【大数据】Apache Hive数仓(学习笔记)
一、数据仓库基础概念
1、数仓概述
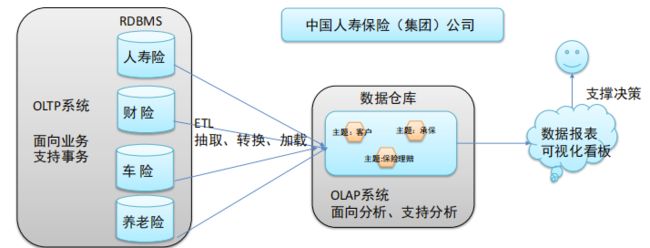
数据仓库(数仓、DW):一个用于存储、分析、报告的数据系统。
OLAP(联机分析处理)系统:面向分析、支持分析的系统。
数据仓库的目的:构建面向分析的集成化数据环境,分析结果为企业提供决策支持。
- 数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统
- 同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用
2、数仓特征
面向主题:主题是一个抽象的概念,是较高层次上数据综合、归类并进行分析利用的抽象。
集成性:主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。需要集成到数仓主题下。(字段重复、字长不一致等)
非易失性(非易变性):数据仓库是分析数据的平台,而不是创造数据的平台。数据仓库中一般有大量的查询操作,但修改和删除操作很少。
时变性:数据仓库的数据需要随着时间更新,以适应决策的需要。
二、Apache Hive 概念
1、Apache Hive 概述
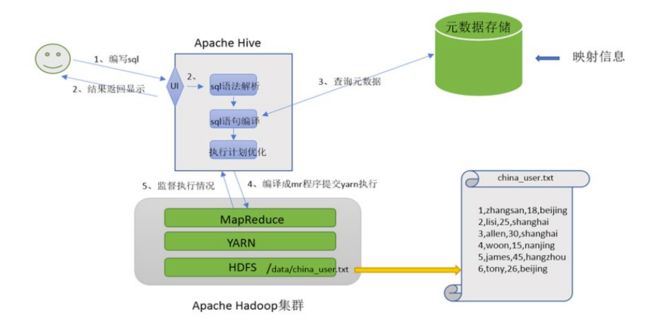
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。

2、Hive和Hadoop关系
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
Hive的优势在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
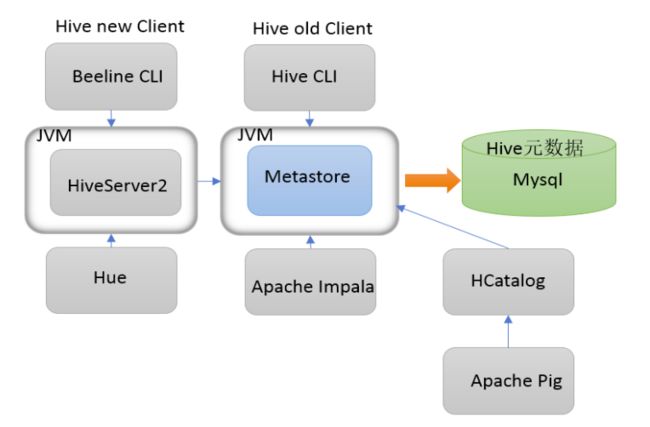
3、Apache Hive 架构、组件
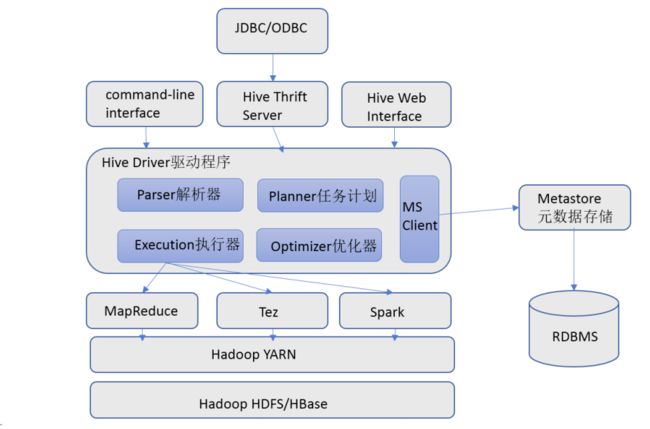
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- CLI(command line interface):shell命令行。
- Hive中的Thrift服务器:允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。
- WebGUI:通过浏览器访问Hive。
- 元数据存储:存储在关系数据库(如 mysql/derby)中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- Driver驱动程序(语法解析器、计划编译器、优化器、执行器):完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
- 执行引擎:Hive通过执行引擎(MapReduce、Tez、Spark)处理数据。
三、Apache Hive安装部署
1、Apache Hive元数据
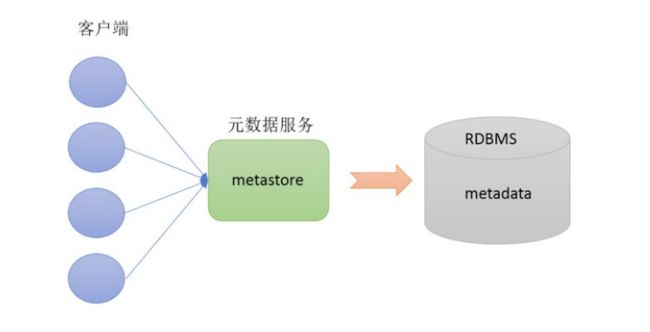
元数据:描述数据的数据,主要是描述数据属性的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata:Hive的元数据。用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。元数据存储在关系型数据库中。
Hive Metastore:元数据服务。用于管理metadata元数据。
metastore配置方式:内嵌模式、本地模式、远程模式。
| 内嵌模式 | 本地模式 | 远程模式 | |
|---|---|---|---|
| Metastore单独配置、启动 | 否 | 否 | 是 |
| Metadata存储介质 | Derby | Mysql | Mysql |
2、Apache Hive部署实战
1)Hadoop与Hive整合
因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据。需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行。
修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
2)上传安装包
node1安装即可
tar zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin/ hive
# 解决Hive与Hadoop之间guava版本差异
cd /export/server/apache-hive-3.1.2-bin/
rm -rf lib/guava-19.0.jar
cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar/lib/
3)修改hive-env.sh
cd /export/server/apache-hive-3.1.2-bin/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/export/server/hadoop-3.3.0
export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib
4)新增hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&u
seSSL=false&useUnicode=true&characterEncoding=UTF-8
value>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>hadoopvalue>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>node1value>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://node1:9083value>
property>
<property>
<name>hive.metastore.event.db.notification.api.authname>
<value>falsevalue>
property>
configuration>
5)添加驱动、初始化
上传MySQL JDBC驱动到Hive安装包lib路径下 mysql-connector-java-5.1.32.jar
初始化Hive的元数据
cd /export/server/apache-hive-3.1.2-bin/
bin/schematool -initSchema -dbType mysql -verbos
# 初始化成功会在mysql中创建74张表
6)metastore服务启动方式
前台启动
# 前台启动
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore
# 前台启动开启debug日志
/export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf
hive.root.logger=DEBUG,console
# 前台启动关闭方式 ctrl+c结束进程
后台启动:输出日志信息在/root目录下nohup.out
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
# 后台挂起启动 结束进程
# 使用jps查看进程 使用kill -9 杀死进程
# nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下
3、Apache Hive客户端使用
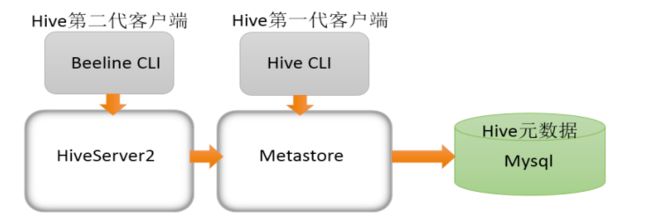
hive(第一代):$HIVE_HOME/bin/hive,是一个 shellUtil。可用于以交互或批处理模式运行Hive查询,用于Hive相关服务的启动,比如metastore服务。
beeline(第二代):$HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,性能加强安全性提高。
启动HiveServer2之前必须先首先启动metastore。
hiveserver2服务启动之后需要稍等一会才可以对外提供服务。
#先启动metastore服务 然后启动hiveserver2服务
nohup /export/servers/hive/bin/hive --service metastore &
nohup /export/servers/hive/bin/hive --service hiveserver2 &
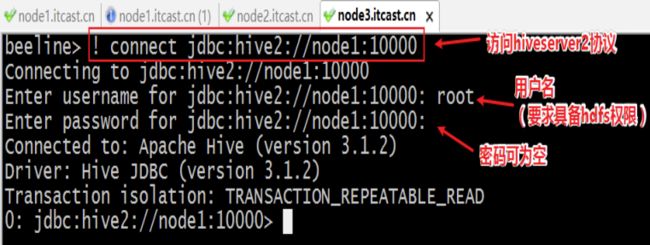
beeline连接配置说明
Hive可视化客户端:DataGrip(jetbrains大爹出的)