ESimCSE 论文笔记
单位:中国科学院信息工程研究所,中国科学院大学,快手科技
时间:2022.09
发表:COLING
论文链接: https://arxiv.org/abs/2109.04380
一、前言
1. ESimCSE想做些什么?
SimCSE 采用两次 dropout 作为一对正样本来当作数据增强的方法(详细内容可见我的上一篇笔记),但这样有一个不好的地方就是模型会偏向认为具有相同长度的句子彼此之间就更为相似。
为了验证这一观点,作者根据句子对的长度差异是否≤3,将每个STS测试集划分为两组,计算每组的模型预测和正则化标准答案之间的相似度差异。结果如表所示,当长度差≤3时,七个数据集的平均相似性差异较大,这验证了作者的假设。

让我比较奇怪的是下面的 ESimCSE ,虽然两者的差距是缩小了,但相似性差异都比 SimCSE 差异大是怎么回事。
2. ESimCSE做到了什么?
为了缓解上述的问题,作者应用一个简单而有效的重复操作来修改输入句子,然后将输入的句子及其修改后的对应句子分别传递给预先训练好的 Transformer 编码器,彼此间作为正样本。此外,还从计算机视觉领域获得灵感,引入了动量对比来增加负数对的数量,而不需要进行额外的计算。
实验结果表明,ESimCSE 无监督方法在 BERT-base 上的平均 Spearman 相关度超过了 SimCSE 2.02%。

二、ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
1. 方法
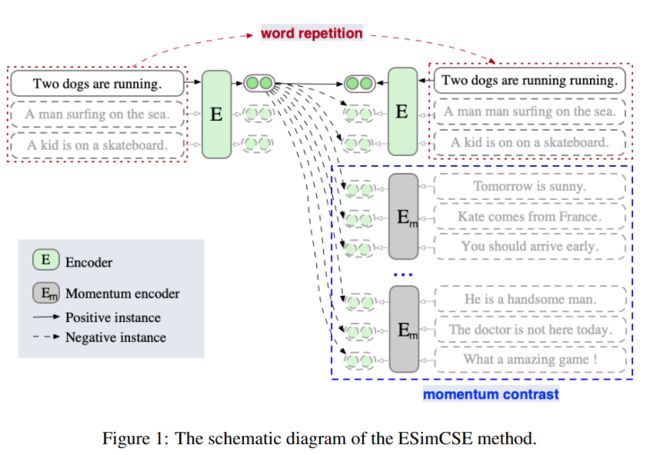
1.1 正样例
对于每个正样例,作者希望在不改变其语义的情况下改变一个句子的长度。现有的改变句子长度的方法通常使用随机插入和随机删除。然而,在一个句子中插入随机选择的词可能会引入额外的噪音,这可能会扭曲句子的含义;从一个句子中删除关键词也会大大改变其语义。
所以作者提出一种将 "单词重复" 作为构造正样例的方法,就是随机地将句子中的一些单词重复起来,如表所示。

重复的子词/单词数量按如下公式随机选取。其中 dup_rate 是个超参数。
dup_len ∈ [0, max(2, int(dup_rate ∗ N )]
在确定了 dup_len 之后,再用均匀分布从序列中随机选择需要重复的 dup_len 子词,组成 dup_set,如下所示
dup_set = uniform([1, N ], num = dup_len)
1.2 负样例
由于对比学习是在正对和负对之间进行的,从理论上讲,更多的负对可以导致对之间更好的比较。因此,一个潜在的优化方向是利用更多的负面配对,鼓励模型进行更精细的学习。然而,更大的批次规模并不总是一个更好的选择。例如,对于SimCSE BERT-base模型,最佳 batch_size 是64,其他的 batch_size 设置会降低性能。
于是作者引入动量对比方法,该方法首先用于 CV 领域中。动量对比允许我们通过维护一个队列,重新使用紧接着的小批中的编码嵌入,以排除负数对。它总是排队等候当前小批的句子嵌入,同时将 "最旧 "的句子嵌入取消。由于排队的句子嵌入来自前面的小批,我们通过取其参数的移动平均值来保持一个动量更新的编码器,并使用动量编码器来生成排队的句子嵌入。
请注意,在使用动量编码器时,作者关闭了dropout,这可以缩小训练和预测之间的差距。
将编码器的参数表示为θe,将动量更新的编码器的参数表示为θm,以下列方式更新θm。其中 λ ∈ [0, 1) 是动量系数参数。
$$ θm ← λθm + (1 − λ)θe $$
在上式中只有参数 θe 通过反向传播更新。这里引入 θm 来为队列生成句子嵌入,因为动量更新可以使 θm 比 θe 进化得更平滑。因此,尽管队列中的句向量是由不同的编码器(在训练期间的不同 steps)编码的,但这些编码器之间的差异可以变得很小。
1.3 损失函数
在了解了正样例和负样例是怎么生成的后,ESimCSE的总损失函数便如下。

其中 $h^{+}_{m}$ 表示在动量更新的队列中的句向量,M是队列的大小。
2. 实验
作者使用 bert 的 cls 向量之上加一层 MLP 当作该句句向量。batch_size = 64。对于 bert-base 学习率是3e-5,其它模型是1e-5。base 模型的 dropout 率为0.1,large 模型为0.15。
单词重复的温度超参数 τ=0.05,dup_rate 经过消融实验定为0.32。动量对比的 λ=0.995,队列大小经过消融实验定为batch_sieze的2.5倍。
对比实验见图2。作者还做了消融实验验证优化的两个方法的有效性,实验结果如下图所示。
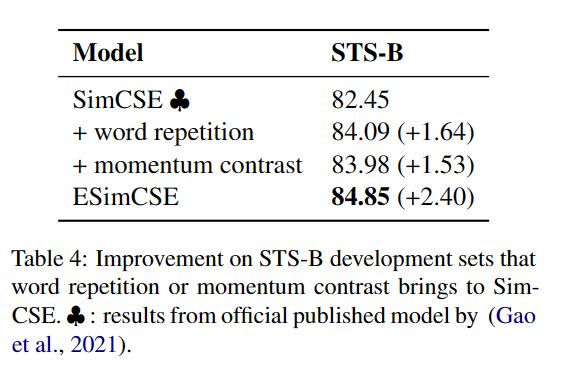
结果表明所提出的两种增强正对和负对的方法都是有效的。且这两种修改可以叠加在一起(ESimCSE)以获得进一步的改进。
作者还做了不同改变句子长度的数据增强方法,结果如下图所示。

三、总结
在本文中,作者提出了为 SimCSE 构建正负对的优化方案,并将其与 SimCSE 结合起来,这就是ESimCSE。通过广泛的实验,所提出的 ESimCSE 在标准的语义文本相似性任务上比 SimCSE 取得了相当大的改进。
四、值得思考的地方
1. 正样例构造方法
又是出人意料的,将单词简单重复比之前直觉想到其它数据增强方法都要好,其实在单词重复的数据增强方法也同时使用了不同的dropout mask率来编码两个正例句子,真的可谓是增强的SimCSE。
单词简单重复比用mask生成新的单词都要更好,这有些不符合直觉,一个新的好 IDEA 也有可能是不那么符合直觉的,但无头脑的反复试错又回到炼丹的过程也不可取,只能像作者这样,先有个大方向(要改变句子长度),再从中反复实验。
2. 负样例构造方法
这里最难理解的点便是为什么增大 batch_size 以提供更多负例效果变差,而使用一个缓慢更新的动量对比编码器维持一个队列以作为负例就能有很大提升,因为原出处 MoCo 提出这个动量对比仅仅也只是为了能在显存有限的情况下提供更多的负例,也并不涉及可以提升性能,作者也没有解释。
首先我们来分析下为什么两个不同的编码器编码出来的向量能相互做负例,其中一个细节是作者在 CLS 向量后接了一个 MLP 才得到最终的句向量,这点和 MoCo v2 的做法一致,即通过 MLP 转换到相同或者说极其相似的向量空间中,所以才能 work。
至于为什么能比增大 batch_size 效果好这么多,我目前还没想到有说服力的想法,后面多阅读后再多想吧。