PyTorch Quantization简介
基于YOLOv5实践目标检测的PTQ与QAT量化
PyTorch Quantization
PyTorch Quantization是一种在机器学习中使用的技术,用于减少深度神经网络的大小和计算需求,使其更适合在内存和处理能力有限的设备上部署。
量化是一种将大量数值表示为较小的离散值的过程,这可以减少神经网络的内存和计算需求。PyTorch提供了各种量化方法,包括训练后静态量化、动态量化和量化感知训练。
训练后静态量化涉及在模型训练后对权重和激活进行量化。动态量化则涉及使用量化感知运行时在推理期间动态量化模型。量化感知训练涉及在训练模型时考虑量化,以便可以在训练后直接对其进行量化。
PyTorch Quantization可以帮助减少神经网络的大小和计算需求,使其更适合在资源受限的设备上部署,如移动电话、嵌入式系统和物联网设备。
PyTorch Quantization是一个工具包,用于训练和评估具有模拟量化的PyTorch模型。PyTorch Quantization API支持将 PyTorch 模块自动转换为其量化版本。转换也可以使用 API 手动完成,这允许在不想量化所有模块的情况下进行部分量化。例如,一些层可能对量化比较敏感,对其不进行量化可提高任务精度。
PyTorch Quantization的量化模型可以直接导出到ONNX,并由TensorRT 8.0或者更高版本导入进行转换Engine。
1、量化函数
ensor_quant和fake_tensor_ quant是量化张量的2个基本函数:
- fake_tensor_quant 返回伪量化张量(浮点值)。
- tensor_quant 返回量化后的张量(整数值)以及其对应的缩放值Scale。
这个错误可能是由于您正在尝试从PyPI(Python Package Index)安装"pytorch-quantization"模块,而该模块实际上是托管在NVIDIA Python Package Index上的。因此,您需要先安装"nvidia-pyindex"模块,然后再安装"pytorch-quantization"模块。
您可以使用以下命令先安装"nvidia-pyindex"模块:
pip install nvidia-pyindex
然后再使用以下命令安装"pytorch-quantization"模块:
pip install pytorch-quantization
如果您使用的是Anaconda环境,可以使用以下命令来安装:
conda install -c nvidia nvidia-pyindex
conda install -c pytorch pytorch-quantization
安装完成后,重新运行您的代码即可。
import torch
from pytorch_quantization import tensor_quant
#国定种子12345并生成随机输入X为:
# tensor([0.9817,8796,0,9921, 0,4611, 0,0832, 0,1784,0,3674, 0,5676,0,3376,0,2119])
torch.manual_seed(12345)
x = torch.rand(10)
print(f"x:{x}")
#伪量化张量 x:
#tensor([0.9843, 0.8828,0.9921, 0.4609 .0859, 0,1797, 0.3672, 0.5703, 0.3359, 0.2109])
fake_quant_x = tensor_quant.fake_tensor_quant(x, x.abs().max())
print(f"fake_quant_x:{fake_quant_x}")
# 量化张量x,scale=128.8857:
# tensor([126.,113., 127.,59., 11., 23., 47., 73.,43.,27.J)
quant_x, scale = tensor_quant.tensor_quant(x, x.abs().max())
print(f"quant_x:{quant_x},scale:{scale}")
x:tensor([0.9817, 0.8796, 0.9921, 0.4611, 0.0832, 0.1784, 0.3674, 0.5676, 0.3376,
0.2119])
fake_quant_x:tensor([0.9843, 0.8828, 0.9921, 0.4609, 0.0859, 0.1797, 0.3672, 0.5703, 0.3359,
0.2109])
quant_x:tensor([126., 113., 127., 59., 11., 23., 47., 73., 43., 27.]),scale:128.00567626953125
这段代码首先使用了PyTorch库生成了一个10个元素的随机张量x,并使用f-string进行格式化输出。接着,使用了pytorch_quantization库中的fake_tensor_quant和tensor_quant函数对x进行了伪量化和量化操作,并使用f-string进行格式化输出。
在输出结果中,x表示原始随机张量,fake_quant_x表示伪量化后的张量,quant_x表示量化后的张量,scale表示用于反量化的缩放因子。
通过这段代码的运行结果,可以看到伪量化和量化后的张量分别被转换为了-1到1和-128到127的范围内的8位整数,这是PyTorch
Quantization库的常见量化方法之一。
2、描述符和量化器
描述符(Descriptor)和量化器(Quantizer)都是在深度学习中常用的概念。它们的作用是将神经网络中的权重和激活值等参数进行优化,从而提高深度神经网络的性能和效率。
描述符是一种用于描述神经网络中权重和激活值等参数的方法,它可以将这些参数转换为一组离散的数值,从而降低神经网络的计算复杂度,提高计算速度。常见的描述符包括二进制描述符(Binary Descriptor)、三值描述符(Ternary Descriptor)等。
量化器是一种用于将神经网络中的参数量化为离散数值的方法,它可以将神经网络中的权重和激活值等参数转换为一组离散的数值,从而降低神经网络的计算复杂度,提高计算速度。常见的量化器包括定点量化器(Fixed-Point Quantizer)、浮点量化器(Floating-Point Quantizer)等。
描述符和量化器可以结合使用,用于对神经网络进行优化。例如,可以使用二进制描述符和定点量化器对神经网络进行优化,从而获得更快的推理速度和更小的存储空间。此外,还可以使用自适应量化器(Adaptive Quantizer)等方法,根据神经网络中不同层的特点,对不同的参数使用不同的描述符和量化器,以达到更好的优化效果。
总的来说,描述符和量化器是深度学习中非常重要的概念,它们的使用可以提高神经网络的性能和效率,为实际应用带来更好的效果。
QuantDescriptor是用来定义张量应如何量化;PyTorch Quantization提供了一些预定义QuantDescriptor,例如:
1、QUANT_DESC_8BIT_PER_TENSOR
2、QUANT_DESC_8BIT_CONV2D_WEIGHT_PER_CHANNEL
TensorQuantizer 可以量化、伪量化或收集张量的统计信息。它与 QuantDescriptor 一起使用,后者描述了如何量化张量。
在 TensorQuantizer 之上分层的是量化模块,这些模块被设计为 PyTorch 全精度模块的替代品。这些是使用 TensorQuantizer 对模块的权重和输入进行伪量化或收集统计信息的方便模块。

3、量化模块
量化模块(Quantization Module)是一种针对深度学习中的神经网络进行优化的方法,它可以将神经网络中的参数进行量化,从而降低计算复杂度,减小模型大小,提高推理速度和功耗效率。
量化模块通常包括以下几个部分:
- 量化器(Quantizer):用于将神经网络中的权重和激活值等参数进行量化,得到一组离散的数值。
- 描述符(Descriptor):用于描述神经网络中的权重和激活值等参数,将其转换为一组离散的数值。
- 反量化器(Dequantizer):用于将量化后的参数反量化为原始的浮点数值,以便进行后续的计算。
- 量化误差计算器(Quantization Error Calculator):用于计算量化误差,以便进行优化。
量化模块的优点在于可以将神经网络中的参数转换为离散的数值,从而降低计算复杂度,减小模型大小,提高推理速度和功耗效率,特别是在移动设备等资源受限的环境下,量化模块的优势更加明显。同时,量化模块还可以通过优化量化策略,减小量化误差,提高模型的精度和鲁棒性。
目前,主流的深度学习框架都提供了量化模块的支持,例如TensorFlow、PyTorch等,可以方便地对神经网络进行量化优化。
有两种主要类型的模块,Conv和Linear。两者都可以取代torch.nn版本,并对权重和激活应用量化。
from torch import nn
from pytorch_quantization import tensor_quant
import pytorch_quantization.nn as quant_nn
# PyTorch模型
fc1 = nn.Linear(in_features, out_features, bias=True)
conv1 = nn.Conv2d(in_channels, out_channels, kernel_size)
# 量化版本的模型
quant_fc1 = quant_nn.Linear(
in_features, out_features, bias=True,
quant_desc_input=tensor_quant.QUANT_DESC_8BIT_PER_TENSOR,
quant_desc_weight=tensor_quant.QUANT_DESC_8BIT_LINEAR_WEIGHT_PER_ROW
)
quant_conv1 = quant_nn.Conv2d(
in_channels, out_channels, kernel_size,
quant_desc_input=tensor_quant.QUANT_DESC_8BIT_PER_TENSOR,
quant_desc_weight=tensor_quant.QUANT_DESC_8BIT_CONV2D_WEIGHT_PER_CHANNEL
)
这段代码展示了如何使用PyTorch
Quantization库中的量化模块对神经网络进行量化优化。具体来说,使用了PyTorch中的nn模块定义了一个全连接层fc1和一个二维卷积层conv1,然后使用PyTorch
Quantization库中的量化模块quant_nn对这两个层进行量化优化。量化优化过程中,使用了8位量化描述符(Quant Desc)对输入、权重和偏置进行量化。对于全连接层,采用了8位线性量化描述符(Quant
Desc 8BIT LINEAR WEIGHT PER ROW)对权重进行量化,对于卷积层,采用了8位卷积权重量化描述符(Quant
Desc 8BIT CONV2D WEIGHT PER CHANNEL)对权重进行量化。通过这种量化优化方式,可以将神经网络中的参数量化为离散的数值,从而提高深度神经网络的性能和效率,减少计算复杂度和存储空间,特别是在移动设备等资源受限的环境下,量化优化的优势更加明显。
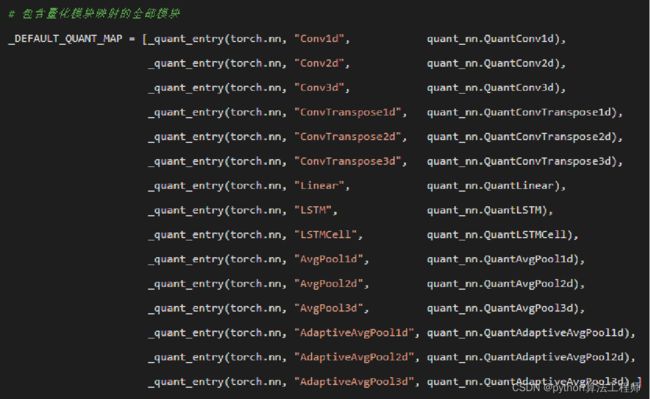
量化工具提供了以下几个量化模块:
QuantConv1d、QuantConv2d、Quant
Conv3d、QuantConvTranspose1d、quantConvTranspose 2d、QuantiConvTransbose
3d、QuantiLinear、QuantAvgPool1d、QuantAvg Pool2d、Quant AvgPool
3d、QuantMaxPool1d、QuantMax Pool2D、Quant MaxPool3d
4、训练后量化
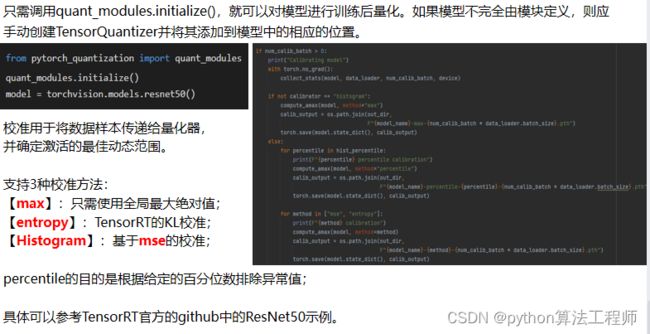
训练后量化(Post-Training Quantization)是一种在训练完成后对深度神经网络进行量化优化的方法。相比于训练中量化,训练后量化更加灵活,可以适用于各种不同的深度神经网络结构和训练框架,同时也可以在训练完成后再进行优化,不会影响模型的训练过程。
训练后量化通常包括以下几个步骤:
- 定义量化器:选择合适的量化器,例如定点量化器或浮点量化器,并设置量化位数和量化误差等参数。
- 进行量化:将训练完成的深度神经网络中的权重、激活值等参数进行量化,得到一组离散的数值。
- 微调:重新训练量化后的模型,以进一步减小量化误差,提高模型的精度和鲁棒性。
- 部署:将量化后的模型部署到目标设备上,并进行推理测试,以验证模型的性能和效果。
训练后量化的优点在于可以在保持模型精度的前提下,显著减小模型的计算复杂度和存储空间,提高模型的推理速度和功耗效率。此外,由于训练后量化是在训练完成后进行的,因此不会影响模型的训练过程,更加灵活和适用于各种不同的深度神经网络结构和训练框架。
目前,主流的深度学习框架都提供了训练后量化的支持,例如TensorFlow、PyTorch等,可以方便地对深度神经网络进行量化优化。
5、量化感知训练
量化感知训练(Quantization-Aware Training)是一种在训练过程中对深度神经网络进行量化优化的方法。与训练后量化相比,量化感知训练可以更好地保持模型的精度和鲁棒性,同时也可以在量化优化的基础上进一步减小量化误差,提高模型的性能和效果。
量化感知训练通常包括以下几个步骤:
- 定义量化器:选择合适的量化器,例如定点量化器或浮点量化器,并设置量化位数和量化误差等参数。
- 定义损失函数:选择适合的损失函数,例如交叉熵损失函数或均方误差损失函数。
- 进行前向传播:将输入数据送入深度神经网络,进行前向传播,得到模型的输出。
- 计算损失函数:将模型的输出与标签数据进行比较,计算损失函数。
- 进行反向传播:根据损失函数计算梯度,进行反向传播,更新模型的参数。
- 进行量化:在反向传播时,将梯度进行量化,得到一组离散的梯度值。
- 更新模型:根据量化后的梯度值更新模型的参数。
重复以上步骤:重复以上步骤,直到模型收敛或达到预定的训练轮数。
量化感知训练的优点在于可以在训练过程中对深度神经网络进行量化优化,提高模型的精度和鲁棒性,同时还可以进一步减小量化误差,提高模型的性能和效果。此外,量化感知训练可以根据不同的量化器和损失函数进行灵活的配置,适用于各种不同的深度神经网络结构和训练任务。
目前,主流的深度学习框架都提供了量化感知训练的支持,例如TensorFlow、PyTorch等,可以方便地对深度神经网络进行量化优化。
量化感知训练基于直通估计(STE)导数近似,通常大家都叫QAT。校准完成后,量化感知训练只需选择一个训练机制并继续训练校准模型。通常,它不需要微调很长时间。
QAT通常使用大约10%的原始训练计划,从初始训练学习率的1%开始,以及余弦退火学习率计划,该计划遵循余弦周期的递减一半,下降到初始微调学习率(初始训练学习速率的0.01%)的1%。
量化感知训练(本质上是一个离散的数值优化问题)不是数学上解决的问题。根据经验,给出以下一些建议:
1、为了使 STE 近似效果良好,最好使用较小的学习速率。大的学习速率更可能放大STE近似引入的方差,并破坏训练的网络。
2、在训练期间不要改变量化表示(Scale尺度),至少不要太频繁。每一步都改变尺度,实际上就像每一步改变数据格式一样,这很容易影响收敛。
6、导出ONNX
导出到ONNX的目标是通过TensorRT而不是ONNXRuntime部署推理。因此,只将伪量化模型导出为TensorRT将采用的形式。伪量化将被分解为一对QuantizeLinear/DequantizeLinean
ONNX算子。TensorRT将获取该图,并在int8中以最优化的方式执行该图。
首先将TensorQuantizer的静态成员设置为使用Pytorch自己的伪量化函数: quant_nn.TensorQuantizer.use_fb_fake_quant = True
此时的伪量化模型便可以像其他Torch模型一样导出到ONNX,例如:
from pytorch_quantization import nn as quant_nn
from pytorch_quantization import quant_modules
import torchvision.models as models
# 开启 FB 伪量化
quant_nn.TensorQuantizer.use_fb_fake_quant = True
# 初始化量化模块
quant_modules.initialize()
# 加载量化后的 ResNet50 模型
model = models.resnet50()
state_dict = torch.load("quant_resnet50-entropy-1024.pth", map_location="cpu")
model.load_state_dict(state_dict)
model.cuda()
# 创建虚拟输入
dummy_input = torch.randn(128, 3, 224, 224, device='cuda')
# 导出量化后的 ONNX 模型
input_names = ["actual_input_1"]
output_names = ["output1"]
torch.onnx.export(
model, dummy_input, "quant_resnet50.onnx",
verbose=True, opset_version=13, input_names=input_names, output_names=output_names,
enable_onnx_checker=False
)
在这个版本中,我们添加了一些必要的导入语句,例如torch和torchvision。我们还创建了虚拟输入,并设置了输入和输出名称,以便在导出 ONNX 模型时使用。
此外,我们还开启了 FB 伪量化,并初始化了量化模块。最后,我们使用torch.onnx.export()函数导出了量化后的 ONNX 模型,并禁用了 ONNX 检查器(因为 ONNX 检查器可能会检测到不支持的操作,从而导致导出失败)。
如果你的目标是通过 TensorRT 而不是 ONNX Runtime 部署推理,则需要执行以下步骤:
在导出 ONNX 模型之前,确保已经使用 PyTorch 或其他支持的深度学习框架将模型转换为 ONNX 格式。
安装 NVIDIA TensorRT 软件包,可以在 NVIDIA 的官方网站上下载和安装。
使用 TensorRT 的 ONNX Parser 将 ONNX 模型转换为 TensorRT 可以理解的格式。你可以使用以下命令将 ONNX 模型转换为 TensorRT:
import tensorrt as trt
import onnx
import os
onnx_model_path = 'path/to/onnx/model.onnx'
engine_path = 'path/to/tensorrt/engine.plan'
# 创建 TensorRT builder 和 logger
builder = trt.Builder(logger)
network = builder.create_network()
# 创建 ONNX parser
parser = trt.OnnxParser(network, logger)
# 导入 ONNX 模型
with open(onnx_model_path, 'rb') as model:
if not parser.parse(model.read()):
for error in range(parser.num_errors):
print(parser.get_error(error))
# 创建 TensorRT engine
engine = builder.build_cuda_engine(network)
# 保存 TensorRT engine
with open(engine_path, 'wb') as f:
f.write(engine.serialize())
这个示例代码假设你已经将 ONNX 模型保存到了 path/to/onnx/model.onnx。它将创建一个 TensorRT builder 和 logger,使用 ONNX parser 将模型导入到 TensorRT 网络中,然后使用 TensorRT builder 构建 CUDA engine,并将其序列化到 path/to/tensorrt/engine.plan。
在部署推理时,加载 TensorRT engine 并执行推理。可以使用以下代码加载 TensorRT engine 并执行推理:
import tensorrt as trt
import numpy as np
engine_path = 'path/to/tensorrt/engine.plan'
# 加载 TensorRT engine
with open(engine_path, 'rb') as f:
engine_data = f.read()
runtime = trt.Runtime(trt.Logger(trt.Logger.WARNING))
engine = runtime.deserialize_cuda_engine(engine_data)
# 创建 TensorRT context
context = engine.create_execution_context()
# 准备输入数据
input_shape = (batch_size, input_channels, input_height, input_width)
input_data = np.random.randn(*input_shape).astype(np.float32)
# 分配 GPU 内存
input_binding = engine.get_binding_index('input')
input_size = np.product(input_shape) * np.dtype(np.float32).itemsize
input_memory = cuda.mem_alloc(input_size)
# 将输入数据复制到 GPU 内存
cuda.memcpy_htod(input_memory, input_data)
# 分配 GPU 内存用于输出结果
output_binding = engine.get_binding_index('output')
output_shape = tuple(context.get_binding_shape(output_binding))
output_size = np.product(output_shape) * np.dtype(np.float32).itemsize
output_memory = cuda.mem_alloc(output_size)
# 执行推理
bindings = [int(input_memory), int(output_memory)]
context.execute_v2(bindings)
# 将输出结果从 GPU 内存复制回主机内存
output_data = np.zeros(output_shape, dtype=np.float32)
cuda.memcpy_dtoh(output_data, output_memory)
这个示例代码假设你已经将 TensorRT engine 序列化到了 path/to/tensorrt/engine.plan。它将加载 TensorRT engine,并使用 TensorRT context 执行推理。在执行推理之前,它将分配 GPU 内存用于输入和输出数据,并将输入数据复制到 GPU 内存中。在执行推理之后,它将从 GPU 内存中复制输出数据,并将其存储在 output_data 中。
总的来说,将 ONNX 模型转换为 TensorRT engine 并执行推理需要一些额外的步骤,但它可以提供更高的推理性能和更低的延迟。