关于网络协议的若干问题(四)
1、QUIC 是一个精巧的协议,它有哪些特性?
答:QUIC 还有其他特性,一个是快速建立连接。另一个是拥塞控制,QUIC 协议当前默认使用了 TCP 协议的 CUBIC(拥塞控制算法)。
CUBIC 进行了不同的设计,它的窗口增长函数仅仅取决于连续两次拥塞事件的时间间隔值,窗口增长完全独立于网络的时延 RTT。
CUBIC 的窗口大小以及变化过程如图所示。
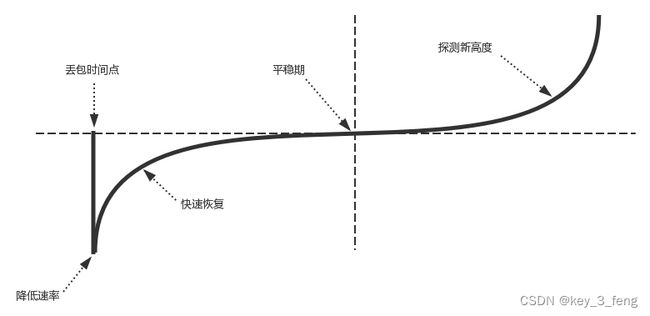
当出现丢包事件时,CUBIC 会记录这时的拥塞窗口大小,把它作为 Wmax。接着,CUBIC 会通过某个因子执行拥塞窗口的乘法减小,然后,沿着立方函数进行窗口的恢复。
从图中可以看出,一开始恢复的速度是比较快的,后来便从快速恢复阶段进入拥塞避免阶段,也即当窗口接近 Wmax 的时候,增加速度变慢;立方函数在 Wmax 处达到稳定点,增长速度为零,之后,在平稳期慢慢增长,沿着立方函数的开始探索新的最大窗口。
2、HTTP 的 keepalive 模式是什么样?
答:在没有 keepalive 模式下,每个 HTTP 请求都要建立一个 TCP 连接,并且使用一次之后就断开这个 TCP 连接。
使用 keepalive 之后,在一次 TCP 连接中可以持续发送多份数据而不会断开连接,可以减少 TCP 连接建立次数,减少 TIME_WAIT 状态连接。
然而,长时间的 TCP 连接容易导致系统资源无效占用,因而需要设置正确的 keepalive timeout 时间。当一个 HTTP 产生的 TCP 连接在传送完最后一个响应后,还需要等待 keepalive timeout 秒后,才能关闭这个连接。如果这个期间又有新的请求过来,可以复用 TCP 连接。
3、HTTPS 协议比较复杂,沟通过程太繁复,这样会导致效率问题,那有哪些手段可以解决这些问题吗?
答:通过 HTTPS 访问的确复杂,至少经历四个阶段:DNS 查询、TCP 连接建立、TLS 连接建立,最后才是 HTTP 发送数据。
首先如果使用基于 UDP 的 QUIC,可以省略掉 TCP 的三次握手。至于 TLS 的建立,如果按基于 TLS 1.2 的,双方要交换 key,经过两个来回,也即两个 RTT,才能完成握手。
在 TLS 1.3 中,握手过程中移除了 ServerKeyExchange 和 ClientKeyExchange,DH 参数可以通过 key_share 进行传输。这样只要一个来回,就可以搞定 RTT 了。
对于 QUIC 来讲,也可以这样做。当客户端首次发起 QUIC 连接时,会发送一个 client hello 消息,服务器会回复一个消息,里面包括 server config,类似于 TLS1.3 中的 key_share 交换。当客户端获取到 server config 以后,就可以直接计算出密钥,发送应用数据了。
4、.HTTPS 的双向认证流程是什么样的?
答:
5、随机数和 premaster 的含义是什么?
答:
6、RTMP 建立连接的序列是什么样的?
答:

客户端发送 C0、C1、 C2,服务器发送 S0、 S1、 S2。
首先,客户端发送 C0 表明自己的版本号,不必等对方的回复,然后发送 C1 表明自己的时间戳。
服务器只有在收到 C0 的时候,才能返回 S0,表明自己的版本号。如果版本不匹配,可以断开连接。
服务器发送完 S0 后,也不用等什么,就直接发送自己的时间戳 S1。客户端收到 S1 的时候,发一个知道了对方时间戳的 ACK C2。同理服务器收到 C1 的时候,发一个知道了对方时间戳的 ACK S2。
于是,握手完成。
7、全局负载均衡使用过程中,常常遇到失灵的情况,你知道具体有哪些情况吗?对应应该怎么来解决呢?
答:全局负载均衡失灵的时间,可以分情况来应对而导致的。
1,全局负载均器因为流量过大,失灵,此情况,是因为流量已经超过了当前机器的极限所导致的,针对此只能通过扩容来解决。
2,全局负载均衡器因为机器故障了,导致的失灵。此情况的发生,说明机器存在负载均衡器有单点问题,须通过增加备机,或者更为可靠的集群来解决。
3,全局负载均衡器因为网络故障,导致的失录此情况,案例莫过于支付宝的光纤被挖掘机挖断,此问题可通过接入更多的线路来解。
8、如果权威 DNS 连不上,怎么办?
答:一般情况下,DNS 是基于 UDP 协议的。在应用层设置一个超时器,如果 UDP 发出没有回应,则会进行重试。
DNS 服务器一般也是高可用的,很少情况下会挂。即便挂了,也会很快切换,重试一般就会成功。
对于客户端来讲,为了 DNS 解析能够成功,也会配置多个 DNS 服务器,当一个不成功的时候,可以选择另一个来尝试。
9、对于数据中心来讲,高可用是非常重要的,每个设备都要考虑高可用,那跨机房的高可用,你知道应该怎么做吗?
答:其实跨机房的高可用分两个级别,分别是同城双活和异地灾备。

同城双活,就是在同一个城市,距离大概 30km 到 100km 的两个数据中心之间,通过高速专线互联的方式,让两个数据中心形成一个大二层网络。
同城双活最重要的是,数据如何从一个数据中心同步到另一个数据中心,并且在一个数据中心故障的时候,实现存储设备的切换,保证状态能够快速切换到另一个数据中心。在高速光纤互联情况下,主流的存储厂商都可以做到在一定距离之内的两台存储设备的近实时同步。数据双活是一切双活的基础。
基于双数据中心的数据同步,可以形成一个统一的存储池,从而数据库层在共享存储池的情况下可以近实时地切换,例如 Oracle RAC。
虚拟机在统一的存储池的情况下,也可以实现跨机房的 HA,在一个机房切换到另一个机房。
SLB 负载均衡实现同一机房的各个虚拟机之间的负载均衡。GSLB 可以实现跨机房的负载均衡,实现外部访问的切换。
如果在两个数据中心距离很近,并且大二层可通的情况下,也可以使用 VRRP 协议,通过 VIP 方式进行外部访问的切换。
异地灾备。
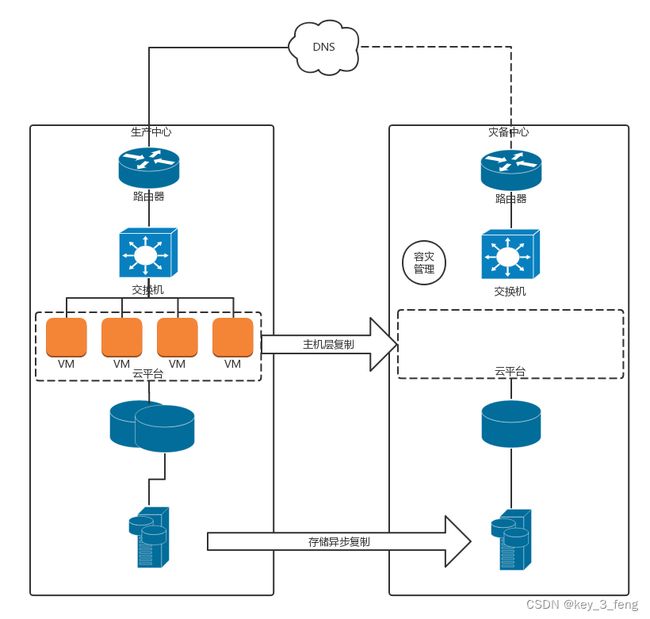
异地灾备的第一大问题还是数据的问题,也即生产数据中心的数据如何备份到容灾数据中心。由于异地距离比较远,不可能像双活一样采取近同步的方式,只能通过异步的方式进行同步。可以预见的问题是,容灾切换的时候,数据会丢失一部分。
由于容灾数据中心平时是不用的,不是所有的业务都会进行容灾,否则成本太高。
对于数据的问题,我比较建议从业务层面进行容灾。由于数据同步会比较慢,可以根据业务需求高优先级同步重要的数据,因而容灾的层次越高越好。
例如,有的用户完全不想操心,直接使用存储层面的异步复制。对于存储设备来讲,它是无法区分放在存储上的虚拟机,哪台是重要的,哪台是不重要的,只会完全根据块进行复制,很可能就会先复制了不重要的虚拟机。
如果用户想对虚拟机做区分,则可以使用虚拟机层面的异步复制。用户知道哪些虚拟机更重要一些,哪些虚拟机不重要,则可以先同步重要的虚拟机。
对业务来讲,如果用户可以根据业务层情况,在更细的粒度上区分数据是否重要。重要的数据,例如交易数据,需要优先同步;不重要的数据,例如日志数据,就不需要优先同步。
在有异地容灾的情况下,可以平时进行容灾演练,看容灾数据中心是否能够真正起作用,别容灾了半天,最后用的时候掉链子。
此文章为10月Day13学习笔记,内容来源于极客时间《趣谈网络协议》,推荐该课程。