Kubernetes 1.18学习笔记
文章目录
- 一、Kubernetes 概述和架构
-
- 1、kubernetes 基本介绍
- 2、Kubernetes 功能
- 3、Kubernetes 架构组件
- 4、Kubernetes 核心概念
- 5、Kubernetes 工作原理
- 二、Kubernetes 集群搭建
-
- 1、系统环境准备
-
- 1.1 安装要求
- 1.2 系统初始化
- 2、客户端工具kubeadm搭建
-
- 2.1 安装步骤
- 2.2 安装组件
- 2.3 集群部署
- 2.4 部署 CNI 网络插件
- 2.5 测试集群
- 3、二进制方式搭建
-
- 3.1 安装步骤
- 3.2 **部署 etcd**(主节点)
- 3.3 安装 docker
- 3.4 部署 master 组件
- 3.5 部署node组件
- 3.6 部署 CNI 网络插件
- 3.7 测试 kubernetes 集群
- 4、两种方式搭建集群的对比
-
- 4.1 Kubeadm 方式搭建 K8S 集群
- 4.2 二进制方式搭建 K8S 集群
- 5、可视化安装
-
- 5.1 Kuboard v3 - kubernetes(推荐)
- 5.2 Kubernetes Dashboard
- 5.3 k8slens IDE(推荐)
- 三、Kubernetes 核心概念(基础)
-
- 1、集群命令行工具 kubectl
-
- 1.1 kubectl 概述
- 1.2 kubectl 命令格式
- 1.3 kubectl 基础命令
- 1.4 kubectl 部署命令
- 1.5 kubectl 集群管理命令
- 1.6 kubectl 故障和调试命令
- 1.7 kubectl 其它命令
- 2、YAML 文件详解
-
- 2.1 YAML 概述
- 2.2 基础语法
- 2.3 YAML 数据结构
- 2.4 组成部分
- 2.5 快速编写
- 3、Pod
-
- 3.1 Pod概述
- 3.2 Pod 实现机制
- 3.3 Pod 镜像拉取策略
- 3.4 Pod 资源限制
- 3.5 Pod 重启机制
- 3.6 Pod 健康检查
- 3.7 Pod 调度策略
- 3.8 污点和污点容忍
- 4、Controller之Deployment
-
- 4.1 Controller 简介
- 4.2 Deployment控制器应用
- 4.3 Deployment 部署应用
- 4.4 升级回滚和弹性收缩
- 5、Service
-
- 5.1 service概述
- 5.2 Service存在的意义
- 5.3 Pod和Service的关系
- 5.4 Service常用类型
- 6、Controller之Statefulset
-
- 6.1 Statefulset概述
- 6.2 无状态和有状态容器
- 6.3 部署有状态应用
- 7、Controller之其他应用
-
- 7.1 DaemonSet
- 7.2 Job和CronJob
- 7.3 Replication Controller
- 四、Kubernetes 核心概念(进阶)
-
- 1、Kubernetes配置管理
-
- 1.1 Secret
- 1.2 ConfigMap
- 2、Kubernetes集群安全机制
-
- 2.1 概述
- 2.2 RBAC介绍
- 2.3 RBAC实现鉴权
- 3、核心技术Ingress
-
- 3.1 前言概述
- 3.2 Ingress和Pod关系
- 3.3 创建Ingress规则
- 3.4 其他高级配置
- 4、Kubernetes核心技术Helm
-
- 4.1 Helm概述
- 4.2 helm下载与配置
- 4.3 使用helm快速部署应用
- 4.4 自定义Chart
- 4.5 chart模板使用
- 5、命名空间
- 6、Kubernetes持久化存储
-
- 6.1 概述
- 6.2 nfs网络存储
- 6.3 PV和PVC
- 五、搭建集群监控平台系统
-
- 1、监控指标
- 3、部署 Pormetheus
-
- 3.1 创建守护进程Pod
- 3.2 rbac创建
- 3.3 ConfigMap
- 3.4 Deployment
- 3.5 Service
- 3.6 创建与部署
- 4、部署 Grafana
-
- 4.1 Deployment
- 4.2 Service
- 4.3 Runing
- 4.4 创建与部署
- 六、搭建高可用 Kubernetes 集群
-
- 1、高可用集群架构
- 2、高可用集群环境准备
-
- 2.1 安装步骤
- 2.2 安装要求
- 2.3 准备环境
- 3、高可用集群搭建
-
- 3.1 系统初始化
- 3.2 安装 docker、kubelet、kubeadm、kubectl
- 3.3 配置高可用 VIP【haproxy+keepalived】
- 3.4 部署 Kubernetes Master 组件
- 3.5 安装集群网络
- 3.6 测试 kubernetes 集群
- 七、在集群环境中部署项目
-
- 1、容器交付流程
- 2、k8s 部署 java 项目流程
- 3、k8s 部署 Java 项目
-
- 3.1 制作镜像
- 3.2 上传镜像仓库
- 3.3 部署项目
一、Kubernetes 概述和架构
1、kubernetes 基本介绍
kubernetes,简称K8s,是用8 代替8 个字符"ubernete"而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes 的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes 提供了应用部署,规划,更新,维护的一种机制。
传统的应用部署方式是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。新的方式是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的
- K8s是谷歌在2014年发布的容器化集群管理系统
- 使用k8s进行容器化应用部署
- 使用k8s利于应用扩展
- k8s目标实施让部署容器化应用更加简洁和高效
2、Kubernetes 功能
- 自动装箱
- 基于容器对应用运行环境的资源配置要求自动部署应用容器
- 自我修复
- 当容器失败时,会对容器进行重启
- 当所部署的 Node 节点有问题时,会对容器进行重新部署和重新调度
- 当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务
- 水平扩展
- 通过简单的命令、用户 UI 界面或基于 CPU 等资源使用情况,对应用容器进行规模扩大或规模剪裁
- 当我们有大量的请求来临时,我们可以增加副本数量,从而达到水平扩展的效果
- 服务发现
- 用户不需使用额外的服务发现机制,就能够基于 Kubernetes 自身能力实现服务发现和负载均衡
- 滚动更新
- 可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新
- 版本回退
- 可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退
- 密钥和配置管理
- 在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署。
- 存储编排
- 自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要
- 存储系统可以来自于本地目录、网络存储 (NFS、Gluster、Ceph 等)、公共云存储服务
- 批处理
- 提供一次性任务,定时任务;满足批量数据处理和分析的场景
3、Kubernetes 架构组件
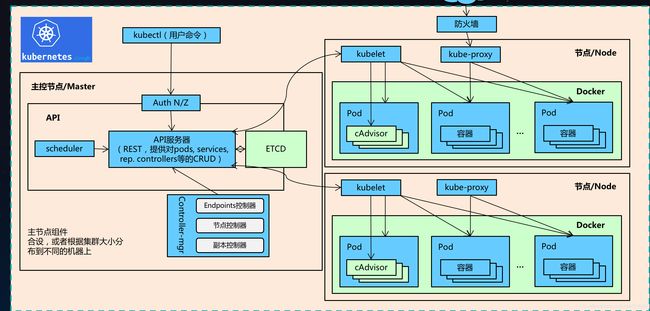
Master:主控节点
- API Server:集群统一入口,以 restful 风格进行操作,同时交给 etcd 存储
- 提供认证、授权、访问控制、API 注册和发现等机制
- scheduler:节点的调度,选择 node 节点应用部署
- controller-manager:处理集群中常规后台任务,一个资源对应一个控制器
- etcd:存储系统,用于保存集群中的相关数据
Worker node:工作节点
- Kubelet:master 派到 node 节点代表,管理本机容器
- 一个集群中每个节点上运行的代理,它保证容器都运行在 Pod 中
- 负责维护容器的生命周期,同时也负责 Volume(CSI) 和 网络 (CNI) 的管理
- kube-proxy:提供网络代理,负载均衡等操作
容器运行环境【Container Runtime】
- 容器运行环境是负责运行容器的软件
- Kubernetes 支持多个容器运行环境:Docker、containerd、cri-o、rktlet 以及任何实现 Kubernetes CRI (容器运行环境接口) 的软件。
fluentd:是一个守护进程,它有助于提升集群层面日志
4、Kubernetes 核心概念
Pod
- Pod 是 K8s 中最小的单元
- 一组容器的集合
- 共享网络【一个 Pod 中的所有容器共享同一网络】
- 生命周期是短暂的(服务器重启后,就找不到了)
Volume
- 声明在 Pod 容器中可访问的文件目录
- 可以被挂载到 Pod 中一个或多个容器指定路径下
- 支持多种后端存储抽象【本地存储、分布式存储、云存储】
Controller
- 确保预期的 pod 副本数量【ReplicaSet】
- 无状态应用部署【Deployment】
- 无状态就是指,不需要依赖于网络或者 ip
- 有状态应用部署【StatefulSet】
- 有状态需要特定的条件
- 确保所有的 node 运行同一个 pod 【DaemonSet】
- 一次性任务和定时任务【Job 和 CronJob】
Deployment
- 定义一组 Pod 副本数目,版本等
- 通过控制器【Controller】维持 Pod 数目【自动回复失败的 Pod】
- 通过控制器以指定的策略控制版本【滚动升级、回滚等】
Service
- 定义一组 pod 的访问规则
- Pod 的负载均衡,提供一个或多个 Pod 的稳定访问地址
- 支持多种方式【ClusterIP、NodePort、LoadBalancer】
Label
- label:标签,用于对象资源查询,筛选
Namespace
- 命名空间,逻辑隔离
- 一个集群内部的逻辑隔离机制【鉴权、资源】
- 每个资源都属于一个 namespace
- 同一个 namespace 所有资源不能重复
- 不同 namespace 可以资源名重复
API
- 我们通过 Kubernetes 的 API 来操作整个集群
- 同时我们可以通过 kubectl 、ui、curl 最终发送 http + json/yaml 方式的请求给 API Server,然后控制整个 K8S 集群,K8S 中所有的资源对象都可以采用 yaml 或 json 格式的文件定义或描述
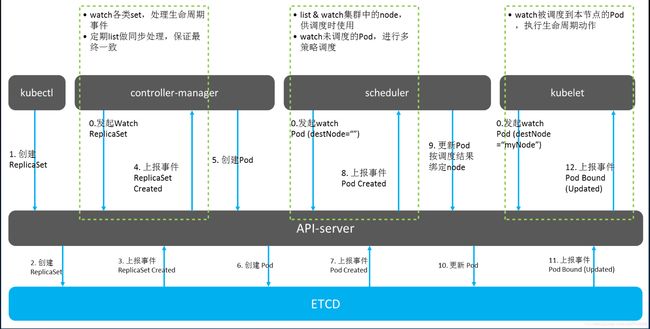
5、Kubernetes 工作原理
二、Kubernetes 集群搭建
1、系统环境准备
1.1 安装要求
在开始之前,部署 Kubernetes 集群机器需要满足以下几个条件:
- 一台或多台机器,操作系统 CentOS7.x-86_x64
- 硬件配置:2GB 或更多 RAM,2 个 CPU 或更多 CPU,硬盘 30GB 或更多【注意】【master 需要两核】
- 可以访问外网,需要拉取镜像,如果服务器不能上网,需要提前下载镜像并导入节点
- 禁止 swap 分区
1.2 系统初始化
# 关闭防火墙
systemctl stop firewalld
# 禁用 firewalld 服务
systemctl disable firewalld
#安装网络工具
yum install net-tools -y
#查看端口
netstat -tunlp
# 关闭 selinux
# 临时关闭【立即生效】告警,不启用,Permissive,查看使用 getenforce 命令
setenforce 0
# 永久关闭【重启生效】
sed -i 's/SELINUX=enforcing/\SELINUX=disabled/' /etc/selinux/config
# 关闭 swap
# 临时关闭【立即生效】查看使用 free 命令
swapoff -a
# 永久关闭【重启生效】
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 在主机名静态查询表中添加 3 台主机
cat >> /etc/hosts << EOF
192.168.249.146 k8smaster
192.168.249.147 k8snode1
192.168.249.148 k8snode2
EOF
# 将桥接的 IPv4 流量传递到 iptables 的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 使 k8s 配置生效
sysctl --system
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
# 根据规划设置主机名【k8smaster 节点上操作】
hostnamectl set-hostname k8smaster
# 根据规划设置主机名【k8snode1 节点上操作】
hostnamectl set-hostname k8snode1
# 根据规划设置主机名【k8snode2 节点操作】
hostnamectl set-hostname k8snode2
还可以设置一下静态ip(cat /etc/sysconfig/network-scripts/ifcfg-ens33),以及开机自启网卡(可以使用DHCP,不影响),网段可以在虚拟网络编辑器进行编辑
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" # 静态ip开启
IPADDR="192.168.249.146" # 设置的静态IP地址
NETMASK="255.255.255.0" # 子网掩码
GATEWAY="192.168.249.2" # 网关地址
DNS1="192.168.249.2" # DNS服务器
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="78250ec9-3095-4140-9e04-e6586d81ba16"
DEVICE="ens33"
ONBOOT="yes" # 开机自启
网络设置完毕后需要重启systemctl restart network,重启完网络服务后ip地址已经发生了改变,此时FinalShell已经连接不上Linux系统,需要创建一个新连接才能连接到Linux
2、客户端工具kubeadm搭建
2.1 安装步骤
kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具。这个工具能通过两条指令完成一个 kubernetes 集群的部署
官方参考:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
- 【环境准备】准备三台虚拟机,并安装操作系统 CentOS 7.x
- 【系统初始化】对三个刚安装好的操作系统进行初始化操作
- 【安装工具】在三个节点安装
dockerkubeletkubeadmkubectl - 【集群部署-master】在 master 节点执行
kubeadm init命令初始化 - 【集群部署-node】在 node 节点上执行
kubeadm join命令,把 node 节点添加到当前集群 - 【安装网络插件】配置 CNI 网络插件,用于节点之间的连通
- 【测试集群】通过拉取一个 nginx 进行测试,能否进行外网测试
# 创建一个 Master 节点
kubeadm init
# 将一个 Worker node 节点加入到当前集群中
kubeadm join <Master 节点的 IP 和端口 >
2.2 安装组件
【所有节点】需要安装以下组件 ,Kubernetes 默认 CRI(容器运行时)为 Docker,因此先安装 Docker,其他操作见上面的系统初始化
- Docker
- kubeadm
- kubelet
- kubectl
# ===========================安装docker=============================
# 配置一下 Docker 的 yum 源【阿里云】
cat >/etc/yum.repos.d/docker.repo<<EOF
[docker-ce-edge]
name=Docker CE Edge - \$basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edge
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
# 然后 yum 方式安装 docker,这里为了版本匹配
yum -y install docker-ce-18.06.1.ce-3.el7
# 查看 docker 版本
docker --version
systemctl start docker
systemctl enable docker
systemctl status docker
# 配置 docker 的镜像源【阿里云】
cat >/etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
# 启动 docker
systemctl restart docker
# 查看是否成功
docker info
# =========================安装 kubeadm,kubelet 和 kubectl=================
# 配置 k8s 的 yum 源【阿里云】
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 列出该阿里云k8s源,提供那些k8s版本
yum list kubeadm --showduplicates
# 安装 kubelet、kubeadm、kubectl,同时指定版本
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
# 设置开机自启【这里暂时先不启动 kubelet】
systemctl enable kubelet
# k8s 命令补全
yum -y install bash-completion
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc
2.3 集群部署
# master节点执行
# apiserver-advertise-address是masterip
# 由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址
#【执行命令会比较慢,因为后台其实已经在拉取镜像了】,我们 docker images 命令即可查看已经拉取的镜像
kubeadm init \
--apiserver-advertise-address=192.168.249.146 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.18.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
# 参数说明
--image-repository 指定镜像源
--apiserver-advertise-address masterip地址
--service-cidr service ip网段
--pod-network-cidr pod网段
--kubernetes-version 指定版本
# 部署成功后,【系统提示】运行以下命令使用 kubectl
# 注意在非root用户
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 在从节点加入主节点
kubeadm join 192.168.249.146:6443 --token nzl3r0.r1skp13wi9vuljbi \
--discovery-token-ca-cert-hash sha256:5d947e66a062c3901f693b98d9d6e271aa42bb2ad2abdd18c37a00e88d47cec4
# 默认 token 有效期为 24 小时,当过期之后,该 token 就不可用了。这时就需要重新创建 token
kubeadm token create --print-join-command
# 如果node节点添加进集群失败,可以删除节点重新添加
# 要删除 node1 这个节点,首先在 master 节点上依次执行以下两个命令
kubectl drain k8snode1 --delete-local-data --force --ignore-daemonsets
kubectl delete node k8snode1
# 执行后通过 kubectl get node 命令可以看到 k8snode1已被成功删除,接着在 k8snode1 这个 Node 节点上执行如下命令,这样该节点即完全从 k8s 集群中脱离开来,之后就可以重新执行命令添加到集群
kubeadm reset
# 执行完成后,我们使用下面命令,查看我们正在运行的节点
kubectl get nodes
2.4 部署 CNI 网络插件
上面的状态还是 NotReady,下面我们需要网络插件,来进行联网访问;网络插件有两种:flannel和calico
# 下载网络插件配置
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 执行添加网络插件
kubectl apply -f kube-flannel.yml
# 这里可能会出错,拉取镜像出错,如果出错需要手动将出错的镜像导入,并将其tag为指定标签
# 或者将docker.io/rancher/mirrored-flannelcni-flannel:v0.20.1(两个地方)替换成registry.cn-hangzhou.aliyuncs.com/shawn222/flannel:v0.20.1
# 也可以通过github下载到阿里云,然后从阿里云下载,参考:https://blog.csdn.net/katch/article/details/102575084
# 查看状态 【kube-system 是 k8s 中的最小单元】
kubectl get pods -n kube-system
# 最后或者直接换网络插件
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
# 运行后的结果为 Ready 状态
kubectl get nodes -owide
# 查看所有的详细信息
kubectl get pod -A -owide
# 查看某一个容器详细运行状态,-n后跟的是命名空间,排查错误用
kubectl describe pod kube-flannel-ds-wclwt -n kube-flannel
# 查看日志
kubectl logs -f --tail 200 -n kube-flannel kube-flannel-ds-5bmpl
手动导入yaml文件后通过查看日志发现镜像无法拉取,于是手动拉取导入,然后用tag打上与yml文件中的镜像一模一样的名字,这里我每个结点都是这样操作(按理说会自动同步过去其他结点,但是每个结点都报错了,所以我手动下载了;当然换个国内源也可以)
# 下载地址
https://github.com/flannel-io/flannel
# 比如yml中写的是docker.io/rancher/mirrored-flannelcni-flannel:v0.20.0,首先下载对应的包
docker load < flanneld-v0.20.0-amd64.docker
# 查看一下
sudo docker images
# 找到对应的镜像打上对应标签
sudo docker tag quay.io/coreos/flannel:v0.20.0-amd64 docker.io/rancher/mirrored-flannelcni-flannel:v0.20.0
2.5 测试集群
在 Kubernetes 集群中创建一个 pod,验证是否正常运行
# 下载 nginx 【会联网拉取 nginx 镜像】
kubectl create deployment nginx --image=nginx
# 查看状态
kubectl get pod
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看一下对外的端口
kubectl get pod,svc
# 访问
http://192.168.249.146:31100/
3、二进制方式搭建
参考:https://blog.csdn.net/qq_40942490/article/details/114022294
3.1 安装步骤
- 【环境准备】准备三台虚拟机,并安装操作系统 CentOS 7.x
- 【系统初始化】对三个刚安装好的操作系统进行初始化操作
- 【部署 etcd 集群】对三个节点安装 etcd
- 【安装 Docker】对三个节点安装 docker
- 【部署 mastber 组件】在 master 节点上安装
kube-apiserver、kube-controller-manager、kube-scheduler - 【部署 node 组件】在 node 节点上安装
kubelet、kube-proxy - 【安装网络插件】配置 CNI 网络插件,用于节点之间的连通
- 【测试集群】通过拉取一个 nginx 进行测试,能否进行外网测试
3.2 部署 etcd(主节点)
服务器初始化见上面,这里首先签发证书,让服务器能够正常访问,需要为 etcd 和 apiserver 自签证书
# 为 etcd 和 apiserver 自签证书【k8smaster 节点操作】
# 创建工作目录
mkdir -p TLS/{etcd,k8s}
cd TLS/etcd/
# 准备 cfssl 证书生成工具
# 原地址【下载太慢】 建议迅雷下载,也可以手动下载
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
cp cfssl_linux-amd64 /usr/local/bin/cfssl
cp cfssljson_linux-amd64 /usr/local/bin/cfssljson
cp cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo
# 【使用自签 CA 生成 etcd 证书】
# 自签 CA
cat > ca-config.json<<EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json<<EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"BL": "Beijing"
}
]
}
EOF
# 签发 etcd 证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
ls *pem
# 【使用自签 CA 签发 Etcd HTTPS 证书】
# 自签 CA,创建证书申请文件:(文件 hosts 字段中 IP 为所有 etcd 节点的集群内部通信 IP,一个都不能少!为了 方便后期扩容可以多写几个预留的 IP)
cat > server-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"192.168.249.146",
"192.168.249.147",
"192.168.249.148"
],
"key": {
"algo": "rsa",
"size": 2048
},
"name": [
{
"C": "CN",
"L": "Beijing",
"SL": "Beijing"
}
]
}
EOF
# 签发 etcd https 证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
ls server*pem
# 下载二进制文件
wget https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
mkdir -p /opt/etcd/{bin,cfg,ssl}
tar -zxvf etcd-v3.4.9-linux-amd64.tar.gz
mv etcd-v3.4.9-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
cp ~/TLS/etcd/ca*pem ~/TLS/etcd/server*pem /opt/etcd/ssl/
创建配置文件,注意ip地址改成自己的
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.249.146:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.249.146:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.249.146:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.249.146:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.249.146:2380,etcd-2=https://192.168.249.147:2380,etcd-3=https://192.168.249.148:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
# 名词解释
# ETCD_NAME:节点名称,集群中唯一
# ETCD_DATA_DIR:数据目录
# ETCD_LISTEN_PEER_URLS:集群通信监听地址
# ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址
# ETCD_INITIAL_ADVERTISE_PEER_URLS:集群通告地址
# ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址
# ETCD_INITIAL_CLUSTER:集群节点地址
# ETCD_INITIAL_CLUSTER_TOKEN:集群 Token
# ETCD_INITIAL_CLUSTER_STATE:加入集群的当前状态,new 是新集群,existing 表示加入 已有集群
创建 etcd.service:
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
--logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
转发 etcd 到 node 节点【k8smaster 节点上操作】【需要输入密码,建议密码设置简单一点】
###### 转发到 k8snode1 ######
scp -r /opt/etcd/ [email protected]:/opt/
scp -r /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
###### 转发到 k8snode2 ######
scp -r /opt/etcd/ root@k8snode2:/opt/
scp -r /usr/lib/systemd/system/etcd.service root@k8snode2:/usr/lib/systemd/system/
# 修改 node 节点上 etcd 的配置文件:IP 和名字【k8snode1 和 k8snode2 节点上操作】
##### k8sndoe1 上操作 #####
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-2"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.249.147:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.249.147:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.249.147:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.249.147:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.249.146:2380,etcd-2=https://192.168.249.147:2380,etcd-3=https://192.168.249.148:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
##### k8sndoe2 上操作 #####
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-3"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.249.148:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.249.148:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.249.148:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.249.148:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.249.146:2380,etcd-2=https://192.168.249.147:2380,etcd-3=https://192.168.249.148:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="existing"
EOF
启动并设置开机启动:【k8snode1 和 k8snode2 均需一起启动】
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
# 查看集群状态
/opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem \
--key=/opt/etcd/ssl/server-key.pem \
--endpoints="https://192.168.249.146:2379,https://192.168.249.147:2379,https://192.168.249.148:2379" endpoint status \
--write-out=table
3.3 安装 docker
在所有节点操作。这里采用二进制安装,用 yum 安装也一样 (多台节点安装可以采用键盘工具)
cd ~/TLS
wget https://download.docker.com/linux/static/stable/x86_64/docker-20.10.3.tgz
tar -zxvf docker-20.10.3.tgz
cp docker/* /usr/bin
# systemd 管理 docker
cat > /usr/lib/systemd/system/docker.service << EOF
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF
# 配置阿里云加速
mkdir /etc/docker
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
# 设置开机启动
systemctl daemon-reload
systemctl start docker
systemctl enable docker
systemctl status docker
# 【k8smaster 节点安装 docker 完毕!转发到 k8snode1 和 k8snode2 节点】【k8smaster 节点上操作】
##### 转发到 k8snode1 #####
scp -r docker/* root@k8snode1:/usr/bin/
scp -r /usr/lib/systemd/system/docker.service root@k8snode1:/usr/lib/systemd/system/
scp -r /etc/docker/ root@k8snode1:/etc/
##### 转发到 k8snode2 #####
scp -r docker/* root@k8snode2:/usr/bin/
scp -r /usr/lib/systemd/system/docker.service root@k8snode2:/usr/lib/systemd/system/
scp -r /etc/docker/ root@k8snode2:/etc/
3.4 部署 master 组件
- kube-apiserver
- kuber-controller-manager
- kube-scheduler
首先进行apiserver自签证书(添加可信任ip列表方式)
# 【生成 kube-apiserver 证书】
# 自签证书颁发机构 CA
cd ~/TLS/k8s
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json << EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
# 生成 kube-apiserver 证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
ls *pem
# 【使用自签 CA 签发 kube-apiserver HTTPS 证书】
# 创建证书申请文件,注意自己添加可信任的ip
cat > server-csr.json << EOF
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"192.168.249.147",
"192.168.249.148",
"192.168.249.146",
"192.168.249.2",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
# 生成 kube-apiserver https 证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
ls server*pem
安装 kube-apiserver
# 下载二进制包
# 下载地址:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.20.md
# kubernetes-server-linux-amd64.tar.gz 包含了 master 和 node 的所有组件
# 这里提供几个下载地址,1.20.1启动需要额外参数
# wget https://storage.googleapis.com/kubernetes-release/release/v1.20.1/kubernetes-server-linux-amd64.tar.gz
wget https://dl.k8s.io/v1.19.0/kubernetes-server-linux-amd64.tar.gz
# 解压二进制包
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
tar -zxvf kubernetes-server-linux-amd64.tar.gz
cd kubernetes/server/bin
cp kube-apiserver kube-scheduler kube-controller-manager /opt/kubernetes/bin
cp kubectl /usr/bin/
# 生成 kube-apiserver 配置文件
cat > /opt/kubernetes/cfg/kube-apiserver.conf << EOF
KUBE_APISERVER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--etcd-servers=https://192.168.249.146:2379,https://192.168.249.147:2379,https://192.168.249.148:2379 \\
--bind-address=192.168.249.146 \\
--secure-port=6443 \\
--advertise-address=192.168.249.146 \\
--allow-privileged=true \\
--service-cluster-ip-range=10.0.0.0/24 \\
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\
--authorization-mode=RBAC,Node \\
--enable-bootstrap-token-auth=true \\
--token-auth-file=/opt/kubernetes/cfg/token.csv \\
--service-node-port-range=30000-32767 \\
--kubelet-client-certificate=/opt/kubernetes/ssl/server.pem \\
--kubelet-client-key=/opt/kubernetes/ssl/server-key.pem \\
--tls-cert-file=/opt/kubernetes/ssl/server.pem \\
--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \\
--client-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--etcd-cafile=/opt/etcd/ssl/ca.pem \\
--etcd-certfile=/opt/etcd/ssl/server.pem \\
--etcd-keyfile=/opt/etcd/ssl/server-key.pem \\
--audit-log-maxage=30 \\
--audit-log-maxbackup=3 \\
--audit-log-maxsize=100 \\
--audit-log-path=/opt/kubernetes/logs/k8s-audit.log"
EOF
# 注:上面两个\\ 第一个是转义符,第二个是换行符,使用转义符是为了使用 EOF 保留换行符。
# –logtostderr:启用日志
# —v:日志等级
# –log-dir:日志目录
# –etcd-servers:etcd 集群地址
# –bind-address:监听地址
# –secure-port:https 安全端口
# –advertise-address:集群通告地址
# –allow-privileged:启用授权
# –service-cluster-ip-range:Service 虚拟 IP 地址段
# –enable-admission-plugins:准入控制模块
# –authorization-mode:认证授权,启用 RBAC 授权和节点自管理
# –enable-bootstrap-token-auth:启用 TLS bootstrap 机制
# –token-auth-file:bootstrap token 文件
# –service-node-port-range:Service nodeport 类型默认分配端口范围
# –kubelet-client-xxx:apiserver 访问 kubelet 客户端证书
# –tls-xxx-file:apiserver https 证书
# –etcd-xxxfile:连接 Etcd 集群证书
# –audit-log-xxx:审计日志
# 把刚生成的证书拷贝到配置文件中的路径
cp ~/TLS/k8s/ca*pem ~/TLS/k8s/server*pem /opt/kubernetes/ssl/
# 创建上述文件配置文件中的 token 文件
# 格式:token,用户名,UID,用户组 token 也可自行生成替换【建议暂时不要替换,直接 copy 代码就完事了】
head -c 16 /dev/urandom | od -An -t x | tr -d ' '
cat > /opt/kubernetes/cfg/token.csv << EOF
c47ffb939f5ca36231d9e3121a252940,kubelet-bootstrap,10001,"system:node-bootstrapper"
EOF
# systemd 管理 apiserver
cat > /usr/lib/systemd/system/kube-apiserver.service << EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-apiserver.conf
ExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动并设置开机启动
systemctl daemon-reload
systemctl start kube-apiserver
systemctl enable kube-apiserver
systemctl status kube-apiserver
# 报错查看一下日志
cat /var/log/messages|grep kube-apiserver|grep -i error
# 授权 kubelet-bootstrap 用户允许请求证书
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
部署 kube-controller-manager
cat > /opt/kubernetes/cfg/kube-controller-manager.conf << EOF
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--leader-elect=true \\
--master=127.0.0.1:8080 \\
--bind-address=127.0.0.1 \\
--allocate-node-cidrs=true \\
--cluster-cidr=10.244.0.0/16 \\
--service-cluster-ip-range=10.0.0.0/24 \\
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--root-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--experimental-cluster-signing-duration=87600h0m0s"
EOF
# –master:通过本地非安全本地端口 8080 连接 apiserver。
# –leader-elect:当该组件启动多个时,自动选举(HA)
# –cluster-signing-cert-file/–cluster-signing-key-file:自动为 kubelet 颁发证书的 CA,与 apiserver 保持一致
# systemd 管理 controller-manager
cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-controller-manager.conf
ExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动并设置开机启动
systemctl daemon-reload
systemctl start kube-controller-manager
systemctl enable kube-controller-manager
systemctl status kube-controller-manager
部署 kube-scheduler
cat > /opt/kubernetes/cfg/kube-scheduler.conf << EOF
KUBE_SCHEDULER_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--leader-elect \
--master=127.0.0.1:8080 \
--bind-address=127.0.0.1"
EOF
# 参数说明
# –master:通过本地非安全本地端口 8080 连接 apiserver。
# –leader-elect:当该组件启动多个时,自动选举(HA)
cat > /usr/lib/systemd/system/kube-scheduler.service << EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler.conf
ExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动并设置开机启动
systemctl daemon-reload
systemctl start kube-scheduler
systemctl enable kube-scheduler
systemctl status kube-scheduler
#======================查看集群状态====================
# 所有组件都已经启动成功,通过 kubectl 工具查看当前集群组件状态
kubectl get cs
3.5 部署node组件
- kubelet
- kube-proxy
安装 kubelet
##### k8snode1 节点上操作,注意修改集群的名字,不要重复(这里的m1) #####
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
cat > /opt/kubernetes/cfg/kubelet.conf << EOF
KUBELET_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--hostname-override=m1 \\
--network-plugin=cni \\
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\
--experimental-bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\
--config=/opt/kubernetes/cfg/kubelet-config.yml \\
--cert-dir=/opt/kubernetes/ssl \\
--pod-infra-container-image=lizhenliang/pause-amd64:3.0"
EOF
# –hostname-override:显示名称,集群中唯一
# –network-plugin:启用 CNI
# –kubeconfig:空路径,会自动生成,后面用于连接 apiserver
# –bootstrap-kubeconfig:首次启动向 apiserver 申请证书
# –config:配置参数文件
# –cert-dir:kubelet 证书生成目录
# –pod-infra-container-image:管理 Pod 网络容器的镜像
cat > /opt/kubernetes/cfg/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS:
- 10.0.0.2
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /opt/kubernetes/ssl/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF
# 将 k8smaster 节点的 bin 文件和证书拷贝到 k8snode1 和 k8snode2 节点上【k8smaster 节点操作】
cd ~/kubernetes/server/bin
##### 转发到 k8snode1 #####
scp -r {kubelet,kube-proxy} root@k8snode1:/opt/kubernetes/bin/
scp -r /usr/bin/kubectl root@k8snode1:/usr/bin/
scp -r /opt/kubernetes/ssl root@k8snode1:/opt/kubernetes
##### 转发到 k8snode2 #####
scp -r {kubelet,kube-proxy} root@k8snode2:/opt/kubernetes/bin/
scp -r /usr/bin/kubectl root@k8snode2:/usr/bin/
scp -r /opt/kubernetes/ssl root@k8snode2:/opt/kubernetes
# 生成 bootstrap.kubeconfig 文件
# apiserver IP:PORT
KUBE_APISERVER="https://192.168.249.146:6443"
# 与 token.csv 里保持一致
TOKEN="c47ffb939f5ca36231d9e3121a252940"
# 生成 kubelet bootstrap kubeconfig 配置文件
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
kubectl config set-credentials "kubelet-bootstrap" \
--token=${TOKEN} \
--kubeconfig=bootstrap.kubeconfig
kubectl config set-context default \
--cluster=kubernetes \
--user="kubelet-bootstrap" \
--kubeconfig=bootstrap.kubeconfig
kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
mv bootstrap.kubeconfig /opt/kubernetes/cfg
# systemd 管理 kubelet
cat > /usr/lib/systemd/system/kubelet.service << EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf
ExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# 启动并设置开机启动
systemctl daemon-reload
systemctl start kubelet
systemctl enable kubelet
systemctl status kubelet
# 批准 kubelet 证书申请并加入集群【k8smaster 节点操作】
# 查看 kubelet 证书请求
kubectl get csr
### 输出结果
### NAME AGE SIGNERNAME REQUESTOR CONDITION
### node-csr-uCEGPOIiDdlLODKts8J658HrFq9CZ--K6M4G7bjhk8A 6m3s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
# 批准申请
kubectl certificate approve node-csr-uCEGPOIiDdlLODKts8J658HrFq9CZ--K6M4G7bjhk8A
# 查看节点,由于网络插件还没有部署,节点会没有准备就绪 NotReady
kubectl get node
部署 kube-proxy
# 以下在node1和node2创建
cat > /opt/kubernetes/cfg/kube-proxy.conf << EOF
KUBE_PROXY_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--config=/opt/kubernetes/cfg/kube-proxy-config.yml"
EOF
cat > /opt/kubernetes/cfg/kube-proxy-config.yml << EOF
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
metricsBindAddress: 0.0.0.0:10249
clientConnection:
kubeconfig: /opt/kubernetes/cfg/kube-proxy.kubeconfig
hostnameOverride: m1
clusterCIDR: 10.0.0.0/24
EOF
#=================回到master结点
# 切换工作目录
cd ~/TLS/k8s
# 创建证书请求文件
cat > kube-proxy-csr.json << EOF
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
# 生成 kubeconfig 文件
KUBE_APISERVER="https://192.168.249.146:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
kubectl config set-credentials kube-proxy \
--client-certificate=./kube-proxy.pem \
--client-key=./kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
##### 转发到 k8snode1 #####
scp -r kube-proxy.kubeconfig root@k8snode1:/opt/kubernetes/cfg/
##### 转发到 k8snode2 #####
scp -r kube-proxy.kubeconfig root@k8snode2:/opt/kubernetes/cfg/
#======================回到node1和node2============
cat > /usr/lib/systemd/system/kube-proxy.service << EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf
ExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl start kube-proxy
systemctl enable kube-proxy
systemctl status kube-proxy
3.6 部署 CNI 网络插件
# node结点操作,下载 CNI 网络插件
wget https://github.com/containernetworking/plugins/releases/download/v0.8.6/cni-plugins-linux-amd64-v0.8.6.tgz
# 安装插件
mkdir -p /opt/cni/bin
tar -zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
# k8smaster 节点操作,国内可以直接下载百度云文件
#链接:https://pan.baidu.com/s/1UaTBQ7GD2Smuty_MyxI1PA?pwd=g47k
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
3.7 测试 kubernetes 集群
# 下载 nginx 【会联网拉取 nginx 镜像】
kubectl create deployment nginx --image=nginx
# 查看状态
kubectl get pod
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看一下对外的端口
kubectl get pod,svc
# 我们到我们的宿主机浏览器上,访问如下地址,两个node的ip都可以访问
http://192.168.249.148:30899/
4、两种方式搭建集群的对比
4.1 Kubeadm 方式搭建 K8S 集群
- 安装虚拟机,在虚拟机安装 Linux 操作系统【3 台虚拟机】
- 对操作系统初始化操作
- 所有节点安装 Docker、kubeadm、kubelet、kubectl【包含 master 和 node 节点】
- 安装 Docker、使用 yum,不指定版本默认安装最新的 Docker 版本
- 修改 Docker 仓库地址,yum 源地址,改为阿里云地址
- 安装 kubeadm,kubelet 和 kubectl
- k8s 已经发布最新的 1.19 版本,可以指定版本安装,不指定安装最新版本
yum install -y kubelet kubeadm kubectl
- 在 master 节点执行初始化命令操作
kubeadm init- 默认拉取镜像地址 K8s.gcr.io 国内地址,需要使用国内地址
- 安装网络插件 (CNI)
kubectl apply -f kube-flannel.yml
- 在所有的 node 节点上,使用 join 命令,把 node 添加到 master 节点上
- 测试 kubernetes 集群
4.2 二进制方式搭建 K8S 集群
- 安装虚拟机和操作系统,对操作系统进行初始化操作
- 生成 cfssl 自签证书
ca-key.pem、ca.pemserver-key.pem、server.pem
- 部署 Etcd 集群
- 部署的本质,就是把 etcd 集群交给 systemd 管理
- 把生成的证书复制过来,启动,设置开机启动
- 安装 Docker
- 部署 master 组件,主要包含以下组件
- apiserver
- controller-manager
- scheduler
- 交给 systemd 管理,并设置开机启动
- 如果要安装最新的 1.19 版本,下载二进制文件进行安装
- 部署 node 组件
- kubelet
- kube-proxy【需要批准 kubelet 证书申请加入集群】
- 交给 systemd 管理组件- 组件启动,设置开机启动
- 批准 kubelet 证书申请 并加入集群
- 部署 CNI 网络插件
- 测试 Kubernets 集群【安装 nginx 测试】
5、可视化安装
5.1 Kuboard v3 - kubernetes(推荐)
参考:安装 Kuboard v3 - kubernetes
# 安装 Kuboard
kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
# 也可以使用下面的指令,唯一的区别是,该指令使用华为云的镜像仓库替代 docker hub 分发 Kuboard 所需要的镜像
# kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3-swr.yaml
# 如果想要定制 Kuboard 的启动参数,请将该 YAML 文件下载到本地,并修改其中的 ConfigMap
# 查看运行状态
watch kubectl get pods -n kuboard
kubectl get svc -A
# 在浏览器中打开链接 http://your-node-ip-address:30080
# 输入初始用户名和密码,并登录
# 用户名: admin
# 密码: Kuboard123
# 执行 Kuboard v3 的卸载
kubectl delete -f https://addons.kuboard.cn/kuboard/kuboard-v3.yaml
# 清理遗留数据,在 master 节点以及带有 k8s.kuboard.cn/role=etcd 标签的节点上执行
rm -rf /usr/share/kuboard
docker的安装方式
# https://hub.docker.com/r/eipwork/kuboard/tags 可以查看最新版本号
sudo docker run -d \
--restart=unless-stopped \
--name=kuboard \
-p 80:80/tcp \
-p 10081:10081/udp \
-p 10081:10081/tcp \
-e KUBOARD_ENDPOINT="http://192.168.249.139:80" \
-e KUBOARD_AGENT_SERVER_UDP_PORT="10081" \
-e KUBOARD_AGENT_SERVER_TCP_PORT="10081" \
-v /root/kuboard-data:/data \
eipwork/kuboard:v3.3.0.3
在浏览器输入 192.168.249.139 即可访问 Kuboard 的界面,登录方式:用户名:admin/密 码:Kuboard123
5.2 Kubernetes Dashboard
参考:Kubernetes Dashboard安装/部署和访问 Kubernetes 仪表板(Dashboard)
Kubernetes Dashboard 是 Kubernetes 的官方 Web UI。使用 Kubernetes Dashboard可以
- 向 Kubernetes 集群部署容器化应用
- 诊断容器化应用的问题
- 管理集群的资源
- 查看集群上所运行的应用程序
- 创建、修改Kubernetes 上的资源(例如 Deployment、Job、DaemonSet等)
- 展示集群上发生的错误
# 安装 Kubernetes Dashboard
kubectl apply -f https://kuboard.cn/install-script/k8s-dashboard/v2.0.0-beta5.yaml
# Kubernetes Dashboard 当前,只支持使用 Bearer Token登录
# 创建 ServiceAccount 和 ClusterRoleBinding
kubectl apply -f https://kuboard.cn/install-script/k8s-dashboard/auth.yaml
# 获取Bearer Token
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
# 执行代理命令
kubectl proxy
# 如需要使用 nodePort 或 Ingress 的方式访问 Kubernetes Dashboard 请配置正确的 https 证书,或者使用 Firefox 浏览器,并忽略 HTTPS 校验错误。
# 访问路径,将上一个步骤中获得的 Token 输入到登录界面中,点击 Sign in 按钮,完成登录
http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
另一种方法,kubernetes官方提供的可视化界面https://github.com/kubernetes/dashboard
# 先自己下载下来
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
# type: ClusterIP 改为 type: NodePort
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
# 然后再次更新运行
# 访问: https://集群任意IP:端口 https://139.198.165.238:32759
# 创建访问账号
# 文件见下面
kubectl apply -f dash.yaml
#获取访问令牌
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
#创建访问账号,准备一个yaml文件; vi dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
5.3 k8slens IDE(推荐)
官网:https://k8slens.dev/
三、Kubernetes 核心概念(基础)
1、集群命令行工具 kubectl
1.1 kubectl 概述
kubectl 是 Kubernetes 集群的命令行工具,通过 kubectl 能够对集群本身进行管理,并能够在集群上进行容器化应用的安装和部署
1.2 kubectl 命令格式
kubectl [command] [type] [name] [flags]
# command:指定要对资源执行的操作,例如 create、get、describe、delete
# type:指定资源类型,资源类型是大小写敏感的,开发者能够以单数 、复数 和 缩略的形式
kubectl get pod pod1
kubectl get pods pod1
kubectl get po pod1
# name:指定资源的名称,名称也是大小写敏感的,如果省略名称,则会显示所有的资源
# flags:指定可选的参数,例如,可用 -s 或者 -server 参数指定 Kubernetes API server 的地址和端口
# 获取 kubectl 的命令
kubectl --help
# 获取某个命令的介绍和使用
kubectl get --help
kubectl create --help
举例常用命令
# 部署应用
kubectl apply -f app.yaml
# 查看 deployment
kubectl get deployment
# 查看 pod
kubectl get pod -o wide
# 查看 pod 详情
kubectl describe pod pod-name
# 查看 log
kubectl logs pod-name [-f]
# 进入 Pod 容器终端, -c container-name 可以指定进入哪个容器。
kubectl exec -it pod-name -- bash
# 伸缩扩展副本
kubectl scale deployment test-k8s --replicas=5
# 把集群内端口映射到节点
kubectl port-forward pod-name 8090:8080
# 查看历史
kubectl rollout history deployment test-k8s
# 回到上个版本
kubectl rollout undo deployment test-k8s
# 回到指定版本
kubectl rollout undo deployment test-k8s --to-revision=2
# 删除部署
kubectl delete deployment test-k8s
# =============更多命令============
# 查看命名空间
kubectl get ns
# 查看全部
kubectl get all
# 重新部署
kubectl rollout restart deployment test-k8s
# 命令修改镜像,--record 表示把这个命令记录到操作历史中
kubectl set image deployment test-k8s test-k8s=ccr.ccs.tencentyun.com/k8s-tutorial/test-k8s:v2-with-error --record
# 暂停运行,暂停后,对 deployment 的修改不会立刻生效,恢复后才应用设置
kubectl rollout pause deployment test-k8s
# 恢复
kubectl rollout resume deployment test-k8s
# 输出到文件
kubectl get deployment test-k8s -o yaml >> app2.yaml
# 删除全部资源
kubectl delete all --all
1.3 kubectl 基础命令
| 命令 | 介绍 |
|---|---|
| create | 通过文件名或标准输入创建资源 |
| expose | 将一个资源公开为一个新的 Service |
| run | 在集群中运行一个特定的镜像 |
| set | 在对象上设置特定的功能 |
| get | 显示一个或多个资源 |
| explain | 文档参考资料 |
| edit | 使用默认的编辑器编辑一个资源 |
| delete | 通过文件名,标准输入,资源名称或标签来删除资源 |
1.4 kubectl 部署命令
| 命令 | 介绍 |
|---|---|
| rollout | 管理资源的发布 |
| rolling-update | 对给定的复制控制器滚动更新 |
| scale | 扩容或缩容 Pod 数量,Deployment、ReplicaSet、RC 或 Job |
| autoscale | 创建一个自动选择扩容或缩容并设置 Pod 数量 |
1.5 kubectl 集群管理命令
| 命令 | 介绍 |
|---|---|
| certificate | 修改证书资源 |
| cluster-info | 显示集群信息 |
| top | 显示资源 (CPU/M) |
| cordon | 标记节点不可调度 |
| uncordon | 标记节点可被调度 |
| drain | 驱逐节点上的应用,准备下线维护 |
| taint | 修改节点 taint 标记 |
1.6 kubectl 故障和调试命令
| 命令 | 介绍 |
|---|---|
| describe | 显示特定资源或资源组的详细信息 |
| logs | 在一个 Pod 中打印一个容器日志,如果 Pod 只有一个容器,容器名称是可选的 |
| attach | 附加到一个运行的容器 |
| exec | 执行命令到容器 |
| port-forward | 转发一个或多个 |
| proxy | 运行一个 proxy 到 Kubernetes API Server |
| cp | 拷贝文件或目录到容器中 |
| auth | 检查授权 |
1.7 kubectl 其它命令
| 命令 | 介绍 |
|---|---|
| apply | 通过文件名或标准输入对资源应用配置 |
| patch | 使用补丁修改、更新资源的字段 |
| replace | 通过文件名或标准输入替换一个资源 |
| convert | 不同的 API 版本之间转换配置文件 |
| label | 更新资源上的标签 |
| annotate | 更新资源上的注释 |
| completion | 用于实现 kubectl 工具自动补全 |
| api-versions | 打印受支持的 API 版本 |
| config | 修改 kubeconfig 文件(用于访问 API,比如配置认证信息) |
| help | 所有命令帮助 |
| plugin | 运行一个命令行插件 |
| version | 打印客户端和服务版本信息 |
2、YAML 文件详解
参考:YAML 入门教程
2.1 YAML 概述
- YAML 文件 : 就是资源清单文件,用于资源编排
- YAML : 仍是一种标记语言。为了强调这种语言以数据做为中心,而不是以标记语言为重点
- YAML : 是一个可读性高,用来表达数据序列的格式
2.2 基础语法
- 使用空格做为缩进
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- 低版本缩进时不允许使用 Tab 键,只允许使用空格
- 使用#标识注释,从这个字符一直到行尾,都会被解释器忽略
- 使用 — 表示新的 yaml 文件开始
2.3 YAML 数据结构
# 对象类型:对象的一组键值对,使用冒号结构表示
name: Tom
age: 18
# yaml 也允许另一种写法,将所有键值对写成一个行内对象
hash: {name: Tom, age: 18}
# 数组类型:一组连词线开头的行,构成一个数组
People
- Tom
- Jack
# 数组也可以采用行内表示法
People: [Tom, Jack]
2.4 组成部分
主要分为了两部分,一个是控制器的定义和被控制的对象。在一个 YAML 文件的控制器定义中,有很多属性名称
| 属性名称 | 介绍 |
|---|---|
| apiVersion | API 版本 |
| kind | 资源类型 |
| metadata | 资源元数据 |
| spec | 资源规格 |
| replicas | 副本数量 |
| selector | 标签选择器 |
| template | Pod 模板 |
| metadata | Pod 元数据 |
| spec | Pod 规格 |
| containers | 容器配置 |
2.5 快速编写
一般来说,我们很少自己手写 YAML 文件,因为这里面涉及到了很多内容,我们一般都会借助工具来创建
# 尝试运行,并不会真正的创建镜像
kubectl create deployment web --image=nginx -o yaml --dry-run
# 我们可以输出到一个文件中
kubectl create deployment web --image=nginx -o yaml --dry-run > hello.yaml
# 可以首先查看一个目前已经部署的镜像
kubectl get deploy
# 导出 nginx 的配置
kubectl get deploy nginx -o=yaml --export > nginx.yaml
3、Pod
参考:https://kubernetes.io/zh-cn/docs/reference/kubernetes-api/workload-resources/pod-v1/
3.1 Pod概述
基本概念
- 最小部署的单元
- Pod 里面是由一个或多个容器组成【一组容器的集合】
- 一个 pod 中的容器是共享网络命名空间
- Pod 是短暂的
- 每个 Pod 包含一个或多个紧密相关的用户业务容器
Pod 存在的意义
- 创建容器使用 docker,一个 docker 对应一个容器,一个容器运行一个应用进程
- Pod 是多进程设计,运用多个应用程序,也就是一个 Pod 里面有多个容器,而一个容器里面运行一个应用程序
- Pod 的存在是为了亲密性应用
- 两个应用之间进行交互
- 网络之间的调用【通过 127.0.0.1 或 socket】
- 两个应用之间需要频繁调用
3.2 Pod 实现机制
Pod 主要有以下两大机制:共享网络 和 共享存储
- 共享网络【容器通过 namespace 和 group 进行隔离】,Pod 中容器通信 过程:
- 同一个 namespace 下
- 在 Pod 中创建一个根容器:
pause 容器 - 在 Pod 中创建业务容器 【nginx,redis 等】【创建时会添加到
info 容器中】 - 在
info 容器中会独立出 ip 地址,mac 地址,port 等信息,然后实现网络的共享
- 共享存储【Pod 持久化数据,专门存储到某个地方中,使用 Volumn 数据卷进行共享存储】
3.3 Pod 镜像拉取策略
拉取策略就是 imagePullPolicy,有以下几个值
IfNotPresent:默认值,镜像在宿主机上不存在才拉取Always:每次创建 Pod 都会重新拉取一次镜像Never:Pod 永远不会主动拉取这个镜像
3.4 Pod 资源限制
Pod 在进行调度的时候,可以对调度的资源进行限制,例如我们限制 Pod 调度是使用的资源是 2C4G,那么在调度对应的 node 节点时,只会占用对应的资源,对于不满足资源的节点,将不会进行调度。
这里分了两个部分:
request:表示调度所需的资源limits:表示最大所占用的资源
sepc:
containers:
- name: db
image: mysql
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
3.5 Pod 重启机制
因为 Pod 中包含了很多个容器,假设某个容器出现问题了,那么就会触发 Pod 重启机制
restartPolicy重启策略主要分为以下三种:
Always:当容器终止退出后,总是重启容器,默认策略 【nginx 等,需要不断提供服务】OnFailure:当容器异常退出(退出状态码非 0)时,才重启容器。Never:当容器终止退出,从不重启容器 【批量任务】
3.6 Pod 健康检查
# 通过容器检查
kubectl get pod
# 通过应用检查,因为有的时候,程序可能出现了 Java 堆内存溢出,程序还在运行,但是不能对外提供服务了,这个时候就不能通过容器检查来判断服务是否可用了。需要通过应用检查
# 存活检查,如果检查失败,将杀死容器,根据 Pod 的 restartPolicy【重启策略】来操作
livenessProbe
# 就绪检查,如果检查失败,Kubernetes 会把 Pod 从 Service endpoints 中剔除
readinessProbe
Probe 支持以下三种检查方式
http Get:发送 HTTP 请求,返回 200 - 400 范围状态码为成功exec:执行 Shell 命令返回状态码是 0 为成功tcpSocket:发起 TCP Socket 建立成功
3.7 Pod 调度策略
- 首先创建一个 pod,然后创建一个 API Server 和 Etcd【把创建出来的信息存储在 etcd 中】
- 然后创建 Scheduler,监控 API Server 是否有新的 Pod,如果有的话,会通过调度算法,把 pod 调度某个 node 上
- 在 node 节点,会通过
kubelet -- apiserver读取 etcd 拿到分配在当前 node 节点上的 pod,然后通过 docker 创建容器
Pod资源限制对Pod的调度会有影响,节点选择器标签影响Pod调度,如果不满足就不会在该结点运行
# 给我们的节点新增标签
kubectl label node m1 env_role=prod
kubectl get nodes m1 --show-labels
# nodeSelector结点选择器会选择对应Pod
节点亲和性 nodeAffinity (比选择器更强)和 之前nodeSelector 基本一样的,根据节点上标签约束来决定Pod调度到哪些节点上
- 硬亲和性:约束条件必须满足
- 软亲和性:尝试满足,不保证

支持常用操作符:in、NotIn、Exists、Gt、Lt、DoesNotExists
反亲和性:就是和亲和性刚刚相反,如 NotIn、DoesNotExists等
apiVersion: v1 # api版本
kind: Pod # 组件类型
metadata:
name: nginx-mysql-pod
labels: # 标签
app: nginx-mysql
spec:
# 结点选择器
#nodeSelector:
#env_role: prod
containers:
- name: nginx # 名称
image: nginx # image地址
- name: mysql
image: mysql
env: # 环境变量
- name: MYSQL_ROOT_PASSWORD
value: mysql
imagePullPolicy: IfNotPresent #镜像拉取策略
# 资源限制策略
resources:
requests:
memory: "64Mi"
cpu: "250m"
# 重启机制
restartPolicy: Never
# Pod健康检查
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
3.8 污点和污点容忍
nodeSelector 和 NodeAffinity,都是Prod调度到某些节点上,属于Pod的属性,是在调度的时候实现的。Taint 污点:节点不做普通分配调度,是节点属性;污点容忍就是某个节点可能被调度,也可能不被调度
使用场景
- 专用节点【限制ip】
- 配置特定硬件的节点【固态硬盘】
- 基于Taint驱逐【在node1不放,在node2放】
污点值:
- NoSchedule:一定不被调度
- PreferNoSchedule:尽量不被调度【也有被调度的几率】
- NoExecute:不会调度,并且还会驱逐Node已有Pod
# 查看节点污点
kubectl describe node k8smaster | grep Taint
# 为节点添加污点
kubectl taint node [node] key=value:污点的三个值
kubectl taint node k8snode1 env_role=yes:NoSchedule
# 删除污点
kubectl taint node k8snode1 env_role:NoSchedule-
#==============演示=============================
# 我们现在创建多个Pod,查看最后分配到Node上的情况
kubectl create deployment web --image=nginx
kubectl get pods -o wide
# 所以节点都被分配到了 node1 和 node2节点上
kubectl scale deployment web --replicas=5
kubectl delete deployment web
# 给 node1节点打上污点
kubectl taint node k8snode1 env_role=yes:NoSchedule
# 然后我们查看污点是否成功添加
kubectl describe node k8snode1 | grep Taint
# 创建nginx pod
kubectl create deployment web --image=nginx
# 复制五次
kubectl scale deployment web --replicas=5
# 然后我们在进行查看
kubectl get pods -o wide
# 现在所有的pod都被分配到了 k8snode2上,因为刚刚我们给node1节点设置了污点
# 删除刚刚添加的污点
kubectl taint node k8snode1 env_role:NoSchedule-
4、Controller之Deployment
4.1 Controller 简介
Controller 是集群上管理和运行容器的对象
- Controller 是实际存在的
- Pod 是虚拟机的
Pod 是通过 Controller 实现应用的运维,比如弹性收缩,滚动升级。Pod 和 Controller 之间是通过 label 标签建立关系,同时 Controller 又被称为控制器工作负载。
- Controller【控制器】【工作负载】
selector: app:nginx - Pod【容器】
labels: app:nginx
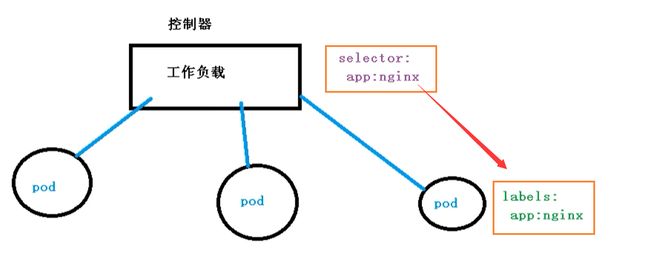
4.2 Deployment控制器应用
- Deployment控制器可以部署无状态应用
- 管理Pod和ReplicaSet
- 部署,滚动升级等功能
- 应用场景:web服务,微服务
Deployment表示用户对K8S集群的一次更新操作。Deployment是一个比RS( Replica Set, RS) 应用模型更广的 API 对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。滚动升级一个服务,实际是创建一个新的RS,然后逐渐将新 RS 中副本数增加到理想状态,将旧RS中的副本数减少到0的复合操作。这样一个复合操作用一个RS是不好描述的,所以用一个更通用的Deployment来描述。以K8S的发展方向,未来对所有长期伺服型的业务的管理,都会通过Deployment来管理
4.3 Deployment 部署应用
# 使用 Deploment 部署应用,代码如下:【缺点:代码不好复用】
kubectrl create deployment web --image=nginx
# 使用 YAML 文件进行配置:【快速编写 YAML 文件】
kubectl create deployment web --image=nginx -o yaml --dry-run > nginx.yaml
# nginx.yaml 文件【selector 和 label 就是我们 Pod 和 Controller 之间建立关系的桥梁】
# 使用nginx.yaml文件创建镜像
kubectl apply -f nginx.yaml
# 对外暴露端口
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web1
# 参数说明
# --port:就是我们内部的端口号
# --target-port:就是暴露外面访问的端口号
# --name:名称
# --type:类型
# 同理,导出配置文件
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web1 -o yaml > web1.yaml
# 查看端口,然后就可以访问了
kubectl get pods,svc
举例
apiVersion: apps/v1 #指定api版本标签】
kind: Deployment
#定义资源的类型/角色】,deployment为副本控制器,此处资源类型可以是Deployment、Job、Ingress、Service等
metadata : #定义资源的元数据信息,比如资源的名称、namespace、标签等信息
name: nginx #定义资源的名称,在同一个namespace空间中必须是唯一的
labels: #定义资源标签(Pod的标签)
app: nginx
spec: #定义deployment资源需要的参数属性,诸如是否在容器失败时重新启动容器的属性
replicas: 3 #定义副本数量
selector: #定义标签选择器
matchLabels : #定义匹配标签
app: nginx #匹配上面的标签,需与上面的标签定义的app保持一致
template: #【定义业务模板】,如果有多个副本,所有副本的属性会按照模板的相关配置进行匹配
metadata:
labels:
app: nginx
spec:
containers: #定义容器属性
- name: nginx #定义一个容器名,一个- name:定义一个容器
image: nginx:1.15.4 #定义容器使用的镜像以及版本
imagePullPolicy: IfNotPresent #镜像拉取策略
ports:
- containerPort: 80 #定义容器的对外的端口
4.4 升级回滚和弹性收缩
- 升级: 假设从版本为 1.14 升级到 1.15 ,这就叫应用的升级【升级可以保证服务不中断】
- 回滚:从版本 1.15 变成 1.14,这就叫应用的回滚
- 弹性伸缩:我们根据不同的业务场景,来改变 Pod 的数量对外提供服务,这就是弹性伸缩
# 应用升级
kubectl set image deployment nginx nginx=nginx:1.15
# 我们在下载 1.15 版本,容器就处于 ContainerCreating 状态,然后下载完成后,就用 1.15 版本去替换 1.14 版本了,这么做的好处就是:升级可以保证服务不中断
kubectl rollout status deployment nginx
kubectl rollout history deployment nginx
# 回滚到上一版本
kubectl rollout undo deployment nginx
# 回滚到指定版本
kubectl rollout undo deployment nginx --to-revision=2
# 通过命令创建多个副本
kubectl scale deployment nginx --replicas=10
# 查看
kubectl get pod
5、Service
文档参考:https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/#headless-services
5.1 service概述
前面我们了解到 Deployment 只是保证了支撑服务的微服务Pod的数量,但是没有解决如何访问这些服务的问题。一个Pod只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以一个新的IP启动一个新的Pod,因此不能以确定的IP和端口号提供服务。
要稳定地提供服务需要服务发现和负载均衡能力。服务发现完成的工作,是针对客户端访问的服务,找到对应的后端服务实例。在K8S集群中,客户端需要访问的服务就是Service对象。每个Service会对应一个集群内部有效的虚拟IP,集群内部通过虚拟IP访问一个服务。在K8S集群中,微服务的负载均衡是由kube-proxy实现的。kube-proxy是k8s集群内部的负载均衡器。它是一个分布式代理服务器,在K8S的每个节点上都有一个;这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的kube-proxy就越多,高可用节点也随之增多。与之相比,我们平时在服务器端使用反向代理作负载均衡,还要进一步解决反向代理的高可用问题。
5.2 Service存在的意义
-
防止Pod失联【服务发现】
因为Pod每次创建都对应一个IP地址,而这个IP地址是短暂的,每次随着Pod的更新都会变化,假设当我们的前端页面有多个Pod时候,同时后端也多个Pod,这个时候,他们之间的相互访问,就需要通过注册中心,拿到Pod的IP地址,然后去访问对应的Pod
-
定义Pod访问策略【负载均衡】
页面前端的Pod访问到后端的Pod,中间会通过Service一层,而Service在这里还能做负载均衡,负载均衡的策略有很多种实现策略,例如:
- 随机
- 轮询
- 响应比
5.3 Pod和Service的关系
这里Pod 和 Service 之间还是根据 label 和 selector 建立关联的 【和Controller一样】,我们在访问service的时候,其实也是需要有一个ip地址,这个ip肯定不是pod的ip地址,而是 虚拟IP vip
5.4 Service常用类型
- ClusterIp:集群内部访问
- NodePort:对外访问应用使用
- LoadBalancer:对外访问应用使用,公有云
kubectl expose deployment nginx --port=80 --target-port=80 --dry-run -o yaml > service.yaml
# 修改完命令后,我们使用创建一个pod
kubectl apply -f service.yaml
# 也可以对外暴露端口,这样是随机的
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=nginx
kubectl get service
kubectl get svc
# 查看服务详情,可以发现 Endpoints 是各个 Pod 的 IP,也就是他会把流量转发到这些节点
kubectl describe svc test-k8s
# 服务的默认类型是ClusterIP,只能在集群内部访问,我们可以进入到 Pod 里面访问
kubectl exec -it pod-name -- bash
curl http://nginx:80
# 如果要在集群外部访问,可以通过端口转发实现(只适合临时测试用)
kubectl port-forward service/nginx 8080:80
curl http://localhost:8080
如果我们没有做设置的话,默认使用的是第一种方式 ClusterIp,也就是只能在集群内部使用,我们可以添加一个type字段,用来设置我们的service类型
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
#nodePort: 31000 # 指定暴露节点端口,范围固定 30000 ~ 32767
selector:
app: nginx
type: NodePort
status:
loadBalancer: {}
运行后能够看到,已经成功修改为 NodePort类型了,最后剩下的一种方式就是LoadBalanced:对外访问应用使用公有云,node一般是在内网进行部署,而外网一般是不能访问到的,那么如何访问的呢?
- 找到一台可以通过外网访问机器,安装nginx,反向代理
- 手动把可以访问的节点添加到nginx中
如果我们使用LoadBalancer,就会有负载均衡的控制器,类似于nginx的功能,就不需要自己添加到nginx上
6、Controller之Statefulset
6.1 Statefulset概述
Statefulset主要是用来部署有状态应用。对于StatefulSet中的Pod,每个Pod挂载自己独立的存储,如果一个Pod出现故障,从其他节点启动一个同样名字的Pod,要挂载上原来Pod的存储继续以它的状态提供服务。
前面我们部署的应用,都是不需要存储数据,不需要记住状态的,可以随意扩充副本,每个副本都是一样的,可替代的。 而像数据库、Redis 这类有状态的,则不能随意扩充副本。StatefulSet 会固定每个 Pod 的名字,具有以下特性
- Service 的
CLUSTER-IP是空的,Pod 名字也是固定的。 - Pod 创建和销毁是有序的,创建是顺序的,销毁是逆序的。
- Pod 重建不会改变名字,除了IP,所以不要用IP直连
6.2 无状态和有状态容器
无状态应用,我们原来使用 deployment,部署的都是无状态的应用
- 认为Pod都是一样的
- 没有顺序要求
- 不考虑应用在哪个node上运行
- 能够进行随意伸缩和扩展
有状态应用,上述的因素都需要考虑到
- 每个Pod独立的,保持Pod启动顺序和唯一性
- 唯一的网络标识符,持久存储
- 有序,比如mysql中的主从
适合StatefulSet的业务包括数据库服务MySQL 和 PostgreSQL,集群化管理服务Zookeeper、etcd等有状态服务。StatefulSet的另一种典型应用场景是作为一种比普通容器更稳定可靠的模拟虚拟机的机制。传统的虚拟机正是一种有状态的宠物,运维人员需要不断地维护它,容器刚开始流行时,我们用容器来模拟虚拟机使用,所有状态都保存在容器里,而这已被证明是非常不安全、不可靠的。
使用StatefulSet,Pod仍然可以通过漂移到不同节点提供高可用,而存储也可以通过外挂的存储来提供 高可靠性,StatefulSet做的只是将确定的Pod与确定的存储关联起来保证状态的连续性
6.3 部署有状态应用
无头service, ClusterIp:none。这里就需要使用 StatefulSet部署有状态应用
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulset
namespace: default
spec:
serviceName: nginx
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14-alpine
ports:
- containerPort: 80
然后通过查看pod,能否发现每个pod都有唯一的名称;然后我们在查看service,发现是无头的service
这里有状态的约定,肯定不是简简单单通过名称来进行约定,而是更加复杂的操作
- deployment:是有身份的,有唯一标识
- statefulset:根据主机名 + 按照一定规则生成域名
每个pod有唯一的主机名,并且有唯一的域名
- 格式:主机名称.service名称.名称空间.svc.cluster.local
- 举例:nginx-statefulset-0.default.svc.cluster.local
7、Controller之其他应用
7.1 DaemonSet
DaemonSet 即后台支撑型服务,主要是用来部署守护进程
长期伺服型和批处理型的核心在业务应用,可能有些节点运行多个同类业务的Pod,有些节点上又没有这类的Pod运行;而后台支撑型服务的核心关注点在K8S集群中的节点(物理机或虚拟机),要保证每个节点上都有一个此类Pod运行。节点可能是所有集群节点,也可能是通过 nodeSelector选定的一些特定节点。典型的后台支撑型服务包括:存储、日志和监控等。在每个节点上支撑K8S集群运行的服务。
守护进程在我们每个节点上,运行的是同一个pod,新加入的节点也同样运行在同一个pod里面
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-test
namespace: default
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
containers:
- name: logs
image: nginx
ports:
- containerPort: 80
# #容器内挂载点
volumeMounts:
- name: varlog
mountPath: /tmp/log
volumes:
- name: varlog
hostPath:
path: /var/log #宿主机挂载点
kubectl apply -f daemon.yaml
kubectl get pod -owide
kubectl exec -it ds-test-cbk6v bash
7.2 Job和CronJob
- 一次性任务:一次性执行完就结束
- 定时任务:周期性执行
Job是K8S中用来控制批处理型任务的API对象。批处理业务与长期伺服业务的主要区别就是批处理业务的运行有头有尾,而长期伺服业务在用户不停止的情况下永远运行。Job管理的Pod根据用户的设置把任务成功完成就自动退出了。成功完成的标志根据不同的 spec.completions 策略而不同:单Pod型任务有一个Pod成功就标志完成;定数成功行任务保证有N个任务全部成功;工作队列性任务根据应用确定的全局成功而标志成功。
# job的yaml文件
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
# 失败后尝试次数
backoffLimit: 4
---
# CronJob的yaml文件
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: registry.cn-beijing.aliyuncs.com/google_registry/busybox:1.24
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
命令操作
# 能够看到目前已经存在的Job
kubectl get jobs
# 我们可以通过查看日志,查看到一次性任务的结果
kubectl logs pi-qpqff
# 查看定时任务,每隔一次会创建一个
kubectl get cronjobs
# 删除svc 和 statefulset
kubectl delete svc web
kubectl delete statefulset --all
kubectl delete cronjobs hello
7.3 Replication Controller
Replication Controller 简称 RC,是K8S中的复制控制器。RC是K8S集群中最早的保证Pod高可用的API对象。通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RC就会启动新的Pod副本;多于指定数目,RC就会杀死多余的Pod副本。即使在指定数目为1的情况下,通过RC运行Pod也比直接运行Pod更明智,因为RC也可以发挥它高可用的能力,保证永远有一个Pod在运行。RC是K8S中较早期的技术概念,只适用于长期伺服型的业务类型,比如控制Pod提供高可用的Web服务。
Replica Set 检查 RS,也就是副本集。RS是新一代的RC,提供同样高可用能力,区别主要在于RS后来居上,能够支持更多种类的匹配模式。副本集对象一般不单独使用,而是作为Deployment的理想状态参数来使用
四、Kubernetes 核心概念(进阶)
1、Kubernetes配置管理
1.1 Secret
参考文档:https://kubernetes.io/zh-cn/docs/concepts/configuration/secret/
Secret的主要作用就是加密数据,然后存在etcd里面,让Pod容器以挂载Volume方式进行访问,一般场景的是对某个字符串进行base64编码 进行加密
- 场景:用户名 和 密码进行加密
密码文件举例
apiVersion: v1
data:
# 下面就是定义的值密码了【其实我们设置的是redhat1和redhat2,在文件中就显示为被加密过的值了,用了base64
username: YWRtaW4=
password: YWRtaW4=
kind: Secret
metadata:
creationTimestamp: "2022-08-30T03:13:56Z"
name: mysecret
type: Opaque
变量形式挂载到Pod
echo -n 'admin' | base64
# 密码文件见下面
kubectl create -f secret.yaml
kubectl apply -f secret-val.yaml
kubectl get pods
kubectl get secret
kubectl exec -it mypod bash
# 输出用户
echo $SECRET_USERNAME
# 输出密码
echo $SECRET_PASSWORD
# 要删除这个Pod,就可以使用这个命令
kubectl delete -f secret-val.yaml
然后可以将密码文件挂载到pod,注意名字和key要和密码文件一一对应
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
数据卷形式挂载
# 根据配置创建容器
kubectl apply -f secret-val.yaml
# 进入容器
kubectl exec -it mypod bash
# 查看,会发现username文件和password文件
ls /etc/foo
修改secret-val.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes:
- name: foo
secret:
secretName: mysecret
举例docker密钥的保存
##命令格式
kubectl create secret docker-registry regcred \
--docker-server=<你的镜像仓库服务器> \
--docker-username=<你的用户名> \
--docker-password=<你的密码> \
--docker-email=<你的邮箱地址>
---
# 编写pod,这样就可以拉取私密镜像仓库了
apiVersion: v1
kind: Pod
metadata:
name: private-nginx
spec:
containers:
- name: private-nginx
image: shawn/guignginx:v1.0
imagePullSecrets:
- name: shawn-docker
1.2 ConfigMap
参考文档:https://kubernetes.io/zh/docs/concepts/configuration/configmap/
ConfigMap作用是存储不加密的数据到etcd中,让Pod以变量或数据卷Volume挂载到容器中;应用场景:配置文件
首先我们需要创建一个配置文件 redis.properties
redis.port=127.0.0.1
redis.port=6379
redis.password=123456
我们使用命令创建configmap
kubectl create configmap redis-config --from-file=redis.properties
# 然后查看详细信息
kubectl get configmap
kubectl describe cm redis-config
Volume数据卷形式挂载
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh","-c","cat /etc/config/redis.properties"]
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: redis-config
restartPolicy: Never
以redis举例,可以抽取应用配置,并且可以自动更新;修改了CM,Pod里面的配置文件会跟着变,但要用需要重启redis
apiVersion: v1
data: #data是所有真正的数据,key:默认是文件名 value:配置文件的内容
redis.conf: |
appendonly yes
kind: ConfigMap
metadata:
name: redis-conf
namespace: default
----
# 创建配置,redis保存到k8s的etcd;
kubectl create cm redis-conf --from-file=redis.conf
----
# 创建pod
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis
command:
- redis-server
- "/redis-master/redis.conf" #指的是redis容器内部的位置
ports:
- containerPort: 6379
volumeMounts:
- mountPath: /data
name: data
- mountPath: /redis-master
name: config
volumes:
- name: data
emptyDir: {}
- name: config
configMap:
name: redis-conf
items:
- key: redis.conf
path: redis.conf
---
# 检查默认配置
kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET appendonly
127.0.0.1:6379> CONFIG GET requirepass
---
# 检查配置是否更新
kubectl exec -it redis -- redis-cli
127.0.0.1:6379> CONFIG GET maxmemory
127.0.0.1:6379> CONFIG GET maxmemory-policy
以变量的形式挂载Pod
apiVersion: v1
kind: ConfigMap
metadata:
name: myconfig
namespace: default
data:
special.level: info
special.type: hello
命令
# 创建pod
kubectl apply -f myconfig.yaml
# 获取
kubectl get cm
kubectl logs mypod
然后创建可以挂载的Pod
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh","-c","echo $(LEVEL) $(TYPE)"]
env:
- name: LEVEL
valueFrom:
configMapKeyRef:
name: myconfig
key: special.level
- name: TYPE
valueFrom:
configMapKeyRef:
name: myconfig
key: special.type
restartPolicy: Never
2、Kubernetes集群安全机制
2.1 概述
当我们访问K8S集群时,需要经过三个步骤完成具体操作
- 认证
- 鉴权【授权】
- 准入控制
进行访问的时候,都需要经过 apiserver, apiserver做统一协调,比如门卫
- 访问过程中,需要证书、token、或者用户名和密码
- 如果访问pod需要serviceAccount
认证
对外不暴露8080端口,只能内部访问,对外使用的端口6443,客户端身份认证常用方式
- https证书认证,基于ca证书
- http token认证,通过token来识别用户
- http基本认证,用户名 + 密码认证
鉴权
基于RBAC进行鉴权操作;基于角色访问控制
准入控制
就是准入控制器的列表,如果列表有请求内容就通过,没有的话 就拒绝
2.2 RBAC介绍
基于角色的访问控制,为某个角色设置访问内容,然后用户分配该角色后,就拥有该角色的访问权限
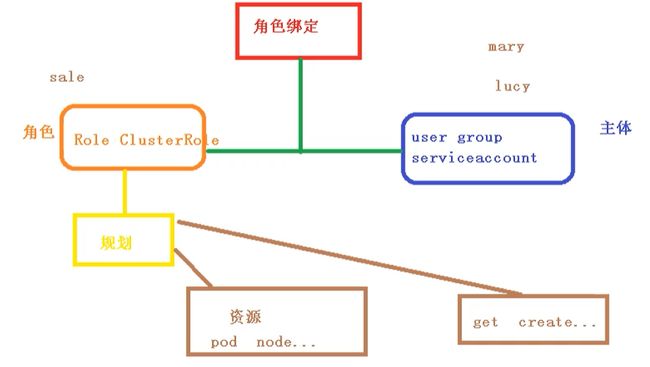
k8s中有默认的几个角色
- role:特定命名空间访问权限
- ClusterRole:所有命名空间的访问权限
角色绑定
- roleBinding:角色绑定到主体
- ClusterRoleBinding:集群角色绑定到主体
主体
- user:用户
- group:用户组
- serviceAccount:服务账号
2.3 RBAC实现鉴权
首先创建角色, rbac-role.yaml进行创建,这个角色只对pod 有 get、list权限
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: pod-reader
namespace: roledemo
rules:
- apiGroups: [""] # ""indicates the core API group
resources: ["pods"]
verbs: ["get","watch","list"]
相关命令
# 查看已经存在的命名空间
kubectl get namespace
# 创建一个自己的命名空间 roledemo
kubectl create ns roledemo
# 默认是在default空间下
kubectl run nginx --image=nginx -n roledemo
# 查看
kubectl get pod -n roledemo
# 创建
kubectl apply -f rbac-role.yaml
# 查看角色
kubectl get role -n roledemo
然后进行创建角色绑定,通过 role-rolebinding.yaml 的方式,来创建我们的角色绑定
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: roledemo
subjects:
- name: shawn
kind: User
apiGroup: rbac.authorization.k8s.io
roleRef:
name: pod-reader # 这里的名称必须与你想要绑定的 Role 或 ClusterRole 名称一致
kind: Role #这里必须是Role或者ClusterRole
apiGroup: rbac.authorization.k8s.io
执行相关命令
# 创建角色绑定
kubectl apply -f rbac-rolebinding.yaml
# 查看角色绑定
kubectl get role, rolebinding -n roledemo
# http://docs.kubernetes.org.cn/494.html
# 在集群范围将cluster-admin ClusterRole授予用户user1,user2和group1
kubectl create clusterrolebinding cluster-admin --clusterrole=cluster-admin --user=user1 --user=user2 --group=group1
3、核心技术Ingress
官网地址:https://kubernetes.github.io/ingress-nginx/
3.1 前言概述
原来我们需要将端口号对外暴露,通过 ip + 端口号就可以进行访问,是使用Service中的NodePort来实现
- 在每个节点上都会启动端口
- 在访问的时候通过任何节点,通过ip + 端口号就能实现访问
但是NodePort还存在一些缺陷
- 因为端口不能重复,所以每个端口只能使用一次,一个端口对应一个应用
- 实际访问中都是用域名,根据不同域名跳转到不同端口服务中
3.2 Ingress和Pod关系
pod 和 ingress 是通过service进行关联的,而ingress作为统一入口,由service关联一组pod中
- 首先service就是关联我们的pod
- 然后ingress作为入口,首先需要到service,然后发现一组pod
- 发现pod后,就可以做负载均衡等操作
在实际的访问中,我们都是需要维护很多域名,a.com 和 b.com然后不同的域名对应的不同的Service,然后service管理不同的pod(ingress不是内置的组件,需要我们单独的安装),相当于Nginx
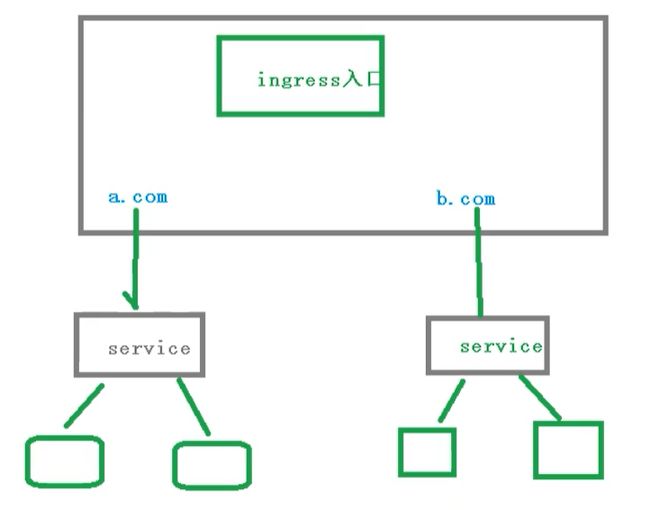
3.3 创建Ingress规则
参考:ingress-controller部署
github:https://github.com/kubernetes/ingress-nginx
- 部署ingress Controller【需要下载官方的】
- 创建ingress规则【对哪个Pod、名称空间配置规则】
# 创建一个nginx应用,然后对外暴露端口,创建pod
kubectl create deployment web --image=nginx
# 查看
kubectl get pods
# 对外暴露端口
kubectl expose deployment web --port=80 --target-port=80 --type=NodePort
kubectl get svc
# 额外下载,这个有版本匹配要求
# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/nginx-0.30.0/deploy/static/mandatory.yaml -O nginx-ingress-controller.yaml
# 可以在spec.template.spec添加 hostNetwork: true,改成ture是为了让后面访问到,不然就是使用service的"type: NodePort"方式暴露的
# 使用"hostNetwork: true"配置网络,pod中运行的应用程序可以直接看到宿主主机的网络接口,宿主机所在的局域网上所有网络接口都可以访问到该应用程序及端口
kubectl apply -f ingress-controller.yaml
# 查看一下
kubectl get pod -n ingress-nginx
kubectl get pod,svc -n ingress-nginx
# 然后可以测试访问一下端口
# 创建ingress规则文件ingress.yaml,如下,然后运行
kubectl apply -f ingress.yaml
# 最后通过下面命令,查看是否成功部署 ingress
kubectl get pods -n ingress-nginx
现在还只能在集群内部访问,需要暴露service,vimservice-nodeport.yaml
---
apiVersion: v1
kind: Service
metadata:
name: ingress-nginx
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
# HTTP
nodePort: 32080
- name: https
port: 443
targetPort: 443
protocol: TCP
# HTTPS
nodePort: 32443
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
ingress.yaml规则文件,注意不同版本间的写法有差异
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ingress-host-bar
spec:
rules:
# 这是访问的域名
- host: shawn.com
http:
paths:
- pathType: Prefix
# 路径,可以分割,把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
path: /
backend:
serviceName: nginx
servicePort: 80
在windows 的 hosts文件,添加域名访问规则【因为我们没有域名解析,所以只能这样做】,最后通过域名:32080就能访问
xx.xx.xx.xx shawn.com
3.4 其他高级配置
其他高级选项和nginx类似,可以通过高级注解选择,参考:nginx-ingress注解官网
路径重写
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
name: ingress-rewrite-bar
spec:
rules:
# 这是访问的域名
- host: "rewrite.shawn.com"
http:
paths:
# 重写路径,去除nginx
# 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
- path: /something(/|$)(.*)
backend:
serviceName: nginx
servicePort: 80
流量限制
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ingress-limit-rate
annotations:
nginx.ingress.kubernetes.io/limit-rps: "1"
spec:
rules:
# 这是访问的域名
- host: "limit.shawn.com"
http:
paths:
- pathType: Exact
# 重写路径,去除nginx
# 把请求会转给下面的服务,下面的服务一定要能处理这个路径,不能处理就是404
path: "/"
backend:
serviceName: nginx
servicePort: 80
4、Kubernetes核心技术Helm
Helm官网:https://helm.sh/zh/
包搜索:https://artifacthub.io/
4.1 Helm概述
Helm是一个Kubernetes的包管理工具,就像Linux下的包管理器,如yum/apt等,可以很方便的将之前打包好的yaml文件部署到kubernetes上。Helm就是一个包管理工具【类似于npm】。Helm有三个重要概念
- helm:一个命令行客户端工具,主要用于Kubernetes应用chart的创建、打包、发布和管理
- Chart:应用描述,一系列用于描述k8s资源相关文件的集合
- Release:基于Chart的部署实体,一个chart被Helm运行后将会生成对应的release,将在K8S中创建出真实的运行资源对象。也就是应用级别的版本管理
- Repository:用于发布和存储Chart的仓库
V3版本变化
- 架构变化
- 最明显的变化是Tiller的删除
- V3版本删除Tiller
- relesase可以在不同命名空间重用
4.2 helm下载与配置
安装文档:https://helm.sh/zh/docs/intro/install/
# 脚本安装,不过可能会失败
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
# 手动进行安装
wget https://get.helm.sh/helm-v3.10.1-linux-amd64.tar.gz
tar -zxvf helm-v3.10.1-linux-amd64.tar.gz
sudo mv linux-amd64/helm /usr/local/bin/helm
helm --help
# 配置微软源
helm repo add stable http://mirror.azure.cn/kubernetes/charts
# 配置阿里源
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
# 配置google源
helm repo add google https://kubernetes-charts.storage.googleapis.com/
# 更新
helm repo update
# 查看全部
helm repo list
# 查看某个
helm search repo stable
# 删除我们添加的源
helm repo remove stable
4.3 使用helm快速部署应用
# 搜索 weave仓库
helm search repo weave
# 搜索完成后,使用命令进行安装
helm install ui aliyun/weave-scope
# 来下载yaml文件【如果】
kubectl apply -f weave-scope.yaml
# 查看
helm list
helm install ui stable/weave-scope
# 查询状态
helm status ui
# 我们通过查看 svc状态,发现没有对象暴露端口
# 需要修改service的yaml文件,添加NodePort
kubectl edit svc ui-weave-scope
4.4 自定义Chart
目录格式
- templates:编写yaml文件存放到这个目录
- values.yaml:存放的是全局的yaml文件
- chart.yaml:当前chart属性配置信息
# 使用命令,自己创建Chart
helm create mychart
# 在templates文件夹创建两个文件
# 导出deployment.yaml
kubectl create deployment web1 --image=nginx --dry-run -o yaml > deployment.yaml
# 导出service.yaml 【可能需要创建 deployment,不然会报错】
kubectl expose deployment web1 --port=80 --target-port=80 --type=NodePort --dry-run -o yaml > service.yaml
# 执行命令创建,在mychart/外层目录执行
helm install web1 mychart
# 当我们修改了mychart中的东西后,就可以进行升级操作
helm upgrade web1 mychart
4.5 chart模板使用
通过传递参数,动态渲染模板,yaml内容动态从传入参数生成
刚刚我们创建mychart的时候,看到有values.yaml文件,这个文件就是一些全局的变量,然后在templates中能取到变量的值,下面我们可以利用这个,来完成动态模板
- 在values.yaml定义变量和值
- 具体yaml文件,获取定义变量值
- yaml文件中大题有几个地方不同
- image
- tag
- label
- port
- replicas
# 在values.yaml定义变量和值
replicas: 3
image: nginx
tag: 1.16
label: nginx
port: 80
# 获取变量和值
# 我们通过表达式形式 使用全局变量 {{.Values.变量名称}} 例如: {{.Release.Name}}
# 然后修改模板文件
# 生成文件查看一下
helm install --dry-run web2 mychart
# 正式执行
helm install web2 mychart
修改模板文件
# deployment.yaml文件
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
name: {{.Release.Name}}-deployment
spec:
replicas: {{.Values.replicas}}
selector:
matchLabels:
app: {{.Values.label}}
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: {{.Values.label}}
spec:
containers:
- image: {{.Values.image}}
name: nginx
resources: {}
status: {}
----
# service.yaml文件
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
name: {{.Release.Name}}-svc
spec:
ports:
- port: {{.Values.port}}
protocol: TCP
targetPort: 80
selector:
app: {{.Values.label}}
type: NodePort
status:
loadBalancer: {}
5、命名空间
如果一个集群中部署了多个应用,所有应用都在一起,就不太好管理,也可以导致名字冲突等。我们可以使用 namespace 把应用划分到不同的命名空间,跟代码里的 namespace 是一个概念,只是为了划分空间
# 创建命名空间
kubectl create namespace testapp
# 部署应用到指定的命名空间
kubectl apply -f app.yml --namespace testapp
# 查询
kubectl get pod --namespace kube-system
# 查询命名空间
kubectl get ns
可以用 kubens 快速切换 namespace,首先进行下载安装
wget https://github.com/ahmetb/kubectx/releases/download/v0.9.4/kubens_v0.9.4_linux_x86_64.tar.gz
tar -zxvf kubens_v0.9.4_linux_x86_64.tar.gz
sudo mv kubens /usr/local/bin/kubens
# 查看所有命名空间
kubens
# 切换命名空间
kubens kube-system
# 回到上个命名空间
kubens -
# 切换集群
# kubectx minikube
6、Kubernetes持久化存储
6.1 概述
之前我们有提到数据卷:emptydir ,是本地存储,pod重启,数据就不存在了,需要对数据持久化存储,对于数据持久化存储【pod重启,数据还存在】,有两种方式
- nfs:网络存储【通过一台服务器来存储】
- PV和PVC
6.2 nfs网络存储
持久化服务器上操作,所有结点都需要安装nfs-utils
# 找一台新的服务器nfs服务端,安装nfs,设置挂载路径,使用命令安装nfs
yum install -y nfs-utils
# 首先创建存放数据的目录
mkdir -p /data/nfs
# 设置挂载路径
# 打开文件
vim /etc/exports
# 添加如下内容
# /data/nfs *(rw,no_root_squash)
# 或者执行
echo "/data/nfs/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
# 执行完成后,即部署完我们的持久化服务器
systemctl enable rpcbind --now
systemctl enable nfs-server --now
#配置生效
exportfs -r
从节点上操作
# 然后需要在k8s集群node节点上安装nfs,这里需要在 node1 和 node2节点上安装
yum install -y nfs-utils
# 执行完成后,会自动帮我们挂载上
showmount -e 192.168.249.139
#执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /root/nfsmount
mkdir -p /data/nfs
mount -t nfs 192.168.249.139:/data/nfs /data/nfs
# 写入一个测试文件,这样两个机器就联通了
echo "hello nfs server" > /data/nfs/test.txt
K8s集群部署应用
# 最后我们在k8s集群上部署应用,使用nfs持久化存储
# 创建一个pv文件
mkdir pv
# 进入
cd pv
创建nfs-nginx.yaml文件,注意修改ip
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dep1
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: wwwroot
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: wwwroot
nfs:
server: 192.168.249.139
path: /data/nfs
测试
kubectl apply -f nfs-nginx.yaml
kubectl describe pod nginx-dep1
# 进入pod中查看
kubectl exec -it nginx-dep1-77f6bcbd45-q9rfz -- bash
# 在/data/nfs创建文件,容器内部会出现,成功挂载
ls /usr/share/nginx/html/
kubectl expose deployment nginx-depl --port=80 --target-port=80 --type=NodePort
6.3 PV和PVC
- PV:持久化存储,对存储的资源进行抽象,对外提供可以调用的地方【生产者】
- PVC:用于调用,不需要关心内部实现细节【消费者】
PV 和 PVC 使得 K8S 集群具备了存储的逻辑抽象能力。使得在配置Pod的逻辑里可以忽略对实际后台存储 技术的配置,而把这项配置的工作交给PV的配置者,即集群的管理者。存储的PV和PVC的这种关系,跟 计算的Node和Pod的关系是非常类似的;PV和Node是资源的提供者,根据集群的基础设施变化而变 化,由K8s集群管理员配置;而PVC和Pod是资源的使用者,根据业务服务的需求变化而变化,由K8s集 群的使用者即服务的管理员来配置。
实现流程
- PVC绑定PV
- 定义PVC
- 定义PV【数据卷定义,指定数据存储服务器的ip、路径、容量和匹配模式】
# pvc.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-dep1
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: wwwroot
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: wwwroot
persistentVolumeClaim:
claimName: my-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 3Gi
storageClassName: nfs
---
# pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv01
spec:
capacity:
storage: 5Gi
# 相当于分组
storageClassName: nfs
accessModes:
- ReadWriteMany
nfs:
path: /data/nfs/01
server: 192.168.249.139
---
# pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv02
spec:
capacity:
storage: 10M
# 相当于分组
storageClassName: nfs
accessModes:
- ReadWriteMany
nfs:
path: /data/nfs/02
server: 192.168.249.139
测试
# 然后就可以创建pod了
kubectl apply -f pv.yaml
kubectl apply -f pvc.yaml
# 然后我们就可以通过下面命令,查看我们的 pv 和 pvc之间的绑定关系
kubectl get pv,pvc
kubect exec -it nginx-dep1 -- bash
# 然后查看 /usr/share/nginx.html
如果删除了pvc,会发现pv状态是处于Released的,需要进入特定的pv配置文件,删除claimRef下的内容即可
五、搭建集群监控平台系统
1、监控指标
一个好的监控系统主要监控以下内容:
- 集群监控
- 节点资源利用率
- 节点数
- 运行 Pods
- Pod 监控
- 容器指标
- 应用程序【程序占用多少 CPU、内存】
2、监控平台
台
- prometheus【监控】
- 定时搜索被监控服务的状态
- 开源
- 监控、报警、数据库
- 以 HTTP 协议周期性抓取被监控组件状态
- 不需要复杂的集成过程,使用 http 接口接入即可
- Grafana【展示】
- 开源的数据分析和可视化工具
- 支持多种数据源

3、部署 Pormetheus
3.1 创建守护进程Pod
首先需要部署一个守护进程,然后创建yaml文件vim node-exporter.yaml
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-system
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
template:
metadata:
labels:
k8s-app: node-exporter
spec:
containers:
- image: prom/node-exporter
name: node-exporter
ports:
- containerPort: 9100
protocol: TCP
name: http
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: node-exporter
name: node-exporter
namespace: kube-system
spec:
ports:
- name: http
port: 9100
nodePort: 31672
protocol: TCP
type: NodePort
selector:
k8s-app: node-exporter
然后通过yaml的方式部署prometheus:
- configmap:定义一个configmap:存储一些配置文件【不加密】
- prometheus.deploy.yaml:部署一个deployment【包括端口号,资源限制】
- prometheus.svc.yaml:对外暴露的端口
- rbac-setup.yaml:分配一些角色的权限
3.2 rbac创建
vim rbac-setup.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-system
3.3 ConfigMap
vim configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'kubernetes-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-ingresses'
kubernetes_sd_configs:
- role: ingress
relabel_configs:
- source_labels: [__meta_kubernetes_ingress_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__meta_kubernetes_ingress_scheme,__address__,__meta_kubernetes_ingress_path]
regex: (.+);(.+);(.+)
replacement: ${1}://${2}${3}
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.example.com:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_ingress_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_ingress_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
3.4 Deployment
vim prometheus.deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
name: prometheus-deployment
name: prometheus
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- image: prom/prometheus:v2.0.0
name: prometheus
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--storage.tsdb.retention=24h"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/prometheus"
name: data
- mountPath: "/etc/prometheus"
name: config-volume
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 2500Mi
serviceAccountName: prometheus
volumes:
- name: data
emptyDir: {}
- name: config-volume
configMap:
name: prometheus-config
3.5 Service
vim prometheus.svc.yaml
---
kind: Service
apiVersion: v1
metadata:
labels:
app: prometheus
name: prometheus
namespace: kube-system
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
nodePort: 30003
selector:
app: prometheus
3.6 创建与部署
kubectl create -f node-exporter.yaml
kubectl create -f rbac-setup.yaml
kubectl create -f configmap.yaml
kubectl create -f prometheus.deploy.yaml
kubectl create -f prometheus.svc.yaml
# 查看
kubectl get pod,svc -n kube-system | grep prometheus
# 浏览器访问:[ip:port] 192.168.249.139:30003
4、部署 Grafana
4.1 Deployment
vim grafana-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-core
namespace: kube-system
labels:
app: grafana
component: core
spec:
replicas: 1
selector:
matchLabels:
app: grafana
component: core
template:
metadata:
labels:
app: grafana
component: core
spec:
containers:
- image: grafana/grafana:4.2.0
name: grafana-core
imagePullPolicy: IfNotPresent
# env:
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
env:
# The following env variables set up basic auth twith the default admin user and admin password.
- name: GF_AUTH_BASIC_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "false"
# - name: GF_AUTH_ANONYMOUS_ORG_ROLE
# value: Admin
# does not really work, because of template variables in exported dashboards:
# - name: GF_DASHBOARDS_JSON_ENABLED
# value: "true"
readinessProbe:
httpGet:
path: /login
port: 3000
# initialDelaySeconds: 30
# timeoutSeconds: 1
volumeMounts:
- name: grafana-persistent-storage
mountPath: /var
volumes:
- name: grafana-persistent-storage
emptyDir: {}
4.2 Service
vim grafana-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-system
labels:
app: grafana
component: core
spec:
type: NodePort
ports:
- port: 3000
selector:
app: grafana
component: core
4.3 Runing
vim grafana-ing.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana
namespace: kube-system
spec:
rules:
- host: k8s.grafana
http:
paths:
- path: /
backend:
serviceName: grafana
servicePort: 3000
4.4 创建与部署
kubectl create -f grafana-deploy.yaml
kubectl create -f grafana-svc.yaml
kubectl create -f grafana-ing.yaml
kubectl get pod,svc -n kube-system | grep grafana
kubectl get pod,svc -A
# 注意url要填写集群内部的ip
# 浏览器访问:[ip:port] http://192.168.60.151:32389/
# 用户名/密码:admin/admin
# 注意ip是集群ip,然后选择Dashboard,选择import选择315模板(二进制搭建不知道为什么会失败,kubeadm搭建正常)
# 可以自行下载导入模板
# https://grafana.com/grafana/dashboards/?search=315
六、搭建高可用 Kubernetes 集群
1、高可用集群架构
之前我们搭建的集群,只有一个 master 节点,当 master 节点宕机的时候,通过 node 节点将无法继续访问,而 master 主要是管理作用,所以整个集群将无法提供服务
- 在 node 节点和 master 节点之间,需要一个 LoadBalancer 组件
- 【作用 1】负载
- 【作用 2】检查 master 节点的状态
- 对外需要一个统一的 VIP
- 【作用 1】虚拟 ip 对外进行访问
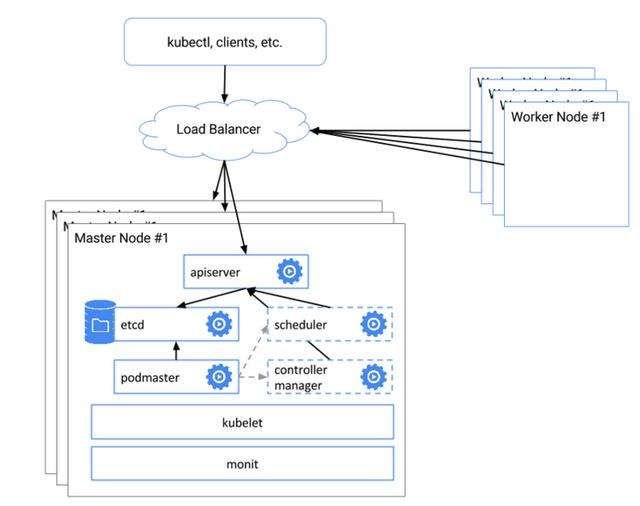
2、高可用集群环境准备
我们采用 2 个 master 节点,一个 node 节点来搭建高可用集群
2.1 安装步骤
使用二进制包方式搭建 Kubernetes 集群主要分为以下几步:
- 【环境准备】准备四台虚拟机,并安装操作系统 CentOS 7.x
- 【系统初始化】对四个刚安装好的操作系统进行初始化操作
- 【安装 docker、kubectl、kubeadm、kubectl】对四个节点进行安装
- 【配置高可用 VIP】对 master 节点安装
keepalived和haproxy - 【部署 master 组件】在 master 节点上安装
kube-apiserver、kube-controller-manager、kube-scheduler - 【安装网络插件】配置 CNI 网络插件,用于节点之间的连通
- 【测试集群】通过拉取一个 nginx 进行测试,能否进行外网测试
2.2 安装要求
- 一台或多台机器,操作系统 CentOS7.x-86_x64
- 硬件配置:2GB 或更多 RAM,2 个 CPU 或更多 CPU,硬盘 30GB 或更多【注意】【master 需要两核】
- 可以访问外网,需要拉取镜像,如果服务器不能上网,需要提前下载镜像并导入节点
- 禁止 swap 分区
2.3 准备环境
| 角色 | IP | 配置 | 步骤 |
|---|---|---|---|
| k8sLoadBalancer(这台可以不用) | 192.168.249.139 | 2CPU 1G | init docker kubectl kubeadm kubectl |
| k8smaster1 | 192.168.249.146 | 2CPU 2G | init docker kubectl kubeadm kubectl keepalived haproxy |
| k8smaster2 | 192.168.249.147 | 2CPU 2G | init docker kubectl kubeadm kubectl keepalived haproxy |
| k8snode1 | 192.168.249.148 | 2CPU 2G | init docker kubectl kubeadm kubectl |
3、高可用集群搭建
3.1 系统初始化
# 所有结点都需要
# 关闭防火墙
systemctl stop firewalld
# 禁用 firewalld 服务
systemctl disable firewalld
# 关闭 selinux
# 临时关闭【立即生效】告警,不启用,Permissive,查看使用 getenforce 命令
setenforce 0
# 永久关闭【重启生效】
sed -i 's/SELINUX=enforcing/\SELINUX=disabled/' /etc/selinux/config
# 关闭 swap
# 临时关闭【立即生效】查看使用 free 命令
swapoff -a
# 永久关闭【重启生效】
sed -ri 's/.*swap.*/#&/' /etc/fstab
# 在主机名静态查询表中添加 4 台主机
cat >> /etc/hosts << EOF
192.168.249.139 k8sLoadBalancer
192.168.249.146 k8smaster1
192.168.249.147 k8smaster2
192.168.249.148 k8snode1
EOF
# 将桥接的 IPv4 流量传递到 iptables 的链【3 个节点上都执行】
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 生效
sysctl --system
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
# 根据规划设置主机名【k8sLoadBalancer 节点上操作】
hostnamectl set-hostname k8sLoadBalancer
# 根据规划设置主机名【k8smaster1 节点上操作】
hostnamectl set-hostname k8smaster1
# 根据规划设置主机名【k8smaster2 节点上操作】
hostnamectl set-hostname k8smaster2
# 根据规划设置主机名【k8snode1 节点操作】
hostnamectl set-hostname k8snode1
3.2 安装 docker、kubelet、kubeadm、kubectl
所有节点安装 docker/kubelet/kubeadm/kubectl,Kubernetes 默认 CRI(容器运行时)为 docker,因此先安装 docker
# 所有结点都需要
# =========================docker安装=================
# 首先配置一下 docker 的阿里 yum 源
cat >/etc/yum.repos.d/docker.repo<<EOF
[docker-ce-edge]
name=Docker CE Edge - \$basearch
baseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edge
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
EOF
# yum 安装
yum -y install docker-ce
# 查看 docker 版本
docker --version
# 配置 docker 的镜像源【阿里云】
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
systemctl start docker
systemctl enable docker
systemctl status docker
# 更改后记得重载一下
systemctl reload-daemon
systemctl restart docker
# ====================安装 kubeadm,kubelet 和 kubectl==============
# 配置 kubernetes 阿里云 yum 源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# yum 方式安装,由于版本更新频繁,这里指定版本号部署
# 查看版本
yum list kubeadm --showduplicates
# 安装 kubelet、kubeadm、kubectl,同时指定版本
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
# 设置开机启动【这里先不启动】
systemctl enable kubelet
3.3 配置高可用 VIP【haproxy+keepalived】
# 【k8smaster1 + k8smaster2 上操作】
# 安装 haproxy + keepalived
# 我们需要在所有的 master 节点【k8smaster1 和 k8smaster2】上部署 haproxy + keepAlive
yum install -y haproxy keepalived
# 配置 haproxy
# 所有master节点的haproxy配置相同,haproxy 的配置文件是/etc/haproxy/haproxy.cfg
# 配置中声明了后端代理的两个 master 节点服务器,指定了 haproxy 运行的端口为 16443 等,因此 16443 端口为集群的入口
# 注意下面ip的更改
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server k8smaster1 192.168.249.146:6443 check
server k8smaster2 192.168.249.147:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:10080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /admin?stats
EOF
配置 keepalived,keepalived中使用track_script机制来配置脚本进行探测kubernetes的master节点是否宕机,并以此切换节点实现高可用,配置文件所在的位置/etc/keepalived/keepalived.cfg
需要注意几点(前两点记得修改):
mcast_src_ip:配置多播源地址,此地址是当前主机的 ip 地址。priority:keepalived根据此项参数的大小仲裁master节点。我们这里让 master 节点为kubernetes提供服务,其他两个节点暂时为备用节点。因此k8smaster1节点设置为100,k8smaster2节点设置为99。state:我们将k8smaster1节点的state字段设置为MASTER,其他节点字段修改为BACKUP。- 上面的集群检查功能是关闭的,等到集群建立完成后再开启。
# k8smaster1节点的keepalived配置文件,虚拟ip是vip地址
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens33
mcast_src_ip 192.168.249.146
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.249.139
}
track_script {
check_haproxy
}
}
EOF
# 配置 k8smaster2 节点,注意换
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id k8s
}
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
mcast_src_ip 192.168.249.147
virtual_router_id 51
priority 99
advert_int 1
authentication {
auth_type PASS
auth_pass ceb1b3ec013d66163d6ab
}
virtual_ipaddress {
192.168.249.139
}
track_script {
check_haproxy
}
}
EOF
启动和检查 【k8smaster1 和 k8smaster2 均要启动】
# 启动 haproxy
systemctl start haproxy
systemctl enable haproxy
systemctl status haproxy
# 启动 keepalived
systemctl start keepalived.service
systemctl enable keepalived.service
systemctl status keepalived.service
# 启动后查看 master 网卡信息
ip a s ens33
# 检查是否可以 ping 通
ping 192.168.249.139
# 如果出错
# 初始化一下!!!并重新启动!!!
systemctl stop firewalld
setenforce 0
swapoff -a
3.4 部署 Kubernetes Master 组件
# 首先在master1结点操作
# 导出初始化配置文件,然后修改配置,再进行初始化
kubeadm config print init-defaults > kubeadm-init.yaml
# 这里直接写入配置,并初始化
cat > kubeadm-init.yaml << EOF
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.249.139 # k8sLoadBalancer ip
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8sloadbalancer
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer: # 添加两行配置
certSANs:
- "192.168.249.139" # k8sLoadBalancer ip 即 VIP 的地址
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers # 阿里云的镜像站点
controlPlaneEndpoint: "192.168.249.139:16443" # VIP 的地址和端口
kind: ClusterConfiguration
kubernetesVersion: v1.18.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 # 添加 pod 网段
scheduler: {}
EOF
# 直接 kubeadm init 初始化,中间会拉取镜像,速度较慢,分为两步来做
# (1)提前拉取镜像
kubeadm config images pull --config kubeadm-init.yaml
# (2)初始化
kubeadm init --config kubeadm-init.yaml --upload-certs
# 执行下方命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 查看节点
kubectl get nodes
# 查看 pod
kubectl get pods -n kube-system
# 按照k8smaster1提示信息,将k8smaster2加入集群
kubeadm join 192.168.249.139:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:b828e96d32b7c4adef8f6cd34392c5c519e133d57dc51e82d61c64e95add41c8 \
--control-plane --certificate-key b52333ccc3d38d166e9aab487412ea8f2bf26430efa45306a3d803d16793bf19
# 查看集群状态
kubectl get cs
# 查看 pod
kubectl get pods -n kube-system
# 默认 token 有效期为 24 小时,当过期之后,该 token 就不可用了。这时就需要重新创建 token
kubeadm token create --print-join-command
# 按照k8smaster1提示信息,将k8snode1加入集群
kubeadm join 192.168.249.139:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d0ad912a5ac6e5c5a1471f5931bee86bf4b077b5c377cca008ec86e280492ba8
3.5 安装集群网络
# 下载 yaml 文件
wget -c https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 安装 flannel 网络
kubectl apply -f kube-flannel.yml
# 这里可能会出错,拉取镜像出错,如果出错需要手动将出错的镜像导入,并将其tag为指定标签,详情见上面集群安装
# 或者将docker.io/rancher/mirrored-flannelcni-flannel:v0.20.1(两个地方)替换成registry.cn-hangzhou.aliyuncs.com/shawn222/flannel:v0.20.1
# 查看状态 【kube-system 是 k8s 中的最小单元】
# 检查
kubectl get pods -n kube-system
watch kubectl get pods -A
3.6 测试 kubernetes 集群
# 创建 nginx deployment
kubectl create deployment nginx --image=nginx
# 暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
# 查看状态
kubectl get pod,svc
## [ip:port] 通过任何一个节点,都能够访问我们的 nginx 页面
# 浏览器访问:
# http://192.168.249.139:30965/
# http://192.168.249.146:30965/
# http://192.168.249.147:30965/
# http://192.168.249.148:30965/
# 注意如果要进行容灾演练,需要3台以上主节点
# 手把手从零搭建 k8s 集群系列(三)高可用(灾备)切换
七、在集群环境中部署项目
1、容器交付流程
- 开发代码阶段
- 编写代码
- 编写 Dockerfile【打镜像做准备】
- 持续交付/集成
- 代码编译打包
- 制作镜像
- 上传镜像仓库
- 应用部署
- 环境准备
- Pod
- Service
- Ingress
- 运维
- 监控
- 故障排查
- 应用升级
2、k8s 部署 java 项目流程
- 制作镜像【Dockerfile】
- 上传到镜像仓库【Dockerhub、阿里云、网易】
- 控制器部署镜像【Deployment】
- 对外暴露应用【Service、Ingress】
- 运维【监控、升级】
3、k8s 部署 Java 项目
3.1 制作镜像
这里已经制作好了一个 jar 包,名字为demojenkins.jar,然后上传并编写vim Dockerfile
FROM openjdk:8-jdk-alpine
VOLUME /tmp
ADD ./demojenkins.jar demojenkins.jar
ENTRYPOINT ["java","-jar","/demojenkins.jar", "&"]
打包与测试
docker build -t java-demo-01:latest .
docker run -d -p 8111:8111 java-demo-01:latest -t
# 打开浏览器进行访问
# http://192.168.249.139:8111/user
3.2 上传镜像仓库
镜像仓库可以选择云服务等,这里选择本地仓库地址进行测试,可以参考:docker学习笔记
## 搭建私人仓库
mkdir -p /data/myregistry
docker pull registry:latest
docker run -d -p 5000:5000 --name my_registry --restart=always -v /data/myregistry:/var/lib/registry registry:latest
## 更改 docker 配置文件(在需要连接到私有仓库的机器上全部都执行一遍)
## 在 k8smaster k8snode1 k8snode2 上均执行一遍
# 注意修改自己的ip
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"],
"insecure-registries": ["192.168.249.139:5000"]
}
EOF
## 重启 docker,重启 registry(如果停止了的话)
systemctl restart docker # 3 台机器上执行
docker start my_registry # 主节点上执行(因为私人仓库在主节点上)
# 访问:ip:5000/v2/_catalog查看本地仓库镜像
#http://192.168.249.139:5000/v2/_catalog
docker tag java-demo-01 192.168.249.139:5000/test/java-demo-01:v1
docker push 192.168.249.139:5000/test/java-demo-01:v1
# 可以在其他结点进行拉取测试
docker pull 192.168.249.139:5000/test/java-demo-01:v1
# ip可以用域名等代替,该方法使用云服务也一样的道理
3.3 部署项目
# 如果时私有仓库注意添加docker源
kubectl create deployment java01 --image=192.168.249.139:5000/test/java-demo-01:v1 --dry-run -o yaml > java01.yaml
kubectl apply -f java01.yaml
kubectl get pod -o wide
# 暴露端口
kubectl expose deployment java01 --port=8111 --target-port=8111 --type=NodePort
# 扩容
kubectl scale deployment javademo1 --replicas=3
## 查看暴露的端口
kubectl get svc
参考:
https://www.bilibili.com/video/BV1GT4y1A756
https://gitee.com/moxi159753/LearningNotes/tree/master/K8S
https://www.kubernetes.org.cn/k8s