Yarn入门详解
Yarn入门详解
一、Yarn概述
Yarn是Hadoop2.0版本引入的集群资源管理系统,直接从MR1演化而来。
 我们可以从上图看出Hadoop2.x可以支持其他的分布式计算框架,在引入Yarn的Hadoop2.x之后同一套硬件集群中可以运行多个任务,例如:MR、Spark任务等
我们可以从上图看出Hadoop2.x可以支持其他的分布式计算框架,在引入Yarn的Hadoop2.x之后同一套硬件集群中可以运行多个任务,例如:MR、Spark任务等
Yarn包含三个组件:
- ResourceManager(RM):资源管理
- NodeManager(NM):相当于1.0中的TaskTracker的角色,接收来自RM的请求,分配Container的资源,通过心跳汇报给RM,并且管理节点内部的资源利用情况
- ApplicationMaster(AM):任务调度
严格意义上来说,Yarn只包含两个组件,ResourceManager以及NodeManager。而ApplicationMaster只是一个Yarn的客户端
Yarn将MR1中的JobTracker的资源管理和任务调度做了权力肢解,分别由ResourceManager和ApplicationMaster进程来实现
二、Yarn架构组件详解
1个NameNode(master)和多个DataNode(slave)
在NameNode上运行ResourceManager
在DataNode上运行NodeManager
并把DataNode的所有计算资源(CPU、内存)视为1个或多个Container,而Container可以被分配执行一个Task(ApplicationMaster、Map Task、Reduce Task等…)
1、ResourceManager(RM)
(1)ResourceManager即资源管理,在Yarn中,RM负责集群中所有资源的统一管理和分配,RM接收来自各个节点(NodeManager)的资源汇报情况,并且将这些信息按照一定的策略分配给各个应用(实际是ApplicationManager分配)
(2)资源分配单位用“资源容器”(Contrainer)表示,Container是一个动态资源分配单位,它将内存、cpu、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量
Container是Yarn框架的计算单元,是具体执行应用task(如map task、reduce task)的基本单位
Container和集群节点的关系是:一个节点会运行多个Container,但一个Container不会跨节点
任何一个job或application必须运行在一个或多个Container中。在Yarn框架中,ResourceManager只负责告诉ApplicationMaster哪些Containers可以用,ApplicationMaster还需要去找NodeManager请求分配具体的Container
一个机器有多少个container?
container的数量=min(2cores, 1.8disks, 总内存/最小容量)
我们可以对最小容量的参数配置,达到控制container的数量
(3)RM包括Scheduler(定时调度器)和ApplicationManager(应用管理器)
Schedular是一个资源调度器,它主要负责协调集群中各个应用的资源分配,保障整个集群的运行效率。
Scheduler是一个可插拔的插件,负责各个运行中的应用的资源分配,受到资源容量,队列以及其他因素的影响。是一个纯粹的调度器,不负责应用程序的监控和状态追踪,不保证应用程序的失败或者硬件失败的情况对task重启,而是基于应用程序的资源需求执行其调度功能,使用了叫做资源container的概念,其中包括多种资源,比如,cpu,内存,磁盘,网络等。在Hadoop的MapReduce框架中主要有三种Scheduler:FIFO Scheduler,Capacity Scheduler和Fair Scheduler
- FIFO Scheduler:先进先出,不考虑作业优先级和范围,适合低负载集群
- Capacity Scheduler:将资源分为多个队列,允许共享集群,有保证每个队列最小资源的使用
- Fair Scheduler:公平的将资源分给应用的方式,使得所有应用在平均情况下随着时间得到相同的资源份额
Scheduler的角色是一个纯调度器,它只负责调度Containers,不会关心应用程序监控及其运行状态等信息,它不做监控以及应用程序的状态跟踪,并且不保证会重启应用程序本身或者硬件出错而执行失败的应用程序
2、NodeManager(NM)
NodeManager进程运行在集群中的节点上,每个节点都会有自己的NodeManager。NodeManager整个集群有多个,负责每个节点上的资源和使用。NodeManager是一个slave服务:
(1)它负责接收处理来自ResourceManager的资源分配请求,分配具体的Container给应用
(2)同时,它还负责监控并报告Container使用信息给ResourceManager
NodeManager只负责管理自身的Container,它并不知道运行在它上面应用的信息。负责管理应用信息的组件是ApplicationMaster
3、ApplicationMaster
ApplicationMaster运行在Container中。
ApplicationMaster的主要作用是向ResourceManager申请资源并和NodeManager协同工作来运行应用的各个任务然后跟踪它们状态及监控各个任务的执行,遇到失败的任务还负责重启它
管理YARN内运行的应用程序的每个实例
功能:
数据切分
为应用程序申请资源并进一步分配给内部任务。
任务监控与容错
负责协调来自ResourceManager的资源,并通过NodeManager监视任务的执行和资源使用情况
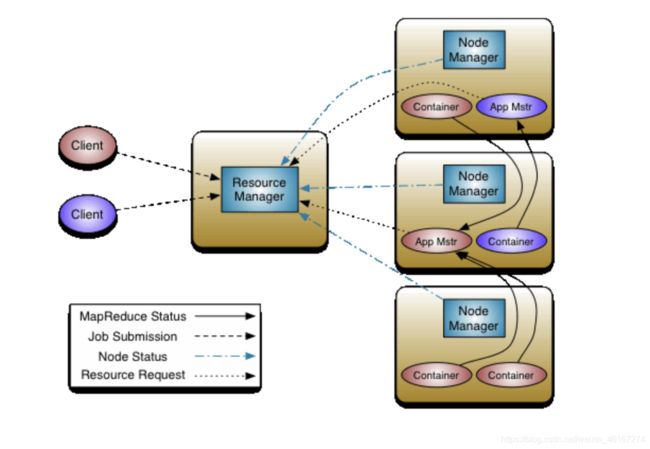
三、Yarn运行流程
1、Clinet向ResouceManager发送Job请求
2、ResouceManager接受到请求后在自身开启一个Container 来运行的ApplicationManager组件,ApplicationManager负责接下来的Job请求
3、ResourceManager(ApplicationManager)分配一个有闲置资源的NodeManager,由该NodeManager启动一个Container,并从HDFS上拷贝Job资源,然后运行ApplicationMaster作为本次Job的主节点
4、ApplicationMaster向ResourceManager(AppMgr)进行注册,注册之后Clinet就可以查询ResourceManager获得自己ApplicationMaster的详细信息,以后就可以和自己的ApplicationMaster直接交互
5、ApplicationMaster计算本次Job所需要的计算资源并向ResouceManager(ApplicationManager)请求资源路径
6、ResouceManager(ResourceScheduler)返回封装好的资源
7、ApplicationMaster根据返回的资源将向各个NodeManager发送任务,开启Container,然后将 Map Task分发到各个Container中运行
8、ApplicationMaster实时监控各个MapTask的完成情况,当所有MapTask都完成后,开始运行Reduce Task。(Reducer和Mapper不在同一个Container)
9、Job完成后,ApplicationMaster向ApplicationsMgr申请注销自己