opencv dnn模块 示例(18) 目标检测 object_detection 之 pp-yolo、pp-yolov2和pp-yolo tiny
文章目录
- 1、PP-YOLO
-
- 1.1、网络架构
-
- 1.1.1、BackBone骨干网络
- 1.1.2、DetectionNeck
- 1.1.3、DetectionHead
- 1.2、Tricks的选择
-
- 1.2.1、更大的batchsize
- 1.2.2、滑动平均
- 1.2.3、DropBlock
- 1.2.4、IOU Loss
- 1.2.5、IOU Aware
- 1.2.6、GRID Sensitive
- 1.2.7、Matrix NMS
- 1.2.8、CoordConv
- 1.2.9、SPP
- 1.2.10、更好的预训练模型、双倍迭代次数
- 1.3、实验
- 1.4、总结
- 2、PP-YOLOv2
-
- 2.1、优化与改进
-
- 2.1.1、采用 Path Aggregation Network(路径聚合网络)
- 2.1.2、采用 Mish 激活函数
- 2.1.3、更大的输入尺寸
- 2.1.4、IoU Aware Branch
- 2.3、仅在minitrain上有效果的trick
- 2.4、实验
- 3、PP-YOLO Tiny
- 4、模型测试
-
- 4.1、python测试
-
- 4.1.1、CPU推理
- 4.1.2、GPU推理
- 4.1.3、TensorRt 推理
- 4.2、Paddle Inference 的 c++ 测试
-
- 4.2.1、CPU测试
- 4.2.2、GPU测试
- 4.2.2、TensorRt测试
- 4.3、ONNX模型OpenCV测试
目标检测算法的准确性和推理速度不可兼得,本文的工作旨在通过tricks组合来平衡目标检测器的性能以及速度。
- PP-YOLO: 45.2% mAP,速度高达72.9 FPS!FPS和mAP均超越YOLOv4,FPS也远超过EfficientDet!
- PP-YOLOv2: 在同等速度下,精度超越 YOLOv5!相较 于 PP-YOLO,v2 版本在 COCO 2017 test-dev 上的精度提升了 3.6%,由 45.9% 提升到了 49.5%;在 640*640 的输入尺寸下,FPS 达到 68.9FPS,而采用 TensorRT 加速的话,FPS 更是达到了 106.5!这样的性能,超越了当前所有同等计算量下的检测器,包括 YOLOv4-CSP 和 YOLOv5l !如果将骨架网络从 ResNet50 更换为 ResNet101,PP-YOLOv2 的优势则更为显著:mAP 达到 50.3%,速度比同计算量的 YOLOv5x 高出了 15.9%。
- PP-YOLO Tiny: 体积只有 1.3M 的 PP-YOLO Tiny(得益于 PaddleSlim 飞桨模型压缩工具的能力),比 YOLO-Fastest 更轻、更快!这样超超超轻量的算法面世,更是很好的满足了产业里大量边缘、轻量化、低成本芯片上使用目标检测算法的种种诉求!
1、PP-YOLO
yolov4,5模型是基于yolo3算法改进得来。但PPYOLO并不像yolov4探究各种复杂的backbone和数据增广手段,也不是靠nas暴力搜索得到一个结构。我们在resnet骨干网络系列(ResNet50-vd),数据增广仅靠mixup的条件下,通过合理的tricks组合,不断提升模型性能。
最终与其他模型对比图如下

1.1、网络架构

1.1.1、BackBone骨干网络
yolov3使用的是较为大型的darknet53,考虑到resnet更广泛的应用以及多样化的分支,我们选用ResNet50-vd作为整个架构,并将部分卷积层替换成可变形卷积,适当增加了网络复杂度。由于DCN会带来额外的推理时间,我们仅仅在最后一层的3x3卷积替换成DCN卷积。
1.1.2、DetectionNeck
这里依然采取的是FPN特征金字塔结构做一个特征融合,类似Yolo3,我们选取最后三个卷积层C3, C4, C5,然后经过FPN结构,将高层级语义信息和低层级信息进行融合。
1.1.3、DetectionHead
原始yolo3的检测头是一个非常简单的结构,通过3x3卷积并最后用1x1卷积调整到自己所需要的通道数目。输出通道数为3(K+5),3代表每个层设定的三种尺寸的锚框,K代表类别数目,5又可以分成4+1,分别是目标框的4个参数,以及1个参数来判断框里是否有物体*。
1.2、Tricks的选择
1.2.1、更大的batchsize
使用更大的batch能让训练更加稳定,我们将batchsize从64调整到196,并适当调节训练策略以及学习率
1.2.2、滑动平均
类似于BN里的滑动平均,我们在训练参数更新上也做了滑动平均策略
W E M A = λ W E M A + ( 1 − λ ) W W_{EMA} = λW_{EMA} + (1 − λ)W WEMA=λWEMA+(1−λ)W,这里 λ λ λ 取0.9998
1.2.3、DropBlock
DropBlock也是谷歌提的一个涨点神器,但是适用范围不大。作者发现给BackBone直接加DropBlock会带来精度下降,于是只在检测头部分添加
1.2.4、IOU Loss
在yolov3中使用的是smooth L1 Loss来对检测框做一个回归,但这个Loss并不适合以mAP为评价指标。因此yolov4中引入了IOU Loss完全替换掉smooth L1 Loss。不同的是我们在原始的L1 Loss上引入额外的IOU Loss分支,由于各个版本的IOU Loss效果差不多,我们选用最基础的IOU Loss形式
1.2.5、IOU Aware
在yolov3中,分类概率和目标物体得分相乘作为最后的置信度,这显然是没有考虑定位的准确度。我们增加了一个额外的IOU预测分支来去衡量检测框定位的准确度,额外引入的参数和FLOPS可以忽略不计
1.2.6、GRID Sensitive
原始Yolov3对应中间点的调整公式如下
x = s ⋅ ( g x + σ ( p x ) ) y = s ⋅ ( g y + σ ( p y ) ) x = s · (gx + σ(px)) \\ y = s · (gy + σ(py)) x=s⋅(gx+σ(px))y=s⋅(gy+σ(py))
其中 σ σ σ 表示 s i g m i o d sigmiod sigmiod 函数。由于 s i g m i o d sigmiod sigmiod 函数两端趋于平滑,中心点很难根据公式调节到网格上面,因此我们改进公式为
x = s ⋅ ( g x + α ⋅ σ ( p x ) − ( α − 1 ) / 2 ) y = s ⋅ ( g y + α ⋅ σ ( p y ) − ( α − 1 ) / 2 ) x = s · (gx + α · σ(px) − (α − 1)/2) \\ y = s · (gy + α · σ(py) − (α − 1)/2) x=s⋅(gx+α⋅σ(px)−(α−1)/2)y=s⋅(gy+α⋅σ(py)−(α−1)/2)
这里我们将 α α α 设为1.05,能帮助中心点回归到网格线上
1.2.7、Matrix NMS
常规(hard-)NMS在排序预测时直接将重复框删除,soft-NMX将score乘以一个惩罚系数进行判断。受Soft-NMS启发,将NMS转为矩阵式并行方法运行。Matrix NMS相较传统NMS运行速度更快。
1.2.8、CoordConv
CoordConv的提出是为了解决常规卷积在空间变换的问题。
它在输入特征图,添加了两个通道,一个表征i坐标,一个表征j坐标。这两个通道带有坐标信息,从而允许网络学习完全平移不变性和变化平移相关度。
为了平衡带来的额外参数和FLOPS,我们只替换掉FPN的1x1卷积层以及detection head的第一层卷积,预测速度校服下降。
1.2.9、SPP
简单讲就是输入特征图经过四个分支之后进行拼接得到。
空间金字塔池化结构是广泛应用的一种结构引入{1, 5, 9, 13}这几种大小的最大池化。
该结构不会引入参数,但是会增加后续卷积的输入通道,引入了2%的参数和1%的FLOPS。
1.2.10、更好的预训练模型、双倍迭代次数
YOLO模型中,backbone部分的权重都是采用在ImageNet上分类任务中训练好的模型权重,在目标检测中默认冻结,backbone部分不参与训练。
PP-YOLO采用更优的backbone预训练权重,最终模型效果更好。显然更好的预训练模型在分类任务上能取得更好的效果,后续我们也会进行替换。
2x scheduler之前模型都是迭代25w个steps,2x scheduler就是迭代50w个steps,效果更好。一般来说2x和3x精度会有提高,再加到4x就会过拟合了。
1.3、实验

-
A->B:首先就是搭建基础版本的PP-YOLO,在尝试替换backbone后,虽然参数小了很多,但是mAP也下降了不少。我们通过增加了DCN卷积,将mAP提高到39.1%,增加的参数仍远远小于原始yolo3
-
B->C:基础模型搭建好后,我们尝试优化训练策略,选用的是更大的batch和EMA,并且加入DropBlock防止过拟合,mAP提升到了41.4%
-
C->F:我们在这个阶段分别增加了IOU Loss,IOU Aware,Grid Sensitive这三个损失函数的改进。分别得到了0.5%, 0.6%, 0.3%的提升,将mAP提升到了42.8%,推理速度下降仍属于可接受范围内
-
F->G:检测框的处理部分也是能提升性能的,通过增加Matrix NMS,mAP提高了0.6%。这个表格暂时不考虑NMS对推理时间的影响,在实际测试中,MatrixNMS是能比传统NMS降低推理时间的
-
G->I:到了最后阶段,很难通过增加网络复杂度来提高mAP,因此我们将SPP和CoordConv放到这里再来考虑。这两个结构所带来的额外参数较少,而实验也证明了将mAP提高到44.3%
-
I->J:分类模型的好坏不能代表整个检测模型的性能,因此我们最后才考虑是否用更好的预训练模型。
我们仍然是在ImageNet上进行预训练得到了一个更好的模型,并且提升了0.3%的mAP
1.4、总结
PP-YOLO没有像yolo4那样死抠现有的SOTA网络结构,而是着眼于合理的tricks堆叠。
通过有效的计算,很好的平衡了准确率以及推理时间,而其中的实验部分也非常适合学习炼丹的小伙伴。
2、PP-YOLOv2
据官网说明,PP-YOLO是PaddleDetection优化和改进的YOLOv3的模型,其精度(COCO数据集mAP)和推理速度均优于YOLOv4模型。(PP-YOLOv2)在COCO test-dev2017数据集上精度达到45.9%,在单卡V100上FP32推理速度为72.9 FPS, V100上开启TensorRT下FP16推理速度为155.6 FPS。

PP-YOLO是在 YOLOv3 的基础上,采用了一整套优化策略,在几乎不增加模型参数和计算量(FLOPs)的前提下,提升检测器的精度得到的极高性价比(mAP 45.9,72.9FPS)的单阶段目标检测器。
而 PP-YOLOv2,是以 PP-YOLO 为基线模型进行了一系列的延展实验得到的。
2.1、优化与改进
2.1.1、采用 Path Aggregation Network(路径聚合网络)

PP-YOLOv2 第一个优化的尝试是设计一个可以为各种尺度图像构建高层语义特征图的检测颈(detection neck)。不同于 PP-YOLO 采用 FPN 来从下至上的构建特征金字塔,PP-YOLOv2 采用了 FPN 的变形之一—PAN(Path Aggregation Network)来从上至下的聚合特征信息。
2.1.2、采用 Mish 激活函数
Mish 激活函数被很多实用的检测器采用,并拥有出色的表现,例如 YOLOv4 和 YOLOv5 都在骨架网络(backbone)的构建中应用 mish 激活函数。而对于 PP-YOLOv2,我们倾向于仍然采用原有的骨架网络,因为它的预训练参数使得网络在 ImageNet 上 top-1 准确率高达 82.4%。所以我们把 mish 激活函数应用在了 detection neck 而不是骨架网络上。
2.1.3、更大的输入尺寸
增加输入尺寸直接带来了目标面积的扩大。这样,网络可以更容易捕捉到小尺幅目标的信息,得到更高的性能。然而,更大的输入会带来更多的内存占用。所以在使用这个策略的同时,我们需要同时减少 Batch Size。在具体实验中,我们将 Batch Size 减少了一倍,从每个 GPU 24 张图像减少到每个 GPU 12 张图像,并将最大输入从 608 扩展到 768。输入大小均匀地从 [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768] 获取。
2.1.4、IoU Aware Branch
在 YOLOv3 中,将分类概率和 objectness 相乘作为最终的检测置信度,但却没有考虑定位置信度。为了解决这一问题,我们将 objectness 与定位置信度 IoU 综合起来, 使用下面的公式来计算出一个新的 objectness:
s = o b j e c t n e s s 1 − α ∗ p α s=objectness^{1-α}*p^{α} s=objectness1−α∗pα
其中 p p p 为检测框与 ground truth 之间的 IoU 的预测值.
为平衡参数,在 PP-YOLOv2 中设置为 0.5。我们使用 BCE(binary cross entropy) loss 来学习 p p p,公式如下所示
l o s s = − t ∗ l o g ( σ ( p ) ) − ( 1 − t ) ∗ l o g ( 1 − σ ( p ) ) loss = −t ∗ log(σ(p)) − (1 − t) ∗ log(1 − σ(p)) loss=−t∗log(σ(p))−(1−t)∗log(1−σ(p))
2.3、仅在minitrain上有效果的trick
在PP-YOLOv2的研发过程中,我们尝试了大量的方法,某些在COCO minitrain上有正向作用但在COCO train2017上反而具有负面作用。接下来,我们对其中一些进行讨论分析。
Cosine Learning Rate Decay: 不同于线性方式学习率衰减,cosine方式学习率衰减是一种平滑的学习率调整,会更有益于训练过程。尽管cosine学习率在COCO minitrain表现更佳,但它对于超参(比如初始学习率、warmup迭代次数、最终的学习率)比较敏感。我们尝试了多种超参数组合,但是在COCO train2017上并未发现正向作用。
Backbone Parameter Freezing: 当在下游任务微调ImageNet预训练模型,冻结前两阶段的参数是一种常用策略。尽管在COCO minitrain上这种策略可以带来1%mAP的性能增益,然而COCO train2017数据上反而带来了0.8%mAP性能下降。
SiLU Activation Function: 我们还尝试在DetectionNeck中采用SiLU替换Mish,在COCO minitrain可以带来0.3%mAP指标提升,但是在COCO train2017上反而带来了0.5%mAP指标下降。
按这样分析的话,那这些trick的使用,也是仅仅对coco数据集有效,如果换成其他数据集,会不会就没效果了???
2.4、实验

- A->B:当我们使用Mish的时候,它的mAP性能从45.1%提高到了47.1%。虽然模型B比模型A稍微慢一些,但是如此显著的增益促使我们在最终的模型中采用PAN。
- B->C:由于在评估过程中YOLOv4和YOLOv5的输入大小是640,我们将训练和评估的输入大小增加到640,以建立公平的比较。业绩平均每小时增长0.6%。
- C->D:不断增加输入尺寸效果更好。然而,不可能同时使用更大的输入大小和更大的批大小。我们使用更大的输入尺寸和每个GPU 12张图像训练模型D。它增加了0.6%的mAP,这比更大的Batch Size带来更多的收益。因此,在最终的实践中,我们选择bigger Input Size。输入大小从[320,352,384,416,448,480,512,544,576,608,640,672,704,736,768]均匀抽取。
- D->E:在训练阶段,改进后的IoU感知损失比之前的表现更好。在前一个版本中,在训练过程中经过数百次迭代,IoU感知损失的值将下降到1e-5。对IoU感知损失进行修改后,其值与IoU损失值处于同一数量级,是合理的。使用该策略后,模型E的mAP增加到49.1%,效率没有任何损失。
3、PP-YOLO Tiny
更适用于移动端的骨干网络: 骨干网络可以说是一个模型的核心组成部分,对网络的性能、体积影响巨大。PPYOLO Tiny 采用了移动端高性价比骨干网络 MobileNetV3。
更适用移动端的检测头(head): 除了骨干网络,PP-YOLO Tiny 的检测头(head)部分采用了更适用于移动端的深度可分离卷积(Depthwise Separable Convolution),相比常规的卷积操作,有更少的参数量和运算成本, 更适用于移动端的内存空间和算力。
去除对模型体积、速度有显著影响的优化策略: 在 PPYOLO 中,采用了近 10 种优化策略,但并不是每一种都适用于移动端轻量化网络,比如 iou aware 和 matrix nms 等。这类 Trick 在服务器端容易计算,但在移动端会引入很多额外的时延,对移动端来说性价比不高,因此去掉反而更适当。
使用更小的输入尺寸: 为了在移动端有更好的性能,PP-YOLO Tiny 采用 320 和 416 这两种更小的输入图像尺寸。并在 PaddleDetection2.0 中提供 tools/anchor_cluster.py 脚本,使用户可以一键式的获得与目标数据集匹配的 Anchor。例如,在 COCO 数据集上,我们使用 320*320 尺度重新聚类了 anchor,并对应的在训练过程中把每 batch 图⽚的缩放范围调整到 192-512 来适配⼩尺⼨输⼊图片的训练,得到更高性能。
召回率优化: 在使⽤⼩尺寸输入图片时,对应的目标尺寸也会被缩⼩,漏检的概率会变大,对应的我们采用了如下两种方法来提升目标的召回率:
-
原真实框的注册方法是注册到网格⾥最匹配的 anchor 上,优化后还会同时注册到所有与该真实框的 IoU 不小于 0.25 的 anchor 上,提⾼了真实框注册的正例。
-
原来所有与真实框 IoU 小于 0.7 的 anchor 会被当错负例,优化后将该阈值减小到 0.5,降低了负例比例。
通过以上增加正例、减少负例的方法,弥补了在小尺寸上的正负例倾斜问题,提高了召回率。
更大的 batch size: 往往更大的 Batch Size 可以使训练更加稳定,获取更优的结果。在 PP-YOLO Tiny 的训练中,单卡 batch size 由 24 提升到了 32,8 卡总 batch size=8*32=256,最终得到在 COCO 数据集上体积 4.3M,精度与预测速度都较为理想的模型。
量化后压缩: 最后,结合 Paddle Inference 和 Paddle Lite 预测库支持的后量化策略,即在将权重保存成量化后的 int8 数据。这样的操作,是模型体积直接压缩到了 1.3M,而预测时使用 Paddle Lite 加载权重,会将 int8 数据还原回 float32 权重,所以对精度和预测速度⼏乎没有任何影响。
通过以上一系列优化,就得到了 1.3M 超超超轻量的 PP-YOLO tiny 模型,而算法可以通过 Paddle Lite 直接部署在麒麟 990 等轻量化芯片上,预测效果也非常理想。
4、模型测试
这里以模型 ppyoloe_plus_crn_l_80e_coco 为例,
首先直接在 PaddleDetection 链接 项目下载预训练模型,地址为 https://paddledet.bj.bcebos.com/models/ppyoloe_plus_crn_l_80e_coco.pdparams。
推理时,可以使用预训练模型,也可以使用导出的推理模型。
- 转换为Paddle Inference模型(不使用TensorRt)
python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_l_80e_coco.yml -o weights=models/ppyoloe_plus_crn_l_80e_coco.pdparams - 转换为Paddle Inference模型(使用TensorRt)
python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_l_80e_coco.yml -o weights=models/ppyoloe_plus_crn_l_80e_coco.pdparams trt=True - 转换为ONNX模型
在Paddle Inference模型基础上转换(详细说明参看 链接 )
首先需要安装pip install paddle2onnx,之后执行,paddle2onnx --model_dir output_inference/ppyoloe_plus_crn_l_80e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file ppyoloe_plus_crn_l_80e_coco.onnx
注意,ONNX模型目前只支持batch_size=1。
4.1、python测试
这里可以直接使用脚本运行测试,
4.1.1、CPU推理
```py
python tools/infer.py -c configs/ppyoloe/ppyoloe_plus_crn_l_80e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_plus_crn_l_80e_coco.pdparams --infer_dir=demo
```
对目录中的图片进行推理,运行统计信息如下:
```bash
------------------ Inference Time Info ----------------------
total_time(ms): 21291.399999999998, img_num: 14
average latency time(ms): 1520.81, QPS: 0.657542
preprocess_time(ms): 28.00, inference_time(ms): 1492.80, postprocess_time(ms): 0.00
```
这里默认使用CPU,平均推理时间约为1.5s,非常慢了。
4.1.2、GPU推理
(这里PP-YOLOE+在GPU上部署或者速度测试需要通过tools/export_model.py导出模型。)
增加参数 --device=gpu, 重新运行,结果平均推理时间为 0.07秒。
------------------ Inference Time Info ----------------------
total_time(ms): 1409.0, img_num: 14
average latency time(ms): 100.64, QPS: 9.936125
preprocess_time(ms): 30.60, inference_time(ms): 70.10, postprocess_time(ms): 0.00
4.1.3、TensorRt 推理
使用参数 --run_mode=trt_fp16 --device=gpu 和 --run_mode=trt_fp32 --device=gpu 测试。由于这里为安装python包,所以不做测试。
4.2、Paddle Inference 的 c++ 测试
这里使用FastDeploy进行测试,先进行10次warming up ,之后记录单次运行时间。注意这里FastDeploy这里的时间包含 preprocess + inference + postprocess。
4.2.1、CPU测试
测试主函数如下
void CpuInfer(const std::string& model_dir, const std::string& image_file) {
auto model_file = model_dir + sep + "model.pdmodel";
auto params_file = model_dir + sep + "model.pdiparams";
auto config_file = model_dir + sep + "infer_cfg.yml";
/*配置推理选项*/
auto option = fastdeploy::RuntimeOption();
option.UseCpu();
auto model = fastdeploy::vision::detection::PPYOLOE(model_file, params_file,
config_file, option);
if (!model.Initialized()) {
std::cerr << "Failed to initialize." << std::endl;
return;
}
auto im = cv::imread(image_file);
fastdeploy::vision::DetectionResult res;
for (int i = 0; i < 10; i++)
model.Predict(&im, &res);
auto t1 = cv::getTickCount();
if (!model.Predict(&im, &res)) {
std::cerr << "Failed to predict." << std::endl;
return;
}
auto t2 = (cv::getTickCount() - t1) / cv::getTickFrequency();
std::cout << "============ time: " << t2 << std::endl;
}
后端使用OpenVino进行推理,耗时为 0.330124秒.
[INFO] fastdeploy/runtime/runtime.cc(279)::fastdeploy::Runtime::CreateOpenVINOBackend Runtime initialized with Backend::OPENVINO in Device::CPU.
============ time: 0.330124
4.2.2、GPU测试
修改前述CPU测试代码中option参数为
option.UseGpu();
后端使用 OnnxRuntime 进行推理,耗时为 0.330124秒.
[INFO] fastdeploy/vision/common/processors/transform.cc(45)::fastdeploy::vision::FuseNormalizeCast Normalize and Cast are fused to Normalize in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(93)::fastdeploy::vision::FuseNormalizeHWC2CHW Normalize and HWC2CHW are fused to NormalizeAndPermute in preprocessing pipeline.
[INFO] fastdeploy/vision/common/processors/transform.cc(159)::fastdeploy::vision::FuseNormalizeColorConvert BGR2RGB and NormalizeAndPermute are fused to NormalizeAndPermute with swap_rb=1
[INFO] fastdeploy/runtime/runtime.cc(293)::fastdeploy::Runtime::CreateOrtBackend Runtime initialized with Backend::ORT in Device::GPU.
============ time: 0.0347463
4.2.2、TensorRt测试
(1)修改前述CPU测试代码中option参数为
option.UseGpu();
option.UseTrtBackend();
后端使用 TensorRt 进行推理,耗时为 0.0225235秒.
[INFO] fastdeploy/runtime/runtime.cc(306)::fastdeploy::Runtime::CreateTrtBackend Runtime initialized with Backend::TRT in Device::GPU.
============ time: 0.0225235
(2)继续测试,开启半精度浮点类型,
option.EnableTrtFP16()
推理耗时缩小到 0.0205824秒。
[INFO] fastdeploy/runtime/backends/tensorrt/trt_backend.cc(551)::fastdeploy::TrtBackend::BuildTrtEngine [TrtBackend] Use FP16 to inference.
[INFO] fastdeploy/runtime/backends/tensorrt/trt_backend.cc(556)::fastdeploy::TrtBackend::BuildTrtEngine Start to building TensorRT Engine...
[INFO] fastdeploy/runtime/backends/tensorrt/trt_backend.cc(643)::fastdeploy::TrtBackend::BuildTrtEngine TensorRT Engine is built successfully.
[ERROR] fastdeploy/runtime/backends/tensorrt/trt_backend.cc(239)::fastdeploy::FDTrtLogger::log 3: [runtime.cpp::nvinfer1::Runtime::~Runtime::346] Error Code 3: API Usage Error (Parameter check failed at: runtime.cpp::nvinfer1::Runtime::~Runtime::346, condition: mEngineCounter.use_count() == 1. Destroying a runtime before destroying deserialized engines created by the runtime leads to undefined behavior.
)
============ time: 0.0205824
每次运行都会编译TensorRt engine,会耗费大量时间,可以设置保存缓存文件供后续直接加载。
option.trt_option.serialize_file = model_dir + sep + "model.trt";
4.3、ONNX模型OpenCV测试
paddle 模型导出为onnx模型,参考 官网链接。导出onnx模型
paddle2onnx --model_dir output_inference/ppyoloe_plus_crn_l_80e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 12 --save_file ppyoloe_plus_crn_l_80e_coco.onnx
注意opencv支持的 opset_version 版本,这里使用这里使用 opencv 4.8 进行测试,设置为 12。
运行报错,提示不支持 nms 层
[ERROR:[email protected]] global onnx_importer.cpp:1064 cv::dnn::dnn4_v20230620::ONNXImporter::handleNode DNN/ONNX: ERROR during processing node with 5 inputs and 1 outputs: [NonMaxSuppression]:(onnx_node!p2o.NonMaxSuppression.0) from domain='ai.onnx'
OpenCV: terminate handler is called! The last OpenCV error is:
OpenCV(4.8.0) Error: Unspecified error (> Node [[email protected]]:(onnx_node!p2o.NonMaxSuppression.0) parse error: OpenCV(4.8.0) D:\opencv\opencv4.8.0\sources\modules\dnn\src\net_impl.hpp:108: error: (-2:Unspecified error) Can't create layer "onnx_node!p2o.NonMaxSuppression.0" of type "NonMaxSuppression" in function 'cv::dnn::dnn4_v20230620::Net::Impl::getLayerInstance'
> ) in cv::dnn::dnn4_v20230620::ONNXImporter::handleNode, file D:\opencv\opencv4.8.0\sources\modules\dnn\src\onnx\onnx_importer.cpp, line 1083
需要在导出推理模型时,增加参数 exclude_nms=True 将nms层移除。
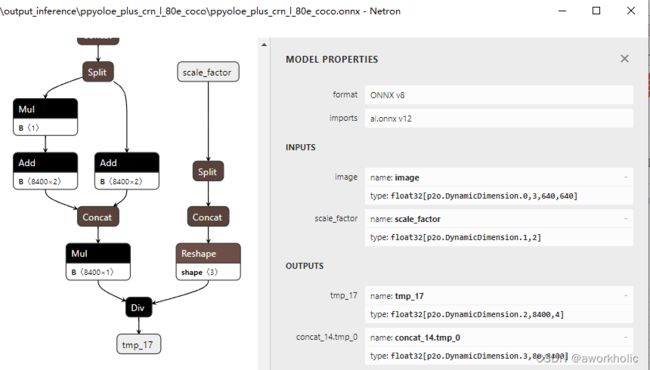
这里可以看到一处nms层之后有2个输出,维度分别为 (N,8400,4)和 (N,80,8400)。
之后重新导出onnx模型,再次执行仍然报错,提示输入为空,
OpenCV: terminate handler is called! The last OpenCV error is:
OpenCV(4.8.0) Error: Assertion failed (!inp.empty()) in cv::dnn::dnn4_v20230620::Net::Impl::updateLayersShapes, file D:\opencv\opencv4.8.0\sources\modules\dnn\src\net_impl.cpp, line 1277
这里报错的原因是因为 opencv加载模型forward推理时,未给输入 scale_factor 分配内存。
(1)第一种解决办法,修改opencv的代码
修改参考博客 opencv dnn模块 DNN中Layer的动态创建、Net自定义网络搭建示例。
net.setInputsNames({"image", "scale"});
net.setInput(blob, "image");
net.setInput(cv::Mat(1,2,CV_32F,cv::Scalar(0)), "scale");
std::vector<Mat> outs;
net.forward(outs, outNames);
运行正常,调试截图如下,和onnx描述一致。
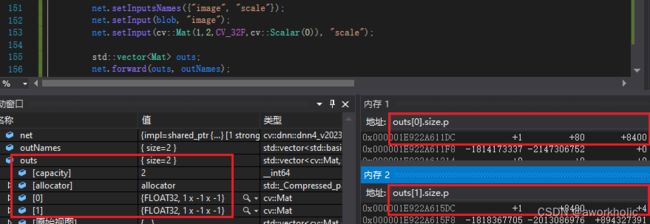
测试时,CPU推理时间为 695ms,GPU推理时间为 122ms。
(2)从导出模型下手
需要修改源代码。。。。暂不处理
实际测试时,发现输出 [1,8400,4] 的数据全部为inf,怀疑原设置scale_factor全零作为输入数据不正确,对比paddle脚本deploy\third_engine\onnx\infer.py调试的数据,应该设置如下 ,后续正常。
float scale[] = {0.5925926, 0.79012346};
net.setInput(cv::Mat(1, 2, CV_32F, scale), "scale");