堆顶元素进行down操作
elif op == 'D':
k = int(line[1]) # 要删除的第k个元素
hk = self.ph[k] # 获取这个元素在堆中的索引
self.swap(hk,self.cnt)
self.cnt -= 1
self.down(hk)
self.up(hk)
else:
k,x = int(line[1]),int(line[2])
hk = self.ph[k]
self.heap[hk] = x
self.down(hk)
self.up(hk)
def down(self,x):
t = x
if 2*x <= self.cnt and self.heap[t] > self.heap[2*x]:t = 2*x
if 2*x+1 <= self.cnt and self.heap[t] > self.heap[2*x+1]:t=2*x+1
if t != x:
self.swap(t,x)
self.down(t)
def up(self,x):
while x >> 1 and self.heap[x] < self.heap[x >> 1]:
self.swap(x,x>>1)
x >>=1
def swap(self,u,t):
self.ph[self.hp[u]],self.ph[self.hp[t]] = self.ph[self.hp[t]],self.ph[self.hp[u]]
self.hp[u],self.hp[t] = self.hp[t],self.hp[u]
self.heap[u],self.heap[t] = self.heap[t],self.heap[u]
if __name__ == '__main__':
heap = heap()
heap.main()
哈希表
- 存储结构:开放寻址法、拉链法
- 作用,将一个比较大的范围的数映射到一个比较小的范围;如 [ − 1 0 9 , 1 0 9 ] [-10^9,10^9] [−109,109],映射到 [ 0 , 1 0 5 ] [0,10^5] [0,105]
- 哈希冲突:两个数被映射到同一个地址上
- 解决哈希冲突的方法:开放寻址法和拉链法
- 拉链法:
- 通过哈希函数将一个值映射到一个地址上
- 这个地址上存储一个单链表
- 如果出现了哈希冲突,就在链表上在增加一个元素
- 拉链法:
class Hash:
def __init__(self):
N = 100003 # 取大于n的第一个质数,降低哈希碰撞的概率
self.h = [-1] * N
self.e = [0] * N
self.ne = [0] * N
self.idx = 0
self.n = N
def insert(self,x):
k = (x % self.n + self.n)% self.n # 计算哈希值,通过哈希值索引到一个地址上
self.e[self.idx] = x # 将这个值存储到链表中
self.ne[self.idx] = self.h[k]
self.h[k] = self.idx
self.idx += 1
def query(self,x):
k = (x % self.n + self.n)% self.n
idx = self.h[k]
while ~idx:
if self.e[idx] == x:return "Yes"
idx = self.ne[idx]
return "No"
def main(self):
n = int(input())
for i in range(n):
line = input().split()
op = line[0]
x = int(line[1])
if op == "I":self.insert(x)
else:print(self.query(x))
if __name__ == '__main__':
hash = Hash()
hash.main()
2. 开放寻址法:
1. 只开一个数组,这个数组的长度一般来说是n的2-3倍
2. 处理冲突,如果计算得到的哈希值指到的地址上存在元素,就从前往后逐个找,直到某个地址上不存在元素
3. 添加:先查找哈希值计算得到的地址上是否存在元素,如果存在就从前往后找,直到找到一个没有元素的地址
4. 查找:先找到哈希值计算得到的地址上,如果当前值与查找的值相等,就找到元素,如果直到找到空位置还没找到需要查找的值,就不存在这个元素
class HASH:
def __init__(self):
N = 200003
self.hash = [float('inf')] * N # 初始化每个地址上存储的值为一个值域之外的值
self.n = N
def find(self,x):
k = (x % self.n + self.n) % self.n
while self.hash[k] != float('inf') and self.hash[k] != x:
k += 1
if k == self.n:k = 0 # 如果k到了最后一个位置,就从0继续开始查找
return k # 如果x存在哈希表中就返回在哈希表中的位置,如果不存在就返回可以插入的位置
def main(self):
n = int(input())
for i in range(n):
line = input().split()
op = line[0]
x = int(line[1])
k = self.find(x)
if op == "I":self.hash[k] = x
else:
if self.hash[k] == x:
print("Yes")
else:print("No")
if __name__ == '__main__':
hash = HASH()
hash.main()
-
字符串哈希:
-
将一个字符串看成一个P进制的数
-
将这个P进制的字符串转换为十进制的数
-
将这个P进制的数对Q取模,计算后的哈希值范围就是[0,Q-1]
-
注意: 1. 不能字符映射成0;2. 假定不存在哈希冲突
- 经验值:
P = 131 或者13331时,Q = 2 64 2^{64} 264,99.99%的概率下不会存在哈希冲突
- 经验值:
-
计算区间[l,r]的哈希值时,只需要查询出h[r]和h[l-1]的哈希值
- h [ r ] = P r − 1 h[r] = P^{r-1} h[r]=Pr−1
- h [ l − 1 ] = P l − 2 h[l-1] = P^{l-2} h[l−1]=Pl−2
- 将两个哈希值进行位数对齐: h [ l − 1 ] ∗ P r − l + 1 h[l-1] * P^{r - l + 1} h[l−1]∗Pr−l+1
- 将对齐后的哈希值相减得到: h [ r ] − h [ l − 1 ] ∗ P r − l + 1 = h [ r − l ] h[r] - h[l-1] * P^{r-l+1} = h[r-l] h[r]−h[l−1]∗Pr−l+1=h[r−l]
- 例如:h[r] = ABCD的哈希值;h[l-1] = AB的哈希值;将h[l-1]与h[r]进行位数对齐后得到AB00,将两个哈希值相减,就得到CD的哈希值
-
AcWing 841. 字符串哈希
给定一个长度为 n的字符串,再给定 m个询问,每个询问包含四个整数 l1,r1,l2,r2,请你判断 [l1,r1]和 [l2,r2] 这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式
第一行包含整数 n 和 m,表示字符串长度和询问次数。
第二行包含一个长度为 n的字符串,字符串中只包含大小写英文字母和数字。
接下来 m行,每行包含四个整数 l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从 11 开始编号。
输出格式
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1 ≤ n , m ≤ 1 0 5 1≤n,m≤10^5 1≤n,m≤105
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
class Hash:
def __init__(self):
N = 100010
self.hash = [0] * N # 存放字符串的前缀哈希值
self.p = [0] * N # 预处理p^n
self.p[0] = 1 # 初始化p[0] = 1; 即P^0 = 1
self.q = 13331 # 经验值 131 或 13331
self.mod = 1 << 64 # 将计算后的值映射到[0,2^64-1]
def insert(self,strs):
"""
计算字符串的前缀哈希值
:param strs:
:return:
"""
n = len(strs)
for i in range(n):
self.hash[i+1] = (self.hash[i] * self.q + ord(strs[i])) % self.mod
self.p[i+1] = self.p[i] * self.q % self.mod
def query(self,left,right):
return (self.hash[right] - self.hash[left - 1] * self.p[right - left + 1]) % self.mod
def main(self):
n,m = map(int,input().split())
strs = input()
self.insert(strs)
for i in range(m):
l1,r1,l2,r2 = map(int,input().split())
h1 = self.query(l1,r1)
h2 = self.query(l2,r2)
if h1 == h2:print("Yes")
else:print("No")
if __name__ == '__main__':
hash = Hash()
hash.main()
第三章 搜索与图论
DFS
AcWing 842. 排列数字
给定一个整数 n,将数字 1∼n排成一排,将会有很多种排列方法。
现在,请你按照字典序将所有的排列方法输出。
输入格式
共一行,包含一个整数 n。
输出格式
按字典序输出所有排列方案,每个方案占一行。
数据范围
1≤n≤7
输入样例:
3
输出样例:
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
class DFS:
def __init__(self):
N = 10
self.res = []
self.isuesd = [0] * N
def dfs(self,u):
if u == self.n: # u表示当前遍历到的层数,如果遍历到第n层,就输出结果并return
print(" ".join(self.res))
return
for i in range(1,self.n+1):
if not self.isuesd[i]:
self.res.append(str(i))
self.isuesd[i] = 1 # 将当前位标记为已经使用过
self.dfs(u+1) # 进行下一层递归遍历
self.res.pop() # 回溯
self.isuesd[i] = 0
def main(self):
self.n = int(input())
self.dfs(0)
if __name__ == '__main__':
dfs = DFS()
dfs.main()
AcWing 843. n-皇后问题
n−皇后问题是指将 n 个皇后放在 n×n 的国际象棋棋盘上,使得皇后不能相互攻击到,即任意两个皇后都不能处于同一行、同一列或同一斜线上。
现在给定整数 n,请你输出所有的满足条件的棋子摆法。
输入格式
共一行,包含整数 n。
输出格式
每个解决方案占 n行,每行输出一个长度为 n 的字符串,用来表示完整的棋盘状态。
其中 . 表示某一个位置的方格状态为空,Q 表示某一个位置的方格上摆着皇后。
每个方案输出完成后,输出一个空行。
注意:行末不能有多余空格。
输出方案的顺序任意,只要不重复且没有遗漏即可。
数据范围
1≤n≤9
输入样例:
4
输出样例:
.Q..
...Q
Q...
..Q.
..Q.
Q...
...Q
.Q..
第一种搜索顺序
class DFS1:
def __init__(self):
N = 20
self.g = [['.'] * N for _ in range(N)]
self.col = [0] * N # 记录当前列是否摆放了皇后
self.dg = [0] * N # 记录右斜对角线是否摆放了皇后
self.udg = [0] * N # 记录左斜对角线是否摆放了皇后
def dfs(self,u):
if u == self.n: # 遍历到最后一行,就输出答案
for i in range(self.n):
print(''.join(self.g[i][:self.n]))
return
for i in range(self.n): # 逐列遍历
# 如果当前位置所在列,所在左斜对角线右斜对角线都未摆放皇后,则可摆放皇后
if not self.col[i] and not self.dg[u + i] and not self.udg[i-u+self.n]:
self.g[u][i] = 'Q'
# 将当前位置三个方向标记为已经摆放皇后
self.col[i] = self.dg[u+i] = self.udg[i-u+self.n] = 1
self.dfs(u+1) # 递归下一行进行遍历
# 回溯
self.col[i] = self.dg[u+i] = self.udg[i-u + self.n] = 0
self.g[u][i] = '.'
def main(self):
self.n = int(input())
self.dfs(0)
if __name__ == '__main__':
dfs = DFS1()
dfs.main()
第二种搜索顺序
class DFS2:
def __init__(self):
N = 20
self.a = [['.'] * N for _ in range(N)]
self.col = [0] * N # 存储当前列是否放皇后
self.row = [0] * N # 存储当前行是否放皇后
self.dg = [0] * N # 存储左对角线是否放皇后
self.udg = [0] * N # 存储右对角线是否放皇后
def dfs(self,x,y,s):
"""
摆放到[x,y]坐标为止,摆放了多少个皇后
:param x:
:param y:
:param s:
:return:
"""
if y == self.n: y = 0 ; x += 1 # 如果y移动到每行的末尾,就将y跳到0位置,并将行数+1
if x == self.n: # 如果移动到最后一行,就需要return
if s == self.n: # 移动到最后一行,并且放置的皇后数量为n,就输出当前放置的方案
for i in range(self.n):
print(''.join(self.a[i][:self.n]))
print()
return
# 当前位置摆放皇后,当前行、列、左右对角线均不能摆放皇后
if not self.col[y] and not self.row[x] and not self.dg[x+y] and not self.udg[y-x+self.n]:
self.a[x][y] = 'Q'
self.col[y] = self.row[x] = self.dg[x+y] = self.udg[y-x+self.n] = 1
self.dfs(x+1,0,s+1)
# 回溯
self.a[x][y] = '.'
self.col[y] = self.row[x] = self.dg[x + y] = self.udg[y - x + self.n] = 0
# 当前位置不摆放皇后
self.dfs(x, y + 1, s)
def main(self):
self.n = int(input())
self.dfs(0,0,0)
if __name__ == '__main__':
dfs = DFS2()
dfs.main()
BFS
AcWing 844. 走迷宫
给定一个 n×m的二维整数数组,用来表示一个迷宫,数组中只包含 0 或 1,其中 0 表示可以走的路,1 表示不可通过的墙壁。
最初,有一个人位于左上角 (1,1) 处,已知该人每次可以向上、下、左、右任意一个方向移动一个位置。
请问,该人从左上角移动至右下角 (n,m)处,至少需要移动多少次。
数据保证 (1,1)处和 (n,m)处的数字为 0,且一定至少存在一条通路。
输入格式
第一行包含两个整数 n 和 m。
接下来 n行,每行包含 m个整数(0 或 1),表示完整的二维数组迷宫。
输出格式
输出一个整数,表示从左上角移动至右下角的最少移动次数。
数据范围
1≤n,m≤100
输入样例:
5 5
0 1 0 0 0
0 1 0 1 0
0 0 0 0 0
0 1 1 1 0
0 0 0 1 0
输出样例:
8
class BFS:
def main(self):
self.path = [] # 存放输入的矩阵值
self.n,self.m = list(map(int,input().split())) # 记录矩阵的行数和列数
self.d = [[-1] * self.m for _ in range(self.n)] # 定义一个矩阵,用于存放当前所有可以到达的点到起点的最小步数
self.d[0][0] = 0 # 初始化起点到自身的距离为0
for i in range(self.n):
line = list(map(int, input().split()))
self.path.append(line)
self.bfs()
def bfs(self):
self.que = [[0,0]] # 起点为(0,0)
self.vector = [[-1,0],[1,0],[0,-1],[0,1]] # 定义一个向量,表示当前点延展的四个方向
while self.que != []: # 逐层进行遍历
cur_node = self.que.pop(0) # 从队列队首弹出一个坐标来向四个方向扩展
for ve in self.vector:
new_x = cur_node[0] + ve[0]
new_y = cur_node[1] + ve[1]
# 1. 扩展的新坐标点必须不能越界
# 2. 新坐标对应的点必须要是没有到达过的点(通过距离矩阵来区分)
# 3. 新坐标对应的点不能为障碍
if 0 <= new_x < self.n and 0 <= new_y < self.m and self.d[new_x][new_y] == -1 and self.path[new_x][new_y] != 1:
self.que.append([new_x,new_y]) # 将符合要求的点加入到队列中
self.d[new_x][new_y] = self.d[cur_node[0]][cur_node[1]] + 1 # 更新距离矩阵中的新坐标到起点的最小距离
print(self.d[self.n-1][self.m-1]) # 打印最右下角的点的距离即为从起点到终点的最小步数
if __name__ == '__main__':
bfs = BFS()
bfs.main()
AcWing 845. 八数码
在一个 3×3 的网格中,1∼8 这 8 个数字和一个 x 恰好不重不漏地分布在这 3×3 的网格中。
例如:
1 2 3
x 4 6
7 5 8
在游戏过程中,可以把 x 与其上、下、左、右四个方向之一的数字交换(如果存在)。
我们的目的是通过交换,使得网格变为如下排列(称为正确排列):
1 2 3
4 5 6
7 8 x
例如,示例中图形就可以通过让 x 先后与右、下、右三个方向的数字交换成功得到正确排列。
交换过程如下:
1 2 3 1 2 3 1 2 3 1 2 3
x 4 6 4 x 6 4 5 6 4 5 6
7 5 8 7 5 8 7 x 8 7 8 x
现在,给你一个初始网格,请你求出得到正确排列至少需要进行多少次交换。
输入格式
输入占一行,将 3×3 的初始网格描绘出来。
例如,如果初始网格如下所示:
1 2 3
x 4 6
7 5 8
则输入为:1 2 3 x 4 6 7 5 8
输出格式
输出占一行,包含一个整数,表示最少交换次数。
如果不存在解决方案,则输出 −1。
输入样例:
2 3 4 1 5 x 7 6 8
输出样例
19
- 思路:
- 状态保存:将二维矩阵的每个状态用一个字符串保存
- 距离保存:用一个字典存储当前状态被扩展到的步数,键为状态,值为扩展步数
- 状态转移:查找x在当前状态字符串中的索引值,x // 3得到x在矩阵中的横坐标值,x % 3得到x在矩阵中的纵坐标值
- 状态计算:新的状态通过四个方向向量计算,计算后的状态需要满足:不能越界;新的状态如果是被扩展过,就不能加入到队列中,也不能进行距离的更新(越早扩展到的状态,扩展的步数越少)
from collections import deque
class Solution:
def __init__(self):
self.dis = dict()
self.vec = [[-1,0],[1,0],[0,-1],[0,1]]
def swap(self,str,x1,x2):
"""
交换字符串中x1位置和x2位置的字符
:param str:
:param x1: 索引x1
:param x2: 索引x2
:return: 交换后的字符串
"""
res = list(str)
res[x1],res[x2] = res[x2],res[x1]
return ''.join(res)
def bfs(self,start):
que = deque([start]) # 初始化队列,将start加入到队列中
self.dis[start] = 0 # 初始化start的距离为1
while que: # 当队列不为空,弹出队首元素,逐层遍历
cur = que.popleft()
idx = cur.find("x") # 找到x所在的索引值
if cur == "12345678x": # 如果得到end值就跳出遍历
return self.dis["12345678x"]
x = idx // 3 # 将x的索引值转换为二维坐标值
y = idx % 3
for i in range(4):
new_x = x + self.vec[i][0]
new_y = y + self.vec[i][1]
if 0 <= new_x < 3 and 0 <= new_y < 3:
new_idx = new_x * 3 + new_y
newstr = self.swap(cur,idx,new_idx)
if newstr not in self.dis: # 如果新的字符串没有被遍历过,就将新的字符串加入到距离字典中
self.dis[newstr] = self.dis[cur] + 1
que.append(newstr) # 新的字符串同时加到队列中
return -1
def main(self):
strs = ''.join(input().split())
res = self.bfs(strs)
print(res)
if __name__ == '__main__':
bfs = Solution()
bfs.main()
树与图的深度优先遍历
AcWing 846. 树的重心
给定一颗树,树中包含 n 个结点(编号 1∼n)和 n−1 条无向边。
请你找到树的重心,并输出将重心删除后,剩余各个连通块中点数的最大值。
重心定义:重心是指树中的一个结点,如果将这个点删除后,剩余各个连通块中点数的最大值最小,那么这个节点被称为树的重心。
输入格式
第一行包含整数 n,表示树的结点数。
接下来 n−1 行,每行包含两个整数 a和 b,表示点 a 和点 b 之间存在一条边。
输出格式
输出一个整数 m,表示将重心删除后,剩余各个连通块中点数的最大值。
数据范围
1 ≤ n ≤ 1 0 5 1≤n≤10^5 1≤n≤105
输入样例
9
1 2
1 7
1 4
2 8
2 5
4 3
3 9
4 6
输出样例:
4

- 思路:
- 递归遍历当前节点的相邻节点
- 递归过程中统计以当前节点为根节点的子节点数
- 由于递归过程只会从上往下遍历,所以当前节点的上面这个连通块数量需要单独计算
- 当前节点子树的大小:递归过程中比较,记录下最大的子树大小
- 当前节点上面连通块的大小:总的节点数 - 当前节点所有子树大小 - 1
class Solution:
def __init__(self):
N = 200010
self.visited = [0] * N # 记录当前点是否被访问过
# 邻接表存储树
self.e = [0] * N
self.h = [-1] * N
self.ne = [0] * N
self.idx = 0
# 记录最大连通块的最小值
self.res = N
def add(self,a,b):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.h[a] = self.idx
self.idx += 1
def dfs(self,u):
self.visited[u] = 1 # 标记当前节点被访问过
res = 0 # 表示以u的子树的大小(只保留最大的子树的大小)
sums = 1 # 当前以u为根节点的节点数
idx = self.h[u] # 遍历邻接表
while ~idx:
cur = self.e[idx]
idx = self.ne[idx]
if not self.visited[cur]: # 如果当前节点没被遍历过,就进行递归处理
s = self.dfs(cur) # 递归返回的节点是当前节点的子节点大小
res = max(res,s) # 更新子节点的大小
sums += s # 更新当前节点的节点数(包含根节点)
root = max(res,self.n - sums) # 更新另外连通块的大小
self.res = min(root,self.res)
return sums
def main(self):
self.n = int(input())
for i in range(self.n-1):
a,b = map(int,input().split())
self.add(a,b)
self.add(b,a)
self.dfs(1)
print(self.res)
if __name__ == '__main__':
dfs = Solution()
dfs.main()
树与图的广度优先遍历
AcWing 847. 图中点的层次
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环。
所有边的长度都是 1,点的编号为 1∼n。
请你求出 1号点到 n 号点的最短距离,如果从 1 号点无法走到 n 号点,输出 −1。
输入格式
第一行包含两个整数 n 和 m。
接下来 m 行,每行包含两个整数 a 和 b,表示存在一条从 a走到 b 的长度为 1 的边。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。
数据范围
1 ≤ n , m ≤ 1 0 5 1≤n,m≤10^5 1≤n,m≤105
输入样例:
4 5
1 2
2 3
3 4
1 3
1 4
输出样例:
1
- 思路:
- 由于边权重都为1,所以可用宽度有限搜索来计算最短路
- 初始每个点到起点的距离(dis数组)都为-1,方便判断当前节点是否被更新过
- 用邻接表存储树
- 宽度优先遍历:
- 初始化先将起点加入到队列,当队列不为空,逐个进行遍历
- 遍历到的节点都是当前节点的邻边
- 如果被遍历到的点到起点的距离没有被更新过,就更新新的节点到起点的距离
- 并将这个点加入到队列中
- 虽然题目给定的存在重边和自环,但是在更新距离的时候判断了当前点到起点的距离是否被更新过,所以即使存在重边和自环,也不会对距离的更新产生影响
class Solution:
def __init__(self):
N = 100010
self.dis = [-1] * N # 记录每个点到起点的最小距离
# 邻接表
self.e = [0] * N
self.ne = [0] * N
self.h = [-1] * N
self.idx = 0
# 数组模拟队列
self.que = [0] * N
self.hh = 0
self.tt = -1
def add(self,a,b):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.h[a] = self.idx
self.idx += 1
def insert(self,x):
"""
向队列中插入一个元素
:param x:
:return:
"""
self.tt += 1
self.que[self.tt] = x
def bfs(self):
self.insert(1) # 初始化向队列中插入起始节点1
self.dis[1] = 0 # 初始化起始节点到自身的距离为0
while self.hh <= self.tt: # 队列不空
cur = self.que[self.hh] # 取出队头元素
self.hh += 1
idx = self.h[cur] # 遍历队头元素的相邻节点
while ~idx:
a = self.e[idx]
if self.dis[a] == -1: # 遍历到的节点距离没有被更新过的话,就更新这个节点
self.dis[a] = self.dis[cur] + 1 # 更新节点到起始节点的距离
self.insert(a) # 将这个节点插入到队列中
idx = self.ne[idx]
return self.dis[self.n]
def main(self):
self.n,m = map(int,input().split())
for i in range(m):
a,b = map(int,input().split())
self.add(a,b)
res = self.bfs()
print(res)
if __name__ == '__main__':
solution = Solution()
solution.main()
拓扑排序
-
拓扑序: “拓扑排序”(topological sort)指在一个称为“有向无环图”中给出了顶点的线性顺序。对于每个有向边 a --> b,顶点“a”先于顶点“b”。
-
入度:指向这个点的边的数量
-
出度:这个点出去的边的数量
-
一个有向无环图至少有一个入度为0的顶点和一个出度为0的顶点。
-
思路:
- 找到所有入度为0的点,加入到队列中
- 逐个遍历队列中的点a
- 取出队列中的点a,遍历这个点的所有邻边b
- 删掉a指向b的边(即:将b的入度减一)
- 如果b的入度变为0,就将b加入到队列中
- 队列中保存的数组就是当前有向无环图的一个topo序
- 如果加入队列中的点的数量大于图中的点数,说明这个图不是有向无环图 \color{red} {如果加入队列中的点的数量大于图中的点数,说明这个图不是有向无环图} 如果加入队列中的点的数量大于图中的点数,说明这个图不是有向无环图
AcWing 848. 有向图的拓扑序列
给定一个 n 个点 m 条边的有向图,点的编号是 1 到 n,图中可能存在重边和自环。
请输出任意一个该有向图的拓扑序列,如果拓扑序列不存在,则输出 −1。
若一个由图中所有点构成的序列 A 满足:对于图中的每条边 (x,y),x 在 A 中都出现在 y 之前,则称 A 是该图的一个拓扑序列。
输入格式
第一行包含两个整数 n 和 m。
接下来 m 行,每行包含两个整数 x 和 y,表示存在一条从点 x 到点 y 的有向边 (x,y)。
输出格式
共一行,如果存在拓扑序列,则输出任意一个合法的拓扑序列即可。否则输出 −1−1。
数据范围
1 ≤ n , m ≤ 1 0 5 1≤n,m≤10^5 1≤n,m≤105
输入样例:
3 3
1 2
2 3
1 3
输出样例:
1 2 3
class Toposort:
def __init__(self):
N = 100010
self.d = [0] * N # 初始化每个节点的入度为0
# 邻接表
self.e = [0] * N
self.ne = [0] * N
self.h = [-1] * N
self.idx = 0
# 数组模拟队列
self.que = [0] * N
self.hh = 0
self.tt = -1
def add(self,a,b):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.h[a] = self.idx
self.idx += 1
def insert(self,x):
self.tt += 1
self.que[self.tt] = x
def bfs(self):
# 遍历一遍,找到入度为0的点加入到队列中
for i in range(1,self.n+1):
if self.d[i] == 0:
self.insert(i)
while self.hh <= self.tt:
cur = self.que[self.hh]
self.hh += 1
idx = self.h[cur]
while ~idx:
x = self.e[idx]
self.d[x] -= 1
if self.d[x] == 0:
self.insert(x)
idx = self.ne[idx]
if self.tt == self.n-1:
for i in range(self.n):
print(self.que[i],end=' ')
else:
print('-1')
def main(self):
self.n, m = map(int,input().split())
for i in range(m):
a,b = map(int,input().split())
self.add(a,b)
self.d[b] += 1
self.bfs()
if __name__ == '__main__':
toposort = Toposort()
toposort.main()
图论
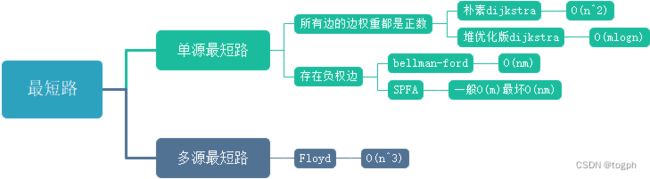
朴素dijkstra
- 初始化一个数组st,用来存放已经确定最短路的点
- 初始化一个数组dist,用来存放每个点到起点的最小距离,每个点初始到起点的距离都为正无穷
- 初始化节点1到自身的距离为0
- 遍历所有节点,每次能找到一个距离最短的点,所以n次遍历能找到所有点到起点的最短距离
- 找到当前未确定最短距离的点中的距离最小的点t
- 遍历t能到达的所有点b,判断t的加入能否更新点b到起点的距离
- 将点t加入到数组st中
- 注意:如果起点不能到达节点n,那么dist[n]一定是正无穷
AcWing 849. Dijkstra求最短路 I
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,所有边权均为正值。
请你求出 1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 −1。
输入格式
第一行包含整数 n 和 m。
接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。
如果路径不存在,则输出 −1。
数据范围
1 ≤ n ≤ 500 , 1≤n≤500, 1≤n≤500,
1 ≤ m ≤ 1 0 5 , 1≤m≤10^5, 1≤m≤105,
图中涉及边长均不超过10000。
输入样例:
3 3
1 2 2
2 3 1
1 3 4
输出样例:
3
class Dijkstra:
def __init__(self):
N = 510
self.arr = [[float('inf')] * N for _ in range(N)] # 稠密图用邻接矩阵存储
self.dist = [float('inf')] * N # 每个点到起点的最短距离
self.st = [0] * N # 记录这个点是否确定最短距离
def dijkstra(self):
self.dist[1] = 0 # 初始化起点到自身的距离为0
for _ in range(self.n):
# 找到所有点中距离最小的点
t = -1
for i in range(1,self.n+1):
if not self.st[i] and (t == -1 or self.dist[t] > self.dist[i]):
t = i
# 看这个点是否能够更新其他点到起点的距离
for j in range(1,self.n+1):
self.dist[j] = min(self.dist[j],self.dist[t] + self.arr[t][j])
self.st[t] = 1
if self.dist[self.n] != float("inf"):print(self.dist[self.n])
else:print(-1)
def main(self):
self.n,m = map(int,input().split())
for i in range(m):
a,b,c = map(int,input().split())
self.arr[a][b] = min(self.arr[a][b],c)
self.dijkstra()
if __name__ == '__main__':
dijkstra = Dijkstra()
dijkstra.main()
堆优化版dijkstra
- 使用小根堆存储每个节点到起点的距离,小根堆堆顶即为未确定最短路的点中到起点距离最小的点
- 当堆不为空,说明还存在没确定最短路的点
- 弹出堆顶元素a,并逐个遍历a的所有邻边b
- 判断a的加入,能否更新节点b到起点的距离
- 如果可以更新节点b的最短距离,就将节点b加入到堆中
- 循环结束后将节点a加入到数组st中
- 注意:这里不用判断重边和自环,重边和自环在计算的时候会被自动取到最小的值 \color {red} {注意:这里不用判断重边和自环,重边和自环在计算的时候会被自动取到最小的值} 注意:这里不用判断重边和自环,重边和自环在计算的时候会被自动取到最小的值
AcWing 850. Dijkstra求最短路 II
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,所有边权均为非负值。
请你求出 1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 −1。
输入格式
第一行包含整数 n 和 m。
接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。
如果路径不存在,则输出 −1。
数据范围
1 ≤ n , m ≤ 1.5 × 1 0 5 1≤n,m≤1.5×10^5 1≤n,m≤1.5×105
图中涉及边长均不小于 0,且不超过 10000。
数据保证:如果最短路存在,则最短路的长度不超过 1 0 9 10^9 109。
输入样例:
3 3
1 2 2
2 3 1
1 3 4
输出样例:
3
import heapq
class Dijkstra:
def __init__(self):
N = 200010
# 稀疏图采用邻接表存储
self.e = [0] * N
self.ne = [0] * N
self.h = [-1] * N
self.w = [float('inf')] * N # 存储边的权重
self.idx = 0
self.st = [0] * N # 存储已经确定最短路的点
self.dist = [float('inf')] * N # 每个点到起点的最短距离
def add(self,a,b,w):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.h[a] = self.idx
self.w[self.idx] = w
self.idx += 1
def dijkstra(self):
heap = []
heapq.heappush(heap,[0,1]) # 使用堆存储每个点的距离存储结构为:[距离,节点]
self.dist[1] = 0 # 初始化节点1到自身的距离为0
while heap: # 当堆不为空时,说明还有点未确定最短路
t = heapq.heappop(heap) # 弹出堆顶的元素(小根堆)
dis = t[0]
cur = t[1]
if self.st[cur]:continue # 如果这个点已经确定最短路,跳出当前层循环
# 遍历当前节点的邻边
idx = self.h[cur]
while ~idx:
j = self.e[idx]
if self.dist[j] > dis + self.w[idx]: # 如果cur的加入能够更新节点j到起点的距离
self.dist[j] = dis + self.w[idx] # 更新距离
heapq.heappush(heap,[self.dist[j],j]) # 将节点j加入到堆中
idx = self.ne[idx]
self.st[cur] = 1
if self.dist[self.n] == float('inf'):print(-1)
else:print(self.dist[self.n])
def main(self):
self.n,m = map(int,input().split())
for i in range(m):
a,b,w = map(int,input().split())
self.add(a,b,w)
self.dijkstra()
if __name__ == '__main__':
dijkstra = Dijkstra()
dijkstra.main()
bellman-ford
- 适用条件:
- 从起点到终点的路径上不能存在负权回路(两种情况例外:1. 有边数限制的情况下,可以存在负权回路;2. 负权回路不在起点到终点的路径上)
- 存在负权边
- 第一层循环n次(不超过n条边,每个点所能得到的最小距离),每次循环需要备份上一次的dist数组,避免发生串联情况下影响后面dist的计算
- 第二层循环m次(循环所有的边),检查当前层的循环能否更新当前点到起点的最小距离
- 松弛操作:dis[b] = min(dis[b],backup[a] + w)
- 三角不等式:dis[b] ≤ min(dis[b],backup[a] + w) (经过n次循环后,一定存在b的距离不能再被a的距离更新,负权回路除外)
- 串联:如果题目中要求只经过1条边,由1到达3;如果不备份dist数组,那么在一次循环中,可能会出现dist[2]被更新为3后,再由dist[2]更新dist[3]得到4;而在后面的迭代中1到3的距离就不能再更新3的距离
- 为了避免这种情况,在外层循环中,每循环一次,都备份一次dist数组;即使dist[2]被更新为3,但是循环中用到的距离还是上一轮的dist距离,不会被当前层的迭代影响
AcWing 853. 有边数限制的最短路
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你求出从 1 号点到 n 号点的最多经过 k 条边的最短距离,如果无法从 1 号点走到 n 号点,输出 impossible。
注意:图中可能 存在负权回路 。
输入格式
第一行包含三个整数 n,m,k。
接下来 m 行,每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
点的编号为 1∼n。
输出格式
输出一个整数,表示从 1 号点到 n 号点的最多经过 k 条边的最短距离。
如果不存在满足条件的路径,则输出 impossible。
数据范围
1≤n,k≤500,
1≤m≤10000,
1≤x,y≤n,
任意边长的绝对值不超过 10000。
输入样例:
3 3 1
1 2 1
2 3 1
1 3 3
输出样例:
3
class Bellman_Ford:
def __init__(self):
N = 510
self.dis = [float('inf')] * N
self.side = list()
def bellman_ford(self):
self.dis[1] = 0
for i in range(self.k):
self.backup = copy.deepcopy(self.dis) # 备份当前dis数组,避免发生串联,影响边数限制下最短路计算
for side in self.side: # 每次循环都需要取出所有边,计算每个点的距离能否被更新
a, b, w = side
self.dis[b] = min(self.dis[b],self.backup[a] + w)
if self.dis[self.n] == float('inf'):print('impossible')
else:print(self.dis[self.n])
def main(self):
self.n,self.m,self.k = map(int,input().split())
for i in range(self.m):
a,b,w = map(int,input().split())
self.side.append([a,b,w])
self.bellman_ford()
if __name__ == '__main__':
bellman_ford = Bellman_Ford()
bellman_ford.main()
spfa(求最短路)
- 初始化将起点加入到队列中,并标记这个节点在队列中
- 初始化起点到自身的距离为0
- 当队列不为空时,逐个取出队首的元素a
- 遍历cur的所有邻边b,判断a的加入能否更新b到起点的距离
- 如果a的加入能够将b到起点的距离更新,就将节点b加入到队列中(前提是队列中不存在节点b)
- 队列中无论加入和弹出元素,都需要更新st数组
AcWing 851. spfa求最短路
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你求出 1 号点到 n 号点的最短距离,如果无法从 1 号点走到 n 号点,则输出 impossible。
数据保证不存在负权回路。
输入格式
第一行包含整数 n 和 m。
接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
输出一个整数,表示 1 号点到 n 号点的最短距离。
如果路径不存在,则输出 impossible。
数据范围
1 ≤ n , m ≤ 1 0 5 , 1≤n,m≤10^5, 1≤n,m≤105,
图中涉及边长绝对值均不超过 10000。
输入样例:
3 3
1 2 5
2 3 -3
1 3 4
输出样例:
2
class SPFA:
def __init__(self):
N = 100010
# 稀疏图用邻接表存储
self.e = [0] * N
self.ne = [0] * N
self.h = [-1] * N
self.w = [float('inf')] * N
self.idx = 0
# 数组模拟队列
self.hh = 0
self.tt = -1
self.que = [0] * N
self.dis = [float('inf')] * N # 存储每个节点到起点的最小距离
self.st = [0] * N #存储队列中存在哪些节点,避免重复节点被加入到队列中(自环)
def add(self,a,b,w):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.w[self.idx] = w
self.h[a] = self.idx
self.idx += 1
def insert(self,x):
self.tt += 1
self.que[self.tt] = x
def spfa(self):
self.insert(1) # 将1号节点加入到队列中
self.st[1] = 1 # 标记1号节点在队列中
self.dis[1] = 0 # 初始化1号节点到自身的距离为0
while self.hh <= self.tt: # 当队列不空,说明队列中存在新的点可能使得其他点到起点的距离变小
cur = self.que[self.hh] # 弹出队首元素
self.hh += 1
self.st[cur] = 0 # 将队首元素标记取消
idx = self.h[cur] # 遍历队首元素的邻边
while ~idx:
j = self.e[idx]
# 计算队首元素的加入能否更新其他点到起点的距离
if self.dis[j] > self.dis[cur] + self.w[idx]:
self.dis[j] = self.dis[cur] + self.w[idx]
if not self.st[j]: # 如果节点j不在队列中,再向队列中加入新的元素
self.insert(j)
self.st[j] = 1
idx = self.ne[idx]
if self.dis[self.n] == float('inf'):print("impossible")
else:print(self.dis[self.n])
def main(self):
self.n,self.m = map(int,input().split())
for i in range(self.m):
a,b,w = map(int,input().split())
self.add(a,b,w)
self.spfa()
if __name__ == '__main__':
spfa = SPFA()
spfa.main()
spfa(判断负环)
- 初始将所有点加入到队列中,逐个遍历每个点的邻边(避免某些负环不在以某个点为起点的路径上)
- 当队列不空,说明队列中的元素还可以取更新其他点的最短距离
- 初始化一个cnt数组,统计每次更新最短距离后,所用到的边数
- 如果更新到某一个点后,出现边数大于等于n,(n个点只存在n-1条边)说明此时存在负环
- 距离更新后,需要将更新距离后的点加入到队列中(前提是队列中不存在这个节点)
AcWing 852. spfa判断负环
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环, 边权可能为负数。
请你判断图中是否存在负权回路。
输入格式
第一行包含整数 n 和 m。
接下来 m 行每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
输出格式
如果图中存在负权回路,则输出 Yes,否则输出 No。
数据范围
1≤n≤2000,
1≤m≤10000,
图中涉及边长绝对值均不超过 10000。
输入样例:
3 3
1 2 -1
2 3 4
3 1 -4
输出样例:
Yes
from collections import deque
class SPFA:
def __init__(self):
N = 10010
self.dis = [0] * N
self.st = [0] * N
self.cnt = [0] * N
self.e = [0] * N
self.ne = [0] * N
self.h = [-1] * N
self.w = [0] * N
self.idx = 0
def add(self,a,b,w):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.w[self.idx] = w
self.h[a] = self.idx
self.idx += 1
def spfa(self):
que = deque()
# 由于需要检查所有点是否存在负环,所以初始化时需要将所有点加入到队列中
for i in range(1,self.n+1):
que.append(i)
self.st[i] = 1 # 将点标记为在队列中
while que:
# 队列不空,弹出队首元素,并将标记去掉
cur = que.popleft()
self.st[cur] = 0
# 遍历这个点的所有邻边
idx = self.h[cur]
while ~idx:
j = self.e[idx]
# 如果cur的加入能够更新节点j的最短距离,就将最短距离更新,并统计节点j得到最短距离时的边数
if self.dis[j] > self.dis[cur] + self.w[idx]:
self.dis[j] = self.dis[cur] + self.w[idx]
self.cnt[j] = self.cnt[cur] + 1
# 如果存在某个点最短距离的边数≥点数,说明至少存在一个负权回路
if self.cnt[j] >= self.n:return True
if not self.st[j]:
que.append(j)
self.st[j] = 1
idx = self.ne[idx]
return False
def main(self):
self.n,m = map(int,input().split())
for i in range(m):
a,b,w = map(int,input().split())
self.add(a,b,w)
res = self.spfa()
if res:print("Yes")
else:print("No")
if __name__ == '__main__':
spfa = SPFA()
spfa.main()
Floyd
-
假设节点序号是从1到n。
f[i][j]是一个n*n的矩阵,第i行第j列代表从i到j的权值,如果i到j有边,那么其值就为w[i][j](边ij的权值)。
如果没有边,那么其值就为无穷大。 -
f[k][i][j]代表(k的取值范围是从1到n),在考虑了从1到k的节点作为中间经过的节点时,节点i到节点j的最短距离。 -
比如:
f[1][i][j]就代表了,在考虑了节点1作为中间经过的节点时,从i到j的最短路径的长度。 -
分析可知:
f[0][i][j]的值无非就是两种情况: (i=>j,i=>1=>j):f[0][i][j]:i=>j 直接从i到j的距离 小于 i=>1=>j 经过节点1到达节点j的距离f[0][i][1]+f[0][1][j]:i=>1=>j 经过节点1到达节点j的距离小于 i=>j 直接从节点i到节点j的距离
-
动态规划分析:
f[k][i][j]可以从两种情况转移而来:- 从
f[k−1][i][j]转移而来,表示i到j的最短距离不经过节点k - 从
f[k−1][i][k]+f[k−1][k][j]转移而来,表示i到j的最短距离经过节点k f[k][i][j]=min(f[k−1][i][j],f[k−1][i][k]+f[k−1][k][j])- 从总结上来看,发现f[k]只可能与f[k−1]有关。
- 从
AcWing 854. Floyd求最短路
给定一个 n 个点 m 条边的有向图,图中可能存在重边和自环,边权可能为负数。
再给定 k 个询问,每个询问包含两个整数 x 和 y,表示查询从点 x 到点 y 的最短距离,如果路径不存在,则输出 impossible。
数据保证图中不存在负权回路。
输入格式
第一行包含三个整数 n,m,k。
接下来 m 行,每行包含三个整数 x,y,z,表示存在一条从点 x 到点 y 的有向边,边长为 z。
接下来 k 行,每行包含两个整数 x,y,表示询问点 x 到点 y 的最短距离。
输出格式
共 k 行,每行输出一个整数,表示询问的结果,若询问两点间不存在路径,则输出 impossible。
数据范围
1 ≤ n ≤ 200 , 1≤n≤200, 1≤n≤200,
1 ≤ k ≤ n 2 1≤k≤n^2 1≤k≤n2
1 ≤ m ≤ 20000 , 1≤m≤20000, 1≤m≤20000,
图中涉及边长绝对值均不超过 10000。
输入样例:
3 3 2
1 2 1
2 3 2
1 3 1
2 1
1 3
输出样例:
impossible
1
class Floyd:
def __init__(self):
N = 210
self.a = [[float('inf')] * N for _ in range(N)]
def floyd(self):
for k in range(1, self.n + 1):
for i in range(1, self.n + 1):
for j in range(1, self.n + 1):
self.a[i][j] = min(self.a[i][j], self.a[i][k] + self.a[k][j])
def main(self):
self.n, self.m, self.k = map(int, input().split())
for i in range(1, self.n + 1):
self.a[i][i] = 0
for i in range(self.m):
a, b, w = map(int, input().split())
self.a[a][b] = min(self.a[a][b], w)
self.floyd()
for j in range(self.k):
x, y = map(int, input().split())
if self.a[x][y] == float('inf'):
print("impossible")
else:
print(self.a[x][y])
if __name__ == '__main__':
floyd = Floyd()
floyd.main()
最小生成树
- 给定一个无向图,在图中选择若干条边把图的所有节点连起来。要求边长之和最小。在图论中,叫做求最小生成树。
- 每次将离连通部分的最近的点和点对应的边加入的连通部分,连通部分逐渐扩大,最后将整个图连通起来,并且边长之和最小。
- 无向图添加边的时候添加两条边(a --> b 和 b --> a)
- 先随机找一个起点,遍历一遍以这个点为起点的所有边,找到边长最短的边t
- 将这个点加入到st数组中(st数组表示生成树中的点)
- 当外层循环到第二次循环的时候,将边权和res += dis[t]
- 再遍历所有边,更新其他边到生成树的距离(边到集合的距离表示:边到集合的最小边长)
伪代码:
int dist[n],state[n];
dist[1] = 0;
for(i : 1 ~ n)
{
t <- 没有连通起来,但是距离连通部分最近的点;
state[t] = 1;
更新 dist;
}
Prim求最小生成树
给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环,边权可能为负数。
求最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。
给定一张边带权的无向图 G=(V,E),其中 V 表示图中点的集合,E 表示图中边的集合,n=|V|,m=|E|。
由 V 中的全部 n 个顶点和 E 中 n−1 条边构成的无向连通子图被称为 G 的一棵生成树,其中边的权值之和最小的生成树被称为无向图 G 的最小生成树。
输入格式
第一行包含两个整数 n 和 m。
接下来 m 行,每行包含三个整数 u,v,w,表示点 u 和点 v 之间存在一条权值为 w 的边。
输出格式
共一行,若存在最小生成树,则输出一个整数,表示最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。
数据范围
1 ≤ n ≤ 500 , 1≤n≤500, 1≤n≤500,
1 ≤ m ≤ 1 0 5 , 1≤m≤10^5, 1≤m≤105,
图中涉及边的边权的绝对值均不超过 10000。
输入样例:
4 5
1 2 1
1 3 2
1 4 3
2 3 2
3 4 4
输出样例:
6
# 给定一个无向图,在图中选择若干条边把图的所有节点连起来。要求边长之和最小。在图论中,叫做求最小生成树。
class Prim:
def __init__(self):
N = 510
self.arr = [[float('inf')] * N for _ in range(N)] # 由于是稠密图,采用邻接矩阵存储
self.dist = [float('inf')] * N # 存储各个点到连通块的最短距离
self.st = [False] * N # 节点是否被加入到生成树中
def prim(self):
res = 0 # 最小生成树权值
for i in range(self.n):
t = -1
# 每次选择一个未加入到最小生成树的节点t
for j in range(1,self.n+1):
if not self.st[j] and (t == -1 or self.dist[t] > self.dist[j]):
t = j
# 如果节点t是孤立点,则直接返回
if i and self.dist[t] == float('inf'):return float('inf')
# 更新最小生成树的权值
if i:res += self.dist[t]
self.st[t] = True # 将节点t加入到最小生成树中
# 循环判断节点t是否能够更新生成树中的其他点的最小距离
for k in range(1,self.n+1):
self.dist[k] = min(self.dist[k],self.arr[t][k])
return res
def main(self):
self.n,self.m = map(int,input().split())
for i in range(self.m):
a,b,w = map(int,input().split())
# 由于图中是无向边,所以存储两条边,分别由a-->b;b-->a
self.arr[b][a] = self.arr[a][b] = min(self.arr[a][b],w)
t = self.prim()
if t == float('inf'):print('impossible')
else:print(t)
if __name__ == '__main__':
prim = Prim()
prim.main()
Kruskal 求最小生成树
-
将所有边按照权重的大小进行升序排序,然后从小到大遍历所有边。
-
如果当前边不在生成树中,就选择这条边,反之就舍去这条边
-
直到n 个顶点,筛选出来 n-1 条边为止。
-
筛选出来的边和所有的顶点构成最小生成树。
判断是否会产生回路的方法为:使用并查集。
-
初始化每个点的父节点指向自身(并查集)
-
遍历过程的每条边,判断这两个顶点的是否在一个集合中。
-
如果边上的这两个顶点在一个集合中,说明两个顶点已经连通,这条边舍掉
-
如果不在一个集合中,则将这条边权重添加到 res += w,并将这个点加入到集合中
AcWing 859. Kruskal算法求最小生成树
给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环,边权可能为负数。
求最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。
给定一张边带权的无向图 G=(V,E),其中 V 表示图中点的集合,E 表示图中边的集合,n=|V|,m=|E|。
由 V 中的全部 n 个顶点和 E 中 n−1 条边构成的无向连通子图被称为 G 的一棵生成树,其中边的权值之和最小的生成树被称为无向图 G 的最小生成树。
输入格式
第一行包含两个整数 n 和 m。
接下来 m 行,每行包含三个整数 u,v,w,表示点 u 和点 v 之间存在一条权值为 w 的边。
输出格式
共一行,若存在最小生成树,则输出一个整数,表示最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。
数据范围
1 ≤ n ≤ 1 0 5 , 1≤n≤10^5, 1≤n≤105,
1 ≤ m ≤ 2 ∗ 1 0 5 , 1≤m≤2∗10^5, 1≤m≤2∗105,
图中涉及边的边权的绝对值均不超过 1000。
输入样例:
4 5
1 2 1
1 3 2
1 4 3
2 3 2
3 4 4
输出样例:
6
class Kruskal:
def __init__(self):
N = 100010
self.arr = list()
self.p = [i for i in range(N)]
def find(self,x):
if x != self.p[x]:
self.p[x] = self.find(self.p[x])
return self.p[x]
def kruskal(self):
res = 0
cnt = 0
for node in self.arr:
a,b,w = node
pa = self.find(a) # 找到a,b点的根节点,如果两个根节点不在同一个集合中,就将b加入到集合中
pb = self.find(b)
if pa != pb:
res += w # 更新总的边权重
cnt += 1 # 更新集合中的点数
self.p[pa] = pb
return res,cnt
def main(self):
self.n,m = map(int,input().split())
for i in range(m):
a,b,w = map(int,input().split())
self.arr.append([a,b,w])
self.arr.sort(key=lambda x:x[2]) # 按边的权重从小到大进行排序
res,cnt = self.kruskal()
if cnt < self.n - 1:print("impossible") # 如果生成树中的点数小于n-1,说明存在点不在生成树中
else:print(res)
if __name__ == '__main__':
kruskal = Kruskal()
kruskal.main()
二分图
染色法判断二分图
- 染色法:可以将所有点分在两个集合,所有的边只在两个集合之间,集合内部不存在边
- 二分图:一定不含有奇数环
- 思路:
- 初始化所有点颜色为0(表示未染色)
- 遍历所有点,每次将未染色的点进行dfs染色(两条边的两个顶点染不同颜色)
- 染色过程中如果某个点染色失败,说明不是二分图
- 如果能够全部染色,说明是二分图
AcWing 860. 染色法判定二分图
给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环。
请你判断这个图是否是二分图。
输入格式
第一行包含两个整数 n 和 m。
接下来 m 行,每行包含两个整数 u 和 v,表示点 u 和点 v 之间存在一条边。
输出格式
如果给定图是二分图,则输出 Yes,否则输出 No。
数据范围
1 ≤ n , m ≤ 1 0 5 1≤n,m≤10^5 1≤n,m≤105
输入样例:
4 4
1 3
1 4
2 3
2 4
输出样例:
Yes
import sys
# 必须设置递归深度
sys.setrecursionlimit(1000000) # python会爆栈,虽然设置了递归深度也没多大用
class Solution:
def __init__(self):
N = 100010
M = 200010
self.e = [0] * M
self.ne = [0] * M
self.h = [-1] * N
self.idx = 0
self.color = [0] * N
def add(self,a,b):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.h[a] = self.idx
self.idx += 1
def dfs(self,u,c):
self.color[u] = c
idx = self.h[u]
while ~idx:
cur = self.e[idx]
if not self.color[cur]:
if not self.dfs(cur,3-c):return False
else:
if self.color[cur] == c:
return False
idx = self.ne[idx]
return True
def main(self):
n,m = map(int,input().split())
for i in range(m):
a,b = map(int,input().split())
self.add(a,b)
self.add(b,a)
flag = True
for i in range(1,n+1):
if not self.color[i]:
if not self.dfs(i,1):
flag = False
print("No")
break
if flag: print("Yes")
if __name__ == '__main__':
solution = Solution()
solution.main()
二分图最大匹配
- 最外层遍历所有的顶点,循环内需要初始化st数组(避免st数组对后面的匹配造成影响)
- 每个点匹配成功就将res加一,表示匹配数
- find(x),查找当前x是否能够成功匹配
- 遍历x的所有邻边,如果当前邻边y没有被匹配过,就试着匹配y
- match(y):记录当前y被谁匹配,如果已经匹配过,就递归对match[y]进行重新配对
- 如果find(match[y])也匹配成功,那么就将原来的y匹配给x
- 匹配失败则返回False
def find(self,boy):
idx = self.h[boy]
while ~idx:
girl = self.e[idx] # 遍历这个boy的所有邻边(girl)
if not self.st[girl]: # 如果这个girl没有匹配过,就试着给这个女孩匹配
self.st[girl] = 1 # 标记匹配过
if self.match[girl] == 0 or self.find(self.match[girl]):
# 如果这个girl匹配的boy数为0,说明这个girl可以被匹配
# 否则就试着重新对这个girl匹配的男孩重新匹配女孩
self.match[girl] = boy
return True # 如果匹配成功就标记为True
idx = self.ne[idx]
return False
AcWing 861. 二分图的最大匹配
给定一个二分图,其中左半部包含 n 1 n_1 n1 个点(编号 1 ∼ n 1 1∼n_1 1∼n1),右半部包含 n 2 n_2 n2 个点(编号 1 ∼ n 2 1∼n_2 1∼n2),二分图共包含 m 条边。
数据保证任意一条边的两个端点都不可能在同一部分中。
请你求出二分图的最大匹配数。
二分图的匹配:给定一个二分图 G,在 G 的一个子图 M 中,M 的边集 {E} 中的任意两条边都不依附于同一个顶点,则称 M 是一个匹配。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
输入格式
第一行包含三个整数 n 1 n_1 n1、 n 2 n_2 n2和 m。
接下来 m 行,每行包含两个整数 u 和 v,表示左半部点集中的点 u 和右半部点集中的点 v 之间存在一条边。
输出格式
输出一个整数,表示二分图的最大匹配数。
数据范围
1 ≤ n 1 , n 2 ≤ 500 , 1≤n_1,n_2≤500, 1≤n1,n2≤500,
1 ≤ u ≤ n 1 , 1≤u≤n_1, 1≤u≤n1,
1 ≤ v ≤ n 2 , 1≤v≤n_2, 1≤v≤n2,
1 ≤ m ≤ 1 0 5 1≤m≤10^5 1≤m≤105
输入样例:
2 2 4
1 1
1 2
2 1
2 2
输出样例:
2
class Solution:
def __init__(self):
N = 510
M = 100010
self.e = [0] * M
self.ne = [0] * M
self.h = [-1] * N
self.idx = 0
self.st = [0] * N
self.match = [0] * N
def add(self,a,b):
self.e[self.idx] = b
self.ne[self.idx] = self.h[a]
self.h[a] = self.idx
self.idx += 1
def find(self,boy):
idx = self.h[boy]
while ~idx:
girl = self.e[idx] # 遍历这个boy的所有邻边(girl)
if not self.st[girl]: # 如果这个girl没有匹配过,就试着给这个女孩匹配
self.st[girl] = 1 # 标记匹配过
if self.match[girl] == 0 or self.find(self.match[girl]):
# 如果这个girl匹配的boy数为0,说明这个girl可以被匹配
# 否则就试着重新对这个girl匹配的男孩重新匹配女孩
self.match[girl] = boy
return True # 如果匹配成功就标记为True
idx = self.ne[idx]
return False
def main(self):
n1,n2,m = map(int,input().split())
for _ in range(m):
boy,girl = map(int,input().split())
self.add(boy,girl)
res = 0
for i in range(1,n1+1):
self.st = [0] * 510 # 每次遍历的时候都需要初始化st数组,避免对后续遍历产生影响
if self.find(i):res += 1 # 如果匹配成功一对,res就加一
print(res)
if __name__ == '__main__':
solution = Solution()
solution.main()
第四章 数学知识
质数
-
质数定义:在大于1的整数中,如果只包含1和本身这两个约数就被称为质数或素数
-
质数的判定:试除法
-
n的因数只需从2枚举到 n \sqrt{n} n
- 证明:
d | n 表示:d能够整除n
n d {n \over d} dn | n 表示: n d {n \over d} dn 也能整除n
例如:2是12的约数,那么6也是12的约数
所以只需要枚举较小的约数即可
∵ d ≤ n d {n \over d} dn
∴ d 2 d^2 d2 ≤ n
∴ d ≤ n \sqrt{n} n
细节: n \sqrt{n} n 最好写成 i ≤ n / i
def find(n):
if n < 2: return "No"
i = 2
while i <= n // i:
if n % i == 0:return "No"
i += 1
return "Yes"
AcWing 866. 试除法判定质数
给定 n 个正整数 a i a_i ai,判定每个数是否是质数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 a i a_i ai。
输出格式
共 n 行,其中第 i 行输出第 i 个正整数 a i a_i ai 是否为质数,是则输出 Yes,否则输出 No。
数据范围
1≤n≤100,
1 ≤ a i ≤ 2 31 − 1 1≤ai≤2^{31−1} 1≤ai≤231−1
输入样例:
2
2
6
输出样例:
Yes
No
def find(n):
if n < 2: return "No"
i = 2
while i <= n // i:
if n % i == 0:return "No"
i += 1
return "Yes"
def main():
n = int(input())
for i in range(n):
a = int(input())
print(find(a))
if __name__ == '__main__':
main()
- 分界质因数:
- n中最多只包含一个大于 n \sqrt{n} n的质因子
def divid(a):
i = 2
while i <= a // i:
if a % i == 0: # 说明找到一个a的质因数
res = 0
while a % i == 0: # 去找当前i出现次数
a //= i
res += 1
print(i,res)
i += 1
if a > 1:print(a,1) # 如果最后a大于1,说明a就是大于sqrt(n)的那个质因数
AcWing 867. 分解质因数
给定 n 个正整数 a i a_i ai,将每个数分解质因数,并按照质因数从小到大的顺序输出每个质因数的底数和指数。
输入格式
第一行包含整数 n。
接下来 n 行,每行包含一个正整数 a i a_i ai。
输出格式
对于每个正整数 a i a_i ai,按照从小到大的顺序输出其分解质因数后,每个质因数的底数和指数,每个底数和指数占一行。
每个正整数的质因数全部输出完毕后,输出一个空行。
数据范围
1≤n≤100,
2 ≤ a i ≤ 2 × 1 0 9 2≤a_i≤2×10^9 2≤ai≤2×109
输入样例:
2
6
8
输出样例:
2 1
3 1
2 3
def divid(a):
i = 2
while i <= a // i:
if a % i == 0: # 说明找到一个a的质因数
res = 0
while a % i == 0: # 去找当前i出现次数
a //= i
res += 1
print(i,res)
i += 1
if a > 1:print(a,1) # 如果最后a大于1,说明a就是大于sqrt(n)的那个质因数
def main():
n = int(input())
for i in range(n):
a = int(input())
divid(a)
print()
if __name__ == '__main__':
main()
第五章 动态规划
文章链接
背包问题
01背包问题
- 状态f[j]的定义:表示取前i件物品,在背包容量不超过j的前提下,能得到的最大价值
- 由于这里做了优化:由二维优化到一维,所以在进行第i次遍历的时候要保证用到的状态是由i-1转移过来
- 所以背包体积的遍历就需要从大到小遍历,遍历的最小值必须要满足
j - v[i] ≥0
for i in range(1,N+1):
for j in range(V,self.v[i]-1,-1):
"""
1. j - self.v[i] 恒小于j,所以j的遍历必须从大到小进行遍历,否
则j - self.v[i]就是由第i层进行更新了
2. 由于j需要大于等于vi,所以j的遍历直接从vi开始即可
"""
self.f[j] = max(self.f[j],self.f[j - self.v[i]] + self.w[i])
AcWing 2. 01背包问题
有 N 件物品和一个容量是 V 的背包。每件物品只能使用一次。
第 i 件物品的体积是 v i v_i vi,价值是 w i w_i wi。
求解将哪些物品装入背包,可使这些物品的总体积不超过背包容量,且总价值最大。
输出最大价值。
输入格式
第一行两个整数,N,V,用空格隔开,分别表示物品数量和背包容积。
接下来有 N 行,每行两个整数 v i , w i v_i,w_i vi,wi,用空格隔开,分别表示第 i 件物品的体积和价值。
输出格式
输出一个整数,表示最大价值。
数据范围
0
输入样例
4 5
1 2
2 4
3 4
4 5
输出样例:
8
class knapsack:
def __init__(self):
N = 1010
self.f = [0] * N
self.w = [0] * N
self.v = [0] * N
def main(self):
N,V = map(int,input().split())
for k in range(1,N+1):
v,w = map(int, input().split())
self.w[k] = w
self.v[k] = v
# 由于i只跟i-1的状态有关,所以可以对二维数组进行优化,优化成滚动数组
for i in range(1,N+1):
for j in range(V,self.v[i]-1,-1):
"""
1. j - self.v[i] 恒小于j,所以j的遍历必须从大到小进行遍历,否
则j - self.v[i]就是由第i层进行更新了
2. 由于j需要大于等于vi,所以j的遍历直接从vi开始即可
"""
self.f[j] = max(self.f[j],self.f[j - self.v[i]] + self.w[i])
print(self.f[V])
if __name__ == '__main__':
knapsack = knapsack()
knapsack.main()
第六章 贪心
区间问题:
Hufman树:
- Acwing148. 合并果子
在一个果园里,达达已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆。
达达决定把所有的果子合成一堆。
每一次合并,达达可以把两堆果子合并到一起,消耗的体力等于两堆果子的重量之和。
可以看出,所有的果子经过 n−1 次合并之后,就只剩下一堆了。
达达在合并果子时总共消耗的体力等于每次合并所耗体力之和。
因为还要花大力气把这些果子搬回家,所以达达在合并果子时要尽可能地节省体力。
假定每个果子重量都为 1,并且已知果子的种类数和每种果子的数目,你的任务是设计出合并的次序方案,使达达耗费的体力最少,并输出这个最小的体力耗费值。
例如有 3 种果子,数目依次为 1,2,9。可以先将 1、2 堆合并,新堆数目为 3,耗费体力为 3。
接着,将新堆与原先的第三堆合并,又得到新的堆,数目为 12,耗费体力为 12。
所以达达总共耗费体力=3+12=15。
可以证明 15 为最小的体力耗费值。
输入格式
输入包括两行,第一行是一个整数 n,表示果子的种类数。
第二行包含 n 个整数,用空格分隔,第 i 个整数 ai 是第 i 种果子的数目。
输出格式
输出包括一行,这一行只包含一个整数,也就是最小的体力耗费值。
输入数据保证这个值小于 231。
数据范围
1≤n≤10000,
1≤ai≤20000
输入样例:
3
1 2 9
输出样例:
15
题解:
哈夫曼问题:给定n个节点,组成一颗完全二叉树
- 两个最小子节点一定是在最下面一层,并且互为兄弟
- 最优子结构:将最下层两两个子节点合并后,可以将当前哈夫曼树看成有n-1个节点的新的哈夫曼树
构建方法:通过小根堆,每次弹出堆顶元素,将两次弹出的堆顶元素相加,将这两个元素的和再次加入到堆中
内部节点的和(1, 2, 3, 4)的和就是解
# 小根堆
import heapq
def main():
n = int(input())
line = list(map(int,input().split()))
res = 0
# 建堆
heapq.heapify(line)
while len(line) > 1: # 当堆中的元素大于1,说明堆中还存在叶节点
a = heapq.heappop(line) # 连续弹出堆顶的元素
b = heapq.heappop(line)
ans = a + b #对堆顶的元素求和
res += ans
heapq.heappush(line,ans) # 将和再加入到堆中
print(res)
if __name__ == '__main__':
main()
排序不等式 :
- AcWing 913. 排队打水
有 n 个人排队到 1 个水龙头处打水,
第 i 个人装满水桶所需的时间是 ti,
请问如何安排他们的打水顺序才能使所有人的等待时间之和最小?
输入格式
第一行包含整数 n。
第二行包含 n 个整数,
其中第 i 个整数表示第 i 个人装满水桶所花费的时间 ti。
输出格式
输出一个整数,表示最小的等待时间之和。
数据范围
1 ≤ n ≤ 1 0 5 10^5 105,
1 ≤ ti ≤ 1 0 4 10^4 104
输入样例:
7
3 6 1 4 2 5 7
输出样例:
56
题解
3 6 1 4 2 5 7
对n个人打水需要等待的总时间为s= 3 * 6 + 6 * 5 + 1 * 4 + 2 * 3 + 5 * 1 + 7 * 0
对一般式就有:
s = t 1 ∗ ( n − 1 ) + t 2 ∗ ( n − 2 ) + t 3 ∗ ( n − 3 ) + . . . + t n − 1 ∗ 1 s = t_1 * (n-1) + t_2 * (n-2) + t_3 * (n-3) + ... + t_n-_1*1 s=t1∗(n−1)+t2∗(n−2)+t3∗(n−3)+...+tn−1∗1
要使得s最小,就需要使得 t 1 < t 2 < t 3 < . . . < t n t_1 < t_2 < t_3 < ... < t_n t1<t2<t3<...<tn
证明:
1. 假设排队顺序不是严格递增,必然存在相邻两个 t i > t i + 1 t_i > t_i+_1 ti>ti+1
2. 相邻两个打水等待时间: s f i = t i ∗ ( n − i ) + t i + 1 ∗ ( n − i − 1 ) sf_i = t_i * (n-i) + t_{i+1} * (n-i-1) sfi=ti∗(n−i)+ti+1∗(n−i−1)
3. 交换这两个顺序得到新的等待时间: s t i = t i + 1 ∗ ( n − i ) + t i ∗ ( n − i − 1 ) st_i= t_{i+1} * (n-i) + t_i * (n-i-1) sti=ti+1∗(n−i)+ti∗(n−i−1)
4. s f i − s t i = t i ∗ ( n − i ) + t i + 1 ∗ ( n − i − 1 ) − t i + 1 ∗ ( n − i ) − t i ∗ ( n − i − 1 ) = t i − t i + 1 sf_i - st_i = t_i * (n-i) + t_{i+1} * (n-i-1) - t_{i+1} * (n-i) - t_i * (n-i-1) = t_i - t_{i+1} sfi−sti=ti∗(n−i)+ti+1∗(n−i−1)−ti+1∗(n−i)−ti∗(n−i−1)=ti−ti+1
5. 由于 t i > t i + 1 t_i > t_{i+1} ti>ti+1,所以交换后得到的等待时间会更少
6. 所以排队顺序为递增排序,得到的等待时间之和会最小
def main():
n = int(input())
line = list(map(int,input().split()))
line.sort()
res = 0
for i in range(n):
res += (line[i] * (n-i-1))
print(res)
if __name__ == '__main__':
main()
绝对值不等式:
- AcWing 104. 货仓选址
在一条数轴上有 N 家商店,它们的坐标分别为 A1∼AN。
现在需要在数轴上建立一家货仓,每天清晨,从货仓到每家商店都要运送一车商品。
为了提高效率,求把货仓建在何处,可以使得货仓到每家商店的距离之和最小。
输入格式
第一行输入整数 N。
第二行 N 个整数 A1∼AN。
输出格式
输出一个整数,表示距离之和的最小值。
数据范围
1≤N≤100000,
0≤Ai≤40000
输入样例:
4
6 2 9 1
输出样例:
12
绝对值不等式: ∣ a − x ∣ + ∣ b − x ∣ ≥ ∣ a − b ∣ |a - x| + |b - x| ≥ |a - b| ∣a−x∣+∣b−x∣≥∣a−b∣
当x位于[a,b]之间的时候取得最小值
题解:
1. 将每个店进行坐标距离从大到小排序
2. 假设仓库选址为坐标x
3. 仓库到每个店的距离 s = ∣ a 1 − x ∣ + ∣ a 2 − x ∣ + ∣ a 3 − x ∣ + . . . + ∣ a n − x ∣ s = |a_1-x| + |a_2 - x| + |a_3 - x| + ... + |a_n - x| s=∣a1−x∣+∣a2−x∣+∣a3−x∣+...+∣an−x∣
4. 依次合并首尾两项 s = ( ∣ a 1 − x ∣ + ∣ a n − x ∣ ) + ( ∣ a 2 − x ∣ + ∣ a n − 1 − x ∣ ) + . . . + ( ∣ a n / 2 − x ∣ + ∣ a n / 2 − x ∣ ) s = (|a_1-x| + |a_n-x|) + (|a_2 - x| + |a_{n-1} - x|) + ... + (|a_{n/2} - x| + |a_{n/2} - x|) s=(∣a1−x∣+∣an−x∣)+(∣a2−x∣+∣an−1−x∣)+...+(∣an/2−x∣+∣an/2−x∣)
5. 根据绝对值不等式可以得到 s ≥ ( ∣ a 1 − a n ∣ ) + ( ∣ a 2 − a n − 1 ∣ ) + . . . + ( ∣ a n / 2 − a n / 2 ∣ ) s ≥ (|a_1-a_n|) + (|a_2 - a_{n-1}|) + ... + (|a_{n/2} - a_{n/2}|) s≥(∣a1−an∣)+(∣a2−an−1∣)+...+(∣an/2−an/2∣)
6. 当x取n / 2(n为偶数)或者(n+1/2、n-1/2)取得最小值
- 双指针
def main():
n = int(input())
line = list(map(int,input().split()))
res = 0
line.sort()
l ,r = 0,n-1
while l < r:
res += (line[r] - line[l])
l += 1
r -= 1
print(res)
if __name__ == '__main__':
main()
def main():
n = int(input())
line = list(map(int,input().split()))
res = 0
line.sort()
for i in range(n):
res += abs(line[i] - line[i >>1]) # 这里可以取i/2也可以取n/2
print(res)
if __name__ == '__main__':
main()
- 证明:
∑ i = 0 n − 1 ( a i − a n / 2 ) = ∑ i = 0 n − 1 ( a i − a i / 2 ) \sum_{i = 0}^{n-1}(a_i - a_{n/2}) = \sum_{i = 0}^{n-1}(a_i - a_{i/2}) i=0∑n−1(ai−an/2)=i=0∑n−1(ai−ai/2)
∑ i = 0 n − 1 ( a i − a n / 2 ) = ( a n − 1 − a n / 2 ) + ( a n − 2 − a n / 2 ) + . . . + ( a n / 2 − a n / 2 ) + . . . + ( a n / 2 − a 0 ) = ( a n / 2 + 1 + a n / 2 + 2 + . . . + a n − 1 ) − ( a 0 + a 1 + . . . + a n / 2 − 1 ) \sum_{i = 0}^{n-1}(a_i - a_{n/2}) = (a_{n-1} - a_{n/2}) + (a_{n-2} - a{n/2}) + ... + (a_{n/2} - a_{n/2}) + ... + (a_{n/2} - a_0) \\ = (a_{n/2+1} + a_{n/2+2} +...+a_{n-1}) - (a_0 + a_1 + ... + a_{n/2-1}) i=0∑n−1(ai−an/2)=(an−1−an/2)+(an−2−an/2)+...+(an/2−an/2)+...+(an/2−a0)=(an/2+1+an/2+2+...+an−1)−(a0+a1+...+an/2−1)
∑ i = 0 n − 1 ( a i − a i / 2 ) = ( a n − 1 − a ( n − 1 ) / 2 ) + ( a n − 2 − a ( n − 2 ) / 2 ) + . . . + ( a n / 2 − a n / 2 ) + . . . + ( a 1 − a 1 / 2 ) + ( a 0 − a 0 ) = ( a 0 + a 1 + . . . + a n − 1 ) − 2 ∗ ( a 0 + a 1 + . . . + a n / 2 − 1 ) − a n / 2 − 1 = ( a n / 2 + 1 + a n / 2 + 2 + . . . + a n − 1 ) − ( a 0 + a 1 + . . . + a n / 2 − 1 ) \sum_{i = 0}^{n-1}(a_i - a_{i/2}) = (a_{n-1} - a_{(n-1)/2}) + (a_{n-2} - a{(n-2)/2}) + ... + (a_{n/2} - a_{n/2}) + ... + (a_1 - a_{1/2}) + (a_0 - a_0)\\ = (a_0 + a_1 +...+a_{n-1}) - 2*(a_0 + a_1 + ... + a_{n/2-1}) - a_{n/2 - 1} \\= (a_{n/2+1} + a_{n/2+2} +...+a_{n-1}) - (a_0 + a_1 + ... + a_{n/2-1}) i=0∑n−1(ai−ai/2)=(an−1−a(n−1)/2)+(an−2−a(n−2)/2)+...+(an/2−an/2)+...+(a1−a1/2)+(a0−a0)=(a0+a1+...+an−1)−2∗(a0+a1+...+an/2−1)−an/2−1=(an/2+1+an/2+2+...+an−1)−(a0+a1+...+an/2−1)
推公式:
- AcWing 125. 耍杂技的牛
农民约翰的 N 头奶牛(编号为 1…N)计划逃跑并加入马戏团,为此它们决定练习表演杂技。
奶牛们不是非常有创意,只提出了一个杂技表演:
叠罗汉,表演时,奶牛们站在彼此的身上,形成一个高高的垂直堆叠。
奶牛们正在试图找到自己在这个堆叠中应该所处的位置顺序。
这 N 头奶牛中的每一头都有着自己的重量 Wi 以及自己的强壮程度 Si。
一头牛支撑不住的可能性取决于它头上所有牛的总重量(不包括它自己)减去它的身体强壮程度的值,现在称该数值为风险值,风险值越大,这只牛撑不住的可能性越高。
您的任务是确定奶牛的排序,使得所有奶牛的风险值中的最大值尽可能的小。
输入格式
第一行输入整数 N,表示奶牛数量。
接下来 N 行,每行输入两个整数,表示牛的重量和强壮程度,
第 i 行表示第 i 头牛的重量 Wi 以及它的强壮程度 Si。
输出格式
输出一个整数,表示最大风险值的最小可能值。
数据范围
1≤N≤50000,
1≤Wi≤10,000,
1≤Si≤1,000,000,000
输入样例:
3
10 3
2 5
3 3
输出样例:
2
题解:
计算每一层的风险值:
| n n n | w w w | s s s | r r r |
|---|---|---|---|
| 1 | w 0 w_0 w0 | s 0 s_0 s0 | 0 − s 0 0 -s_0 0−s0 |
| 2 | w 1 w_1 w1 | s 1 s_1 s1 | w 0 − s 1 w_0 - s_1 w0−s1 |
| … | … | … | … |
| i | w i w_i wi | s i s_i si | w 0 + w 1 + . . . + w i − 1 − s i w_0 + w_1 + ... + w_{i-1} -s_i w0+w1+...+wi−1−si |
| i+1 | w i + 1 w_{i+1} |