全链路追踪spring-cloud-sleuth-zipkin
微服务架构下 多个服务之间相互调用,在解决问题的时候,请求链路的追踪是十分有必要的,鉴于项目中采用的spring cloud架构,所以为了方便使用,便于接入等
项目中采用了spring cloud sleuth + zipkin 。现总结如下:
spring cloud sleuth + zipkin 总共分为几个角色:
1、信息上传(上传方式:RABBIT、KAFKA,WEB)
2、信息存储(mysql、es 等)
3、信息展示 (web查询界面)
测试环境中采用了最简单 client端通过http上传到server,server存储到mysql中
一、client端
加入依赖
compile('org.springframework.cloud:spring-cloud-starter-zipkin')
增加配置:

spring:
zipkin:
enabled: true
base-url: http://zipkin-server
sender:
type: web
sleuth:
sampler:
percentage: 1.0
客户端采用type:web方式,上传到 base-url:zipkin-server (zipkin-server 注册到Euraka可以实现多个实例的负载均衡)采样频率 percentage: 1.0 (即100%上传)
二、server端
1)引入依赖:
compile('io.zipkin.java:zipkin-server')
compile('io.zipkin.java:zipkin-autoconfigure-ui')
compile('io.zipkin.java:zipkin-autoconfigure-storage-mysql')
2)增加EnableZipkinServer 注解:
1 @EnableEurekaClient
2 @SpringBootApplication
3 @EnableZipkinServer
4 public class ZipkinServerApplication {
5 public static void main(String[] args) {
6 SpringApplication.run(ZipkinServerApplication.class, args);
7 }
8 }
3)初始化数据库:
CREATE TABLE IF NOT EXISTS zipkin_spans ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL, `id` BIGINT NOT NULL, `name` VARCHAR(255) NOT NULL, `parent_id` BIGINT, `debug` BIT(1), `start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL', `duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations'; ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds'; ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames'; ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range'; CREATE TABLE IF NOT EXISTS zipkin_annotations ( `trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit', `trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id', `span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id', `a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1', `a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB', `a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation', `a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp', `endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address', `endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null', `endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null' ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds'; ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames'; ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces'; ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job'; CREATE TABLE IF NOT EXISTS zipkin_dependencies ( `day` DATE NOT NULL, `parent` VARCHAR(255) NOT NULL, `child` VARCHAR(255) NOT NULL, `call_count` BIGINT, `error_count` BIGINT ) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci; ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
4)配置数据库 (略)
5)为了控制访问权限, 采用Spring security最简单的basic认证
Configuration
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Value("${visit.username}")
private String userName;
@Value("${visit.password}")
private String password;
@Override
protected void configure(HttpSecurity http) throws Exception {
http.csrf().disable()
.authorizeRequests()
.antMatchers("/health").permitAll()
.antMatchers("/zipkin").hasRole("ADMIN")
.anyRequest().authenticated()
.and()
.httpBasic();
}
6)将服务发布到k8s集群中,同是采用 NodePord方式 暴露端口出去,不用通过网关就可以访问
三、信息查询
1、主页 可以按条件过滤
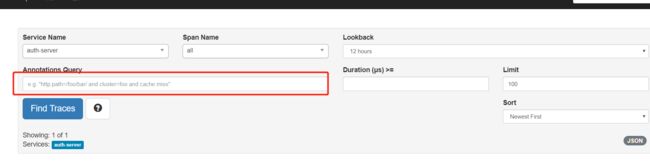
可以按条件进行过滤~ 请求路径方法 等,这里最重要的是可以网关中加入自定义 tag 例如手机号 用户号等自定义信息 ~
2、详细信息服务之间的调用链路
