ArcGIS以表格显示分区统计 区域重叠解决方案 / dbf文件合并
ArcGIS以表格显示分区统计 区域重叠解决方案/dbf文件合并
文章目录
- ArcGIS以表格显示分区统计 区域重叠解决方案/dbf文件合并
-
- 1.工具分析
- 2.出现问题的原因
- 3.解决方法
-
-
- 1). 按属性分割
- 2).使用python编程
-
- 语法
- TIPS贴士
- 4).合并dbf表格
-
- 4. 总结
1.工具分析
以表格显示分区统计,是arcmap里空间分析工具中区域分析下的一个子工具。它通过指定要素数据集和栅格数据集,以及对应分区字段,将
汇总另一个数据集区域内的栅格数据值并将结果报告到表。
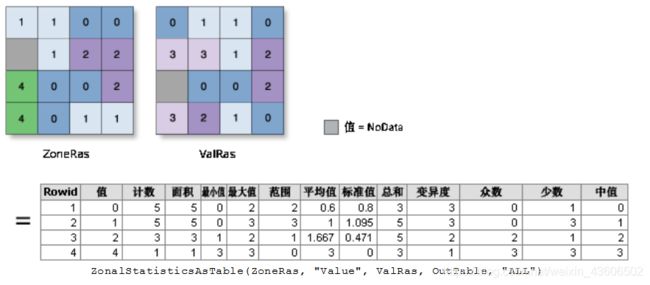
这个工具对于某些无重叠的区域非常好用,比如统计每个行政区域的指数。但是对于某些重叠的数据集区域,就会出现问题。
2.出现问题的原因
我遇到这个问题是因为任务要求计算,全国333个村庄的植被覆盖指数。333个村庄只有点的数据信息,需要先对其做缓冲区分析,得出1km、3km、5km的圆形缓冲区再计算。

然而一些村庄相邻的很近,最后生成的表格里,有的村庄直接消失了。经排查发现,是由于区域重叠导致的,丢失的村庄是因为和别的村庄重叠过多。使用以表格显示分区统计的时候,分区统计会自动剔除掉重叠的部分,以至于有些缓冲区根本没法得到数据值。
3.解决方法
针对这一问题我们没有找到相关的设置能够解决,于是想了一个比较笨的方法,核心思想就是将所有的对象一个一个的计算从而避免重叠,具体步骤如下:
1). 按属性分割
使用ArcGIS10.5版本的按属性分割工具,选择按属性分割(分析工具->提取->按属性分割)工具。在10.5版本直接提供了对应工具,同样也可以使用10.2版本的分割工具,效果应该是一样的。

通过分割,我们得到了333个单独的村庄图层
2).使用python编程
打开ArcMap中的对应python工具(工具栏->地理处理->Python),输入以下代码:
import arcpy
from arcpy import env
from arcpy.sa import *
village=260 #遍历村庄
year=2001 #遍历年数
oup="D:\地理经济2\output3" #输出文件夹
cfileP="D:\地理经济2\hi" #栅格文件夹
inp="D:\地理经济2\V3.gdb\T" #村庄缓冲区文件夹,注意我把其放在了gdb下,文件夹名称下的.gdb一定不能扔掉
for year in range(2001,2002): #选择遍历年数
for village in range (260,334): #选择遍历刚刚生成的村庄
inp1=inp+str(viilage) #每一轮的真实输入路径,一定要str(village),不能直接加
oup1=oup+"\\"+str(year)+"\\"+str(i)+".dbf" #每一轮的输出路径(注意要\\双杠不能单杠,否则报错)
cfileP1=cfileP+"\\"+str(year)+"\\ndvi"+str(year)+"a" #每一轮的栅格路径
outZSat=ZonalStatisticsAsTable(inp1,"OBJECTID",cfileP1,oup1,"DATA","ALL") #调用函数
关于上述的路径,
1) 村庄的缓冲区是放在gdb下的
2) 栅格数据是按年分别放在对应文件夹下的
3) 输出文件夹里,事先准备好了各年份的文件夹,方便数据分类,当然可以根据自己的需要调整
其实原理很简单其实就是调用了其函数,函数的各个值的含义如下
语法
ZonalStatisticsAsTable (in_zone_data, zone_field, in_value_raster, out_table, {ignore_nodata}, {statistics_type})
| 参数 | 说明 | 数据类型 |
|---|---|---|
| in_zone_data | 定义区域的数据集。可通过整型栅格或要素图层来定义区域。 | Raster Layer |
| zone_field | 保存定义每个区域的值的字段。该字段可以是区域数据集的整型字段或字符串型字段 | Field |
| in_value_raster | 含有要计算统计数据的值的栅格。 | Raster Layer |
| out_table | 将包含每个区域中值的汇总的输出表。 | Table |
| ignore_nodata(可选) | 指示值输入中的 NoData 值是否会影响其所落入区域的结果。DATA — 在任意特定区域内,仅使用在输入值栅格中拥有值的像元来确定该区域的输出值。在统计计算过程中,值栅格内的 NoData 像元将被忽略。NODATA — 在任意特定区域内,如果值栅格中存在任何 NoData 像元,则会视作对该区域中所有像元执行统计计算的信息不足;因此,整个区域在输出栅格中都将接收 NoData 值。 | Boolean |
| Statistics_type(可选) | 要计算的统计类型。 ALL —将计算所有的统计数据。这是默认设置. MEAN — 计算值栅格中与输出像元同属一个区域的所有像元的平均值。 MAJORITY — 确定值栅格中与输出像元同属一个区域的所有像元中最常出现的值。 MAXIMUM — 确定值栅格中与输出像元同属一个区域的所有像元的最大值。 MEDIAN — 确定值栅格中与输出像元同属一个区域的所有像元的中值。 MINIMUM — 确定值栅格中与输出像元同属一个区域的所有像元的最小值。 MINORITY — 确定值栅格中与输出像元同属一个区域的所有像元中出现次数最少的值。 RANGE — 计算值栅格中与输出像元同属一个区域的所有像元的最大值与最小值之差。 STD — 计算值栅格中与输出像元同属一个区域的所有像元的标准差。 SUM — 计算值栅格中与输出像元同属一个区域的所有像元的值的总和。 VARIETY — 计算值栅格中与输出像元同属一个区域的所有像元中唯一值的数目。 MIN_MAX —既计算最小值统计数据也计算最大值统计数据。 MEAN_STD —既计算平均值统计数据也计算标准差统计数据。 MIN_MAX_MEAN —同时计算最小值、最大值和平均值统计数据。 |
String |
TIPS贴士
- 命名一定要到位,不管是输入还是输出,可以减少很多麻烦
- 一般来说选择Data和ALL,这里给出各个参考值的实际含义方便之后对数据进行解释
- 输出文件路径一定要加文件格式,这里我选择的是.DBF
- 这里其实还可以多加循环,一次性把1km,3km,5km的缓冲都给算了,但是奈何笔记本算力有限,一下子算很多容易卡,出问题,所以还是不推荐使用很多的for循环嵌套。当然算力很强的随意鸭,
4).合并dbf表格
这样最后的出来的就是一大堆一行的表格,但是实际操作的时候肯定是要一个完整具有所有数据的表格鸭。这里使用了Excel的一段函数,进行修改,则可以合并每个文件夹中所有的dbf文件到一个表格。
但是啊这个效率也是奇慢无比!!不得比统计的快……欢迎提出更好的方法!
操作如下:
- .在文件夹内新建一个excel文件,然后右键sheet,查看代码
- .输入以下代码并且运行
Sub 合并当前目录下所有工作簿的全部工作表()
Dim MyPath, MyName, AWbName
Dim Wb As Workbook, WbN As String
Dim G As Long
Dim Num As Long
Dim BOX As String
Application.ScreenUpdating = False
MyPath = ActiveWorkbook.Path
MyName = Dir(MyPath & "\" & "*.dbf")
AWbName = ActiveWorkbook.Name
Num = 0
Do While MyName <> ""
If MyName <> AWbName Then
Set Wb = Workbooks.Open(MyPath & "\" & MyName)
Num = Num + 1
With Workbooks(1).ActiveSheet.Cells(.Range("B65536").End(xlUp).Row + 2, 1) = Left(MyName, Len(MyName) - 4)
For G = 1 To Sheets.Count
Wb.Sheets(G).UsedRange.Copy .Cells(.Range("B65536").End(xlUp).Row + 1, 1)
Next
WbN = WbN & Chr(13) & Wb.Name
Wb.Close False
End With
End If
MyName = Dir
Loop
Range("B1").Select
Application.ScreenUpdating = True
MsgBox "共合并了" & Num & "个工作薄下的全部工作表。如下:" & Chr(13) & WbN, vbInformation, "提示"
End Sub
上述代码还可以把dbf改为xml,就可以合并excel的表格了,还是有那么一点实用的
- 合并之后的表有表头,全选所有数据,再选择菜单栏上的数据->筛选

点击任意一个表头勾掉除了数字以外的字符即可获得完整表
- 这样完了之后还差原来的村庄数据,所以再连接一次!注意排序!这里的排序是文本排序,即1,10,100酱紫的。命名真的很重要,依次连接生成数据表和原来的村庄信息表,即完成处理。
4. 总结
总的来说这个方法还是挺暴力的,而且算的非常慢噢,包括后面的表格合并,需要耗费大量的时间,确实算不上是个好方法,欢迎交流如果有别的方法~