漫谈自动驾驶-自动驾驶最新的技术栈有哪些,一文讲清楚
目录
1 简介
2 简要介绍
2.1 自动化水平
2.2 硬件
2.3 软件
3 感知
4 轨迹预测
5 建图
6 定位
7 规划
8 控制
9 V2X
10 仿真
11 安全性
12 数据闭环
12.1 数据选择
12.2 数据标注
12.3 主动学习
13 结论
13.1 ChatGPT 和 SOTA 大模型
13.2 大模型在自动驾驶系统中的应用
1 简介
10多年来,自动驾驶一直是一个热门话题。2004年和2005年,DARPA举办了乡村无人车大赛。2007年,DARPA还举办了城市环境中的自动驾驶大赛。之后,斯坦福大学的S.Thrun教授(2005年冠军和2007年亚军)加入谷歌,建立了Google X和自动驾驶团队。
最近有三篇关于自动驾驶的调查报告[3,9,14]。自动驾驶作为机器学习和计算机视觉等人工智能领域最具挑战性的应用之一,已经被证明是一个"长尾"问题,即少量类别占据了绝大多少样本,而大量的类别仅有少量的样本。在本文中,我们研究了如何在数据闭环中研发自动驾驶技术。我们的综述工作涵盖了自动驾驶技术主要领域,包括:感知、建图和定位、预测、规划和控制、仿真、V2X和安全等。
最后,我们将讨论新兴大模型对自动驾驶行业的影响。
2 简要介绍
目前存在的一些关于自动驾驶技术的综述文章,包含整个系统/平台到单个模块/功能[1-2,4-8,10-13,15-33]。在本节中,我们简要介绍图1所示的基本自动驾驶功能和模块,硬件和软件体系结构,包括:感知、预测、定位和建图、规划、控制、安全、仿真以及V2X等。
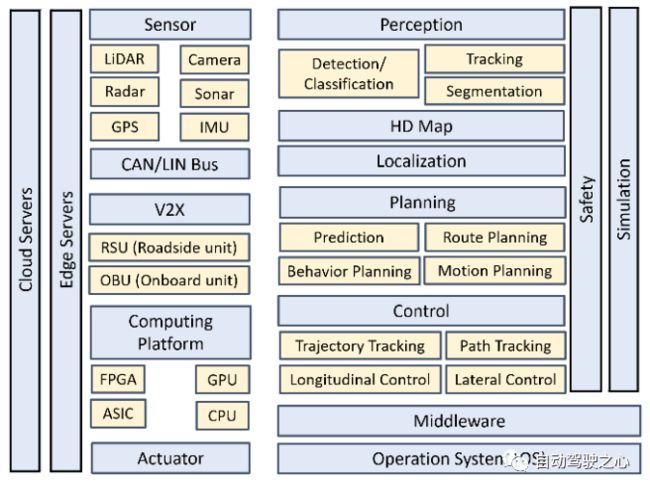
图 1 自动驾驶平台的硬件和软件
2.1 自动化水平
美国运输部和国家公路交通安全管理局(NHTSA)采用了国际标准化组织汽车工程师学会(SAE)制定的自动化水平标准,该标准将自动驾驶车辆自动化分为6个等级,即从0级(人工驾驶员完全控制)到5级(车辆完全自主驾驶)。
在1级中,驾驶员和自动化系统共同控制车辆。在2级中,自动化系统完全控制车辆,但驾驶员必须时刻准备好立即干预。在3级中,驾驶员可以免于驾驶任务,车辆将要求立即响应,因此驾驶员仍须随时准备干预。在4级中,与3级相同,但不需要驾驶员保持注意力来确保安全,驾驶员可以安全地睡觉或离开驾驶员座位。
2.2 硬件
自动驾驶车辆测试平台应该能够实现实时通信,例如使用控制器区域网络(CAN)总线和以太网,可以准确地实现车辆的方向、油门和制动器的实时控制。进行车辆传感器合理配置,以满足环境感知的可靠性要求,并最大限度降低生产成本。
自动驾驶车辆的感知可以分为三大类:本体感知、定位和环境感知。本体感知:通过车辆的传感器测量当前车辆状态,即横摆速率、速度、偏航角等。本体感知的传感器包括行程计、惯性测量单元(IMU)、陀螺仪和CAN总线。定位:使用外部传感器(如全球定位系统(GPS))或IMU读数的里程计来确定车辆的全局和局部位置。环境感知:使用外部感测器来感知车道标线、道路坡度、交通信号牌、天气条件和障碍物等。
本体感知传感器和环境感知传感器分为主动传感器和被动传感器。主动传感器以电磁波的形式发出能量,并测量返回时间以确定距离等参数,例如声纳、雷达和光探测与测距(LiDAR)传感器。被动传感器不发出信号,而是感知环境中已经存在的电磁波(例如基于光的和红外相机)。
另一个重要方面是计算平台,它支持传感器数据处理以识别周围环境,并通过密集优化算法、计算机视觉算法和机器学习算法来实时控制车辆。目前存在不同的计算平台,如CPU、GPU、ASIC和FPGA等。为了支持基于AI的自动驾驶,也需要云服务器来提供大数据服务,例如进行大规模机器学习和大容量数据存储(例如高清地图)。为了实现车路协同,还需要处理车端信息的路侧通信设备和计算设备。图2显示了一辆自动驾驶汽车中的传感器配置示例(来自公开数据集NuScene)。它安装了LiDAR、相机、雷达、GPS和IMU等。

图 2 自动驾驶传感器硬件示例
如果需要收集多模态传感器数据,还需要进行传感器校准,其中涉及确定每个传感器数据之间的坐标系统关系,例如相机校准、相机-LiDAR校准、LiDAR-IMU校准以及相机-雷达校准。此外,传感器之间需要使用统一的时钟(例如GNSS),然后使用某个信号触发传感器的操作。例如,LiDAR的传输信号可以触发相机的曝光时间,实现时间同步。
2.3 软件
自动驾驶系统的软件平台分为4个层次,从底层到顶层分别为:实时操作系统(RTOS)、中间件、功能软件和应用软件。软件体系结构分为:模块化结构和端到端结构。
模块化系统由多个构件组成,连接感知输入到执行器输出。模块化自动驾驶系统(ADS)的关键功能通常分为:感知、定位和绘图、预测、规划和决策以及车辆控制等。
端到端系统直接从传感器输入生成控制信号。控制信号主要来自转向轮和油门(加速器),用于加速/减速(甚至停止)和左/右转弯。端到端驾驶主要包括三种方式:直接监督深度学习、神经进化和深度强化学习。

图 3 显示了端到端和模块化系统的体系结构
"感知"系统通过传感器收集信息并从环境中提取有效信息。它能对驾驶环境进行上下文理解,如检测、跟踪和分割障碍物、道路标志/标线和空旷的可驾驶区域。根据所采用的传感器,环境感知任务主要通过使用LiDAR、相机、雷达或多传感器融合来完成。在最高层次上,感知方法可以分为三类:中介感知、行为反射感知和直接感知。中介感知需要绘制车辆、行人、树木、车道标记等周围环境的详细地图。行为反射感知将传感器数据(图像、点云、GPS位置)直接映射到驾驶机动操作。直接感知将行为反射感知与中介感知方法的度量获取相结合。
"建图"是指建立包含道路、车道、标志/标线和交通规则等信息的地图。一般来说,有两种主要类型的地图:平面地图,指依赖地理信息系统(GIS)上的图层或平面绘制的地图;点云地图,指基于GIS中的数据点集的地图。高清(HD)地图包含自动驾驶所需的有用的静态元素,如车道、建筑、交通灯和车道标记等。HD地图与车辆定位功能紧密相连,并与车辆传感器(如LiDAR、雷达和相机)保持交互,从而构建自动驾驶系统的感知模块。
"定位"确定车辆相对于驾驶环境的位置。全球导航卫星系统(GNSS)如GPS、GLONASS、北斗和伽利略等,他们使用不少于四颗卫星并以相对较低的成本估计车辆的全球位置。全球导航卫星系统可以使用差分模式来提高GNSS的精度。GNSS通常与IMU集成来设计性价比高的车辆定位系统。IMU用于估计车辆相与其初始位置的相对位置,这种方法称为里程计。由于HD地图已经用于自动驾驶,基于HD地图的定位也被考虑在内。最近,出现了许多自主的里程计方法和同时定位与建图方法(SLAM)。SLAM技术通常应用一个里程计算法来获得当前姿态信息,然后将其送到一个全局地图优化算法中。基于图像的计算机视觉算法包括:特征提取和匹配、相机运动估计、三维重建(三角测量)和优化(约束调整)等,由于这些算法的缺点,目前视觉SLAM仍然是一个具有挑战性的方向。
"预测"是指根据障碍物的运动学、行为和长短期历史估计其轨迹。要完全解决轨迹预测问题,社会智能化非常重要。因为智能化的社会环境中,各种可能性被约束,无限的搜索空间也被约束。为了建立社会互动模型,我们需要了解智能体及其周围环境的动态,以预测其未来的行为,防止发生任何碰撞。
"规划"是生成一条避障的参考路径或轨迹,使车辆在避开障碍物的同时到达目的地。规划可以分为不同的等级:路线(任务)规划、行为规划和运动规划。路径规划是指在有向图中寻找点到点的最短路径,传统方法分为目标导向技术、基于分离器的技术、分层技术和有界跳技术四类。行为规划决定了局部驾驶任务,该任务使车辆向目的地前进并遵守交通规则,传统上由有限状态机(FSM)定义。最近正在研究模仿学习和强化学习,以生成车辆所需的行为。运动规划在环境中选择一条连续路径,以完成局部驱动任务,例如RRT(快速探索随机树)和Lattice规划。
"控制"是通过选择适当的执行器输入来执行规划的动作。通常控制可分为横向控制和纵向控制。大部分情况下,可以将控制解耦为两阶段,即轨迹/路径生成阶段和跟踪阶段,例如纯跟踪法。然而,它也可以同时生成轨迹/路径并进行跟踪。
"V2X(车联网)"是一种能够使车辆能够与周围的车流和环境进行通信的车辆技术系统,包括:车辆间通信(V2V)和车辆基础设施通信(V2I)。从行人的移动设备到交通灯上的固定传感器,车辆可以通过V2X访问大量数据。通过积累来自其他车辆的详细信息,将克服单车智能的感知范围、盲区和规划不足等缺点。V2X有助于提高安全性和交通效率,但车辆之间和车路之间的协同仍然具有挑战性。
值得一提的是,ISO(国际标准化组织)26262标准适用于自动驾驶车辆,它定义了一套全面的要求,以确保车辆软件开发的"安全"。该标准建议使用危险分析和风险评估(HARA)方法来识别危险事件,并确定了减轻危险的安全目标。车辆安全完整性级别(ASIL)是ISO 26262中定义的车辆系统风险分类方案。AI系统带来了更多安全问题,这些问题由一个新建立的标准ISO/PAS 21448 SOTIF(预期功能的安全性)来解决。
除了模块化或端到端系统,ADS开发中还有一个重要的"仿真"平台。由于在道路上驾驶实验车辆的成本很高,而且在现有的人类驾驶的道路网络上进行实验,会受到限制,因此仿真环境可以实现在实际道路测试之前开发某些算法/模块。仿真系统由以下核心部分组成:传感器模型(相机、雷达、LiDAR和声纳)、车辆动力学和运动学、行人、驾车者和骑车者的形状和运动学模型、路网和交通网络、三维虚拟环境(城市和乡村场景)以及驾驶行为模型(年龄、文化、种族等)。仿真平台存在的关键问题是"sim2real"和"real2sim",前者是指如何模拟真实场景,后者是指如何以数字孪生的方式进行情景再现。
3 感知
感知周围环境并提取信息是自动驾驶的关键任务。使用不同传感模式的各种任务都属于感知范畴[5-6,25,29,32,36]。基于计算机视觉技术,相机成为使用最广泛的传感器,3D视觉则成为一个强大的替代方案/补充。
最近,BEV(鸟瞰视角)感知[25,29]成为自动驾驶中最活跃的感知方向之一,特别是在基于视觉的系统中。主要原因有以下两点:首先,BEV对驾驶场景的表示可以直接由下游模块应用,如轨迹预测和运动规划等。其次,BEV提供了一种可解释的方式来融合来自不同视角、模式、时间序列和智能体的信息。例如,其他常用传感器,如LiDAR和Radar在3D空间中获取的数据,可以轻松转换到BEV,并直接与相机直接进行传感器融合。
在调研报告[25]中,BEV工作可以分为以下几个类别,如图4所示。

图 4 BEV工作的类别
首先,根据视图变换方式可以分为基于几何的变换和基于网络的变换。基于几何的变换充分利用相机的物理原理进行视图转换,该方法可进一步分为经典的基于同图的方法(即逆投影映射)和基于深度的方法,通过显式或隐式深度估计可以将二维特征提升至三维特征。
根据深度信息的利用方式,我们可以将基于深度的方法分为两类:基于点的方法和基于体素的方法;基于点的方法直接利用深度估计将像素转换为点云,散布在连续的三维空间中;而基于体素的方法通常直接利用深度引导将二维特征(而不是点)散布在相应的三维位置上。
基于网络的方法可以采用自下而上的策略,即神经网络像视图投影仪一样发挥作用;另一种方法可以采用自上而下的策略,即直接构建BEV查询,并通过交叉注意力机制(基于Transformer)在前视图像上搜索相应的特征,提出稀疏、密集或混合查询以匹配不同的下游任务。
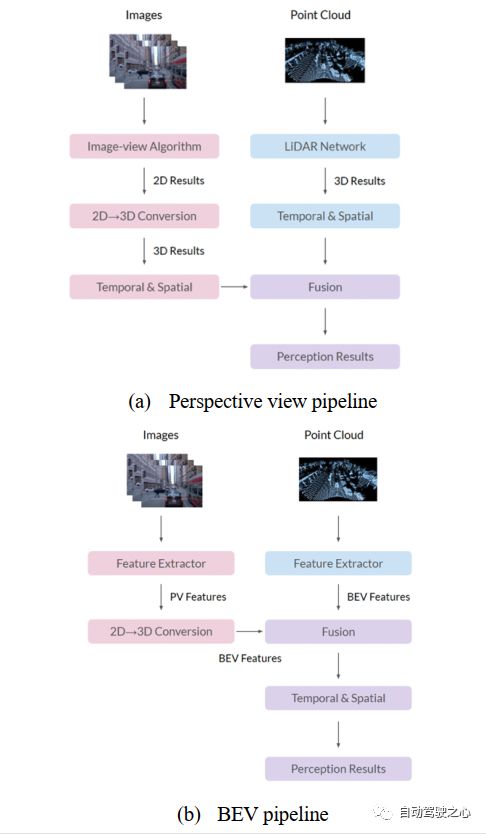
图 5 BEV方案
迄今为止,BEV网络已被用于物体检测、语义分割、在线映射、传感器融合和轨迹预测等。如研究论文[29]图5所示,BEV融合算法有两种典型的过程设计。两者主要区别在于2D到3D的转换和融合模块。在透视图方案(a)中,首先将不同算法的结果转换到三维空间,然后使用先验规则或人工方法进行融合。BEV方案(b)首先将透视图特征转换为BEV,然后融合特征以获得最终预测结果,从而保留大部分原始信息并避免人工设计。
继BEV之后,三维占位网络逐渐成为自动驾驶感知领域的前沿技术[32]。BEV可以简化驾驶场景的纵向几何,而三维体素能够以较低的分辨率表示完整的几何,包括道路地面和障碍物体积,这需要较高的计算成本。基于相机的方法正在三维占位网络中兴起。图像具有天然的像素密度,但是需要深度信息才能反向投射到三维占位中。注:对于LiDAR数据,占位网络实际上实现了语义场景补全(SSC)任务。
在图6中,我们解释了BEV和占用网络的三种模型体系结构,仅针对相机输入,仅针对LiDAR输入以及两者结合输入。
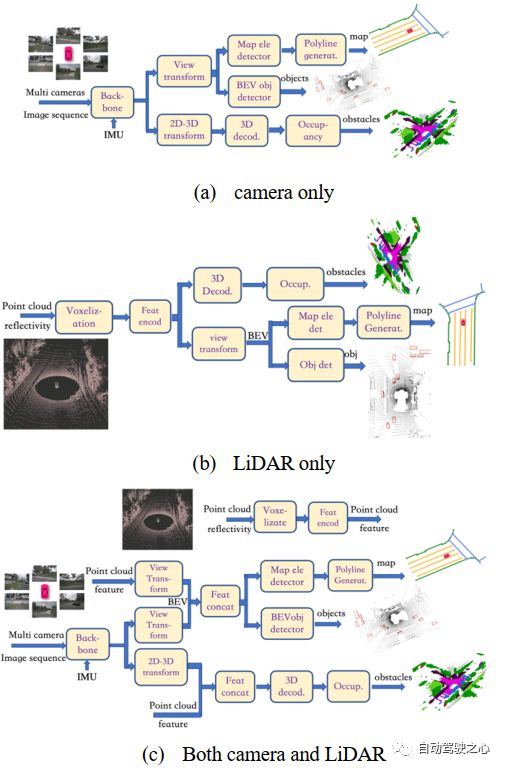
图 6 BEV和占位网络实例
仅多相机输入如图6(a)所示,多相机图像首先通过"Backbone"模块编码,如EfficientNetor/RegNet加上FPN/Bi-FPN,然后分为两路;一方面,图像特征进入"view transform"模块,通过深度分布或Transformer架构构建BEV特征,然后分别进入两个不同的头部:一个头通过"map ele detector"模块输出地图元素的矢量化表示(其结构类似于基于Transformer的DETR模型,也有一个可变形的关注模块,并输出关键点的位置和它们所属元素的ID)和"polyline generat"模块(它也是一个基于Transformer结构的模型,输入这些嵌入的关键点、多段线分布模型可以生成多段线的顶点并获得地图元素的几何表示),另一个头通过"BEV obj Detector"模块获得obj BEV边界框,它可以使用Transformer架构或类似的PointPillar架构来实现;另一方面,在"2D-3D transform"模块中,基于深度分布将二维特征编码投影到三维坐标,其中保留高度信息,得到的相机体素特征进入"3D decod."模块得到多尺度体素特征,然后进入"occupancy"模块进行类预测,生成体素语义分割。
仅LiDAR输入如图6(b)所示,部分模块与图6(a)相同。首先,在"Voxelization"模块中,将点云划分为间距均匀的体素网格,生成三维点与体素的多对一映射;然后进入"FeatEncod"模块,将体素网格转换为点云特征图(使用PointNet或PointPillar);一方面,在"view transform"模块中,将特征图投影到BEV上,在BEV空间中结合特征聚合器和特征编码器,然后进行BEV解码,分为两个头:一个头部的工作原理如图6(a)所示。另一方面,三维点云特征图可以直接进入"3D Decod"模块,通过三维解卷积获得多尺度体素特征,然后在"Occup"模块中进行上采样和类预测,生成体素语义分割。
相机和LiDAR同时输入如图6(c)所示,大多数模块与图6(a)和6(b)相同,除了"Feat concat"模块将连接来自LiDAR路径和相机路径的特征。
注:对于基于相机的占位网络,值得一提的是计算机图形学和计算机视觉领域的一种新范例--神经辐射场(NeRF)[47]。NeRF不是直接还原整个三维场景的几何图形,而是生成一种被称为"辐射场"的体积表示,它能够为相关三维空间中的每一点创建颜色和密度。
4 轨迹预测
为实现安全高效的导航,自动驾驶汽车应考虑周围其他智能体的未来轨迹。轨迹预测最近受到了广泛关注,这是一项极具挑战性的任务,它根据场景中所有运动的智能体的当前和过去状态预测其未来状态。
预测任务可分为两部分。第一部分是作为分类任务的"意图",它通常可被视为一个监督学习问题,我们需要标注智能体可能的意图。第二部分是需要预测智能体在未来N个帧中的一组可能位置的"轨迹",这个"轨迹"被称为"路径点"(way-points)。这建立了它们与其他智能体以及道路的交互。
文献[10,12,34]进行了一些预测相关的研究。传统上,我们将行为预测模型分为基于物理的模型、基于机动的模型和基于交互意识的模型。基于物理的模型由动态方程构成,为不同类别的智能体建立人工设计运动模型。基于机动的模型是基于智能体的预期运动类型的实际模型。交互感知模型通常是基于ML的系统,能够对场景中的每一个智能体进行配对推理,并为所有动态智能体生成交互感知预测。
图 7 L4创业公司Cruise.AI的预测模型
图7给出了L4自动驾驶创业公司Cruise.AI[36]设计的预测模型图。显然,它展示了一个编码器-解码器结构。在编码器中,有一个"场景编码器"来处理环境上下文(地图),类似于谷歌Waymo的ChauffeurNet(光栅化图像作为输入)或VectorNet(矢量化输入)架构一样;有一个"对象历史编码器"来处理智能体历史数据(位置);还有一个基于注意力图网络来捕捉智能体之间的联合交互。为了处理动态场景的变化,他们将专家混合(MoE)编码到门控网络中。例如,在停车场有不同的行为,如倒车驶出、驶出和K形转弯、平行停车第二次尝试、倒车和驶出、倒车平行停车和垂直驶出等。
在图7所示的解码器中,有一个两阶段的结构,即由一个简单的回归器生成初始轨迹,然后由具有"多模态不确定性"估计的长期预测器进行完善。为了增强轨迹预测器,还有一些辅助任务需要训练,如"联合轨迹不确定性"估计和"交互检测和不确定性"估计,以及"占位预测"。
该轨迹预测器的一个大创新是它的"自监督"机制。基于"后见之明"的观察,他们提供"机动自动标注器"和"交互自动标注器"为预测器模型生成大量训练数据。
5 建图
地图,特别是HD地图,是自动驾驶的先验知识。建图技术可以分类为在线建图和离线建图[24]。在离线建图中,我们在中心位置收集所有数据,这些数据采集来自安装有GNSS、IMU、LiDAR和相机的车辆。另一方面,在线建图使用轻量级模块在自动驾驶车辆上进行。
所有有前途的建图技术目前都使用LiDAR作为主要传感器,特别是用于HD地图。另一方面,也有一些方法只使用视觉传感器构建地图,如Mobileye的REM,或称为roadbook,它基于视觉SLAM和深度学习[35]。
创建HD地图通常涉及采集高质量的点云、对准同一场景的多个点云、标记地图元素以及频繁更新地图。这个过程需要大量人力和时间,限制了其可扩展性。BEV感知[25,29]具有在线学习地图的潜力,它根据局部传感器观察动态地构建高清地图,这可能是一种可以为自动驾驶汽车提供语义和先验几何信息的更具可扩展性的方式,。
在这里,我们介绍在线建图的最新工作,称为MachMap[45],它将高清地图构建公式化为BEV空间中的点检测范式,以端到端的方式。基于地图紧凑方案,它遵循基于查询的范式,集成了CNN基础架构(如InternImage),基于时间的实例解码器和点掩膜耦合头。

图 8 MachMap框架
MachMap的框架如图8所示。它通过图像骨干和周围图像的颈部从每个视图生成2D特征。然后,可变形注意力用于聚合不同视图之间的3D特征,并沿z轴对其进行平均。在时间融合模块中,新的BEV特征与BEV特征的隐藏状态进行融合。
利用实例级可变形注意力机制执行实例解码器可以完善内容和点特征并获得最终结果。
6 定位
自动驾驶车辆的精准定位可对下游任务(如行为规划)产生巨大的影响。虽然使用传统的动态传感器(如IMU和GPS)可以获得可接受的结果,但基于视觉的传感器(LiDAR或相机)显然更适合这项任务,因为使用这类传感器获得的定位结果同时依赖于车辆本身及其周围的环境。虽然这两种传感器都具有良好的定位性能,但它们也存在一些局限性[27]。
多年来,研究者一直在研究自动驾驶汽车定位,这大多数情况下是与建图一起进行的,这带来了两种不同的路线:第一种是SLAM,即定位和建图同时循环运行;第二种是将定位和建图分开,直接离线构建地图。
最近,深度学习为SLAM带来了新的数据驱动的方法,尤其是更具挑战性的视觉SLAM,这在论文[28]中有所提及。这里我们讨论一个基于Transformer定位方法的例子[48],其中获取姿势是通过所提出的POse Estimator Transformer(POET)模块使用注意机制与从跨模型特征中检索到的相关信息交互来更新的。定位架构如图9所示。
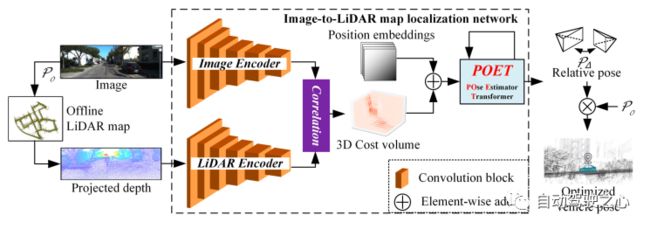
图 9 使用Transformers进行地图定位
如图9所示,该网络以RGB图像和LiDAR地图上给定初始姿态的相邻点云的重投影深度图像作为输入。然后,它们分别通过对应的编码器进行处理以获得高维特征。之后,进行图像特征和LiDAR特征融合,获得融合特征。之后,把位置信息添加到融合特征后,将融合特征输入到所提出的POET模块中。
POET将融合特征作为输入并初始化姿势信息。经过与融合特征相关信息的迭代更新,姿势信息可以被优化为图像与初始姿态之间高精度的相对姿态。
这里应用了DETR解码器来更新姿势信息。解码器由交替堆叠的自注意层和交叉注意层组成。自注意力在姿势信息内计算,而交叉注意力在姿势信息和处理过的代价量之间计算。
7 规划
大多数规划方法,尤其是行为规划,是基于规则的[1,2,7-8],这为数据驱动系统的探索和升级带来了巨大的负担。基于规则的规划框架负责为车辆的低级控制器要跟踪的轨迹点序列。基于规则的规划框架的优点是具有可解释性,当出现故障或意外的系统行为时,可以识别有缺陷的模块。其局限性在于需要许多手动启发式功能。
基于学习的规划方法已成为自动驾驶研究中的一种趋势[15,18,33]。驾驶模型可以通过仿真学习获取知识,并通过强化学习探索驾驶策略。与基于规则的方法相比,基于学习的方法可以更有效地处理车辆与环境的交互。尽管其概念吸引人,但当模型行为不当时,很难甚至不可能找出原因。
仿真学习(IL)是指基于专家轨迹的智能体学习策略。每个专家轨迹都包含一系列状态和动作,并且所有"状态-动作"对都被提取来构建数据集。IL的具体目标是评估状态与动作之间最适合的映射,以便智能体尽可能接近专家轨迹。
为了缓解标注数据的负担,一些科学家已经将强化学习(RL)算法应用于行为规划或决策制定。智能体可以通过与环境交互获得一些奖励。RL的目标是通过试误来优化累积数值奖励。通过与环境持续交互,智能体逐步获得关于达到目标端点的最佳策略的知识。在RL中从零开始训练策略通常很耗时且具有挑战性。将RL与其他方法(如IL和课程学习)相结合可能是一个可行的解决方案。
近年来,深度学习(DL)技术通过深度神经网络(DNN)的奇妙特性:函数逼近和表征学习,为行为规划问题提供了强大的解决方案。DL技术使RL/IL能够扩展到以前难以解决的问题(如高维状态空间)。
这里介绍一个两阶段占位预测引导的神经规划器(OPGP)[46],它将未来占位和运动规划的联合预测与预测引导相结合,如图10所示。
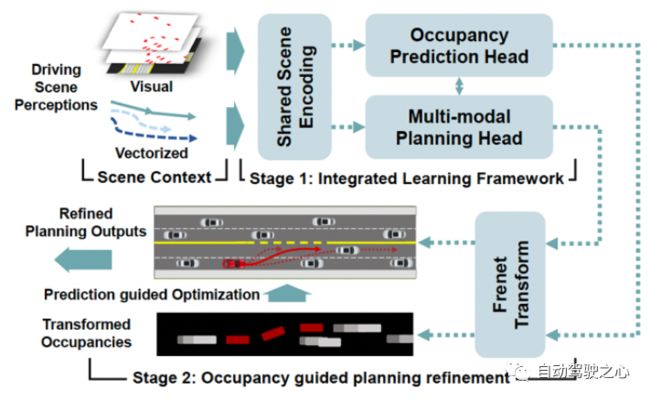
图 10 两阶段式OPGP
在OPGP的第一阶段,在基于Transformer骨干上建立了一个集成网络。视觉特征是历史占用栅格和栅格化BEV路线图的组合,代表特定场景下交通参与者的空间-时间状态。矢量化上下文最初关注以自动驾驶车辆为中心的参与者的动态上下文。考虑到视觉特征和矢量化上下文的交互,同时输出所有类型交通参与者的占位预测。同时,编码后的场景特征和占位情况在规划头中共享并实现有条件地查询,规划头进行多模态运动规划。
OPGP第二阶段的重点是以一种优化可行的方式为细化建模来自占用率预测的明确指导。更具体地说,他们在Frenet空间(这是一个由切线和曲率决定的移动右旋坐标系)中构建了一个优化过程,用于使用变换后的占用率预测进行规划细化。
8 控制
与自动驾驶中的其他模块(如感知和规划)相比,车辆控制相对成熟,经典控制理论发挥着主要作用[20,21]。然而,深度学习方法不仅能在各种非线性控制问题上获得优异的性能,还能将先前学习到的规则外推到新的场景中,因此在自动驾驶控制领域的应用前景十分广阔。因此,深度学习在自动驾驶控制中的应用正变得越来越流行[13]。
传感器的配置多种多样;有些人仅通过视觉来控制车辆,有些人则利用测距传感器(LiDAR或雷达),还有些人利用多传感器。在控制目标方面也存在差异,有些人将系统设计为一个高级控制器提供目标,然后通过低级控制器实现目标,这种方式通常使用经典控制技术。另一些则旨在端到端学习的自动驾驶,将观测结果直接映射到低级车辆控制界面命令。
车辆控制可以分为横向控制和纵向控制。横向控制系统旨在控制车辆在车道上的位置,并实现其他横向动作,如变道和回避碰撞动作。在深度学习领域,这通常是通过使用车载相机的图像/LiDAR的点云捕捉环境信息作为神经网络的输入来实现的。
在本节中,我们将介绍一种带有语义视觉地图和相机的端到端(E2E)驾驶模型[16]。仿真人类驾驶是通过对抗学习来实现的,其中一个生成器模仿人类驾驶员,一个识别器使其像人类驾驶员。
训练数据(名称为"Drive360数据集")由前置相机和渲染的TomTom路线规划模块采集。然后采用HERE地图数据对数据集进行离线增强,以提供同步的语义地图信息。

图 11 E2E驾驶模式框架
对于基本的E2E驾驶模型,记录历史图像和地图渲染序列,并预测动作。网络结构如图11(a)所示:图像通过视觉编码器输入,输出的潜变量进一步输入LSTM,从而产生隐藏状态h;地图渲染也在视觉编码器中处理,产生另一个潜变量量;然后将这三个变量连接起来预测动作。
带有额外语义地图信息的简单方法称为后融合方法,其示意图如图11(b)所示:一个向量嵌入所有语义地图信息,经过全连接网络处理,输出潜在变量量与、和h连接。
最近,一种新方法被提出:根据语义图信息提高分割网络的输出类别概率,其完整架构如图11(c)所示。该方法使用语义分割网络获得所有19个类别的置信度掩码,然后使用软注意力网络使该掩码生成19个类别的注意力向量。
在训练驾驶模型时,决策问题可以被视为匹配动作序列(称为drivelets)的监督回归问题。因此可以使用生成对抗网络(GAN)来制定模仿学习问题,其中生成器是驾驶模型,判别器识别drivelet是否类似于人类规划的路径。
9 V2X
得益于通信基础设施的完善和通信技术的发展(如车联网(V2X)通信等),车辆可以通过可靠的方式传递信息,从而实现车辆之间的协作[4,11]。协同驾驶利用车对车(V2V)和车对基础设施(V2I)通信技术,旨在实现协同功能:(i)协同感知和(ii)协同操纵。
有一些通用的协同驾驶场景:智能停车、变道和并线以及交叉路口协同管理。车辆队列(Vehicle Platooning),也称为车队驾驶,是指两辆或两辆以上的车辆连续在同一车道上以较小的的车间距(通常小于1秒)同速并排行驶,这是实现合作自动驾驶的一个主要用例[26]。
采用集中式或分散式的策略进行有价值的研究工作主要集中在协调交叉路口的CAV和高速公路入口匝道上的并线上。在集中式的策略中,系统中至少有一项任务是由单个中央控制器控制所有车辆的。在分散控制中,每辆车根据从道路上其他车辆或协调器接收到的信息选择自己的控制策略。
分散式的策略可分为三种类型:协商、协议和紧急。最有代表性的协商类型是:协同合作问题和博弈竞争问题。协调过程的协议将产生一系列可接受的措施,甚至动态地重新确定目标。紧急问题使得每辆车根据自己的目标和感知,以一种有利于自己的方式规划,例如博弈论或自组织。
与单车感知不同,协同感知可以利用多个智能体之间的交互来丰富自动驾驶系统的感知,因此受到了广泛关注[31]。随着深度学习方法被广泛应用于自动驾驶感知系统,协同感知系统的能力和可靠性也在稳步增加。
根据信息传递和协同阶段,协同感知方案可大致分为早期协同、中期协同和后期协同。早期协同采用网络输入端的原始数据融合,也称为数据级融合或低级融合。考虑到早期协同的高带宽,一些工作提出了中间协同方法,以平衡性能和带宽之间的权衡。后期协同或对象级协同采用网络预测融合。协同感知的挑战性问题包括:标定、车辆定位、时空同步等。

图 12 V2X协同感知示意图
这里我们提出了一个多层的V2X感知平台,如图12所示。时间同步信息处理不同智能体的数据之间的时间差异。为了灵活性,数据容器优先保留一个时间窗口,例如1秒(LiDAR/雷达为10帧,相机为30帧)。空间构建需要姿态信息,姿态信息从车辆定位和标定中获取,大多基于在线地图或与离线建立的HD地图信息进行匹配。
我们假设传感器是相机和LiDAR。神经网络模型可以处理原始数据,包括:输出中间表征(IR)、场景分割和目标检测。为统一协同空间,原始数据映射到BEV(鸟瞰视图),处理结果也位于相同的空间中。
为了保持有限的尺度空间,保留多个IR层,如3层,这允许不同数据分辨率的灵活融合。V2X协同感知需要接收端做更多工作,整合来自其他车辆和路侧的信息,分别融合IR、分割和检测。融合模块可以使用CNN、Transformer或图神经网络(GNN)。
注意:FCL代表全连接层原始数据需要"压缩"模块和"解压缩"模块;"插值"模块和"运动补偿"模块对基于时间同步的信号和基于在线建图/定位/HD地图(离线构建)的相对姿态的接收器都是有用的。
10 仿真
在封闭道路或公共道路上进行实车测试既不安全,成本又高,而且并不总是可重复的。模拟测试有助于填补这项空白,然而,模拟测试的问题在于:它的好坏取决于用来测试的模拟器和模拟场景对于真实环境的代表性程度[17]。
理想的仿真效果应该尽可能接近现实。然而,这意味着模拟器必须模拟三维场景环境方面高度精细,并在汽车物理等底层车辆计算方面非常精确。因此,需要在三维场景的精细度度和车辆动力学的简化之间进行权衡。
一般来说,从虚拟场景中学到的驾驶知识需要迁移到现实世界中,因此如何将在模拟场景中学到的驾驶知识适应到现实中成为一个关键问题。虚拟世界和现实世界之间的差距通常被称为"现实差距"。为了处理这种差距,人们提出了各种方法,分为两类:从仿真到现实的知识转移(sim2real)和在数字孪生中学习(real2sim)[44]。
在sim2real中逐渐发展出6种方法,包括课程学习、材料学习、知识提炼、鲁棒性强化学习、领域随机化和迁移学习。基于数字孪生的方法旨在利用传感器和物理模型的数据,在仿真环境中构建真实世界物理实体的映射,达到反映相应物理实体全生命周期过程的作用,如AR(增强现实)和MR(混合现实)。
尽管仿真的自动驾驶测试系统相对便宜而且安全,但为了评估而制作的安全关键场景对于管理风险和降低成本更为重要[22]。实际上,安全关键场景在现实世界中并不多见,因此在仿真中生成这些场景数据的各种方法被投入研究,生成方式分为三种类型:数据驱动生成,即仅利用收集到的数据集信息生成场景;对抗生成,即利用部署在仿真中的自动驾驶车辆的反馈信息生成场景;基于知识的生成,即主要利用外部知识信息作为生成场景的约束或指导。
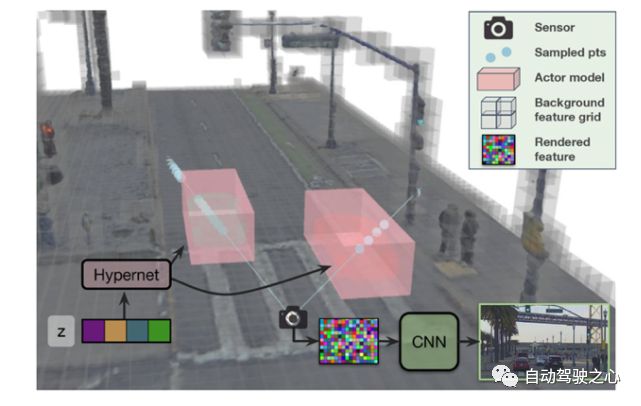
图 13 UniSim传感器模拟器概述
这里我们报告一个最新的神经传感器仿真平台[49]-UniSim,由Waabi、Toronto 和MIT构建。UniSim将车辆传感器捕获的单个记录日志转换为逼真的闭环多传感器仿真作为可编辑和可控制的数字孪生。图13展示了UniSim的概况。
如图13所示,UniSim是一个神经闭环仿真器,它联合学习静态场景和动态行为者的形状和外观表示,从对环境的单次通过中捕获的传感器数据。为了更好地处理外推视角,为动态对象引入了可学习的先验知识,并利用卷积网络完成未见区域。
此外,UniSim中的3D场景被分为静态背景(灰色)和一组动态行为者(红色)。神经特征场对静态背景和动态行为者模型进行单独访问,并执行体绘制以生成神经特征描述符。静态场景由稀疏特征网格建模,并使用Hypernet从可学习潜在空间生成每个参与者的表示。最后,使用CNN将特征解码为图像。
注意:一类称为扩散模型[50]的新兴生成模型,具有正向过程和反向过程的通用过程,以学习数据分布以及采样过程以生成新数据,在计算机视觉中获得了重大关注。最近,它在图像到图像、文本到图像、3D形状生成、人体运动合成、视频合成等方面变得越来越受欢迎。期待扩散模型为自动驾驶中的仿真器合成可想象的驾驶场景内容。
11 安全性
安全性是实际部署自动驾驶系统(ADS)的主要挑战[19,23]。除了传感器和网络系统的可能受到传统攻击之外,基于人工智能或机器学习(包括深度学习)的系统,尤其需要考虑神经网络天生易受来自对抗性示例的对抗性攻击所带来的新的安全问题。
ISO 26262道路车辆——功能安全是广泛使用的安全指导标准,仅适用于缓解与已知部件故障相关的已知不合理风险(即已知不安全情景)。但不适用于因复杂的环境变化以及ADS如何应对它们而产生的AV驾驶风险,而车辆不存在技术故障
目前,对抗防御可以分为主动防御和被动防御。主动防御集中于改善目标AI模型的鲁棒性,而被动防御则针对检测反向示例,然后再将它们反馈到模型中。主动防御方法主要有五种类型:对抗训练、网络蒸馏、网络正则化、模型集成和认证防御。被动防御主要包括以下两类:对抗检测和对抗转换。
可解释性是由深度神经网络的黑盒特性引起的一个问题。简单地说,它应该为深度学习模型的行为提供人类可以理解的解释。解释过程可以分为两个步骤:提取步骤和展示步骤。提取步骤获得中间表征,展示步骤以简单的方式将其呈现给人类。在自动驾驶中,可视化模型主干中的特征图或管理解码器输出的损失,是增强可解释性的有效方式。
为了提供安全保证,需要针对ADS将面临的现实世界中的各种场景进行大量的验证和确认(V&V)。V&V最大化场景覆盖率的一个常规策略是在模拟生成的大量包含ADS的场景样本。确保合理覆盖率的方法分为两类:基于场景抽样的方法和形式化方法。
场景抽样方法是人工智能安全控制的主要方法,包括基于测试的抽样和基于伪造的抽样,基于测试的抽样是为了以最小的代价获得最大的场景覆盖率,基于伪造的抽样是为了发现开发人员更关注的不常见案例,如安全关键场景。

图 14 SOTIF的目标[23]
ISO 21448《预定功能安全》(SOTIF)提出了一个定性目标,从高层次描述了如何最小化ADS功能设计中已知和未知的不安全场景后果[23],如图14所示。基于采样的方法在发现未知的不安全场景时偏差较小,更具探索性,并且从未知到已知的过程中,所有采样场景都在一致的仿真环境和相同的保真度水平下进行。
在AV安全性中广泛使用的常规方法包括模型检查、可达性分析和定理证明。模型检查来自软件开发,以确保软件行为遵循设计规范。当安全规范以公理和引理描述时,然后进行定理证明以使用最坏情况假设来证明安全性。由于可达性分析可以对动态驾驶任务(DDT)的特征给出安全声明,它估计DDT的特征,例如Mobileye的安全模型RSS(责任敏感安全)和Nvidia的安全模型SFF(安全力场)。
12 数据闭环
从车辆采集数据、筛选有价值的数据、标注数据、训练/优化预期模型、验证目标模型并部署到车辆上等过程,构成了自动驾驶研发的数据闭环[37-41],如图15所示。
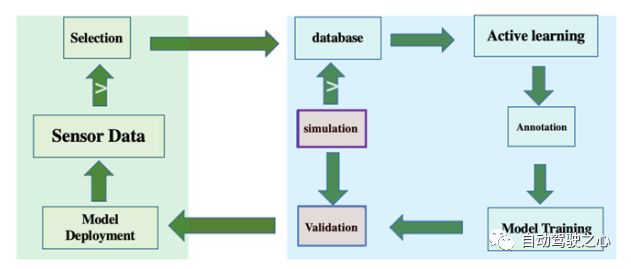
图 15 自动驾驶研发的数据闭环
作为自动驾驶研发平台,数据闭环应包括客户端车端和服务器云端,实现车端数据采集和初步筛选、云端数据库基于主动学习的挖掘、自动标注、模型训练和仿真测试(仿真数据也可加入模型训练)、模型部署回车端。数据选择/筛选和数据标注/标注是决定数据闭环效率的关键模块。
12.1 数据选择
特斯拉是第一家在量产车上明确提出数据选择策略的公司,被称为在线"影子模式"。可以看出,数据选择分为两种方式:一种是在线方式,将数据采集的触发模式设置在人类驾驶的车辆上,这样可以最经济地采集到所需的数据;这种方式大多用于量产和商务阶段(注:商务车配备安全操作员通常直接手动触发采集)。另一种是离线数据库模式,一般采用数据挖掘模式,在云服务器中对增量数据进行筛选,这种模式常用于研发阶段,即使是量产阶段采集的数据也会在服务器端数据中心进行二次筛选;此外,在已知场景或目标数据严重缺乏的情况下,也可以在车辆或服务器端设置"内容搜索"模式,搜索类似的物体、场景或场景数据,以提高训练数据的多样性和模型的泛化能力。
在自动驾驶领域,边缘情况也有等同或类似的概念,如异常数据、新奇数据、异常值数据、分布外数据(OOD)等。边缘情况检测可分为在线和离线两种模式。在线模式通常用作安全监测和预警系统,而离线模式通常用于在实验室中开发新算法,选择合适的训练和测试数据。边缘情况可以定义在几个不同的层次:1)像素/体素;2)域;3)对象;4)场景;5)情景。最后一个情景级别的极端情况通常不仅与感知相关,还涉及预测和决策规划。

图 16 在线和离线数据选择
在此,我们提出一个在线和离线数据选择框架,如图16所示。在图16(a)所示的在线模式下,我们采用多种筛选路径,如场景搜索、阴影模式、驾驶操作和单类分类。在内容搜索模式下,基于给定的查询,"场景/情景搜索"模块从图像或连续帧中提取特征(空间或时间信息)进行模式匹配,以发现特定的对象、情境或交通行为,例如夜间街道上出现的摩托车、恶劣天气下高速公路上的大货车、环岛中的车辆和行人、高速路上的变道、街道交叉口的掉头行为等。
“阴影模式"模块根据车载自动驾驶系统(ADS)的结果进行判断,如感知模块中不同摄像头检测到的物体匹配错误、连续帧检测到的抖动或突然消失、隧道出入口强烈的光照变化,以及决策规划中要求车辆减速但车辆实际加速或要求车辆加速但车辆实际减速的行为,检测到前方障碍物但未试图避让、变道时接近并几乎与后侧摄像头检测到的车辆相撞等异常情况。
”驾驶操作"模块将从车辆CAN总线获得的偏航率、速度等数据中检测异常情况,如奇怪的之字形现象、过度加速或制动、大角度转向或转弯角度,甚至触发突然紧急制动(AEB)。
"单类分类"模块一般为感知、预测和规划中的数据进行训练异常检测器,这是一种广义的数据驱动的"影子模式";它依据感知特征、预测轨迹和规划路径的正常驾驶数据;对于车端的轻量化任务,则采用单类SVM模型。
最后,根据采集路径对"数据采集"模块中对采集到的数据进行标注。
对于图16(b)所示的离线模式,我们同样选择多条路径进行数据筛选。无论是从研发数据采集车还是量产商业车上采集的新数据,都将存储在"临时存储"硬盘中,以备二次选择。同样,另一个"场景/情景搜索"模块根据定义的某种情景的直接检索数据。应用的算法/模型规模更大,计算耗时更长,但不受实时性的限制。此外,还可以使用数据挖掘技术。聚类"模块将执行一些无监督的分组方法或密度估计方法来生成场景聚类。因此,某些远离聚类中心点的数据会产生异常。
为了进一步筛选数据,可以分步骤在数据上运行自动驾驶软件(如LogSim风格),并可以在一系列设计的检查点上检测到异常。这里,自动驾驶采用模块化过程,包括"感知/定位/融合"模块、"预测/时间域融合"模块和"规划和决策"模块。每个模块的输出是一个检查点,通过"单类分类"模块检测异常。因为没有实时限制,所采用这种异常检测器更复杂。在服务器端,可以使用深度神经网络进行单类分类。这是一种离线的“影子模式”。

图 17 预测模块
"感知/定位/融合"模块的架构与图6相似。"预测/时空融合"模块作为额外的输出头,其结构图如图17所示。特征进入"时序编码"模块,该模块的结构可以设计为类似于RNN(GRU或LSTM)模型或基于图神经网络(GNN)的交互建模器,融合多帧特征。运动解码"模块理解类似于BEVerse模型的时空特征,并输出预测轨迹。

图 18 规划和决策模块
在感知和预测的基础上,我们设计了与ST-P3类似的规划决策算法框图,如图18所示。基于预测输出的BEV时空特征,我们选择了基于采样的规划方法,在 "Plan Decod"模块中训练代价函数来计算采样器生成的各种轨迹,并在"ArgMin"模块中找到代价最小的轨迹。代价函数包括安全性(避开障碍物)、交通规则和轨迹平滑性(加速度和曲率)等方面。最后,对整个感知-预测-规划过程的全局损失函数进行优化。
综上所述,BEV/Occupancy网络为基础的感知、预测和规划构成了一个端到端的自动驾驶解决方案,称为BP3。
12.2 数据标注
数据标注的任务分为研发阶段和量产阶段:1)研发阶段主要涉及研发团队的数据采集车,包括LiDAR,使LiDAR能够为相机的图像数据提供三维点云数据,从而提供三维地面真实值。例如,BEV(鸟瞰)视觉感知需要从二维图像中获取BEV输出,这涉及到透视投影和三维信息推测;2)在量产阶段,数据主要由乘用车客户或商用车运营客户提供。其中大部分没有LiDAR数据,或者只有有限FOV(如前向)的三维点云。因此,对于相机图像输入,需要估计或重建三维数据以进行标注。
在图6中,我们展示了基于深度学习的端到端(E2E)数据标注模型。然而,为了训练这样一个E2E模型,我们需要大量的标注数据。为了缓解数据需求,我们提出了一个半传统的标注框架,它是经典计算机视觉和深度学习的混合体,如图19所示。
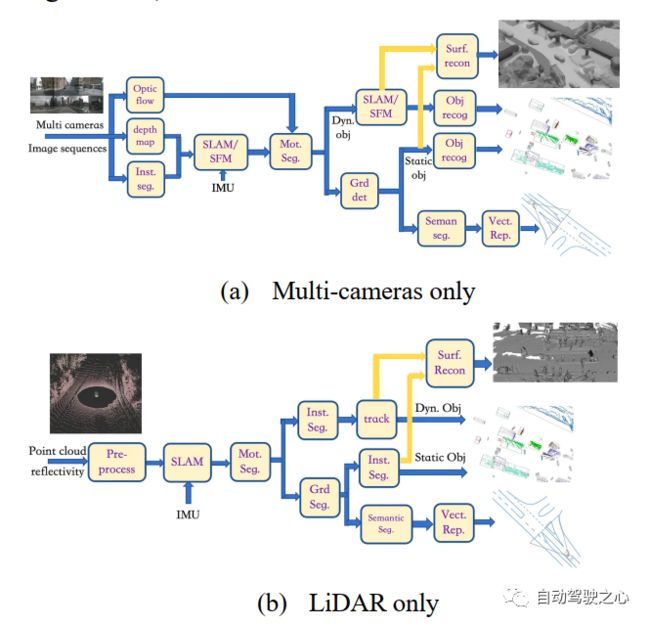

图 19 半传统的数据标注框架
对于仅相机多输入,如图19(a)所示,我们首先在多个相机的图像序列中使用三个模块,即"inst seg"、"depth map"和"optical flow",以计算实例分割图、深度图和光流图;"inst seg"模块使用深度学习模型定位和分类一些对象像素,如车辆和行人;"depth map"模块使用深度学习模型根据单目视频估计两个连续帧之间的像素运动,形成虚拟立体视觉来推断深度图;"optical flow"模块使用深度学习模型直接推断两个连续帧之间的像素运动;基于深度图估计,"SLAM/SFM"模块可以获得类似RGB-D+IMU传感器的稠密3D重构点云;与此同时,实例分割结果实际上可以剔除障碍物,如车辆和行人;通过"motseg"模块,获得的各种运动障碍物将在下一个"SLAM/SFM"模块(不输入IMU)中重建,这类似于RGB-D传感器的SLAM架构,可以看作单目SLAM的扩展;然后,它将"instseg"的结果转移到"obj recog"模块,并标注点云的3D包围框;对于静态背景,"grd det"模块将区分静态障碍物和道路点云,以便静止障碍物(如停车车辆和交通锥)将"inst seg"模块的结果转移到"obj recog"模块,对点云的3D边界框进行标注;从"SLAM/SFM"模块获得的动态对象点云和从"grd det"模块获得的静态对象点云进入"Surf Recon"模块进行泊松重建;道路表面点云仅提供拟合的3D道路表面;从图像域"inst seg"模块可以获得道路表面区域;基于自身运动学,可以进行图像拼接;在"seman seg"模块在拼接的道路表面图像之后,可以获得车道标线、斑马线和道路边界;然后,在"vectrep"模块中使用多线标注;最后,所有标注都投影到车辆坐标系上,得到一帧的最终标注。
图19(b)所示,对于仅LiDAR输入,我们经过"预处理"模块、"SLAM"模块和"mot seg "模块。在"inst seg"模块中,直接对不同于背景的运动物体进行基于点云的检测;使用神经网络模型(如PointNet和PointPillar)从点云中提取特征图;对于静态背景,经过"Grd Seg"模块后,判断为非路面的点云进入另一个"Inst Seg"模块进行物体检测,得到静态物体的三维边界框标注;对于路面点云,应用"Semantic Seg"模块,基于深度学习模型,利用反射强度对与图像数据相似的语义对象进行像素级分类,即车道标线、斑马线、道路区域等;通过检测道路边界得到路缘石位置,最后在"Vect Rep"模块中进行多边形的标注;跟踪到的动态物体点云和实例分割得到的静态物体点云进入"surf recon"模块,进行泊松重建;最后,将所有标注投影到车辆坐标系上得到一帧的最终标注。
对于图19(c)所示具有LiDAR和多相机的输入,我们将图19(a)中的"光流"模块替换为"场景流"模块,"场景流"模块使用深度学习模型估计三维点云的运动;"深度图"模块替换为"深度填充"模块,"深度填充"模块使用神经网络模型完成深度填充,深度填充由点云投影(插值和"填补空洞")到图像平面得到,然后反向投影回三维空间生成点云;同时,"seg inst"模块替换为"seman seg"模块,该模块使用深度学习模型标注点云;随后,稠密的点云和IMU数据将进入"SLAM"模块进行运动轨迹估计,并选择标记为障碍物(车辆和行人)的点云;同时,估计的场景流也将进入"mot seg"模块,进一步区分运动障碍物和静态障碍物;运动物体通过"inst seg"模块和"track"模块后,得到运动物体的标注;同样,静态障碍物通过"grd seg"模块后,由"inst seg"模块标注;车道标线、斑马线、道路边缘等地图元素通过"seman seg"模块得到;拼接后的路面图像和对齐后的点云进入"vect rep"模块进行多边形标注;通过跟踪得到的动态物体点云和实例分割得到的静态物体点云进入"surf recon"模块进行泊松重建;最后将所有标注投影到车辆坐标系上得到一帧的最终标注。
注意:这种半传统标注方法也被称为4D标注,是由特斯拉的自动驾驶团队首先探索。因此,所提出的数据标注框架分两阶段运行:首先是半传统4D标注,然后是基于深度学习的端到端标注。
12.3 主动学习
自动驾驶机器学习模型的训练平台可以根据边缘情况、OOD或异常数据的检测方法,采用合理的方法利用这些增量数据。其中,主动学习是最常用的方法,可以有效利用这些有价值的数据。主动学习是一个迭代过程,在这个过程中,每次迭代都会学习一个模型,并使用一些启发式方法从未标明点池中选择一组点进行标注。不确定性估计是启发式方法之一,在自动驾驶领域得到了广泛应用。不确定性有两种主要类型:感知不确定性和偶然不确定性。感知不确定性通常被称为模型不确定性,其估计方法主要包括集合法(Ensemble method)和蒙特卡罗剔除法(Monte Carlo dropout method);偶然不确定性被称为数据不确定性,常用的估计方法是基于贝叶斯理论的概率机器学习。
注:尽管人们大多采用监督学习来训练数据闭环中的模型,但为了提高泛化、可扩展性和效率,引入了一些新的机器学习技术,如半监督学习(同时使用有标签和无标签数据),甚至自监督学习(如流行的无标签数据对比学习)。
13 结论
在这篇关于自动驾驶的综述中,我们概述了一些关键的创新和未解决的问题。我们提出了几种基于深度学习的架构模型,即BEV/占位感知、V2X中的协同感知、基于BEV/占用网络的感知与预测和规划(BP3)的端到端自动驾驶。本文的一个新观点是,我们更关注自动驾驶研发中的数据闭环。特别是,我们提出了对应的数据选择/筛选和数据标注/标记机制来驱动数据闭环。
13.1 ChatGPT 和 SOTA 大模型
最后,我们简要讨论大模型对自动驾驶领域及其数据闭环范式的影响。
最近,由大型语言模型(LLMs)驱动的聊天系统(如chatGPT和PaLM)出现并迅速成为自然语言处理(NLP)中实现人工通用智能(AGI)的一个前景广阔的方向[42]。实际上,诸如大规模预训练(学习整个世界网络上的知识)、指令微调、提示学习、上下文学习、思维链(COT)和来自人类反馈的强化学习(RLHF)等关键创新在提高LLM的适应性和性能方面发挥了重要作用。与此同时,强化偏差、隐私侵犯、有害错觉(不真实的胡言乱语)和巨大的计算机功耗等问题也引起了人们的关注。
大模型的概念已经从NLP扩展到其他领域,如计算机视觉和机器人学。同时,多模态输入或输出的实现使应用领域更加广泛。视觉语言模型(VLMs)从网络规模的图像-文本对中学习丰富的视觉语言相关性,并通过单个VLM(如CLIP和PaLM-E)实现对各种计算机视觉任务的零样本预测。Meta[43]提出的ImageBind是一种学习跨六种不同模态(图像、文本、音频、深度、热和IMU数据)联合嵌入的方法。它实际上利用了大规模视觉语言模型,并通过与图像配对将零样本功能扩展到一种新的模态。
扩散模型在图像合成领域取得了巨大成功,并扩展到其他模态,如视频、音频、文本、图形和三维模型等。作为多视图重建的一个新分支,NeRF提供了3D信息的隐式表示。扩散模型和NeRF的结合在文本到3D合成方面取得了显着成效。
NavGPT是一个纯粹基于LLM的指令遵循导航代理器,它通过在视觉语言导航任务中进行零样本预测,揭示了GPT模型在具体场景中的推理能力。NavGPT可以明确对导航进行高级规划,包括将指令分解为子目标、整合与导航任务相关的常识知识、从观察到的场景中识别地标、跟踪导航进度以及通过计划调整适应异常情况。
13.2 大模型在自动驾驶系统中的应用
总之,LLM的出现使得AGI从NLP到各个领域,尤其是计算机视觉领域产生了连锁反应。自动驾驶系统(ADS)必将受到这一趋势的影响。有了足够多的海量数据和视觉语言模型,再加上NeRF和扩散模型,大模型的理念和操作将为自动驾驶带来革命性的变化。"长尾"问题将在很大程度上得到缓解,数据闭环可能会转变为另一种闭环模式,即预训练+微调+强化学习,更不用说轻量级车载模型的仿真平台搭建和训练数据的自动标注了。
然而,我们仍然对其鲁棒性、可解释性和实时延迟表示担忧。安全是ADS中最重要的问题,大模型中的有害信息将导致驾驶危险。基于规则的系统可以很容易地理解一些故障导致的结果,但深度学习模型仍然缺少性能和架构之间的联系。使用ADS最关键的是实时响应。到目前为止,我们还没有看到任何一个大模型的应用可以在100毫秒内生成结果,更不用说车载工作的内存要求了。