C++深度优化——无锁队列实现及测试
最近在研究无锁队列,从网上学习到了lock-free的定义,特此摘录如下:
如果涉及到共享内存的多线程代码在多线程执行下不可能互相影响导致被hang住,不管OS如何调度线程,至少有一个线程在做有用的事,那么就是lock-free。
摘录自:C++ memory order循序渐进(一)—— 多核编程和memory model_c++ 多核编程-CSDN博客
我总结:lock-free其实就是存在一种可回滚的机制,在尝试失败后恢复到最新的状态继续尝试。
网上有很多无锁队列的实现,看了几个,发现都是有BUG的,也包括我之前写的关于无锁队列的实现。比如:
多线程---解析无锁队列的原理与实现_多线程无锁队列_攻城狮百里的博客-CSDN博客
总结了一下这些实现的最根本问题:在队列中只有一个元素的时候,在弹出该元素的同时,push可能正在修改该元素的next成员。也就是说我们的计算机现在没有一个原子操作在验证尾指针没变的同时修改其成员。现在的原子操作能做到的只是在确认指针没变的时候修改指针本身。
于是我实现了一个目前看上去没有bug的单生产者单消费者的队列,如下:
#include
template
class lock_free_queue
{
private:
struct node_t
{
val_t v;
std::atomic next;
node_t():v(), next(nullptr){}
node_t(const val_t& v_):v(v_), next(nullptr)
{}
};
std::atomic m_head, m_tail;
std::atomic m_tail_changed;
public:
lock_free_queue():m_head(new node_t()), m_tail(m_head.load()), m_tail_changed(false)
{}
void push(const val_t& v)
{
node_t* p_newnode = new node_t(v); //* 创建一个新的对象
node_t* pnullptr = nullptr,*p_oldtail = nullptr;
do
{
pnullptr = nullptr;
p_oldtail = m_tail.load(); //* 这里如果挂起,下面的p_oldtail->next就会崩溃
std::atomic_thread_fence(std::memory_order_acquire);
if ( !m_tail_changed.load() && p_oldtail->next.compare_exchange_strong(pnullptr, p_newnode))
{
break;
}
m_tail_changed.store(false, std::memory_order_release);
}while (true);
if (!m_tail.compare_exchange_strong(p_oldtail, p_newnode)) ;
}
bool pop(val_t& v)
{
node_t* p_oldhead = m_head.load()->next.load();
//* 取出头
while (p_oldhead && !m_head.load()->next.compare_exchange_strong(p_oldhead, p_oldhead->next.load()))
{}
if (p_oldhead == nullptr)return false; //* 列表为空
node_t* p_oldheadbak = p_oldhead;
//* 控制取出最后一个元素后尾指针的位置,但是tail取出并销毁后push如果之前已经保存了tail就会失效
if (m_tail == p_oldhead)
{
m_tail_changed.store(true, std::memory_order_relaxed); //* 这里可能会对末尾修改,先置标志让为为指针判断失效
std::atomic_thread_fence(std::memory_order_release);
if (!m_tail.compare_exchange_strong(p_oldhead, m_head.load(), std::memory_order_acq_rel))
m_tail_changed.store(false, std::memory_order_release); //* 假设修改尾指针成功了,但是未来得及置标志
}
if (p_oldheadbak)
{
v = p_oldheadbak->v;
delete p_oldheadbak;
}
return true;
}
}; 这个实现引入了一个新的类成员m_tail_changed用以表示尾指针是否变化。但分析来看,这实际上就是一个自旋锁,在pop函数中如果可能修改尾指针先置上该标志以保证m_tail_changed==true是sequence-before m_tail修改的。这样在push中如果发现m_tail_changed标志被置上就需要等待尾指针更新完毕。当然,这种实现确实是违背了lock-free的原则,因为自旋锁的存在会导致全局的阻塞,虽然这种情况只有在弹出最后一个元素的时候才会存在。
接下来展示一下测试情况:
#include
#include
#include
#include
#include
#include
#include "lock_free_queue.hpp"
#include "lock_queue.hpp"
using namespace std;
#define MAX_LOOP_CNT 100000
int main(int argc, char**argv)
{
do
{
cout << "lock free" << endl;
lock_free_queue lfq;
thread producer([&]()
{
int v = 0;
int i = 0;
while (i++ < MAX_LOOP_CNT)
{
lfq.push(v++);
}
});
int s = 0, f = 0;
thread consumer([&]()
{
//std::this_thread::sleep_for(std::chrono::nanoseconds(100));
int vpop = 0;
int i = 0;
while (i++ < MAX_LOOP_CNT)
{
if (lfq.pop(vpop))
s++;
else
f++;
}
});
auto begin = std::chrono::high_resolution_clock::now();
producer.join();consumer.join();
auto end = std::chrono::high_resolution_clock::now();
auto du = std::chrono::duration_cast(end - begin);
cout << "s:" << s << " f:" << f << " t:" << du.count() << endl;
}while(0);
do
{
cout << "lock" << endl;
volatile bool brun = true;
lock_queue lfq;
thread producer([&]()
{
int v = 0;
int i = 0;
while (i++ < MAX_LOOP_CNT)
{
lfq.push(v++);
}
});
int s = 0, f = 0;
thread consumer([&]()
{
//std::this_thread::sleep_for(std::chrono::nanoseconds(100));
int vpop = 0;
int i = 0;
while (i++ < MAX_LOOP_CNT)
{
if (lfq.pop(vpop))
s++;
else
f++;
}
});
auto begin = std::chrono::high_resolution_clock::now();
producer.join(); consumer.join();
auto end = std::chrono::high_resolution_clock::now();
auto du = std::chrono::duration_cast(end - begin);
cout << "s:" << s << " f:" << f << " t:" << du.count() << endl;
}while(0);
return 0;
}
查看一下有锁和无锁情况下执行100000次插入和弹出的情况。在windows x64系统上,使用debug模式得到的结果如下:

无锁队列插入10^5次时间是有锁队列的一半。但是在release情况下:
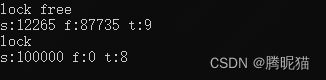
有锁队列和无锁队列效率相当,甚至有锁队列的效率要略高于无锁队列。这有可能是无锁队列在内部需要创建node节点导致的。
下面是CentOS7.9系统中使用-g时候的情况:

无锁队列的效率也是要比有锁队列快一倍的。然后再试试-O2优化的结果:

这个效率,只能说相当,无锁略快,但是如果再使用内存池进行优化应该会更好一些。
试一下boost.lockfree.queue的效率,Windows X64 Release:

Windows X64 Debug:

就SPSC来看这个效率实在是堪忧,甚至还比不上有锁队列。
但是到达MPSC情况如何,设置8个生产者,Windows X64 Debug:
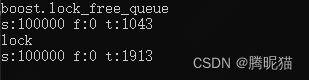
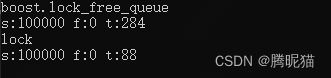
看到这个情况下boost无锁队列的效率约为有锁的2-3倍。Windows X64 Release模式下也是如此:
再试试MPMC的情况,Windows X64 Debug:
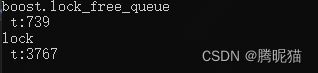
Windows X64 Release:
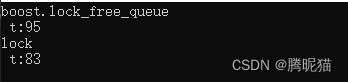
我们来分析一下,MPSC模式下,队列一直不是空的,所以没有涉及首指针和尾指针的竞争,因此无锁队列可以高效执行。在MPMC模式下,Debug模式差距很大,这个很好解释,有锁队列使用了全局锁定,因此,生产和生产、消费和消费、生产和消费都有阻塞;无锁队列涉及的只是生产和生产、消费和消费的竞争,偶尔涉及生产和消费的竞争。在Release化以后其实比较难以解释,可能是由于积极锁导致的CPU空跑引起了无锁的效率低下?
最后,来个最顶的concurrentqueue。首先是O2模式下面SPSC:
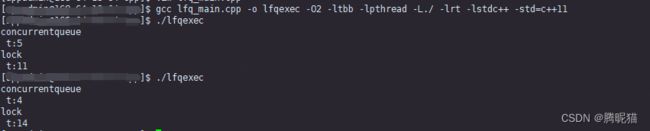
然后是-g模式:
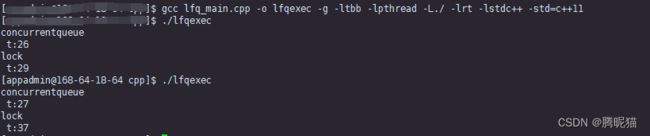
然后是SPMC O2结果:

-g结果:
 接着是MPSC结果:
接着是MPSC结果:
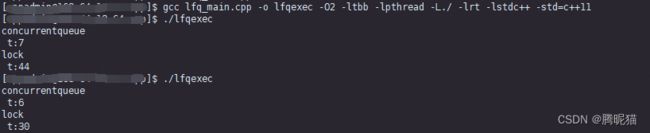

最后是MPMC结果:

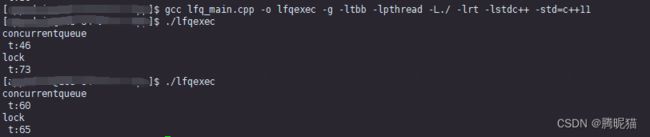
可见concurrentqueue真的是相当的给力,性能在4中情况下都很好。其中MPMC的结果最差,性能也要略微超过有锁队列。在MPSC的情况下性能最好性能升值能提高到原来的5倍左右。这个库内部是怎么解决头尾节点同步的问题值得进一步深入研究。