hibernate中@Entity和@Table的区别
原文章网址:点击打开
Java Persistence API定义了一种定义,可以将常规的普通Java对象(有时被称作POJO)映射到数据库。
这些普通Java对象被称作Entity Bean。
除了是用Java Persistence元数据将其映射到数据库外,Entity Bean与其他Java类没有任何区别。
事实上,创建一个Entity Bean对象相当于新建一条记录,删除一个Entity Bean会同时从数据库中删除对应记录,修改一个Entity Bean时,容器会自动将Entity Bean的状态和数据库同步。
Java Persistence API还定义了一种查询语言(JPQL),具有与SQL相类似的特征,只不过做了裁减,以便处理Java对象而非原始的关系表。
hibernate中@Entity和@Table的区别:
@Entity说明这个class是实体类,并且使用默认的orm规则,即class名即数据库表中表名,class字段名即表中的字段名
如果想改变这种默认的orm规则,就要使用@Table来改变class名与数据库中表名的映射规则,@Column来改变class中字段名与db中表的字段名的映射规则
@Entity注释指名这是一个实体Bean,@Table注释指定了Entity所要映射带数据库表,其中@Table.name()用来指定映射表的表名。
如果缺省@Table注释,系统默认采用类名作为映射表的表名。实体Bean的每个实例代表数据表中的一行数据,行中的一列对应实例中的一个属性。@Column注释定义了将成员属性映射到关系表中的哪一列和该列的结构信息,属性如下:
1)name:映射的列名。如:映射tbl_user表的name列,可以在name属性的上面或getName方法上面加入;
2)unique:是否唯一;
3)nullable:是否允许为空;
4)length:对于字符型列,length属性指定列的最大字符长度;
5)insertable:是否允许插入;
6)updatetable:是否允许更新;
7)columnDefinition:定义建表时创建此列的DDL;
8)secondaryTable:从表名。如果此列不建在主表上(默认是主表),该属性定义该列所在从表的名字。
@Id注释指定表的主键,它可以有多种生成方式:1)TABLE:容器指定用底层的数据表确保唯一;
2)SEQUENCE:使用数据库德SEQUENCE列莱保证唯一(Oracle数据库通过序列来生成唯一ID);
3)IDENTITY:使用数据库的IDENTITY列莱保证唯一;
4)AUTO:由容器挑选一个合适的方式来保证唯一;
5)NONE:容器不负责主键的生成,由程序来完成。@GeneratedValue注释定义了标识字段生成方式。
@Temporal注释用来指定java.util.Date或java.util.Calender属性与数据库类型date、time或timestamp中的那一种类型进行映射。
@Temporal(value=TemporalType.TIME)
@Entity
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private Long id;
private String name;
private int age;
private String addree;
// Getters and Setters
}
如果没有 @javax.persistence.Entity 和 @javax.persistence.Id 这两个注解的话,它完全就是一个典型的 POJO 的 Java 类,现在加上这两个注解之后,就可以作为一个实体类与数据库中的表相对应。他在数据库中的对应的表为:
图 1. Employee 表对应的 ER 图
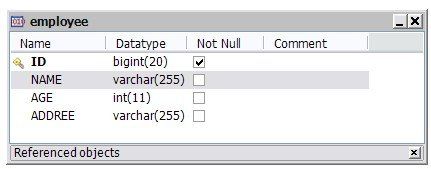
映射规则:
1. 实体类必须用 @javax.persistence.Entity 进行注解;
2. 必须使用 @javax.persistence.Id 来注解一个主键;
3. 实体类必须拥有一个 public 或者 protected 的无参构造函数,之外实体类还可以拥有其他的构造函数;
4. 实体类必须是一个顶级类(top-level class)。一个枚举(enum)或者一个接口(interface)不能被注解为一个实体;
5. 实体类不能是 final 类型的,也不能有 final 类型的方法;
6. 如果实体类的一个实例需要用传值的方式调用(例如,远程调用),则这个实体类必须实现(implements)java.io.Serializable 接口。
将一个 POJO 的 Java 类映射成数据库中的表如此简单,这主要得益于 Java EE 5种引入的 Configuration by Exception 的理念,这个理念的核心就是容器或者供应商提供一个缺省的规则,在这个规则下程序是可以正确运行的,如果开发人员有特殊的需求,需要改变这个默认的规则,那么就是对默认规则来说就是一个异常(Exception)。
如上例所示:默认的映射规则就是数据库表的名字和对应的 Java 类的名字相同,表中列的名字和 Java 类中相对应的字段的名字相同。
现在我们可以改变这种默认的规则:
清单 2. 使用 @Table 和 @Column 注解修改映射规则
@Entity
@Table(name="Workers")
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
private Long id;
@Column(name="emp_name", length=30)
private String name;
@Column(name="emp_age", nullable=false)
private int age;
@Column(name="emp_address", nullable=false ,unique=true)
private String addree;
// Getters and Setters
}
首先我们可以可以使用
@Javax.persistence.Table 这个注解来改变 Java 类在数据库表种对应的表名。这个注解的定义如下:
@javax.persistence.Column 注解,定义了列的属性,你可以用这个注解改变数据库中表的列名(缺省情况下表对应的列名和类的字段名同名);指定列的长度;或者指定某列是否可以为空,或者是否唯一,或者能否更新或插入。
从它的定义可以看出他只可以用在类中的方法前面或者字段前面。
其中 name 属性的值为数据库中的列名,unique 属性说明该烈是否唯一,nullable 属性说明是否可以为空,length 属性指明了该列的最大长度等等。其中 table 属性将在 @SecondaryTable 的使用中已有过介绍。
JPA 中两种注解方式
JPA 中将一个类注解成实体类(entity class)有两种不同的注解方式:基于属性(property-based)和基于字段(field-based)的注解。
1,基于字段的注解,就是直接将注解放置在实体类的字段的前面。前面的 Employee 实体类就是使用的这种注解方式;
2,基于属性的注解,就是直接将注解放置在实体类相应的 getter 方法前面,而不是 setter 方法前面(这一点和 Spring 正好相反)。前面的 Employee 实体类如果使用基于属性注解的方式就可以写成如下形式。
但是同一个实体类中必须并且只能使用其中一种注解方式,要么是基于属性的注解,要么是基于字段的注解。两种不同的注解方式,在数据库中对应的数据库表是相同的,没有任何区别,开发人员可以根据自己的喜好任意选用其中一种注解方式。
@SecondaryTable 的使用
上面介绍的几个例子都是一个实体类映射到数据库中的一个表中,那么能否将一个实体类映射到数据库两张或更多表中呢表中呢。在有些情况下如数据库中已经存在原始数据类型,并且要求不能更改,这个时候如果能实现一个实体类对应两张或多张表的话,将是很方便的。JPA2.0 中提供了一个 @SecondaryTablez 注解(annotation)就可以实现这种情况。下面用一个例子说明一下这个注解的使用方法:
清单 6. @SecondaryTable 的使用
@Entity
@SecondaryTables({
@SecondaryTable(name = "Address"),
@SecondaryTable(name = "Comments")
})
public class Forum implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
private Long id;
private String username;
private String password;
@Column(table = "Address", length = 100)
private String street;
@Column(table = "Address", nullable = false)
private String city;
@Column(table = "Address")
private String conutry;
@Column(table = "Comments")
private String title;
@Column(table = "Comments")
private String Comments;
@Column(table = "Comments")
private Integer comments_length;
// Getters and Setters
}
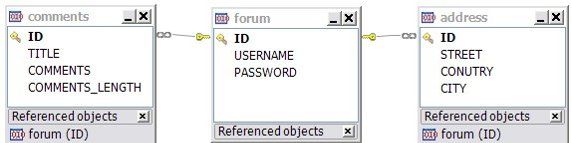
清单 5 中定义了两个 Secondary 表,分别为 Address 和 Comments,
同时在 Forum 实体类中也通过 @Column 注解将某些子段分别分配给了这两张表,那些 table 属性得值是 Adress 的就会存在于 Address 表中,
同理 table 属性的值是 Comments 的就会存在于 Comments 表中。那些没有用 @Column 注解改变属性默认的字段将会存在于 Forum 表中。
图 4 就是持久化后在数据库中对应的表的 ER 图,从图中可看出来,这些字段如我们预料的一样被映射到了不同的表中。
图 4. @SecondaryTable 持久化后对赢得 ER 图
嵌套映射
在使用嵌套映射的时候首先要有一个被嵌套的类,清单 5 中 Address 实体类使用 @Embeddable 注解,说明这个就是一个可被嵌套的类,与 @EmbeddedId 复合主键策略中的主键类(primary key class)稍有不同的是,这个被嵌套类不用重写 hashCode() 和 equals() 方法,复合主键将在后面进行介绍。
清单 7. 被嵌套类
@Embeddable
public class Address implements Serializable {
private String street;
private String city;
private String province;
private String country;
// Getters and Setters
}
清单 6 中 Employee 实体类是嵌套类的拥有者,其中使用了 @Embedded 注解将 Address 类嵌套进来了。
清单 8. 嵌套类的使用者
@Entity
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private String email;
private String cellPhone;
@Embedded
private Address address;
// Getters and Setters
}
清单 7 是持久化后生成的数据库表,可以看出被嵌套类的属性,也被持久化到了数据库中,默认的表名就是嵌套类的拥有者的类名。
清单 9. 使用嵌套类生成的表结构
CREATE TABLE `employee` ( `ID` bigint(20) NOT NULL, `EMAIL` varchar(255) default NULL, `NAME` varchar(255) default NULL, `CELLPHONE` varchar(255) default NULL, `STREET` varchar(255) default NULL, `PROVINCE` varchar(255) default NULL, `CITY` varchar(255) default NULL, `COUNTRY` varchar(255) default NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;
被嵌套类的注解方式,field 方式或者 property 方式,依赖于嵌套类的拥有者。上面例子中的 Employee 实体类采用的是 field 注解方式,那么在持久化的过程中,被嵌套类 Address 也是按照 field 注解方式就行映射的。
我们也可以通过 @Access 注解改变被嵌套类映射方式,清单 8 通过使用 @Access 注解将 Address 被嵌套类的注解方式设定成了 property 方式。清单 9 Employee 仍然采用 filed 注解方式。这种情况下,持久化的时候,被嵌套类就会按照自己设定的注解方式映射,而不会再依赖于嵌套类的拥有者的注解方式。但这并不会映射的结果。
清单 10. 基于 property 方式注解的被嵌套类
@Embeddable
@Access(AccessType.PROPERTY)
public class Address implements Serializable {
private String street;
private String city;
private String province;
private String country;
@Column(nullable=false)
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
@Column(nullable=false,length=50)
public String getCountry() {
return country;
}
public void setCountry(String country) {
this.country = country;
}
@Column(nullable=false,length=20)
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getStreet() {
return street;
}
public void setStreet(String street) {
this.street = street;
}
}
清单 11. 基于 field 方式注解
@Entity
@Access(AccessType. FIELD)
public class Employee implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String name;
private String email;
private String cellPhone;
@Embedded
private Address address;
// Getters and Setters
}
事先设定被嵌套类的注解方式,是一种应该大力提倡的做法,因为当同一个类被不同的注解方式的类嵌套时,可能会出现一些错误。
总结
简单映射是 ORM,也就是对象关系映射中较为简单的一种,他只是数据库表与类之间的一一对应,并未涉及表之间的关系,也就未涉及类与类之间的关系,也可以说是其他如继承映射,关联关系映射的基础,所以说熟悉并掌握简单关系映射还是很有必要的。
Hibernate中关于@MappedSuperclass和@Entity的区别
package com.entity.base;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.MappedSuperclass;
@MappedSuperclass
public class BaseEntity {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Integer id;
如果上诉代码中在使用@MappedSuperclass标签的地方使用了@Entity标签的话,
会让hibernate错误的认为所有的Entity都是在一张数据表中的。
http://www.voidcn.com/blog/kunshan_shenbin/article/p-4753265.html
JPA Java Persistence API,是Java EE 5的标准ORM接口,也是ejb3规范的一部分。
Hibernate,当今很流行的ORM框架,是JPA的一个实现,但是其功能是JPA的超集。
JPA和Hibernate之间的关系,可以简单的理解为JPA是标准接口,Hibernate是实现。那么Hibernate是如何实现与JPA的这种关系的呢。Hibernate主要是通过三个组件来实现的,及hibernate-annotation、hibernate-entitymanager和hibernate-core。
hibernate-annotation是Hibernate支持annotation方式配置的基础,它包括了标准的JPA annotation以及Hibernate自身特殊功能的annotation。
hibernate-core是Hibernate的核心实现,提供了Hibernate所有的核心功能。
hibernate-entitymanager实现了标准的JPA,可以把它看成hibernate-core和JPA之间的适配器,它并不直接提供ORM的功能,而是对hibernate-core进行封装,使得Hibernate符合JPA的规范。
Jpa是一种规范,而Hibernate是它的一种实现。除了Hibernate,还有EclipseLink(曾经的toplink),OpenJPA等可供选择,所以使用Jpa的一个好处是,可以更换实现而不必改动太多代码。
在play中定义Model时,使用的是jpa的annotations,比如javax.persistence.Entity, Table, Column, OneToMany等等。但它们提供的功能基础,有时候想定义的更细一些,难免会用到Hibernate本身的annotation。我当时想,jpa这么弱还要用它干什么,为什么不直接使用hibernate的?反正我又不会换成别的实现。
因为我很快决定不再使用hibernate,这个问题就一直放下了。直到我现在在新公司,做项目要用到Hibernate。
我想抛开jpa,直接使用hibernate的注解来定义Model,很快发现了几个问题:
- jpa中有Entity, Table,hibernate中也有,但是内容不同
- jpa中有Column,OneToMany等,Hibernate中没有,也没有替代品
我原以为hibernate对jpa的支持,是另提供了一套专用于jpa的注解,但现在看起来似乎不是。一些重要的注解如Column, OneToMany等,hibernate没有提供,这说明jpa的注解已经是hibernate的核心,hibernate只提供了一些补充,而不是两套注解。要是这样,hibernate对jpa的支持还真够足量,我们要使用hibernate注解就必定要使用jpa。