利用深度学习进行组水平大脑解码
摘要
脑成像数据解码越来越受欢迎,可用于脑机接口和神经表征等方面的研究。解码通常是特定于个体的,由于不同被试之间的差异较大,因而不能很好地泛化。克服这一问题的技术不仅需要能够提供更丰富的神经科学见解,而且还能使组水平模型的性能优于特定个体模型。在这里,本文提出了一种使用个体嵌入的方法(类似于自然语言处理中的词嵌入),来学习并利用个体间变异性的结构作为解码模型的一部分,即WaveNet架构的分类自适应。本研究将该方法应用于脑磁图数据,其中15名被试观看了118张不同的图像,每个图像有30个示例,使用图像呈现后的整个1s窗口来进行图像分类。本研究表明,深度学习和个体嵌入的结合对于缩小个体水平和组水平解码模型之间的性能差距至关重要。重要的是,组水平模型在低精度被试上的表现优于个体模型,并且可用于初始化个体模型。虽然总体上未发现组水平模型的性能显著优于个体水平模型,但是在更大的数据集上,组水平建模的性能预计会更高。为了提供组水平层面的生理学解释,本研究利用了置换特征重要性方法,提供了模型中编码的时空和频谱信息。所有代码均可在GitHub上获得(https://github.com/ricsinaruto/MEG-group-decode)。
前言
近年来,解码技术在神经影像学领域越来越受欢迎,特别是从内部状态(即大脑活动)解码外部变量(如刺激类别)。这种分析对于脑机接口(BCI)应用或获得神经科学见解非常有用。对大脑记录进行解码的应用中通常为每个数据集和每个被试拟合单独的模型(通常是线性模型)。这样做的好处是解码可以根据数据集/被试进行调整,但缺点是无法利用可在数据集/被试之间传递的知识。这对于神经影像学领域尤为重要,因为收集更多数据既昂贵而且难度也较大(例如在临床人群中)。特定被试(个体水平)模型的实际缺点还包括计算负荷增加、过拟合几率更高以及无法适应新的被试。本研究旨在利用多个被试的数据,训练一个可以在被试之间泛化的共享模型(组水平模型)。个体水平和组水平模型的概念可视化如图1所示。
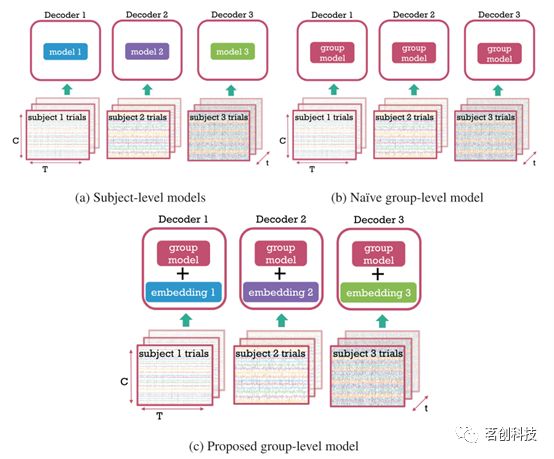
图1.个体水平和组水平模型的概念可视化。
由于脑磁图(MEG)具有高时间分辨率和相对较好的空间分辨率,因而是研究大脑活动快速动态的极好方法。MEG非常适合进行解码分析,这种分析通常使用个体水平模型进行。这是因为神经影像数据中存在很高的被试间变异性。另一种方法是在多个被试中训练和使用相同的解码模型。将不明确地对任何被试间变异性进行建模的方法称为“朴素组水平建模”。这种朴素方法实际上假设所有数据来自同一被试(参见图1b),但由于被试间差异很大,通常表现得非常糟糕。本研究旨在改进这些方法。如果组水平建模能够考虑到高度的被试间变异性,那么就可以在被试间共享相关信息,从而带来两个关键优势。首先,我们可以直接从组水平解码模型中获得神经科学见解。其次,使用适当规模的多被试数据集,组水平模型的性能将优于个体水平模型。
本研究的主要目标是通过使用单个组水平解码模型来改进个体水平模型,该模型可以在被试之间(以及被试内)进行泛化。本文将其称为跨被试解码,即模型在所有被试的部分数据上进行训练,然后在留出数据上进行测试。这是因为在这种方式下表现良好的组水平模型有助于获得与组水平相关的神经科学信息。本文还介绍了另一种方法,即留一法分析(Leave-one-subject-out,LOSO)。在LOSO分析中,组水平模型在多个被试数据上进行训练,并在一个新的未知数据上进行测试,这在零样本学习BCI应用中特别有用。
在这里,本研究提出了一种通用架构,借助个体嵌入(图1c和图2)对多个被试进行联合解码。需要注意的是,我们在全时段解码的背景下进行此操作,因为最近的研究表明,全时段模型的性能优于滑动窗口解码。本研究使用包含视觉任务的MEG数据集(15名被试),并做出了以下贡献。首先,本研究引入了具有个体嵌入的组水平模型,明显改进了朴素组水平建模,并展示了与个体水平解码模型相比,可以提供的解码方面的潜在改进。其次,本研究深入探讨了非线性和个体嵌入如何有助于组水平建模。第三,本文展示了可以从基于深度学习的解码模型中获得神经科学见解,并使用置换特征重要性(PFI)来揭示有意义的时空和频谱信息是如何编码的。
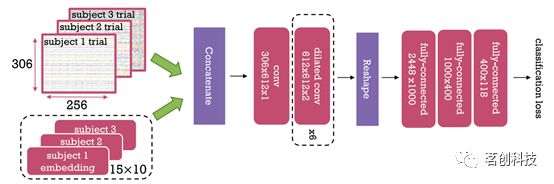
图2.基于个体嵌入的组水平WaveNet分类器。
方法
数据
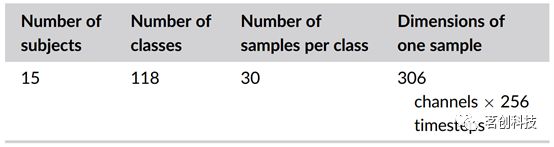
本研究使用任务态MEG数据集,其中包括15名被试观看118张不同的图像,每张图像观看30次。分段后的数据是公开的,但本研究直接从原作者那里获得了连续的原始MEG数据,以便能够使用MNE-Python运行我们的预处理流程。原始数据经过0.1-125Hz的带通滤波,并使用陷波滤波器去除线噪声。使用白化处理来消除个体水平模型中通道之间的协方差。先前的研究表明,去除通道间协方差(白化处理),或者可以说是多元噪声归一化,可以提高线性解码模型的性能。对于组水平模型,不执行白化处理,而是通过去除均值并除以方差来对每个通道进行单独标准化。在组水平模型中不使用白化的原因是,当每个PCA分解投射到不同的空间时,它会破坏被试间通道的对齐。在白化处理之后,将数据降采样至250Hz并进行1.024s的分段。这导致了来自306个MEG传感器的306×256维试次(通道×时间点)。我们进行多类解码,预测118个类(图像)中每个类别的概率。有关分段数据的概要,详见表1。
表1.分段数据集的维度。
模型
本研究的目标不是设计一种用于解码MEG数据的新架构,而是基于已被证明对时间序列数据有效的卷积神经网络架构来构建模型。因此,本研究使用了一种基于WaveNet的解码模型进行分类,该模型已经成功地应用于音频领域,我们称之为WaveNet分类器。WaveNet中的扩张卷积对于建模时间序列数据非常有效,因为连续层可以提取输入的互补频率内容。本研究的WaveNet分类器模型由两部分组成:(时间)卷积块用作特征提取器,全连接块用于分类(图2)。卷积块使用一系列1D扩张卷积层,其中包括随机失活(dropout)和反双曲正弦激活函数。对于个体水平的建模,本研究使用3个卷积层。对于组水平的建模,使用了6个卷积层。通过训练分别使用3层和6层的个体水平和组水平模型,并在每种情况下选择最佳的模型版本,从而在个体水平和组水平之间进行公平比较。
本研究评估了每个模型的两个版本,分别是线性的和非线性的Wavenet分类器。这样我们就可以看到非线性(深度学习的基石)如何与组水平建模相互作用。最后,将组水平建模分为两种方法。首先,我们有一个朴素组水平模型,即标准的6层Wavenet分类器。其次是本研究提出的组水平模型,通过包含个体嵌入来改进朴素组水平模型。下面给出了个体水平(方程(1))、朴素组水平(方程(2))和嵌入组水平(方程(3))模型的数学表示。

其中,s表示单个被试,S是所有被试的集合。ts和ys分别表示被试s的目标变量和输入试次,fs是被试特定模型,fg是跨被试共享的组水平模型。es是特定被试的学习嵌入。个体嵌入是一种处理被试间变异的方法,类似于自然语言处理(NLP)中的词嵌入,每个被试都有一个对应的稠密向量。将该向量与输入试次数据的通道维度在所有时间点上进行连接(在每个试次中)。
实验过程
本研究的主要评估指标是在118个类别上进行跨被试解码的分类准确性。对于每个被试和类别,按照4∶1的比例划分训练集和验证集。个体水平和组水平模型在相同的划分上进行训练和评估。请注意,对于每个模型,还进行了额外的训练,其中(线性)恒等函数被用作激活函数,以评估非线性的影响。使用Adam优化器分别训练500和2000个epoch的线性模型和非线性模型。表2列出了图3中呈现的所有模型和训练组合。
表2.模型和训练组合及其对应的命名。
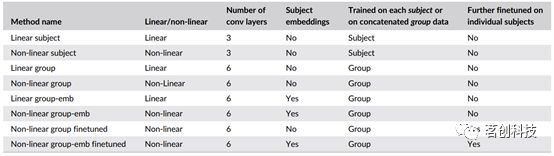
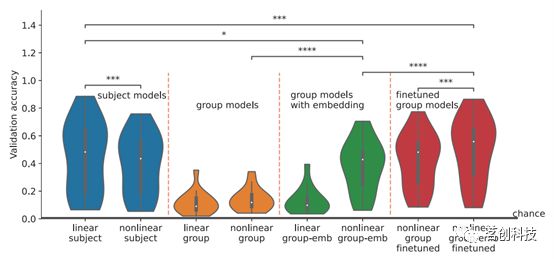
图3.在每个被试的验证集上评估经过训练的个体水平和组水平模型。
在组水平和个体水平模型中,Dropout设置为0.4和0.7,批大小分别为590和59。组水平模型的学习率设置为0.0001,个体水平模型的学习率设置为0.00005。在NVIDIA A100 GPU上,单个个体水平和组水平模型的训练时间分别为5-15分钟和4小时。
结果
所有训练模型的验证精度如图3所示。有趣的是,在个体水平上,线性模型的表现略优于非线性模型(增加了4%,p=5.7e-4)。本研究认为,在被试内进行训练/验证时,数据规模和噪声水平的限制都导致了非线性模型的性能欠佳。MEG数据集普遍存在较大的被试间差异,个体准确率范围从5%到88%不等。正如预期的那样,训练朴素组水平模型,即将线性或非线性WaveNet分类器简单应用于组水平建模(橙色小提琴图)时,会导致性能大大降低。在非线性模型中添加个体嵌入(non-linear group-emb)可将性能提高24%(p=1.9e-6),但在线性模型中则没有提高(linear group-emb)。这表明,在非线性激活函数中结合个体嵌入可以缩小与个体水平模型的差距。
本研究还对每个被试的训练数据分别进行了500个epoch的嵌入组水平模型的微调(non-linear group-emb finetuned)。有效地使用组水平模型作为个体水平模型的初始化,相对于从头开始训练的个体水平模型(linear subject)来说有所改进,实现了50%的精度(提高了5%)。这表明在组水平上学习到的表征对于个体水平的建模是有用的。相比之下,对朴素组水平模型进行微调(non-linear group finetuned)仅达到42%的精度,这表明将微调与最好的组水平模型相结合时,可以达到最佳性能。
在神经解码中,人们普遍认为组水平模型的表现要比个体模型差。为什么会出现这种情况呢?通过绘制两种模型中每个被试的表现(图4),可以得到一些启示。对于non-linear group-emb模型,有4个精度较低(15%-30%)的被试比linear subject中的精度要高(尽管被试间的均值较低)。这表明如果能够识别出这些被试,那么组水平模型可以成功地应用于某些个体。事实上,在linear subject个体水平的精度与non-linear group-emb和non-linear group-emb finetuned模型的精度之间具有强烈的负相关(分别为−0.88和−0.54)。将finetuned与个体水平模型(linear subject)相比,只有两个精度较高的被试略有下降,而较低/中等精度的被试通常比高精度被试显示出更大的改进(图4)。

图4.当比较经过训练的linear subject、non-linear group-emb和non-linear group-emb finetuned模型时,所有15个被试(不同颜色)的精度变化情况如图所示。
在训练non-linear group-emb模型时,对留一被试的嵌入进行随机初始化。在LOSO(零样本)评估中,两组模型都达到了5%的精度(图5a)。直到使用留一被试训练数据的70%时,两组模型都显著优于线性被试模型(p<0.05,经多重比较校正)。因此,当微调组水平模型时,可以用比线性被试更少的数据来达到相同的性能水平。不出所料,non-linear group-emb模型没有比朴素模型(non-linear group)更好,但重要的是,也没有更差。与图3中的微调设置不同的是,当适应新的被试时,更好的组水平性能并不意味着更好的微调性能。本研究认为这是因为在适应新被试时,该被试的嵌入是随机初始化的,因此在微调过程中需要重新学习。这是本研究方法的一个局限性。
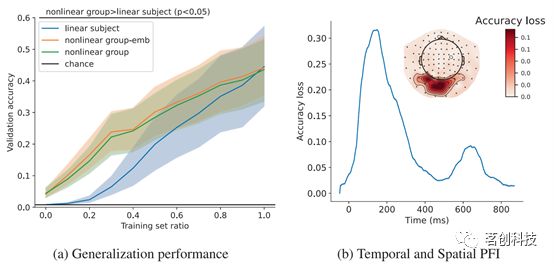
图5.a)对留出被试进行泛化和微调。b)训练后non-linear group-emb模型的时间(线条)和空间(传感器空间图)PFI。
图5b显示了训练后non-linear group-emb模型的时间和空间PFI。为了使结果更加稳健和平滑,对于时间PFI,采用100ms时间窗的随机混排,并对相同位置的磁强计和梯度计进行空间PFI的混排处理。精度损失较高的时间窗或通道被解释为包含更多有关视觉图像的神经可辨别性的信息。这表明了大脑中与呈现图像相关的信息处理是在何时何地发生的。时间PFI在150ms左右显示了一个巨大的峰值,这与之前在该数据集上的个体水平PFI结果一致。之后,信息内容迅速下降,在650ms左右的出现了第二个较小的峰值,这可能对应于500ms图像呈现结束后的大脑响应。空间PFI显示,最重要的通道位于大脑后部视觉区域的传感器中,这符合视觉任务的预期。这种PFI分析与深度学习模型中经常使用的基于梯度的分析方法之间存在良好的一致性。
为了进一步了解所训练的non-linear group-emb模型,可以通过分析学习到的权重来获得可解释的空间、时间和频谱信息。这种分析之所以可行,是因为我们使用了多层神经网络,而在经典的线性模型中无法进行等效的分析。我们可以利用模型自身的结构(即连续的层),以及卷积层中的滤波器可以被视为单个的计算单元。这里的目的是理解模型本身以及它如何表示和处理数据。
图6显示了6个卷积层中的3个层的结果,同一层内的卷积核往往具有相似的时间敏感性,因此本研究只显示了5个卷积核(图6c)。为了比较具有不同输出幅度的卷积核之间的时间PFI,对输出偏差进行标准化处理。在早期层中,敏感性在100ms左右达到峰值,然后迅速下降,最后再次缓慢上升。早期层中的卷积核具有一定的随机空间敏感性(图6a),而且不同卷积核之间存在一些差异。这种敏感性类似于对分类性能来说信息量最大的空间特征(参见图5b)。图6b显示了空间PFI的时间分布。这表明空间敏感性似乎不随时间而变化;也就是说,最重要的通道始终是相同的。
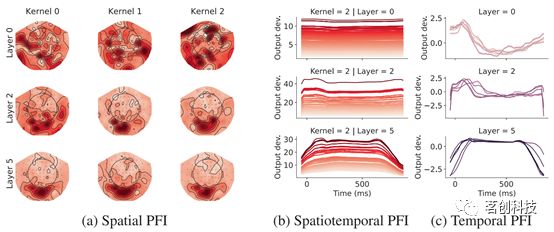
图6.利用PFI可以获得时空信息。
在神经生理学中,我们经常对振荡信号以及特定频率与某些任务(这里是视觉刺激解码)之间的关联性感兴趣。为此,本研究在频谱域中使用PFI,用于测量卷积核输出在特定频段扰动下的变化(图7a)。在所有层和卷积核中,该特征具有1/f(频率)形状,在10Hz处有一个明显的峰值。这些都是MEG信号的常见特征,表明卷积核的频谱敏感性与数据的功率谱一致。有趣的是,先前对该数据集的PFI分析未显示出10Hz的峰值。因此,分析深度学习模型的权重可以揭示更多或不同的信息。在图7b中,还观察了4个通道邻域的频谱PFI,并发现卷积核对所有频率下的相同通道(在视觉区域)都很敏感,并且这些通道具有更大的10Hz峰值。

图7.显示了3层卷积核的频率敏感性。
结论
本研究专注于跨被试解码,这是由于在组水平上表现良好的模型可用于获得与组水平相关的神经科学见解。在这种情况下,本研究提出的基于深度学习的组水平模型优于朴素组模型,并实现了与个体水平模型相似的性能。该模型具有三个关键优势,首先,它在组水平上提供了更丰富的信息。其次,当数据集较大时,组水平模型可能优于个体水平模型。第三,组水平模型可用于初始化个体水平模型,其性能优于随机初始化的个体水平模型。此外,个体嵌入和非线性对于使用组水平模型解码神经成像数据的目标是非常重要的,这将使我们能够更好地利用这种固有的有限资源。
参考文献:Csaky, R., van Es, M. W. J., Jones, O. P., & Woolrich, M. (2023). Group-level brain decoding with deep learning. Human Brain Mapping, 1-15. https://doi.org/10.1002/hbm.26500
小伙伴们关注茗创科技,将第一时间收到精彩内容推送哦~
