刷LeetCode必备的C++STL基础
写在前面:这篇笔记是由本人原创,兄弟萌如果觉得不错的话,可以点个关注或收藏,方便以后查阅呀。
文章目录
- 前言
- 一、STL概述:六大模块
- 二、输入输出
-
- 1. C++标准输入输出
-
- 1.1 特点
- 1.2 导入
- 1.3 使用
- 2. C标准输入输出
-
- 2.1 特点
- 2.2 导入
- 2.3 使用
- 三、vector:变长数组容器
-
- 1. 底层
- 2. 作用
- 3. 导入
- 4. 定义
- 5. vector迭代器
-
- 5.1 迭代器定义
- 5.2 迭代器运算
-
- 5.2.1 自增
- 5.2.2 自减
- 5.2.3 移位
- 5.2.4 比较
- 5.3 使用迭代器循环遍历容器
- 6. 访问元素
-
- 6.1 下标访问
- 6.2 迭代器访问
- 7. 常用方法
-
- 7.1 vi.begin()
- 7.2 vi.end()
- 7.3 vi.push_back()
- 7.4 vi.pop_back()
- 7.5 vi.size()
- 7.6 vi.clear()
- 7.7 vi.insert()
- 7.8 vi.erase()
-
- 7.8.1 vi.erase(it)
- 7.8.2 vi.erase(first, last)
- 四、set:集合容器
-
- 1. 底层和特性
- 2. 作用
- 3. 导入
- 4. 定义
- 5. set迭代器
-
- 5.1 迭代器定义
- 5.2 迭代器运算
-
- 5.2.1 自增
- 5.2.2 自减
- 5.2.3 比较
- 5.3 使用迭代器循环遍历容器
- 6. 访问元素
- 7. 常用方法
-
- 7.1 st.begin()
- 7.2 st.end()
- 7.3 st.size()
- 7.4 st.clear()
- 7.5 st.insert()
- 7.6 st.find()
- 7.7 st.erase()
-
- 7.7.1 st.erase(it)
- 7.7.2 st.erase(value)
- 7.7.3 st.erase(first, last)
- 五、string:字符串容器
-
- 1. 底层
- 2. 作用
- 3. 导入
- 4. 定义
- 5. 字符串输入输出
-
- 5.1 字符串输入
- 5.2 字符串输出
- 6. string迭代器
-
- 6.1 迭代器定义
- 6.2 迭代器运算
-
- 6.2.1 自增
- 6.2.2 自减
- 6.2.3 移位
- 6.2.4 比较
- 6.3 使用迭代器循环遍历容器
- 7. 访问元素
-
- 7.1 下标访问
- 7.2 迭代器访问
- 8. 常用方法
-
- 8.1 str.begin()
- 8.2 str.end()
- 8.3 str.c_str()
- 8.4 重载运算符
- 8.5 str.length()或str.size()
- 8.6 str.clear()
- 8.7 str.insert()
-
- 8.7.1 str1.insert(int pos, str2)
- 8.7.2 str.insert(it1, it2, it3)
- 8.8 str.erase()
-
- 8.8.1 str.erase(it)
- 8.8.2 str.erase(first, last)
- 8.8.3 str.erase(int pos, length)
- 8.9 str.substr(int pos, len)
- 8.10 str.find()
-
- 8.10.1 str1.find(str2)
- 8.10.2 str1.find(str2, int pos)
- 8.11 str.replace()
-
- 8.11.1 str1.replace(int pos, len, str2)
- 8.11.2 str1.replace(it1, it2, str2)
- 六、map:映射容器
-
- 1. 底层和特性
- 2. 作用
- 3. 导入
- 4. 定义
- 5. map迭代器
-
- 5.1 迭代器定义
- 5.2 迭代器运算
-
- 5.2.1 自增
- 5.2.2 自减
- 5.2.3 比较
- 5.3 使用迭代器循环遍历容器
- 6. 访问元素
-
- 6.1 下标访问
- 6.2 迭代器访问
- 7. 常用方法
-
- 7.1 mp.begin()
- 7.2 mp.end()
- 7.3 mp.size()
- 7.4 mp.clear()
- 7.5 插入
-
- 7.5.1 mp[key] = value;
- 7.5.2 mp.insert(pair对象)
- 7.6 mp.find()
- 7.7 mp.erase()
-
- 7.7.1 mp.erase(it)
- 7.7.2 mp.erase(first, last)
- 七、queue:队列容器
-
- 1. 特性
- 2. 作用
- 3. 导入
- 4. 定义
- 5. queue没有迭代器
- 6. 访问元素
-
- 6.1 q.front()
- 6.2 q.back()
- 7. 常用方法
-
- 7.1 q.front()
- 7.2 q.back()
- 7.3 q.push()
- 7.4 q.pop()
- 7.5 q.size()
- 7.6 q.empty()
- 八、deque:双端队列容器
- 九、priority_queue:优先队列容器
-
- 1. 底层和特性
- 2. 作用
- 3. 导入
- 4. 定义
- 5. priority_queue没有迭代器
- 6. 访问元素
- 7. 常用方法
-
- 7.1 q.top()
- 7.2 q.push()
- 7.4 q.pop()
- 7.5 q.size()
- 7.6 q.empty()
- 8. 自定义优先级
-
- 8.1 基本数据类型优先级设置
- 8.2 内置比较类:less和greater
-
- 8.2.1 less类
- 8.2.2 greater类
- 8.2.3 总结
- 8.3 结构体优先级设置
-
- 8.3.1 在结构体内部定义友元函数
- 8.3.2 在结构体外部定义cmp比较类
- 十、stack:栈容器
-
- 1. 底层和特性
- 2. 作用
- 3. 导入
- 4. 定义
- 5. stack无迭代器
- 6. 访问元素
- 7. 常用方法
-
- 7.1 st.top()
- 7.2 st.push()
- 7.3 st.pop()
- 7.4 st.size()
- 7.5 st.empty()
- 十一、pair:成对
-
- 1. 底层
- 2. 作用
- 3. 导入
- 4. 定义
- 5. 访问元素
- 6. 常用方法
- 十二、algorithm:算法库
-
- 1. 简介
- 2. 导入
- 3. 常用函数
-
- 3.1 max()
- 3.2 min()
- 3.3 abs()
- 3.4 swap()
- 3.5 reverse()
- 3.6 next_permutation()
- 3.7 fill()
- 3.8 sort()
-
- 3.8.1 自定义cmp()函数详解
-
- 3.8.1.1 从小到大排序
- 3.8.1.2 从大到小排序
- 3.8.2 结构体数组排序
- 3.8.3 容器排序
- 3.9 lower_bound()和upper_bound()
-
- 3.9.1 lower_bound()
- 3.9.2 upper_bound()
- 3.9.3 总结
- 3.9.4 获取返回位置的下标
前言
最近在刷LeetCode上的算法题目,如果想要游刃有余的做这些题目,掌握一门高级计算机编程语言的函数库是必不可少的,C++的标准模板库(STL)是一个不错的选择。为了记录这几天的学习成果,同时方便今后的查阅,遂写下这篇STL的学习笔记。
C++的STL博大精深,内容非常广泛,这篇笔记按照重要程度只对常用的容器和算法做简单而必要的介绍。
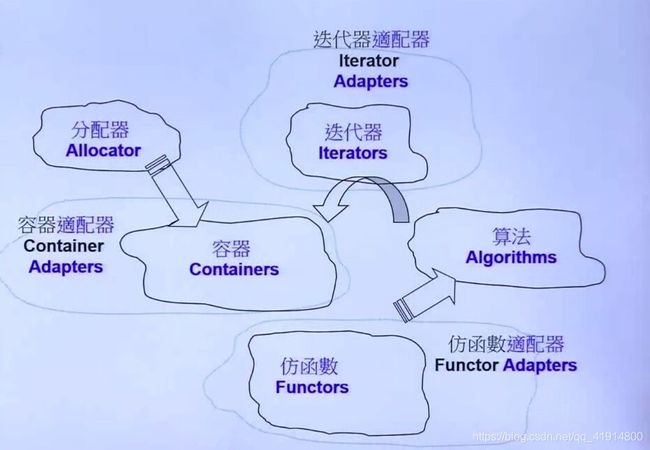
一、STL概述:六大模块
C++标准模板库由6大模块组成:分配器、容器、迭代器、算法、仿函数和适配器。
其中,容器container用来存储数据元素,迭代器iterator可以理解为类指针,即封装的指针,算法algorithm通过迭代器操纵容器中的元素。一个简单例子就是:sort(it1, it2)是STL中的一个排序算法,它通过迭代器it1,it2来确定容器的数据范围[it1, it2),从而对容器中的这部分数据进行排序(操纵)。
二、输入输出
1. C++标准输入输出
cin负责输入,cout负责输出。
1.1 特点
cin和cout不用设置输入输出数据的格式,可以直接进行输入输出,但是开销比较大,有时候在LeetCode上容易超时,所以推荐使用C语言的标准输入输出函数scanf和printf。
1.2 导入
#include < iostream >
using namespace std;
1.3 使用
输入1:cin >> var1 >> var2 >> var3 >> ... ;
可以用回车换行作为变量之间的分隔符。
输入2:cin.getline(str, 100)
读取一行,str是缓冲区的起始位置,100是缓冲区的大小,如定义一个缓冲区数组:char str[100];
输入3:getline(cin, str)
读取一行,这里str是一个string字符串对象。
输出:cout << var1 << var2 << "\n" << endl;
输出换行符有两种方式:
方式1:输出 “\n”
方式2:输出 endl
2. C标准输入输出
2.1 特点
必须指定格式,效率比cin、cout高,推荐使用。
2.2 导入
#include
2.3 使用
输入:scanf("%d%f%c", &var1, &var2, &var3);
输入一个整数、小数、字符,可以以空格为分隔符,回车换行作为结束符。
输出:printf("%d, %f, %c", var1, var2, var3);
输出一个整数、小数、字符并以逗号为分隔符。
三、vector:变长数组容器
1. 底层
底层是顺序结构——数组,当容量不足时,重新分配一个更大的连续数组。
2. 作用
存储不定长数据;
以邻接表的方式存储图(二维vector)。
3. 导入
#include < vecrot >
using namespace std;
4. 定义
形式1:vector< typename > vi;
可以理解为定义了一个变长数组:vi[size],size可变。
形式2:定义一个vector数组:
vector< typename > a[100];
形式3:定义一个二维vector:
vector< vector< int > > vi;
形式2与形式3的区别在于:前者一维长度固定为100,而后者两个维度均是可变的。
5. vector迭代器
5.1 迭代器定义
vector< typename >::iterator it;
相当于是一个类指针。
5.2 迭代器运算
5.2.1 自增
形式1:it ++;
形式2:++ it;
5.2.2 自减
形式1:it --;
形式2:-- it;
5.2.3 移位
it + n,即迭代器加整数,表示迭代器it所对应位置后n位对应的迭代器,如:vi.begin() + i指向vi[i]。
it - n,即迭代器减整数,表示迭代器it所对应位置前n位对应的迭代器。
只有容器vector和string的迭代器才支持这种迭代器加减整数的移位操作。
5.2.4 比较
迭代器不支持it < vi.end()的比较操作,而只能是:it != vi.end(),用在循环中判断是否到达容器末尾。
5.3 使用迭代器循环遍历容器
for (vector< int >::iterator it = vi.begin(); it != vi.end(); it ++){pass}
6. 访问元素
通过下标和迭代器两种方法访问。
6.1 下标访问
下标从0开始,vi[i]返回第i + 1个元素。
6.2 迭代器访问
如:
vector< int >::iterator it = vi.begin() + i;
*it 代表第i + 1个元素。
7. 常用方法
假设vector< int > vi;
7.1 vi.begin()
返回第一个元素位置对应的迭代器。
7.2 vi.end()
返回最后一个元素后一个位置对应的迭代器,通常作为循环的结束标志。
7.3 vi.push_back()
vi.push_back(x)
末尾添加x。
7.4 vi.pop_back()
vi.pop_back()
删除末尾元素。
7.5 vi.size()
vi.size()
返回元素个数。
7.6 vi.clear()
vi.clear()
清空所有元素。
7.7 vi.insert()
vi.insert(it, x)
在迭代器it对应的位置插入x,后面元素均后移一位。
7.8 vi.erase()
7.8.1 vi.erase(it)
vi.erase(it)
删除迭代器it指向的单个元素。
7.8.2 vi.erase(first, last)
vi.erase(first, last)
删除前闭后开区间[first, last)内的所有元素。
四、set:集合容器
1. 底层和特性
内部使用红黑树(一种平衡二叉查找树)实现。
特性1:自动去重,元素不重复。
特性2:自动排序,即把它看做是一个序列,这个序列从小到大排列。
2. 作用
自动去重并按升序排列。
3. 导入
#include < set >
using namespace std;
4. 定义
形式1:set< typename > st;
形式2:定义一个set数组:
set< typename > a[100];
形式3:定义一个嵌套集合:
set< vector< int > > st;
5. set迭代器
5.1 迭代器定义
set< typename >::iterator it;
相当于是一个类指针。
5.2 迭代器运算
5.2.1 自增
形式1:it ++;
形式2:++ it;
5.2.2 自减
形式1:it --;
形式2:-- it;
只有容器vector和string的迭代器才支持这种迭代器加减整数的移位操作(因为它们支持下标访问元素),set的迭代器不支持这种操作。
5.2.3 比较
迭代器不支持it < st.end()的比较操作,而只能是:it != st.end(),用在循环中判断是否到达容器末尾。
5.3 使用迭代器循环遍历容器
for (set< int >::iterator it = st.begin(); it != st.end(); it ++){pass}
6. 访问元素
只能通过迭代器访问。
如:
set< int >::iterator it = st.begin() + i;
*it 代表第i + 1个元素。
7. 常用方法
假设set< int > st;
7.1 st.begin()
返回第一个元素位置对应的迭代器。
7.2 st.end()
返回最后一个元素后一个位置对应的迭代器,通常作为循环的结束标志。
7.3 st.size()
st.size()
返回元素个数。
7.4 st.clear()
st.clear()
清空所有元素。
7.5 st.insert()
st.insert(x)
插入元素x,自动去重和递增排序。
时间复杂度:O(logN)。
7.6 st.find()
st.find(value)
查找value,返回对应的迭代器。
时间复杂度:O(logN)。
7.7 st.erase()
7.7.1 st.erase(it)
st.erase(it)
删除迭代器it指向的单个元素。
通常与st.find(x)搭配使用,如:
st.erase(st.find(x)) 删除元素x。
7.7.2 st.erase(value)
st.erase(value)
删除指定元素值value。
7.7.3 st.erase(first, last)
st.erase(first, last)
删除前闭后开区间[first, last)内的所有元素。
五、string:字符串容器
1. 底层
底层是顺序结构——字符数组。
2. 作用
存储字符串。
3. 导入
#include < string >
using namespace std;
注意:与#include 不一样。
4. 定义
形式1:string str;
可以理解为定义了一个字符数组:char str[size],size可变。
形式2:初始化字符串:
string str = "abcd";
5. 字符串输入输出
5.1 字符串输入
cin >> str; 回车换行标志输入结束。
5.2 字符串输出
cout << str;
6. string迭代器
6.1 迭代器定义
string::iterator it;
相当于是一个类指针。
6.2 迭代器运算
6.2.1 自增
形式1:it ++;
形式2:++ it;
6.2.2 自减
形式1:it --;
形式2:-- it;
6.2.3 移位
it + n,即迭代器加整数,表示迭代器it所对应位置后n位对应的迭代器,如:str.begin() + i指向str[i]。
it - n,即迭代器减整数,表示迭代器it所对应位置前n位对应的迭代器。
只有容器vector和string的迭代器才支持这种迭代器加减整数的移位操作。
6.2.4 比较
迭代器不支持it < str.end()的比较操作,而只能是:it != str.end(),用在循环中判断是否到达容器末尾。
6.3 使用迭代器循环遍历容器
for (string::iterator it = str.begin(); it != str.end(); it ++){pass}
7. 访问元素
通过下标和迭代器两种方法访问。
7.1 下标访问
下标从0开始,str[i]返回第i + 1个字符。
7.2 迭代器访问
如:
str::iterator it = str.begin() + i;
*it 代表第i + 1个字符。
8. 常用方法
假设string str;
8.1 str.begin()
返回第一个元素位置对应的迭代器。
8.2 str.end()
返回最后一个元素后一个位置对应的迭代器,通常作为循环的结束标志。
8.3 str.c_str()
str.c_str();
返回字符串对应的C字符数组,以’\0’结尾,对应的输出格式符为%s。
8.4 重载运算符
字符串支持有以下运算符:
连接运算符:
str1 = str2 + str3; 连接字符串
str1 += str2; 连接字符串并赋值
比较运算符:比较规则:字典序
str1 == str2
str1 != str2
str1 < str2
str1 <= str2
str1 > str2
str1 >= str2
8.5 str.length()或str.size()
返回元素个数。
8.6 str.clear()
str.clear()
清空所有元素。
8.7 str.insert()
8.7.1 str1.insert(int pos, str2)
str1.insert(int pos, str2)
从位置pos处开始插入字符串str2。
8.7.2 str.insert(it1, it2, it3)
str.insert(it1, it2, it3)
从迭代器it1指定的位置开始插入[it2, it3)确定的字符串。
8.8 str.erase()
8.8.1 str.erase(it)
str.erase(it)
删除迭代器it指向的单个字符。
8.8.2 str.erase(first, last)
str.erase(first, last)
删除前闭后开区间[first, last)内的所有元素。
8.8.3 str.erase(int pos, length)
str.erase(pos, length)
从位置pos处开始删除length个字符。
8.9 str.substr(int pos, len)
返回一个子串,长度为len。
8.10 str.find()
模式匹配方法
时间复杂度:O(m * n),m、n是两个字符串的长度。
8.10.1 str1.find(str2)
str1.find(str2)
若存在,返回第一次出现的位置。
若不存在,返回常量string::npos,即-1。
8.10.2 str1.find(str2, int pos)
str1.find(str2, pos)
从位置pos处开始查找str2。
若存在,返回第一次出现的(绝对)位置。
若不存在,返回常量string::npos,即-1。
8.11 str.replace()
会改变源字符串。
8.11.1 str1.replace(int pos, len, str2)
str1.replace(int pos, len, str2)
将从位置pos处开始的len个字符替换为字符串str2。
8.11.2 str1.replace(it1, it2, str2)
str1.replace(int pos, len, str2)
将区间[it1, it2)内的字符替换为字符串str2。
六、map:映射容器
1. 底层和特性
内部基于pair对象(后面会介绍,可以简单为由键值对组成的二元结构体)和红黑树(一种平衡二叉查找树)实现。
特性1:键key唯一。
特性2:按键key自动去重。
特性3:自动排序,即把它看做是一个序列,这个序列从小到大排列。
2. 作用
建立字符串与整数间的映射;
判断大整数或其他数据是否存在。
3. 导入
#include < map >
using namespace std;
4. 定义
形式1:map< typename1, typename2 > mp;
如:将set容器映射为字符串,map
5. map迭代器
5.1 迭代器定义
map< typename1, typename2 >::iterator it;
相当于是一个类指针。
5.2 迭代器运算
5.2.1 自增
形式1:it ++;
形式2:++ it;
5.2.2 自减
形式1:it --;
形式2:-- it;
只有容器vector和string的迭代器才支持这种迭代器加减整数的移位操作(因为它们支持下标访问元素),map的迭代器不支持这种操作。
5.2.3 比较
迭代器不支持it < mp.end()的比较操作,而只能是:it != mp.end(),用在循环中判断是否到达容器末尾。
5.3 使用迭代器循环遍历容器
for (map< string, int >::iterator it = mp.begin(); it != mp.end(); it ++){pass}
6. 访问元素
通过下标和迭代器两种方法访问。
6.1 下标访问
这里下标是键key,如:mp[‘c’]代表对应值value = 20。
6.2 迭代器访问
如:
map< int >::iterator it = mp.begin() + i;
迭代器it指向第i + 1个键值对,
it -> first 代表键key,
it -> second 代表值value。
7. 常用方法
假设map< string, int > mp;
7.1 mp.begin()
返回第一个键值对对应的迭代器。
7.2 mp.end()
返回最后一个键值对后一个位置对应的迭代器,通常作为循环的结束标志。
7.3 mp.size()
mp.size()
返回元素个数。
7.4 mp.clear()
mp.clear()
清空所有元素。
7.5 插入
7.5.1 mp[key] = value;
mp['c'] = 20;
若存在键key = ‘c’,则修改其值为20;
若不存在,则插入键值对(‘c’, 20),并递增排序。
7.5.2 mp.insert(pair对象)
插入pair对象对应的键值对。
pair对象见后面的介绍。
7.6 mp.find()
mp.find(key)
查找键key,返回对应的迭代器,而不是对应值value。
时间复杂度:O(logN)。
7.7 mp.erase()
7.7.1 mp.erase(it)
mp.erase(it)
删除迭代器it指向的单个键值对。
通常与mp.find(key)搭配使用,如:
mp.erase(mp.find(key)) 删除key对应的键值对。
7.7.2 mp.erase(first, last)
mp.erase(first, last)
删除前闭后开区间[first, last)内的所有键值对。
七、queue:队列容器
1. 特性
特性:先进先出。
2. 作用
广度优先搜索。
3. 导入
#include < queue >
using namespace std;
4. 定义
queue< typename > q;
5. queue没有迭代器
因为queue限制只能操作两端元素,所以没有迭代器用来遍历整个队列元素。
6. 访问元素
只能通过API访问。
6.1 q.front()
q.front()
返回队首元素(出口)。
6.2 q.back()
q.back()
返回队尾元素(入口)。
7. 常用方法
假设queue< int > q;
7.1 q.front()
q.front()
返回队首元素(出口)。
使用前最好用q.empty()判断是否为空。
7.2 q.back()
q.back()
返回队尾元素(入口)。
使用前最好用q.empty()判断是否为空。
7.3 q.push()
q.push(x)
入队,队尾插入x。
7.4 q.pop()
q.pop()
出队,删除队首元素。
7.5 q.size()
q.size()
返回元素个数。
7.6 q.empty()
q.empty()
判断是否为空。
八、deque:双端队列容器
首尾均可以插入和删除,API跟queue类似,省略。
九、priority_queue:优先队列容器
1. 底层和特性
底层是用堆实现。
特性:优先级最大元素置于队首,队尾负责入队(插入)。
2. 作用
贪心问题;
优化迪杰斯特拉算法。
3. 导入
#include < queue >
using namespace std;
4. 定义
形式1:priority_queue< typename > q;
形式2:见 8. 自定义优先级。
5. priority_queue没有迭代器
因为priority_queue限制只能操作两端元素,所以没有迭代器用来遍历整个优先队列元素。
6. 访问元素
只能通过API访问队首元素。
``q.top() 返回队首优先级最高的元素。
7. 常用方法
假设priority_queue< int > q;
7.1 q.top()
q.top()
返回队首优先级最高的元素(出口)。
使用前最好用q.empty()判断是否为空。
7.2 q.push()
q.push(x)
入队,队尾插入x。
7.4 q.pop()
q.pop()
出队,删除队首元素。
7.5 q.size()
q.size()
返回元素个数。
7.6 q.empty()
q.empty()
判断是否为空。
8. 自定义优先级
8.1 基本数据类型优先级设置
默认数据大的优先级高。即:
priority_queue< int > q;等价于priority_queue< int, vector
其中,int表示队列元素是整型,vector< int >表示底层承载数据结构为vector容器,less< int >是一个比较类,表示数据大的优先级高。
8.2 内置比较类:less和greater
8.2.1 less类
less< int >类可以理解为是一个比较函数:less(int a, int b),它接受两个参数a、b,并且底层使用小于号<比较参数a和b,即a < b,这样当比较结果为true时,返回右值b(较大值),当比较结果为false时,返回左值a(仍然是较大值),即:只返回较大值,所以当优先队列使用less< int >作为参数时,认为数据大的优先级高。
8.2.2 greater类
greater< int >类可以理解为是一个比较函数:greater(int a, int b),它接受两个参数a、b,并且底层使用大于号>比较参数a和b,即a > b,这样当比较结果为true时,返回右值b(较小值),当比较结果为false时,返回左值a(仍然是较小值),即:只返回较小值,所以当优先队列使用greater< int >作为参数时,认为数据小的优先级高。
8.2.3 总结
可以理解为:无论内置less类、greater类还是自定义cmp类,它们都接受参数a、b,并且用大于号或小于号比较它们。三个类均是:当比较结果为true时,就返回右值放入vector< int >中,比较结果为false时,就返回左值放入vector< int >中。此时可以通过返回值是两者中的大值还是小值判断priority_queue队列中是认为数据大的优先级高还是数据小的优先级高。
8.3 结构体优先级设置
8.3.1 在结构体内部定义友元函数
如:
struct fruit{
string name;
int price;
//定义友元函数,无论定义数字小的优先级高还是数字大的优先级高,只能重载小于号<,并且返回值类型为bool。
friend bool operator < (const fruit &f1, const fruit &f2){//当结构体数据比较大时,可以使用引用节省时间。
return f1.price < f2.price;//按照8.2.3 总结,始终返回较大值
或
return f1.price > f2.price;//按照8.2.3 总结,始终返回较小值
}
};
定义:priority_queue< fruit > q;
或
priority_queue< fruit, vector
8.3.2 在结构体外部定义cmp比较类
struct cmp{
//重载小括号(),可以理解为遇到cmp(a, b)时调用此函数。
bool operator () (const fruit &f1, const fruit &f2){
return f1.price < f2.price;//按照8.2.3 总结,始终返回较大值
或
return f1.price > f2.price;//按照8.2.3 总结,始终返回较小值
}
定义:priority_queue< fruit, vector
十、stack:栈容器
1. 底层和特性
底层是顺序结构——数组。
特性:后进先出。
2. 作用
模拟递归。
3. 导入
#include < stack >
using namespace std;
4. 定义
stack< typename > st;
5. stack无迭代器
因为stack的特性是后进先出,所以没有迭代器用来遍历整个容器元素。
6. 访问元素
只能通过API访问栈顶元素。
st.top() 返回栈顶元素。
7. 常用方法
假设stack< int > st;
7.1 st.top()
返回栈顶元素。
7.2 st.push()
st.push(x)
栈顶添加x。
7.3 st.pop()
st.pop()
删除栈顶元素。
7.4 st.size()
st.size()
返回元素个数。
7.5 st.empty()
st.empty()
判断是否为空。
十一、pair:成对
1. 底层
可以理解为是一个内部有两个元素的结构体,即:
struct pair{
typename1 first;
typename2 second;
};
2. 作用
代替二元结构体;
作为map的键值对进行插入,见 六、7.5.2
如:
mp.insert(make_pair("hello", 5))
或
mp.insert(pair< string, int > ("hello", 5))。
3. 导入
#include < utility >
using namespace std;
或
#include < map >
using namespace std;
因为map内部实现涉及了pair,所以添加map头文件会自动添加utility头文件。
4. 定义
形式1:pair< typename1, typename2 > p;
形式2:初始化 pair< string, int > p("hello", 5);
形式3:创建临时对象,即省去对象名 pair< string, int > ("hello", 5)
形式4:使用函数创建临时对象 make_pair("hello", 5)
5. 访问元素
正常结构体访问方法。
p.first 访问第一个字段;
p.second 访问第二个字段。
6. 常用方法
假设pair< typename1, typename2 > p1, p2;
比较运算符:
比较规则:先比较第一个字段first,当first字段相等时,再比较第二个字段second。
p1 == p2
p1 != p2
p1 < p2
p1 <= p2
p1 > p2
p1 >= p2
十二、algorithm:算法库
1. 简介
C++STL中许多常用函数都封装在algorithm库中。
2. 导入
#include < algorithm >
using namespace std;
3. 常用函数
3.1 max()
max(x, y)
返回两个参数中的较大值。
只能接受两个参数,如果想要比较三个数中的最大值,可以如下:max(x, max(y, z))
3.2 min()
min(x, y)
返回两个参数中的较小值。
只能接受两个参数,如果想要比较三个数中的最小值,可以如下:
min(x, min(y, z))
3.3 abs()
abs(x)
返回整数x的绝对值。
只能接受整数参数,如果想要返回小数的绝对值,可以如下:
#include < math.h>
fabs(x),x可以是小数。
3.4 swap()
swap(x, y)
交换x、y的值。
3.5 reverse()
reverse(it1, it2)
将容器或数组在区间[it1, it2)之间的元素值反转。
当是数组时,it1、it2是数组指针;
当是容器时,it1、it2是容器迭代器;
3.6 next_permutation()
next_permutation(it1, it2)
求出区间[it1, it2)序列在全排列下的下一个序列,并且用这个新序列更新原序列[it1, it2),如果当前序列不是全排列的最后一个序列,返回true,否则,返回false。
如:由1、2、3组成的全排列是:
123
132
213
231
312
321
int a[10] = {1, 2, 3};
do{
printf("%d%d%d\n", a[0], a[1], a[2]);
}while(next_permutation(a, a + 3));
3.7 fill()
fill(it1, it2, value)
将数组(指针)或容器(迭代器)区间[it1, it2)内的元素设置为value。
3.8 sort()
规避了经典快排可能出现的会导致实际复杂度退化到O(n^2)的极端情况。
sort(it1, it2, 比较函数名)
比较函数是可选项,默认为递增排序。
排序的前提是元素具有可比性,结构体本身没有大小关系,因此需要自定义比较规则。
3.8.1 自定义cmp()函数详解
3.8.1.1 从小到大排序
//返回值必须为bool型
bool cmp(int x, int y){
return x < y;
}
可以理解为:如果返回为true,x和y相对位置不变,x放在y前面,如果返回为false,x和y交换位置,y放在x前面,即:始终是较小值放在前面,较大值放在后面,所以从小到大排序。
3.8.1.2 从大到小排序
//返回值必须为bool型
bool cmp(int x, int y){
return x > y;
}
可以理解为:如果返回为true,x和y相对位置不变,x放在y前面,如果返回为false,x和y交换位置,y放在x前面,即:始终是较大值放在前面,较小值放在后面,所以从大到小排序。
注意跟priority_queue中自定义优先级规则的区别:自定义优先级时,认为cmp函数如果返回true,就返回右值y,而这里认为cmp函数如果返回true,就保持x和y相对位置不变。
3.8.2 结构体数组排序
假设:
struct node{
int x;
int y;
}
自定义结构体比较函数:
bool cmp(node a, node b){
if (a.x != b.x) return a.x > b.x;
else return a.y < b.y;
}
即:先按x从大到小排序,假设x相等,再按y从小到大排序。
3.8.3 容器排序
1:标准容器中,只有vector、string和deque可以使用sort()排序,因为set、map本身有序,故不允许使用sort()排序。
2:字符串string本身已经重载了>或<,故可以直接对字符串数组进行排序,另外可以自定义按照字符串长度排序的新规则。
3.9 lower_bound()和upper_bound()
二者均针对有序数组(返回指针)或有序容器(返回迭代器)进行操作。
3.9.1 lower_bound()
lower_bound(first, last, value)
返回[first, last)内第一个大于等于value的元素的位置(指针或迭代器)。
3.9.2 upper_bound()
upper_bound(first, last, value)
返回[first, last)内第一个大于value的元素的位置(指针或迭代器)。
3.9.3 总结
情形1:当区间[first, last)内不存在查找值value时,lower_bound()和upper_bound()均返回插入该元素的位置指针或迭代器。如下图所示:

情形2:当区间[first, last)内存在若干个查找值value时,lower_bound()返回第一个value元素的位置指针或迭代器,upper_bound()返回最后一个value元素的位置指针或迭代器。如下图所示:

3.9.4 获取返回位置的下标
lower_bound()和upper_bound()均返回的是指针或迭代器,如果想要获取对应的下标,只需令返回值减去数组的首地址或容器的首个元素的迭代器即可。即:
[lower_bound() - a, upper_bound() - a)