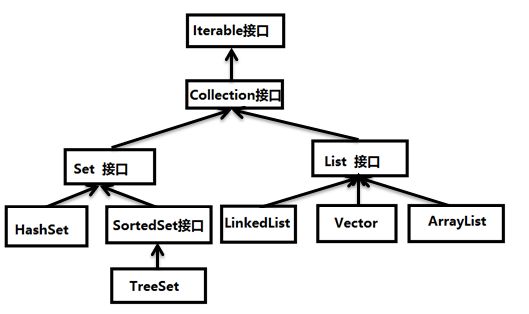
Java的类集(Collection)框架使你的程序处理对象组的方法标准化。类集框架被设计用于适应几个目的。首先,这种框架是高性能的。对基本类集(动态数组,链接表,树和散列表)的实现是高效率的。一般很少需要人工去对这些“数据引擎”编写代码(如果有的话)。第二点,框架必须允许不同类型的类集以相同的方式和高度互操作方式工作。第三点,类集必须是容易扩展和/或修改的。为了实现这一目标,类集框架被设计成包含一组标准的接口。对这些接口,提供了几个标准的实现工具(例如LinkedList,HashSet和TreeSet),通常就是这样使用的。如果你愿意的话,也可以实现你自己的类集。为了方便起见,创建用于各种特殊目的的实现工具。一部分工具可以使你自己的类集实现更加容易。最后,增加了允许将标准数组融合到类集框架中的机制。
Set接口:
集合接口定义了一个集合。它扩展了Collection并说明了不允许复制元素的类集的特性。因此,如果试图将复制元素加到集合中时,add()方法将返回false(不抛异常)。
HashSet:
对于 HashSet 而言,它是基于 HashMap 实现的,HashSet 底层采用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,它只是封装了一个 HashMap 对象来存储所有的集合元素,所有放入 HashSet 中的集合元素实际上由 HashMap 的 key 来保存,而 HashMap 的 value 则存储了一个 PRESENT,它是一个静态的 Object 对象。 HashSet 的绝大部分方法都是通过调用 HashMap 的方法来实现的,因此 HashSet 和 HashMap 两个集合在实现本质上是相同的。
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
TreeSet:
TreeSet是实现了SortedSet接口,SortedSet接口定义了几种方法,使得对集合的处理更加方便。调用first()方法,可以获得集合中的第一个对象。调用last()方法,可以获得集合中的最后一个元素。调用subSet()方法,可以获得排序集合的一个指定了第一个和最后一个对象的子集合。如果需要得到从集合的第一个元素开始的一个子集合,可以使用headSet()方法。如果需要获得集合尾部的一个子集合,可以使用tailSet()方法。
TreeSet支持两种排序方法:自然排序和定制排序。
自然排序:TreeSet调用集合元素的compareTo(Object obj)方法来比较元素之间的大小,然后按照元素升序排列。这就要求对象元素必须实现Comparable接口中的compareTo(Object obj)方法。在自然排序下,TreeSet判断两个对象是否相同的唯一标准:两个对象通过compareTo(Object o)方法比较是否相等:该方法返回0,则认为相等,返回1则认为不相等。java的一些常见的类,例如Character,String,Date等已经实现了Comparable接口。
定制排序:在创建TreeSet集合对象时,需要关联一个Comparator对象,并且实现Comparator中的compare(T obj1,T obj 2)。当通过Comparator对象实现TreeSet的定制排序时,也不可以向TreeSet中添加不同类型的对象(public TreeSet(Comparator comparator))。
public class Text {
public static void main(String[] args) {
TreeSet set = new TreeSet();
set.add("c");
set.add("a");
set.add("ef");
set.add("b");
set.add("e");
set.add("d");
SortedSet subSet1 = set.subSet("b", "e");
System.out.println(subSet1); //[b, c, d]
SortedSet subSet2 = set.headSet("b");
System.out.println(subSet2); //[a]
SortedSet subSet3 = set.tailSet("e");
System.out.println(subSet3); //[e, ef]
}
}
用Set获取数据时只能用迭代或者foreach来取值。
List接口
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下 >标)来访问List中的元素,这类似于Java的数组。
ArrayList:
ArrayList是一个基于数组上的链表,它扩展AbstractList并执行List接口。ArrayList支持可随需要而增长的动态数组。在Java中,标准数组是定长的。在数组创建之后,它们不能被加长或缩短,这也就意味着你必须事先知道数组可以容纳多少元素。但是,你直到运行时才能知道需要多大的数组。为了解决这个问题,类集框架定义了ArrayList。本质上,ArrayList是对象引用的一个变长数组。也就是说,ArrayList能够动态地增加或减小其大小。数组列表以一个原始大小被创建。当超过了它的大小,类集自动增大(当前长度的1.5倍,初始化长度为10,这里可以用初始化长度来进行性能优化)。
当使用ArrayList时,有时想要获得一个实际的数组,这个数组包含了列表的内容。可以通过调用方法toArray()来实现它。(数组转list:Arrays.asList()返回一个受指定数组支持的固定大小的列表)
public class Text {
public static void main(String[] args) {
String[] array = new String[2];
List list2 = Arrays.asList(array);
array[0] = "test2";
System.out.println(list2);
list2.add("test");
System.out.println(list2);
}
}
在add时会抛出UnsupportedOperationException,原因是asList返回的是一个Array的一个内部类而不是真正的ArrayList:
Vector:
同ArrayList一样是一个基于数组上的链表,但是不同的是Vector是同步的。
LinkedList:
与ArrayList一样实现List接口,只是ArrayList是List接口的大小可变数组的实现,LinkedList是List接口链表的实现。基于链表实现的方式使得LinkedList在插入和删除时更优于ArrayList,而随机访问则比ArrayList逊色些。
LinkedList除了它继承的方法之外,LinkedList类本身还定义了一些有用的方法,这些方法主要用于操作和访问列表。使用addFirst()方法可以在列表头增加元素;使用。使用add()方法的add(int, Object)形式,插入项目到指定的位置。调用getFirst()方法可以获得第一个元素。调用getLast()方法可以得到最后一个元素。为了删除第一个元素,可以使用removeFirst()方法;为了删除最后一个元素,可以调用removeLast()方法。
List 在很多方面跟 Array 数组感觉很相似,尤其是 ArrayList,那 List 和数组究竟哪个更好呢?
相似之处:
都可以表示一组同类型的对象
都使用下标进行索引
不同之处:
数组可以存任何类型元素
List 不可以存基本数据类型,必须要包装
数组容量固定不可改变;List 容量可动态增长
数组效率高; List 由于要维护额外内容,效率相对低一些
Map 接口:
Map用于保存具体映射关系的数据,因此Map集合里保存着两组值,一组值用于保存Map里的key,另外一组值用于保存Map里的value,key和value都可以是任意类型的数据。Map的key不允许重复,即同一个Map对象的任何两个key通过equals方法比较总是返回false,每个key只能映射一个value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
HashMap:
对于 HashMap 而言,系统 key-value 当成一个整体进行处理,系统总是根据 Hash 算法来计算 key-value 的存储位置,这样可以保证能快速存、取 Map 的 key-value 对。
当程序执行 put(key, value)方法时,系统将调用key的 hashCode() 方法得到其 hashCode 值——每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值。得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。
取值时,HashMap 可以根据索引、快速地取出该 bucket 里的 Entry;在发生“Hash 冲突”的情况下,单个 bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
Hashtable:
Hashtable(先存在的)几乎可以等价于HashMap。与HashMap相比Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Hashtable是线程安全的,性能上就要比HashMap差一点。
另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
Hashtable不可以接受null(HashMap可以接受为null的键值(key)和值(value))。
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
Entry e = tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}
int hash(Object k) {
if (useAltHashing) {
if (k.getClass() == String.class) {
return sun.misc.Hashing.stringHash32((String) k);
} else {
int h = hashSeed ^ k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
} else {
return k.hashCode();
}
}
ConcurrentHashMap:
ConcurrentHashMap也是题中线程安全的map,他融合了hashtable和hashmap二者的优势。
图左侧清晰的标注出来,lock每次都要锁住整个结构。
ConcurrentHashMap正是为了解决这个问题而诞生的。
ConcurrentHashMap锁的方式是稍微细粒度的。 ConcurrentHashMap将hash表分为16个桶(默认值),诸如get,put,remove等常用操作只锁当前需要用到的桶。
试想,原来 只能一个线程进入,现在却能同时16个写线程进入(写线程才需要锁定,而读线程几乎不受限制,之后会提到),并发性的提升是显而易见的。
更令人惊讶的是ConcurrentHashMap的读取并发,因为在读取的大多数时候都没有用到锁定,所以读取操作几乎是完全的并发操作,而写操作锁定的粒度又非常细,比起之前又更加快速(这一点在桶更多时表现得更明显些)。只有在求size等操作时才需要锁定整个表。
(http://www.importnew.com/22007.html;http://blog.csdn.net/wisgood/article/details/19338693)
附:Collections.synchronizedMap()是Collections提供的同步map方法,他的实现还是很简单的,使用了 synchronized 同步关键字来保证对 Map 的操作是线程安全的。
public static Map synchronizedMap(Map m) {
return new SynchronizedMap<>(m);
}
/**
* @serial include
*/
private static class SynchronizedMap
implements Map, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map m) {
if (m==null)
throw new NullPointerException();
this.m = m;
mutex = this;
}
SynchronizedMap(Map m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
//......
}
性能:ConcurrentHashMap性能是明显优于Hashtable和SynchronizedMap的。