使用 TensorRT 对 YOLOv8 模型进行 int8 量化
文章目录
- 前言
- 1. 量化后的效果
- 2. 代码
- 3. 软硬件环境
- 4. int8 量化的参考资料
前言
使用 Python 版的 TensorRT,可以很方便地对 YOLOv8 模型进行 int8 量化。得到 int8 量化模型之后,用 YOLOv8 的官方代码就可以直接调用该模型。
截止到目前 2023 年 9 月底,YOLOv8 官方最新的版本 8.0.186,还不支持直接进行 TensorRT 的 int8 量化,因此需要我们手动进行量化。(目前 YOLOv8 官方工具只支持转换 FP32 和 FP16 格式的 TensorRT 模型)
进行 int8 量化时的 4 个要点如下:
- 需要使用 TensorRT 的 Polygraphy 工具,以便于标定 calibration。
- 必须使用实际的训练集图片进行标定,才能得到较好的 int8 量化模型。
- 进行标定时,并不是使用的图片越多越好。可以尝试使用不同的图片数量进行标定,以获得具有最佳指标的模型。如使用 32, 64 或 200 张图片。
- 对于 YOLOv8x 模型来说,min-max 的标定方法要远好于 entropy 的标定方法。
下面是量化效果和具体的代码等。
1. 量化后的效果
量化之后的模型,推理速度快了约 5 倍,并且 mAP50 等指标基本相同。
运行结果如下 2 图。
1.1 FP32 的 PyTorch 模型推理结果。

1.2 TensorRT 的 int8 量化模型结果如下。

在上面的测试结果中,使用的是 YOLOv8x 模型,用自己的数据集进行训练,一共检测 2 个类别。
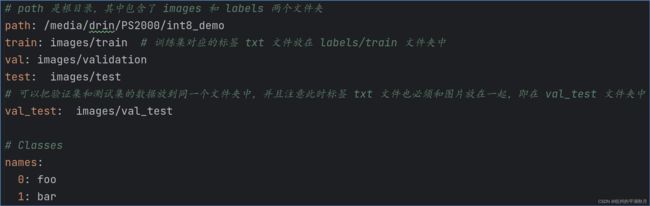
验证量化模型的指标时,使用的数据是将验证集和测试集合并到一起,然后进行验证。此时 YOLOv8 用到的 yaml 文件中,可以增加 val_test 数据集。yaml 文件的内容如下图。
注意此时要创建一个 val_test 文件夹,并且把验证集、测试集的图片以及 txt 标签文件,全都放到这个 val_test 文件夹中。
2. 代码
我创建了 trt_int8_quantization_yolo8.py,用于生成 int8 量化并检查 mAP50 等指标。量化时主要使用 TensorRT 的 Polygraphy 工具。
下面是这个文件的全部内容,因此包含了 docstrings 等。可以把下面的代码直接拷贝出来使用。
#! /usr/bin/env python3
# -*- coding: UTF-8 -*-
"""本模块用于对 YOLOv8 模型进行 int8 量化并检查 mAP50 等指标。量化时主要使用 TensorRT 的 Polygraphy 工具。
版本号: 1.0
日期: 2023-09-26
作者: [email protected]
"""
import json
import os
import pathlib
from datetime import datetime
import cv2 as cv
import numpy as np
import onnxruntime
# 注意!必须先导入 YOLO,然后再导入 trt,否则在运行 validate_model 函数时,程序会被中断,并
# 报错 “Process finished with exit code 139 (interrupted by signal 11: SIGSEGV)”
from ultralytics import YOLO
import tensorrt as trt
from tqdm import tqdm
from polygraphy.backend.trt import NetworkFromOnnxPath, CreateConfig, EngineFromNetwork
from polygraphy.backend.trt import Calibrator
def _yolo8_2_onnx(pt_model_path):
"""把 YOLOv8 模型从 .pt 格式转换为 ONNX 模型。
Arguments:
pt_model_path (str): 一个字符串,是一个训练好的 YOLOv8 detection 模型的路径。
"""
pt_model_path = pathlib.Path(pt_model_path).expanduser().resolve()
if not pt_model_path.exists():
raise FileNotFoundError(f'Model not found: {pt_model_path}')
print(f'{pt_model_path= }')
model = YOLO(pt_model_path)
model.export(format='onnx')
onnx_model_name = pt_model_path.stem + '.onnx'
onnx_model = pt_model_path.parent / onnx_model_name
print(f'Done! Model is exported as {onnx_model}')
def _get_metadata():
"""生成 metadata,这个 metadata 将被用于 YOLOv8 的 TensorRT 模型。
如果是在 Anaconda 虚拟环境中安装的 YOLOv8 ,可以参考官方源码 exporter.py:
~/.conda/envs/yolo8/lib/python3.10/site-packages/ultralytics/engine/exporter.py
:return:
metadata (dict): 一个字典,包含了 YOLOv8 的 TensorRT 模型所需的元数据。
"""
description = f'Ultralytics YOLOv8X model'
names = {'0': 'foo', '1': 'bar'} # 各个检测类别索引和名字的对应关系
metadata = {
'description': description,
'author': 'Ultralytics',
'license': 'AGPL-3.0 https://ultralytics.com/license',
'date': datetime.now().isoformat(),
'version': '8.0.186',
'stride': 32,
'task': 'detect',
'batch': 1,
'imgsz': [1504, 1504],
'names': names
}
return metadata
def _calib_data_yolo8(onnx_input_name, onnx_input_shape,
calibration_images_quantity, calibration_images_folder):
"""生成标定数据,用于对 YOLOv8 模型进行 int8 量化。
为了有更好的量化效果,得到更好的比例值 scale,需要进行标定。标定时一般有 2 个要求:
a. 标定数据是经过前处理之后的图片(通常是归一化之后的 [0, 1] 之间的数)。
b. 标定数据应该使用实际的图片,比如训练集的图片。
Arguments:
onnx_input_name (str): 一个字符串,是 ONNX 模型输入的名字。
onnx_input_shape (tuple(int, int, int, int)): 一个元祖,是 ONNX 模型的输入张量的形状。
calibration_images_quantity (int): 一个整数,是标定时使用的图片数量。
calibration_images_folder (str): 一个字符串,指向一个文件夹,该文件夹内的图片将被用于标定。
:return
one_batch_data (Generator[dict[str, ndarray]]): 一个字典,包含了一个批次的标定数据。
"""
print(f' {onnx_input_shape= }') #
if onnx_input_shape[1] != 3: # ONNX 输入的形状可以是:1, 3, 1504, 1504。第一维度是深度通道。
raise ValueError(f'Error, expected input depth is 3, '
f'but {onnx_input_shape= }')
calibration_images_folder = pathlib.Path(calibration_images_folder).expanduser().resolve()
if not calibration_images_folder.exists():
raise FileNotFoundError(f'{calibration_images_folder} does not exist.')
print(f'{calibration_images_folder= }')
batch_size = onnx_input_shape[0]
required_height = onnx_input_shape[2]
required_width = onnx_input_shape[3]
# 初始化第 0 批数据。标定时必须给 engine 输入 FP32 格式的数据。
output_images = np.zeros(shape=onnx_input_shape, dtype=np.float32)
# 如果图片总数不够,则使用所有图片进行标定。
calibration_images_quantity = min(calibration_images_quantity,
len(os.listdir(calibration_images_folder)))
print(f'Calibration images quantity: {calibration_images_quantity}')
print(f'Calibrating ...')
# 创建一个进度条。
tqdm_images_folder = tqdm(calibration_images_folder.iterdir(),
total=calibration_images_quantity, ncols=80)
for i, one_image_path in enumerate(tqdm_images_folder):
# 只有一个循环完整结束后,tqdm 进度条才会前进一格。因此要在 for 循环的开头
# 使用 i == calibration_images_quantity 作为停止条件,才能看到完整的 tqdm 进度条
if i == calibration_images_quantity:
break
bgr_image = cv.imread(str(one_image_path)) # noqa
# 改变图片尺寸,注意是宽度 width 在前。
bgr_image = cv.resize(bgr_image, (required_width, required_height)) # noqa
one_rgb_image = bgr_image[..., ::-1] # 从 bgr 转换到 rgb
one_image = one_rgb_image / 255 # 归一化,转换到 [0, 1]
one_image = one_image.transpose(2, 0, 1) # 形状变为 depth, height, width
batch_index = i % batch_size # 该批次数据中的索引位置
output_images[batch_index] = one_image # 把该图片放入到该批次数据的对应位置。
if batch_index == (batch_size - 1): # 此时一个 batch 的数据已经准备完成
one_batch_data = {onnx_input_name: output_images}
yield one_batch_data # 以生成器 generator 的形式输出数据
output_images = np.zeros_like(output_images) # 初始化下一批次数据。
def onnx_2_trt_by_polygraphy(onnx_file, optimization_level=5,
conversion_target='int8', engine_suffix='engine',
calibration_method='min-max', calibration_images_quantity=64,
calibration_images_folder=None,
onnx_input_shape=None):
"""把 onnx 模型转换为 TensorRT 模型。可以进行 int8 量化,也可以转换为 FP16 格式的模型。
Arguments:
onnx_file (str | pathlib.Path): 一个字符串或 Path 对象,指向一个 ONNX 文件。
optimization_level (int): 一个整数,代表优化等级。level 越大,则会花更多时间对 engine 进行优化,得
到的 engine 性能有可能会更好。
conversion_target (str): 一个字符串,是 'int8', 'fp16' 或者 'fp32'。int8 表示进行 int8 量化,
而 fp16、fp32 则表示转换为 FP16 或 FP32 格式的 TensorRT 模型。
engine_suffix (str): 是输出的 TensorRT 模型的文件名后缀,可以是 'plan' 、'engine' 或 'trt'。
calibration_method (str): 是进行 int8 量化时的标定方法。如果输入 None,则使用默认的
entropy 方法,如果输入 min-max,则使用 min-max 标定方法。
calibration_images_quantity (int): 一个整数,是标定时使用的图片数量,只在 int8 量化时有效。
onnx_input_shape (tuple(int, int, int, int) | None): 一个元祖,是 ONNX 模型的输入张量的形状。
:return
converted_trt (str): 一个字符串,是生成的 TensorRT 模型的绝对路径。
"""
if conversion_target.lower() not in ['int8', 'fp16', 'fp32']:
raise ValueError(f"The conversion_target must be one of ['int8', 'fp16', 'fp32'], "
f"but get {conversion_target= }")
if engine_suffix not in ['plan', 'engine', 'trt']:
raise ValueError(f"The engine_suffix must be one of ['plan', 'engine', 'trt'], "
f"but get {engine_suffix= }")
onnx_file = pathlib.Path(onnx_file).expanduser().resolve()
if not onnx_file.exists():
raise FileNotFoundError(f'Onnx file not found: {onnx_file}')
print(f"Succeeded finding ONNX file! {onnx_file= }")
print(f'Polygraphy inspecting model:')
os.system(f"polygraphy inspect model {onnx_file}") # 用 polygraphy 查看 ONNX 模型
network = NetworkFromOnnxPath(str(onnx_file)) # 必须输入字符串给 NetworkFromOnnxPath
# 1. 准备转换 engine 文件时的配置。包括 optimization_level 和 flag 等。
builder_config = CreateConfig(builder_optimization_level=optimization_level)
print(f'{builder_config.builder_optimization_level= }')
converted_trt_name = (f"{onnx_file.stem}_optimization_level_{optimization_level}"
f"_{conversion_target}")
if conversion_target.lower() == 'fp16':
builder_config.fp16 = True
print(f'{builder_config.fp16= }')
elif conversion_target.lower() == 'int8':
# 2. 准备 int8 量化所需的 5 个配置。
# 2.1 设置 INT8 的 flag
builder_config.int8 = True
print(f'{builder_config.int8= }')
# 2.2 用 onnxruntime 获取模型输入的名字和形状.
session = onnxruntime.InferenceSession(onnx_file, providers=['CPUExecutionProvider'])
onnx_input_name = session.get_inputs()[0].name
if onnx_input_shape is None: # 查询 ONNX 中的输入张量形状。
onnx_input_shape = session.get_inputs()[0].shape
# 2.3 准备标定用的 cache 文件。
calibration_cache_file = f"./{onnx_file.stem}_int8.cache"
calibration_cache_file = pathlib.Path(calibration_cache_file).expanduser().resolve()
if calibration_cache_file.exists(): # 始终使用一个新的 cache,才能每次都生成新的 TensorRT 模型。
os.remove(calibration_cache_file)
# 2.4 设置标定方法。实际验证发现,对于 YOLOv8 模型,IInt8MinMaxCalibrator 标定的效果最好。
if calibration_method == 'min-max':
calibrator_class = trt.IInt8MinMaxCalibrator
else:
# 默认使用 entropy 方法,该方法通过减少量化时的信息损失 information loss,对模型进行标定。
calibrator_class = trt.IInt8EntropyCalibrator2
# 2.5 在 Calibrator 类中,传入标定方法,标定数据和 cache 等。
builder_config.calibrator = Calibrator(
BaseClass=calibrator_class,
data_loader=_calib_data_yolo8(onnx_input_name=onnx_input_name, onnx_input_shape=onnx_input_shape,
calibration_images_quantity=calibration_images_quantity,
calibration_images_folder=calibration_images_folder),
cache=calibration_cache_file)
int8_suffix = f'_{calibration_method}_images{calibration_images_quantity}'
converted_trt_name = converted_trt_name + int8_suffix
converted_trt = onnx_file.parent / (converted_trt_name + f'.{engine_suffix}')
print('Building the engine ...')
# 3. 按照前面的配置 config,设置 engine。注意 EngineFromNetwork 返回的是一个可调用对象 callable。
build_engine = EngineFromNetwork(network, config=builder_config)
# 4. 调用一次 build_engine,即可生成 engine,然后保存 TensorRT 模型即可。
with build_engine() as engine, open(converted_trt, 'wb') as t:
yolo8_metadata = _get_metadata() # 需要创建 YOLOv8 的原数据 metadata
meta = json.dumps(yolo8_metadata) # 转换为 json 格式的字符串
# 保存 TensorRT 模型时,必须先写入 metadata,然后再写入模型的数据。
t.write(len(meta).to_bytes(4, byteorder='little', signed=True))
t.write(meta.encode())
t.write(engine.serialize())
engine_saved = ''
if not pathlib.Path(converted_trt).exists():
engine_saved = 'not '
print(f'Done! {converted_trt} is {engine_saved.upper()}saved.')
return str(converted_trt)
def validate_model(model_path, conf, iou, imgsz, dataset_split, agnostic_nms,
batch_size=1, simplify_names=True, **kwargs):
"""验证 YOLOv8 模型的指标。可以是 TensorRT 模型或 PyTorch 的模型。
Arguments:
model_path (str): 一个字符串,是一个训练好的 YOLOv8 detection 模型的路径。
conf (float): 一个范围在 [0, 1] 的浮点数,表示在预测时,使用的置信度阈值。
iou (float): 一个范围在 [0, 1] 的浮点数,表示在预测时,使用的交并比。
imgsz (int): 一个整数,是预测时,使用的图片最大高度和最大高度。
dataset_split (str): 一个字符串,是 val 或 test,分别代表验证集或测试集。
如果使用 val_test,必须把标签和图片都放入同一个文件夹 val_test 中。
agnostic_nms (bool): 一个布尔值,如果为 True,则在进行 NMS 时,不区分类别,即把所有
类别都看做同一个类别。而如果为 False,则只有相同类别的框,才会用来进行 NMS。
batch_size (int): 一个整数,是预测时的 batch 大小。
simplify_names (bool): 一个布尔值。如果为 True,则可以把各个类别的名字进行简化。
"""
model_path = pathlib.Path(model_path).expanduser().resolve()
if not model_path.exists():
raise FileNotFoundError(f'Model not found: {model_path}')
print(f'{model_path= }')
print(f'{conf= }, {iou= }, {imgsz= }')
model = YOLO(model_path, task='detect') # 须在创建模型时设置 task。
detect_data = r'/media/drin/PS2000/int8_demo/int8_demo.yaml'
if (model_path.suffix == '.pt') and simplify_names:
# model.names 只对 pt 模型有效,对 engine 模型无效。
model.names[0] = 'foo' # 可以把类别的名字进行简化
model.names[1] = 'bar'
metrics = model.val(split=dataset_split, save=False,
data=detect_data,
agnostic_nms=agnostic_nms, batch=batch_size,
conf=conf, iou=iou, imgsz=imgsz,
**kwargs)
map50 = round(metrics.box.map50, 3)
print(f'{dataset_split} mAP50= {map50}')
def main():
"""把 YOLOv8 模型进行 int8 量化,然后用验证集、测试集的数据,验证量化后模型的指标。
一共有 3 个步骤,第一个步骤是把 pt 模型转换为 ONNX 模型,第二个步骤是进行 int8 量化,
第三个步骤是验证量化模型的指标。
注意第一个步骤要和后面两个步骤分开执行。即先注释第二步和第三步,执行第一步转换 ONNX 模型。
然后将第一步注释掉,再次运行 main 程序,执行后面的第二步和第三步。
"""
# 1. 先用下面 2 行,把 PyTorch 模型转换为 ONNX 模型。
# pt_model_path = (r'/media/drin/PS2000/int8_demo/'
# r'demo_int8_conf0.5_iou0.7_imgsz1504_map964.pt')
# yolo_2_onnx(pt_model_path=pt_model_path)
# 2. 用 ONNX 模型进行 int8 量化,生成 TensorRT 的模型。
onnx_file = (r'/media/drin/PS2000/int8_demo/'
r'demo_int8_conf0.5_iou0.7_imgsz1504_map964.onnx')
calibration_images = 64 # 也可以尝试 100, 32 等其它图片数量进行标定。
calibration_images_folder = r'/media/drin/PS2000/int8_demo/images/train' # 使用训练集的图片进行标定。
saved_engine = onnx_2_trt_by_polygraphy(
onnx_file=onnx_file, optimization_level=5, conversion_target='int8',
engine_suffix='engine', calibration_images_quantity=calibration_images,
calibration_images_folder=calibration_images_folder)
# 3. 用验证集和测试集,检查 int8 量化后的模型指标。
# 也可以输入 pt_model_path 验证 PyTorch 模型的指标。
validate_model(model_path=saved_engine,
dataset_split='val_test', # 同时使用验证集和测试集的数据。
imgsz=1504,
conf=0.5, iou=0.7, agnostic_nms=True)
if __name__ == '__main__':
main()
运行上面主程序 main 的第二步骤和第三步骤时,输出结果如下图。
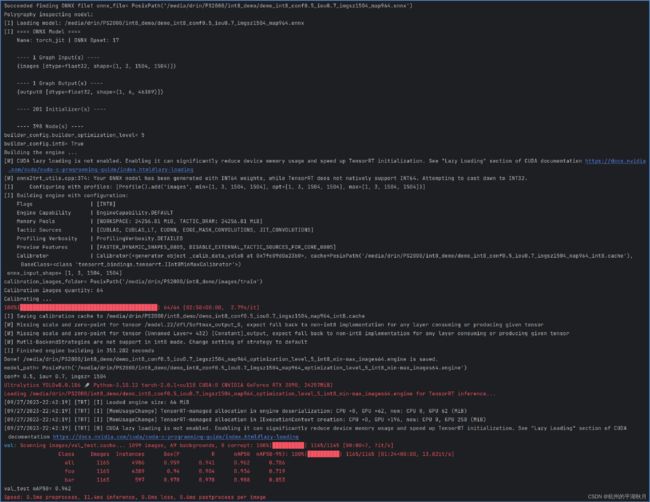
3. 软硬件环境
建议使用 Anaconda 创建虚拟环境,在虚拟环境中装各种软件。避免因为多个软件版本冲突,导致无法运行的问题。
使用的软硬件环境如下:
TensorRT:8.6.1.post1
Polygraphy: 0.47.1
YOLOv8: 8.0.186
CUDA: 11.8
PyTorch: 2.0.1+cu118
Python: 3.10.12
GPU: 3090
在虚拟环境中安装 TensorRT 时,可以在 https://pypi.org/project/tensorrt/ 查看它的安装方法,或是使用 NVIDIA 的地址进行安装: pip install tensorrt --extra-index-url https://pypi.nvidia.com
4. int8 量化的参考资料
关于 int8 量化的一些理论和操作,可以参看 NVIDIA 的 tutorial:
https://github.com/NVIDIA/TensorRT/tree/release/8.6/quickstart/quantization_tutorial
——————————本文结束——————————