【笔记】软件测试06——Web自动化
阅读:
石墨文档
七、web自动化测试
GUI自动化测试学习内容:
- 了解自动化测试的相关概念
- 掌握Selenium Webdriver常用API
- 掌握自动化测试中的元素定位方法
- 掌握自动化测试中的元素操作
- 掌握自动化测试断言操作
- 掌握unittes框架的基本应用及自动化管理
一)自动化测试的相关概念
什么是自动化测试?
自动化测试就是把人对软件的测试行为转化由机器执行测试行为的一种实践。对于最常见的GUI自动化测试来讲,就是由自动化测试模拟之前那需要人工在软件界面上的各种操作,并且自动验证其结果是否符合预期结果。
自动化测试是否会把测试工程师淘汰?
从分析——计划——设计——实现——执行这个流程中,分析、计划、设计是需要人工进行的,实现、执行的过程中,也有自动化无法满足要求的情况。
什么样的项目适合自动化?
- 需求文档、不会频繁变更
- 研发和维护周期长,需要频繁执行回归测试
- 需要在多种平台上重复运行相同测试的场景
- 性能、兼容性通过手工测试无法实现,或者手工测试成本太高
- 被测软件的开发较为规范,能够保证系统的可测试性
- 测试人员具备一定的编程能力
1)自动化测试的类型分类
自动化测试有广义和狭义之分:
- 广义:借助工具进行软件测试都可以成为自动化测试
- 狭义:主要指基于UI层的自动化测试
测试划分:功能、性能、安全
测试阶段划分:基于代码的单元测试、集成阶段的接口测试、系统测试阶段的UI自动化
2)自动化测试用例设计原则
自动化测试用例设计原则:
- 自动化测试一般集中在需要重复测试的基本功能、基本业务流以及正向路径操作,不要将复杂的异常测试、复杂业务流程操作等加入到自动化测试用例中
- 自动化测试用例应尽量保持用例之间的独立性,最好不要形成依赖关系
- 自动化测试如果对数据进行了修改,在测试结束后应尽量保持还原,避免对其他用例执行产生影响
- 每个自动化测试用例只能验证一个功能点
二)webdriver
1)webdriver环境配置
什么是Selenium webdriver?
Se:硒
- 一种开源、免费的自动化测试工具,目前80%以上的公司都在使用它进行自动化测试
- 多浏览器支持:Firefox、Chrome、IE、Opera
- 多平台支持:Java、Python、Ruby、php、C#,JavaScript
- 简单(API简单),灵活(用开发语言驱动)
01环境配置
- 通过pip install selenium安装最新的selenium
- 下载对应的chromedriver或geckodriver,并将driver房到环境变量路径中
Chromedriver下载镜像:
CNPM Binaries Mirror
geckodriver下载镜像(firefox):
http://npm.taobao.org/mirrors/geckodriver/
3.在pycharm中导入webdriver即可使用
from selenium import webdriver02 webdriver的工作原理
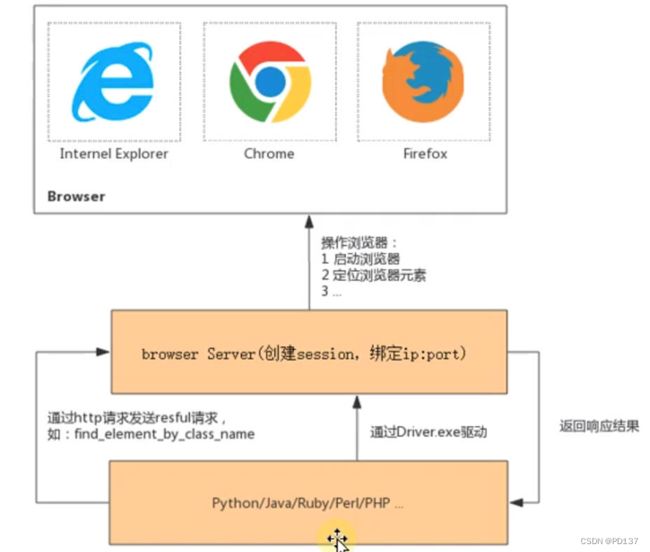
即编写脚本通过http请求发送relful请求,如:find_ element_ by_ class_ name ,脚本通过driver. exe驱动server 服务器,创建session, 绑定ip,向浏览器进行发送操作,并返回响应结果。
2 )自动化测试的基本操作
01自功化测试的基本操作示例
LOVE四步法:

eg

02 webriver常用API -浏览器操作
打开: driver. get(URL)
关闭:driver.quit()结束进程或driver.close()仅关闭当前窗口
设置窗口大小:driver.set_window_size(200, 500)
最大化窗口:driver.maxmize_window()
获取网页资源:driver.page_source
获取窗口名称:driver.name
刷新页面:driver.refresh()
获取页面标题:driver.title
获取当前页面的url地址:driver.curret_url
获取当前页面截图:driver.get_screenshot_as_file(path)03 web常用定位方式
webdriver常用API——常用的八种定位方式:
格式:
from selenium import webdriver
driver = webdriver.Chrome()
#id定位
name = driver.find_element('id', 'username')
name.send_keys('教育')
#name属性定位
driver.find_element('name', 'sex').click() # 选中性别中男这个选项 返回找到的第一个值
driver.find_elements('name', 'sex')[1].click() # find_elements将以列表形式返回多个符合条件的元素,返回列表的第二个,列表从0下标开始
#class name属性定位
driver.find_element('class name', 'dotborder').send_keys('凡云教育')
#对于复合样式的元素,不能直接使用class name方法来进行定位,以下语句报错
driver.find_element('class name', 'dotborder border').send_keys('aaaaa')
#tag name定位:一般用于寻找同类元素,返回列表
elements = driver.find_elements('tag name', 'input')
print(len(elements))
#link text和partial link text专门用于定位超链接a标签。
driver.find_element('link text', '打开百度').click() #全匹配
driver.find_element('partial link text', '百度').click()#部分匹配
#xpath定位
#绝对路径定位法
print(driver.find_element('xpath', '/html/body/form'))
#相对路径定位法
print(driver.find_element('xpath', '//tbody/tr[3]/td[2]/i').text)
print(driver.find_element('xpath', '//tbody/tr[3]//i').text)
#xpath属性定位
print(driver.find_element('xpath', "//input[@type='file']"))
driver.find_element('xpath', "//input[@type='text'][@mode='sub']").send_keys('18')
# xpath模糊定位
print(driver.find_element('xpath', "//*[contains(text(), '60岁')]").text)
driver.find_element('xpath', "//textarea[contains(@placeholder, 'yourself')]").send_keys('hello,教育')
find_element和find_elements
对于查找元素的方法,在webdriver中四种不同的写法,请注意区别:
- find_element('xx','selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements('xx','selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
- find_element_by_xx('selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements_by_xx('selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
三)Selenium+webdriver操作
1)Selenium元素查找
01、基本元素
- id:find_element('id','selector')
- name:find_element('name','selector')
- class name:find_elemnet('class name','selector')
- tag name:find_elementfind_elements('tag name','selector')
使用无痕窗口,因为没有任何cookie,代码打开的浏览器就是没有的,所以定位元素的时候,使用无痕窗口打开。
find_element和find_elements
对于查找元素的方法,在webdriver中四种不同的写法,请注意区别:
- find_element('xx','selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements('xx','selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
- find_element_by_xx('selector')根据指定的方式定位元素,仅返回找到的第一个元素,如果美有元素符合则直接抛出异常
- find_elements_by_xx('selector')根据指定的方式定位元素,以列表形式返回找到的所有元素,如果没有元素符合则返回空列表
eg:
对于一段html
如下代码都可以获取到这个标签:
#id
driver.find_element_by_id("username_id")
#name
driver.find_elemenet_by_name("username")
#class_name
driver.find_element_by_class_name("red")
#tag
driver.find_element_by_tag_name("input")

实例:
from selenium import webdriver
from time import sleep
driver=webdriver.Chrome()
url = 'https://www.baidu.com'
#使用浏览器打开指定页面
driver.get(url)
#id 查找元素(标签、标记、节点)
driver.find_element("id","kw").send_keys("肖战王一博")
driver.find_element("id","su").click()
#name
driver.find_element("name","wd").send_keys("肖战王一博")
driver.find_element("id","su").click()
#class_name
driver.find_element("class name","s_ipt").send_keys("肖战王一博")
driver.find_element("id","su").click()
sleep(3)
#关闭浏览器
driver.quit()复合样式不能用class去定位,直接报错,可以使用css selector进行定位

02、超链接(a标签)
- link text
- partial link text
- 超链接的例子
对于一段html
访问 百度 网站如下代码都可以获取到这个标签
#link_text
driver.find_element("link text","访问 百度 网站")
#partial_link_text
driver.find_element("partial link text","访问")注意:
如果相同的规则回队应多个标签,那么这些方法会返回第一个
实际例子:

#定位a标签
#link_text
driver.find_element("link text","hao123").click()
#partial_link_text 如果文本比较长 ,定位部分可以使用这个,能够完整尽量完整
driver.find_element("partial link text","hao12").click()03、css选择器
web页面元素:
1、HTML页面基本结构
html文档头部区域,页面不可见
html文档内容区域,页面可见
2、常见的页面元素:
- 容器型元素:div、form、table
- 页面元素:link、img、input(button、text、file)、select、checkbox、radio、textarea、submit
css选择器语法:
| 选择器 |
例子 |
例子描述 |
| .class |
.intro |
选择class="intro"的所有元素 |
| #id |
#firstname |
选择id="firstname"的所有元素 |
| * |
* |
选择所有元素 |
| element |
p |
选择所有 元素 |
| element,element |
div,p |
选择所有 元素和所有 元素 |
| element element |
div p |
选择 元素内部的所有 元素 |
| element>element |
div>p |
选择父元素为 元素的所有 元素 |
| element+element |
div+p |
选择紧接在 元素之后的所有 元素 |
| [attribute] |
[tartget] |
选择带有target属性所有元素 |
| [attribute=value] |
[target=_nlank] |
选择target="_bklank"的所有元素 |
参考:
selenium:css_selector定位详解 - 也许明天 - 博客园
方法:
- 利用元素的标签、元素的单一属性定位(id、class)等
- 多属性定位
- 标签+属性组合
- 层级(子孙)定位
方法:
find_element_by_css_selector(CSS选择器)
#new:
find_element('css selector','css选择器')eg:
以上的百度搜索框
#id
find_element_by_css_selector("#kw").send_keys("博君一肖")
# . : class
find_element_by_css_selector(".s_ipt").send_keys("博君一肖")
#name
find_element_by_css_selector("[name=wd]").send_keys("博君一肖")
#value
find_element_by_css_selector("[value=百度一下]").click()
#多属性定位,以下返回的是列表
driver.find_element('css selector','[type="checkbox"][name="hobby"]')[2].click()
#利用父子关系来定位目标元素,父元素>第一个子元素,nth-child指定子元素,序号从1开始
deriver.find_element('css selector','tbody>tr:nth-child(1)>td:nth-child(2)>input')
#父子关系(>)孙子关系(空格)
driver.find_element('css selector','tbody>tr:nth-child(3) i')
#模糊匹配*=
driver.find_element('css selector','input[value*="测试2"]').click()eg:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
#找class=s_ipt
driver.find_element('css selector','.s_ipt').send_keys('博肖希望小学')
driver.find_element('css selector','#su').click()
sleep(1)
driver.quit()复合样式不能用class去定位,直接报错,可以使用css selector进行定位

driver.find_element('css selector','.dotborder.border')F12的console

04、元素定位Xpath
- Xpath概念
xpath = xml path
XML和HTML一样是标签语言,通过标签的嵌套来表达信息,自然而言,形参了父节点、子节点、后代节点、同胞节点等关系。而xpath就是用来在这些节点中找到所需要的
XML: 可扩展标记语言
HTML:超文本标记语言
Xpath语法
绝对路径和相对路径
- 绝对路径表示法:指从/目录开始的绝对的路径表示法,必须根据实际路径逐级表示(从根目录开始,即从标签开始)
- 相对路径表示法:指从目标对象所在位置根据其父对象进行路径表示的方法
- xpath表达式
完整:
| 表达式 |
描述 |
| nodename |
选区此节点的所有子节点 |
| / |
从根节点选取 |
| // |
从匹配选择的当前节点选择文档中的节点 |
| . |
选区当前节点 |
| .. |
选区当前节点的父节点 |
- 获取内容
| 表达式 |
描述 |
| @ |
选取属性 |
| text() |
获取文本 |
- 进阶表达式
| 路径表达式 |
结果 |
| /bookstore/book[1] |
选取属于bookstore子元素的第一个book元素 |
| /bookstore/book[last()] |
选取属于bookstore子元素的最后一个book元素 |
| /bookstore/book[last()-1] |
选取属于bookstore子元素的倒数第二个book元素 |
| //book/title[text()='Harry Potter'] |
选择所有book下的title元素,仅仅选择文本为Harry Potter的title元素 |
| //title[@lang="eng"] |
选择lang属性值为eng的所有title元素 |
- 实践使用方法
- 通过Chrome的调试工具,获得特定元素的xpath
- 修改得到的xpath表达式
- 通过chrome的xpath herper扩展插件,匹配查看
- F12的console

实例:
还是百度的例子
#通过xpath的方式定位
driver.find_element("xpath","//*[@id='kw']").send_keys("博君一肖")
driver.find_element("xpath","//*[@id='su']").click()
#xpath定位
#绝对路径定位法
print(driver.find_element('xpath', '/html/body/form'))
#相对路径定位法。必须以"//"开头
print(driver.find_element('xpath', '//tbody/tr[3]/td[2]/i').text)
#简化,tr下只有一个i元素,不管i是哪一级,注意前面是“//”
print(driver.find_element('xpath', '//tbody/tr[3]//i').text)
#xpath属性定位 ,input标签这种的type='file'
print(driver.find_element('xpath', "//input[@type='file']"))
#多属性
driver.find_element('xpath', "//input[@type='text'][@mode='sub']").send_keys('18')
# xpath模糊定位,根据关键词查找不能等于
print(driver.find_element('xpath', "//*[contains(text(), '60岁')]").text)
driver.find_element('xpath', "//textarea[contains(@placeholder, 'yourself')]").send_keys('hello,教育')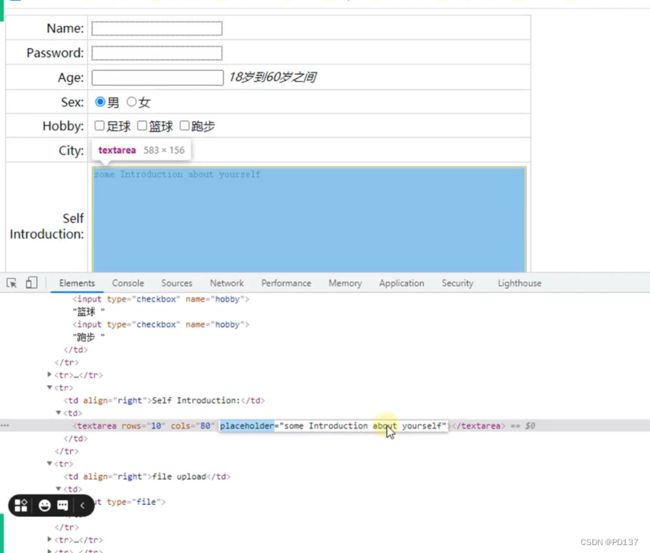
05、元素操作
- clear() 清除文本
- send_keys() 模拟输入
- click() 单击元素
eg:
driver.find_elemnet("id","kw").send_keys("肖战")
time.sleep(3)
driver.find_element("id",""kw").clear()
time.sleep(3)
driver.find_element("id",""kw").send_keys("王一博")
driver.find_element("id",""su").click()-
元素属性获取
- size 返回元素大小
- text 获取元素的文本
- get_attribute() 获取属性值
- is_display() 判断元素是否可见
- is_enabled() 判断元素是否可用
eg:
print(driver.find_element("id",""kw").size)
print(driver.find_element("id",""kw").text)
print(driver.find_element("id",""kw").is_enable())
print(driver.find_element("id",""kw").is_display())
driver.find_element("xpath",""//*[text()='新闻']").get_attribute("herf")01获取元素指定属性的值
driver.find_element_by_id('username').get_attribute('value')02复选框常见操作
#判断是否可见
print(driver.find_element_by_id('kw').is_displayed())
#判断是否可用
print(driver.find_element_by_id('kw').is_enable())
#判断是否已经被选中,如果选择则返回True,否则返回false
print(driver.find_element_by_id('kw').is_selected())03发送复合按键
#shift+字母小写实现大写输入,需要进行复合按键来操作下,模拟人操作键盘
from selenium.webdriver.common.keys import Keys #Keys可以帮助使用复合按键
driver.find_element().send_keys(Keys.SHIFT,'bx'*50) #输入的值大写和小写都可以,*50:输入该值50个04下拉列表常见操作
from selenium.webdriver.support.ui import Select
Select(driver.find_element_by_id('status')).select_by_index(3) #选择的序号,下标从0开始
Select(driver.find_element_by_id('status')).select_by_visible_text('Ongoing') #根据文本进行选择
Select(driver.find_element_by_id('status')).select_by_value('sh') #便签里面的value=''的值05实战
from selenium import webdriver
#from time import sleep
import time
driver.get('https://www.woniuxy.com')
driver.maximize_window() # 窗口最大化,确保登陆按钮显示在界面上
driver.find_element('link text', '登录').click()
driver.find_element('id', 'l_tel').send_keys('15828183448')
driver.find_element('id', 'l_pass').send_keys(pwd)
time.sleep(10)
driver.find_element('id', 'loginButton').click()
driver.execute_script("window.scrollTo(0, 300);")
time.sleep(1)
driver.find_element('link text', '付费专属').click()
driver.find_element('link text', '查看更多').click()
Select(driver.find_element('id', 'area')).select_by_visible_text('凡云教育')
courses = driver.find_elements('class name', 'course-name')
for course in courses:
if course.text.strip():
print(course.text)06、元素定位的常规原则
01元素定位方式选择:
- 页面有id时,优先使用id来定位,其次是name
- Xpath很强悍,但定位性能不是很好,当其他方法不好定位时可以用
- 定位一组相同元素时,可以考虑使用tag name或name
- 定位连接时,可考虑link text或partial link text
02定位元素的注意事项
- 找到待定位元素的唯一属性
- 如果该元素没有唯一属性,则先找到能被唯一定位到的父元素/子元素/相邻元素,再使用xpath或css选择器等进行基于位置的定位
- 不要使用随机唯一属性定位
- 最重要的时多与研发沟通,尽量把关键元素加上id或name,并减少不合理的页面元素,例如重复id,此类事情最好不要发生
2)浏览器的基本操作
浏览器操作(方法)
- maximize_window() 最大化浏览器
- set_window_size(width,height) 设置浏览器宽、高像素点
- set_window_position(x,y) 设置浏览器位置,浏览器左上角相对于屏幕左上角位置
- send.keys() 向文本域或文件上传按钮发送文字内容
- back() 后退
- clear() 清除按钮
- click() 点击按钮
- forword() 前进
- refresh() 刷线
- close() 关闭当前页面
- quit() 关闭浏览器
浏览器信息(属性)
- title 获取页面title
- text 获取节点上的文本信息,标签中间的值可获得
- current_url() 获取当前页面URL
- is_displayed() 判断是否显示出来,返回布尔值,用于判断
- get_attribute('属性') 获取指定属性的值,可获取文本框输入的值
eg:
print(driver.title)
print(driver.current_url())
print(driver.find_element('id','kw').get_attribute('class'))
#最大化
driver.maximize_window()
#设置浏览器
time.sleep(1)
driver.set_window_size(800,600)
time.sleep(3)
driver.set_window_position(200,200)
driver.find_element("id","kw").send_keys("bjyx")
driver.find_element("id","su").click()
sleep(2)
driver.back()
time.sleep(2)
driver.forword()
time.sleep()
driver.refresh()
time.sleep(2)
driver.back()
driver.find_element("xpath","//*[text()='hao123']").click()
time.sleep(2)
driver.close()
time.sleep(2)
driver.quit()3)页面等待
- 为什么要等待
因为web中看到的元素,不一定是写在html代码中的,有可能是通过javascript代码的demo来操作产生出来的。而js产生元素,很可能先要去获取到数据,处理后再去显示的。所以:不一定网页打开,所有元素都在页面中了。如果马上去找,可能会出错。
代码执行速度远远快于页面加载的速度,翻页的时候需要进行页面等待。
等待方式:
- 显示等待
- 隐式等待
- 强制等待
- 显式等待
可针对每一个元素进行单独设置,等待条件更加灵活。针对某一些元素来执行等待,等待显示。
注意:如果显式等待和隐式等待同时设置,以最长等待时间为准
- 如何操作:
- 使用webdriverWait包装webDriver对象
-
- 使用webdriver的utill方法,传入可调用对象(通常是presence_of_element_location函数的返回值)
- 需导入包
from selenuim.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import webDriverwait常见的EC方法:
- title_is(strtitle):判断当前页面的title是否精确等于预期
- title_contains(strtitle):判断当前页面title是否包含指定字符串
- presence_of_element_located(locator):判断某个元素是否被加载到dom树(html代码)里,并不代表元素一定可见
- visibility_of_element_located(locator):判断某个元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0
- inivisibility_of_element_located(locator):判断某个元素是否不可见
- element_to_clickable(locator):判断某个元素中是否可见并且enable的,这样才叫clickable
- text_to_be_present_in_element(locator):判断某个元素中的text是否包含了预期的字符串
-
- 显式等待eg:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenuim.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import webDriverwait
url = 'https://www.baidu.com'
driver = wevdriver.Chrome()
driver.get(url)
#输入框输入要搜索的内容 博肖
driver.find_element("id","kw").send_kesys("博肖")
#点击 百度一下
driver.find_element("id","su").click()
#显式等待,导包太多了
#EC期待等待的时间 等待某个元素加载完成,每个0.5秒去检测一次,最多等待5秒 ID为1的元素
element = webDriverWait(driver,5).
until(EC.presence_of_location((By.ID,'1')))
#element.sen_keys("admin")
#点击一个搜索到的条目
driber.find_elemenet("id","1").click()
sleep(3)
#关闭浏览器
driver.quit()
eg2:
#5代表最多等待5秒,等待id为msg的元素值的参数出现
webDriverWait(driver,5).until(EC.text_to_be_present_in_element('text','msg'),'出错啦:找不到该用户名...')
#element_to_clickable
webDriverWait(driver,10).until(EC.element_to_clickable(('id','btn3'))
#inivisibility_of_element_located,如果是不可见的则报错,invisibility是不可见
webDriverWait(driver,5).until(EC.visibility_of_element_located(('id','btn2')))
#presence_of_element_located
webDriverWait(driver.5).until(EC.presence_of_element_located(('id','btn2')))显示等待比较灵活,比较麻烦。
若是以后遇到没有找到元素等的问题,可以考虑下是否是没有等待时间。
2.隐式等待
即全局等待
设置依次后(隐式等待只需设置一次),全局有效,在元素没有出现时最多只等待指定时间,但如果再等待时间内,什么时候元素出现什么时候停止等待。
隐式等待只能等待元素生成,当这个元素不存在时就会等定位元素,但当元素存在时则不会等待。当有时侯等的不是元素存不存在,而是等待元素显示的文字,文字还没有生成,则无法获取(这个时候可以使用强制等待)。
隐式等待只能在元素不存在这种情况才能生效,否则不会产生任何等待效果。
implicitly_wait(5)给浏览器加入了一个默认的设置,在每一次操作这个元素,若没有获取到该元素,则会等待设置的时间,如果找到了则继续,否则抛出元素未找到异常。
eg: 推荐
from selenium import webdriver
url = 'https://www.baidu.com'
driver = wevdriver.Chrome()
driver.get(url)
#输入框输入要搜索的内容 博肖
driver.find_element("id","kw").send_kesys("博肖")
#点击 百度一下
driver.find_element("id","su").click()
#隐式等待 implicitly隐含
driver.implicitly_wait(5)
#点击一个搜索到的条目
driber.find_elemenet("id","1").click()
sleep(3)
#关闭浏览器
driver.quit()
3.强制等待
即固定等待
优势:
用法简单,一般用于项目调试,或者用于等待元素状态、文本发生改变
劣势:
等待时间固定,如果脚本中大量使用会导致脚本运行效率低
import time
time.sleep(2)
实例:以百度搜索框为例
from selenium import webdriver
from time import sleep
#创建webDriver对象 Chrome()封装了谷歌的一些方法
#如果把驱动放置到了 系统环境变量目录中,可不带参数创建
driver=webdriver.Chrome()
#如果没有放置到系统环境变量目录中,需要通过参数指定
#driver = webdriver.chrome(executable_path="./chromedriver.exe")
url = 'https://www.baidu.com'
#使用浏览器打开指定页面
driver.get(url)
#输入框输入要搜索的内容 博肖
driver.find_element("id","kw").send_kesys("博肖")
#点击 百度一下
driver.find_element("id","su").click()
#强制等待 不是最优解,每个电脑的加载速度不一样
sleep(1)
#点击一个搜索到的条目
driber.find_elemenet("id","1").click()
sleep(3)
#关闭浏览器
driver.quit()4)模拟鼠标操作
selenium可以模拟鼠标的操作
需导包:
from selenium.wevdriver.common.action_chains import ActionChians使用步骤:
- 创建ActionChains对象
- 使用ActionChains对象的方法进行操作
- context_click() 右击-->模拟说吧右键点击效果
- double_click() 双击
- drag_and_drop() 拖动-->模拟双标拖动效果
- move_to_element() 悬停-->模拟鼠标悬停效果
- 其他 可参考ActionChains的源代码
- 通过ActionChains"提交"这些操作
perform() 执行-->此方法用来执行以上所有鼠标方法
例子:百度搜索eg
01右击:

from selenium import webdriver
from time import sleep
from selenium.wevdriver.common.action_chains import ActionChians
from selenium.webdriver.common.by import By
#创建webDriver对象 Chrome()封装了谷歌的一些方法
#如果把驱动放置到了 系统环境变量目录中,可不带参数创建
driver=webdriver.Chrome()
#如果没有放置到系统环境变量目录中,需要通过参数指定
#driver = webdriver.chrome(executable_path="./chromedriver.exe")
#driver=webdriver.Chrome("chromedriver.exe")与代码同在一文件夹
url = 'https://www.baidu.com'
#使用浏览器打开指定页面
driver.get(url)
#右击
action = ActionChains(driver)
action.context_click(driver.find_element("id","su"))
#实践的操作一定要执行
action.perform()
sleep(3)
#关闭浏览器
driver.quit()02悬停:
悬停摄像头图标

#其他代码同上
action.move_to_element(driver.find_element("class name","soutu_btn"))eg2:
百度的:

driver.get('https://www.baidu.com')
item = driver.find_element('id', 's-usersetting-top')
ActionChains(driver).move_to_element(item).perform() # 模拟鼠标的移动操作
driver.find_element('link text', '高级搜索').click()隐藏不可操作:

可见可操作:

实操

driver.get('https://www.qq.com')
item = driver.find_element('class name', 'more-txt')
ActionChains(driver).move_to_element(item).perform()
driver.find_element('link text', '车型').click()03拖拽
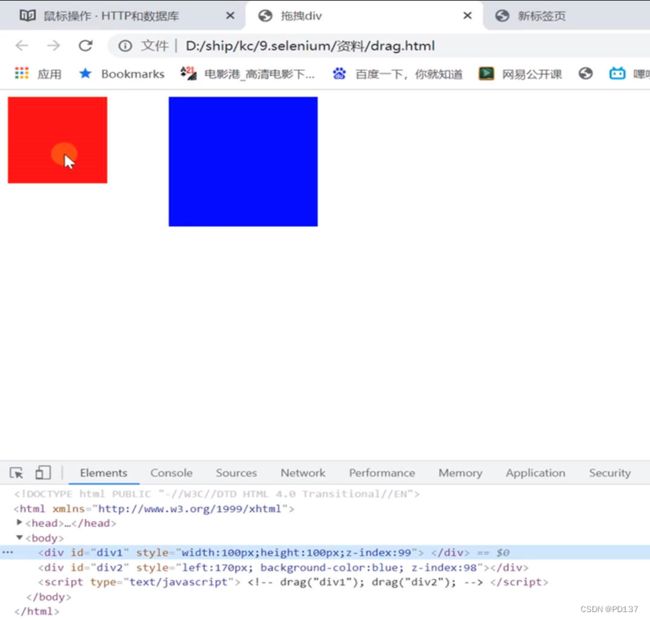
#拖拽
action.drag_and_drop(driver.find_element("id","div1"),
driver.find_element("id","div2"))5)键盘操作
- 方法
element.send_keys()- 参数
- 普通字符串
-
- ”键盘按键“
| 键值 |
解释 |
| send_keys(Keys.BACK_SPACE) |
删除键BackSpace |
| send_keys(Keys.SPACE) |
空格键Space |
| send_keys(Keys.TAB) |
制表键Tab |
| send_keys(Keys.ESPACE) |
回退键Esc |
| send_keys(Keys.ENTER) |
回车键Enter |
| send_keys(Keys.CONTROL,‘a’) |
全选Ctrl+A |
| send_keys(Keys.CONTROL,‘c’) |
复制CTRL+C |
| send_keys(Keys.CONTROL,‘x’) |
剪切CTRL+X |
| send_keys(Keys.CONTROL,‘v’) |
粘贴Ctrl+V |
| send_keys(Keys.F1) |
键盘F1 |
| send_keys(Keys.F12) |
键盘F12 |
- 例子

实例:

from selenium import webdriver
from time import sleep
from selenium.webdriver.common.keys import keys
#创建webDriver对象 Chrome()封装了谷歌的一些方法
#如果把驱动放置到了 系统环境变量目录中,可不带参数创建
driver=webdriver.Chrome()
#如果没有放置到系统环境变量目录中,需要通过参数指定
#driver = webdriver.chrome(executable_path="./chromedriver.exe")
url = 'https://www.baidu.com'
#使用浏览器打开指定页面
driver.get(url)
el = driver.find_element("id","kw")
#输入python
el.send_keys("python")
time.sleep(2)
#全选
el.send_keys(keys.CONTROL,"a")
time.sleep(2)
#回退键 删除
el.send_keys(keys.BACKSPACE)
time.sleep(2)
el.send_keys("博肖")
time.sleep(2)
#全选
el.send_keys(keys.CONTROL,"a")
time.sleep(2)
#复制
el.send_keys(keys.CONTROL,"c")
time.sleep(2)
#粘贴
el.send_keys(keys.CONTROL,"c")
time.sleep(2)
sleep(3)
#关闭浏览器
driver.quit()6)下拉框选择
下拉框是HTML
- 步骤
- 通过select元素创建出Select对象
- 通过Select对象的方法选中选项
- select_by_index() 根据option索引来定位,从0开始
- select_by_value() 根据option属性、value属性来定位
- select_by_visible_text()根据option显示文本来定位
- 例子:
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome(exectable_path="./chromedriver.exe")
url = r'C:\Users\T\注册A.html'
driver.get(url)
ele = driver.find_element(By.ID,'selectA')
#强转成select
select = Select(ele)
sleep(1)
#从0开始
select.select_by_index(2)
sleep(1)
select.select_by_value('bj')
sleep(1)
select.select_visible_text('A广州')
sleep(3)
driver.quit()
7)滚动条(直接执行js代码)
- 滚动条
往右右侧的滚动条,可以上下切换内容
- 限制与突破
webdriver类库中并没用直接提供滚动条进行操作方法,但是它提供了可调用JavaScript脚本的方法,所以可以通过javascript脚本来达到操作滚动条的目的。
- 方法
- 让浏览器执行js代码
driver.execute_script(js代码字符串)-
- 滚动的js代码
- 绝对滚动
- 滚动的js代码
window.scrollTo(x,y)-
-
- 相对滚动
-
window.scrollBy(x,y)- 扩展
通过driver的execute_script方法,可以做很多事情。
from selenium import webdriver
import time
driver=webdriver.Chrome()
url = 'https://www.douyu.com/directory/all'
driver.get(url)
driver.maxmize_window()
time.sleep(3)
driver.find_element_by_xpath("//*[@title='下一页']").click()
time.sleep(3)
#关闭浏览器
driver.quit()
#需要滚动条下拉才能刷新出内容
driver.get(url)
driver.maximize_window()
time.sleep(2)
js_str='window.scrollTo(0,10000)'
driver.execute_script(js_str)8)警告框
- 警告框
- 通过js中的alert、confirm、prompt方法弹出等待框,会阻挡对网页的继续操作。
- 相应方法
- alert=driver.switch_to.alert:获得警告框
-
- alert.dismiss():关闭警告框:适用于三种警告框
-
- alert.accrpt():确认(也会关闭警告框),适用于confirm和prompt
-
- alert.send_keys():输入文字,适用于prompt
-
- alert.text:获得警告框中的文字
示例:
from selenium import webdriver
import time
driver=webdriver.Chrome()
url = 'file:///D:/ship/eg.html'
driver.get(url)
time.sleep(2)
driver.finde_element("id","alerta").click()
#遇到警告框,切换到警告框,然后操作警告框
alert = driver.switch_to.alert
print(alert.text)
time.sleep(2)
alert.dismiss()
time.sleep(3)
#关闭浏览器
driver.quit()9)frame切换
- frame框架
- 此框架含义仅仅是”矩形区域“,在一个网页中,可以轻松套上另一个网页。对于html标签有