【每日力扣41】计数质数
一、题目[LeetCode-204]
统计所有小于非负整数 n 的质数的数量。
示例 1:
输入:n = 10
输出:4
解释:小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。
示例 2:
输入:n = 0
输出:0
示例 3:
输入:n = 1
输出:0
提示:
- 0 <= n <= 5 * 10^6
二、思路
方法一:暴力法(两层嵌套for循环,一层计数O(n),一层判断O(√n))
编写子方法isPrime()用于判断对于一个数n其是否为质数。先写出边界条件,n==0,n==1,为false;n==2时为true。对于n>2的n,只要满足从2~ √n的任何数都不能整除n,即为质数,返回true;否则存在2~ √n的某个数能够整除n,则n是合数,返回false。这里用一个for循环实现。时间复杂度为O(√n)。
然后再母方法countPrimes()中,使用for循环判断0~n-1的数中有多少数是质数。因此调用n次isPrime()即可。总时间复杂度为O(n^(3/2))。
class Solution {
public:
int countPrimes(int n) {
int count = 0;
for(int i = 0; i < n; i++)
if(isPrime(i))
count++;
return count;
}
bool isPrime(int n){
if(n == 0 || n == 1)
return false;
if(n == 2)
return true;
for(int i = 2; i <= sqrt(n); i++)
{
if(n % i == 0)
return false;
}
return true;
}
};因时间复杂度为O(n^(3/2)),对于n=5000000的测试用例用时过大,因此运行超时。
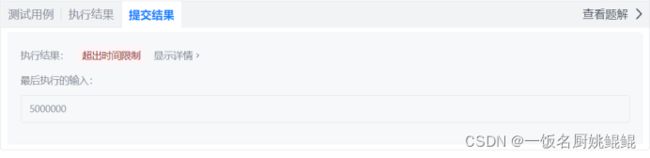
方法二:数组表出法
对于传统的嵌套循环,难以逃脱时间复杂度的桎梏。这里则可采用一个数组用于存储表示对应下标n“是否为质数”的bool值,用O(n)的空间复杂度换取更优化的时间复杂度。
我们使用bool数组表示出对于每个下标i(i∈[0, n-1]),i是否为质数。创建一个数组vector
接下来我们再使用一个O(n)的for循环求得isPrime[]中所有为true的数的个数即可。
class Solution {
public:
int countPrimes(int n) {
if(n < 3)//没有质数的边界情况
return 0;
vector isPrime(n, true);
isPrime[0] = false; isPrime[1] = false;//初始化一个bool数组,用于存储对应的下标值是否为质数
for(int i = 2; i * i < n; i++)//对于从0~√(n-1)的数i,因为其倍数都是合数,所以只要将其倍数对应的isPrime[i*x]置为false即可得到正确的isPrime[]数组
{
if(isPrime[i])//优化1:只需要讨论i是质数的情况。因为i如果是合数,则其所有倍数的情况早已被合数i之前的质数(i的除1外的最小因数)处理
{
for(int x = i; i * x < n; x++)//优化2:i所乘倍数x只需从i计起,不需要从2开始自增。因为x取2~i的某一值得情况早已被先前i取该某值时与现在的i相乘处理。可以认为优化原理是乘法交换律。
isPrime[i * x] = false;//质数i的x倍数都是合数,因此将对应的isPrime[i]改为false.
}
}
int count = 0;
for(int i = 0; i < n; i++)
if(isPrime[i])
count++;//遍历出isPrime[]中true值的数量即为答案
return count;
}
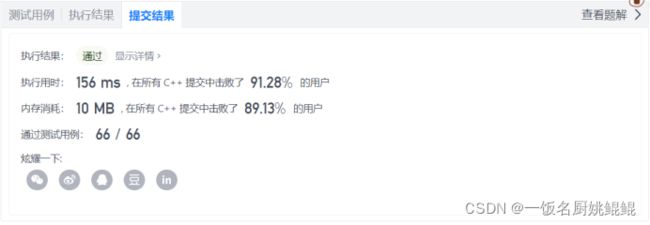
}; 
三、官方题解(来源:力扣(LeetCode))
方法一:枚举(同上文方法一)
很直观的思路是我们枚举每个数判断其是不是质数。
考虑质数的定义:在大于 1 的自然数中,除了 1 和它本身以外不再有其他因数的自然数。因此对于每个数 x,我们可以从小到大枚举 [2,x−1] 中的每个数 y,判断 y 是否为 x 的因数。但这样判断一个数是否为质数的时间复杂度最差情况下会到 O(n),无法通过所有测试数据。
考虑到如果 y 是 x 的因数,那么 x/y也必然是 x 的因数,因此我们只要校验 y 或者 x/y 即可。而如果我们每次选择校验两者中的较小数,则不难发现较小数一定落在 [2, √x] 的区间中,因此我们只需要枚举 [2, √x] 中的所有数即可,这样单次检查的时间复杂度从 O(n) 降低至了 O(√n)。
class Solution {
public:
bool isPrime(int x) {
for (int i = 2; i * i <= x; ++i) {
if (x % i == 0) {
return false;
}
}
return true;
}
int countPrimes(int n) {
int ans = 0;
for (int i = 2; i < n; ++i) {
ans += isPrime(i);
}
return ans;
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/count-primes/solution/ji-shu-zhi-shu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。复杂度分析
- 时间复杂度:O(n√n)。单个数检查的时间复杂度为 O(√n),一共要检查 O(n) 个数,因此总时间复杂度为 O(n√n)。
- 空间复杂度:O(1)。
方法二:埃氏筛(类似上文方法二)
枚举没有考虑到数与数的关联性,因此难以再继续优化时间复杂度。接下来我们介绍一个常见的算法,该算法由希腊数学家厄拉多塞(Eratosthenes)提出,称为厄拉多塞筛法,简称埃氏筛。
我们考虑这样一个事实:如果 x 是质数,那么大于 x 的 x 的倍数 2x,3x,… 一定不是质数,因此我们可以从这里入手。
我们设 isPrime[i] 表示数 i 是不是质数,如果是质数则为 1,否则为 0。从小到大遍历每个数,如果这个数为质数,则将其所有的倍数都标记为合数(除了该质数本身),即 0,这样在运行结束的时候我们即能知道质数的个数。
这种方法的正确性是比较显然的:这种方法显然不会将质数标记成合数;另一方面,当从小到大遍历到数 x 时,倘若它是合数,则它一定是某个小于 x 的质数 y 的整数倍,故根据此方法的步骤,我们在遍历到 y 时,就一定会在此时将 x 标记为 isPrime[x]=0。因此,这种方法也不会将合数标记为质数。
当然这里还可以继续优化,对于一个质数 x,如果按上文说的我们从 2x 开始标记其实是冗余的,应该直接从 x⋅x 开始标记,因为 2x,3x,… 这些数一定在 x 之前就被其他数的倍数标记过了,例如 2 的所有倍数,3 的所有倍数等。
class Solution {
public:
int countPrimes(int n) {
vector isPrime(n, 1);
int ans = 0;
for (int i = 2; i < n; ++i) {
if (isPrime[i]) {
ans += 1;
if ((long long)i * i < n) {
for (int j = i * i; j < n; j += i) {
isPrime[j] = 0;
}
}
}
}
return ans;
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/count-primes/solution/ji-shu-zhi-shu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 复杂度分析
- 时间复杂度:O(nloglogn)。具体证明这里不再展开,读者可以自行思考或者上网搜索。
- 空间复杂度:O(n)。我们需要 O(n) 的空间记录每个数是否为质数。
方法三:线性筛
此方法不属于面试范围范畴,本节只做简单讲解。
class Solution {
public:
int countPrimes(int n) {
vector primes;
vector isPrime(n, 1);
for (int i = 2; i < n; ++i) {
if (isPrime[i]) {
primes.push_back(i);
}
for (int j = 0; j < primes.size() && i * primes[j] < n; ++j) {
isPrime[i * primes[j]] = 0;
if (i % primes[j] == 0) {
break;
}
}
}
return primes.size();
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/count-primes/solution/ji-shu-zhi-shu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 复杂度分析
- 时间复杂度:O(n)。
- 空间复杂度:O(n)。
四、学习心得
①埃氏筛算法求解质数的判断
②线性筛算法求解质数的判断