初步认识爬虫
目录
一、爬虫产生背景
如果我们需要大量数据,有哪些获取数据的方式呢?
(1)企业产生的数据
(2)数据平台购买的数据
(3)政府/机构公开的数据
(4)数据管理咨询公司的数据
(5)爬取的网络数据
二、什么是网络爬虫?
三、爬虫的用途
四、爬虫的分类
按照使用场景进行分类:
按照爬取形式进行分类:
按照爬取数据的存在方式进行分类:
五、网络爬虫的主要开发语言有Java,Python和C++,为什么选择Python开发呢?
(1)抓取网页本身的接口
(2)网页抓取后的处理
(3)开发效率高
(4)上手快
六、爬虫具体能做些什么呢?
一、爬虫产生背景
搜索引擎使用了网络爬虫不停地从互联网抓取网站数据,并将网站镜像保存在本地,这才能为大众提供信息检索的功能。
目前的互联网已经迈入大数据时代,通过对海量的数据进行分析,能够产生极大的商业价值。
如果我们需要大量数据,有哪些获取数据的方式呢?
(1)企业产生的数据
(2)数据平台购买的数据
(3)政府/机构公开的数据
(4)数据管理咨询公司的数据
(5)爬取的网络数据
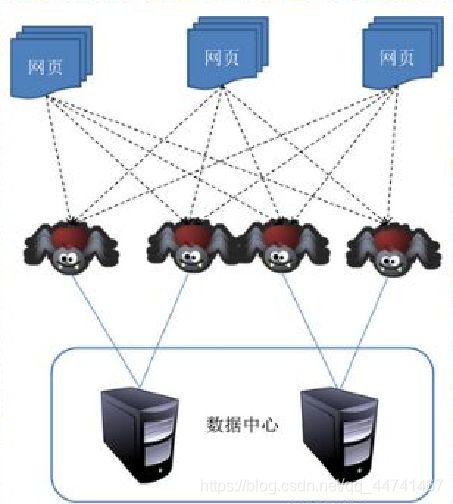
无论是搜索引擎,还是个人或单位获取目标数据,都需要从公开网站上爬取大量数据,在此需求下,爬虫技术应运而生,并迅速发展成为一门成熟的技术。
二、什么是网络爬虫?
如果说网络像一张网,那么爬虫就是网上的一只小虫子,在网上爬行的过程中遇到了数据,就把它抓取下来。

网络爬虫,又称为网页蜘蛛、网络机器人,是一种按照一定的规则,自动请求万维网网站并提取网络数据的程序或脚本。
注意:这里的数据是指互联网上公开的并且可以访问到的网页信息,而不是网站的后台信息(没有权限访问),更不是用户注册的信息(非公开的)。(当然可以,后果嘛,自己品!)

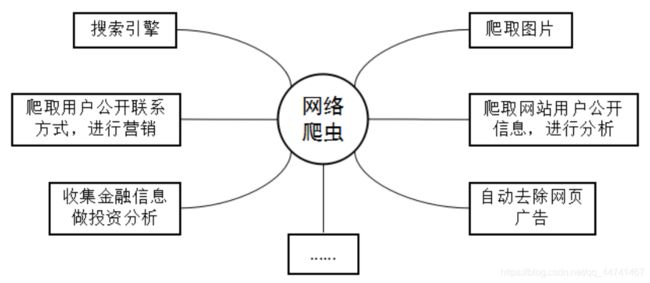
三、爬虫的用途
四、爬虫的分类
按照使用场景进行分类:
通用爬虫:又称全网爬虫,将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
聚焦爬虫:又称主题网络爬虫,是指选择性地爬行那些与预先定义好的主题相关的页面的网络爬虫
按照爬取形式进行分类:
累积式爬虫:累积式爬虫是指从某一个时间点开始,通过遍历的方式抓取系统所能允许存储和处理的所有网页
增量式爬虫:在具有一定量规模的网络页面集合的基础上,采用更新数据的方式选取已有集合中的过时网页进行抓取,以保证所抓取到的数据与真实网络数据足够接近。
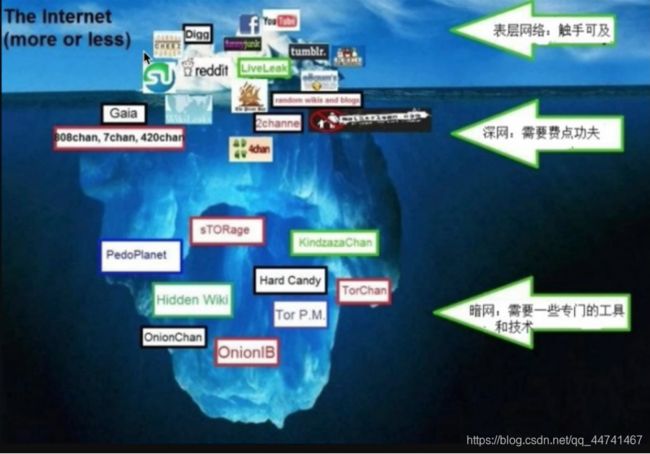
按照爬取数据的存在方式进行分类:
表层爬虫:爬取表层网页的爬虫叫做表层爬虫。表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的Web页面。
深层爬虫:爬取深层网页的爬虫就叫做深层爬虫。深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。
五、网络爬虫的主要开发语言有Java,Python和C++,为什么选择Python开发呢?
(1)抓取网页本身的接口
Python的urllib包提供了较为完整的访问网页文档的API;相比与其他静态编程语言(如Java、C#、C++),Python抓取网页文档的接口更简洁
(2)网页抓取后的处理
Python的Beautiful Soup提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
(3)开发效率高
因为爬虫的具体代码得根据网站不同而修改的,而Python这种灵活的脚本语言特别适合这种任务。
(4)上手快
网络上Python的教学资源很多,便于大家学习,出现问题也很容易找到相关资料。另外,Python还有强大的成熟爬虫框架的支持,比如Scrapy。
六、爬虫具体能做些什么呢?
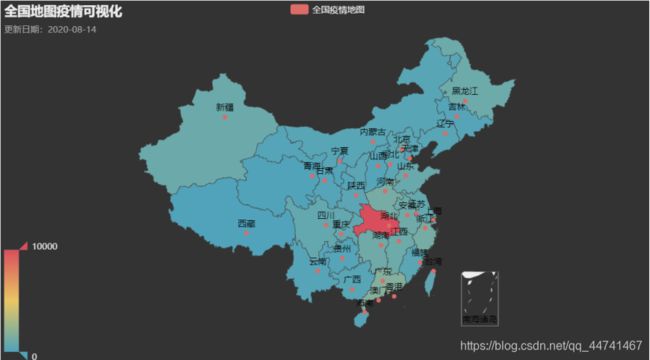
全国疫情图
网评

人工智能

