大数据HiveSQL学习笔记三-查询基础语法以及常用函数
大数据HiveSQL学习笔记三-查询基础语法以及常用函数
一、基础语法
1、SELECT …列名… FROM …表名… WHERE …筛选条件…
如:需要根据城市,性别找出匹配的10个用户
user_info:用户表
user_name 用户姓名
sex用户性别
SELECT user_name
FROM user_info
WHEREcity = ‘beijing’ and sex = ‘female’
limit 10;
注:如果该表是一个分区表,则WHERE条件中必须对分区字段进行限制
如:需找出2019-12-31日购买商品类型是food的用户名,购买数量,支付金额
user_trade(用户交易表):
pay_amount付款金额
goods_category购买物品品类
piece数量
SELECT user_name,
piece,
pay_amount
FROM user_trade
WHERE dt = ‘2019-12-31’ and goods_category = ‘food’;
2、GROUP BY分类汇总
如:2019年一月到三月,每个品类有多少人购买,累计金额是多少
SELECT goods_category,
count(distinct user_name) as user_num,
sum(pay_amount) as total_amount
FROM user_trade
WHERE dt between ‘2019-01-01’ and ‘2019-03-31’
GROUP BY goods_category;
GROUP BY … HAVING
如:2019年4月,支付金额超过5万元的用户
SELECT user_name,
sum(pay_amount) as total_pay_amount
FROM user_trade
WHERE dt between ‘2019-04-01’ and ‘2019-04-30’
GROUP BY user_name
HAVING sum(pay_amount) > 50000;
注:
HAVING:对GROUP BY 的对象进行筛选,是对聚合结果进行筛选而不是对原表进行筛选
3、ORDER BY
如:2019年4月,支付金额最多的TOP5用户
SELECT user_name,
sum(pay_amount) as total_amount
FROM user_trade
WHERE dt between ‘2019-04-01’ and ‘2019-04-30’
GROUP BY user_name
ORDER BY total_amount DESC
limit 5;
ASC:升序(默认 )
DESC:降序
对多个字段进行排序:ORDER BY 字段1 ASC, 字段2 DESC
每个字段都要指定升序还是降序
注:ORDER BY 后不直接写sum(pay_amount)而用total_amount是因为HiveSQL的执行顺序,ORDER BY的执行顺序在SELECT之后 ,所以需使用重新定义的列名进行排序
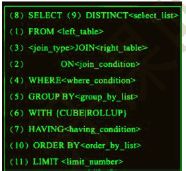
4、HiveSQL执行顺序
FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY->LIMIT
二、常用函数
查看Hive中的函数:show functioins;
查看具体函数的用法:
desc function 函数名;
desc function extended 函数名;
1、如何把时间戳转化为日期
函数:
from_unixtime(bigint unixtime, string format):
将时间戳转化为 指定格式的日期
format:
yyyy-MM-dd hh:mm:ss
yyyy-MM-dd hh
yyyy-MM-dd hh:mm
yyyyMMdd
函数:
unix_timestamp(string date)
将日期转化为时间戳
如:查询交易表中2019-04-01日,付款日期和付款日期对应的时间戳
SELECT pay_time,
from_unixtime(pay_time, ‘yyyy-MM-dd hh:mm:ss’)
FROM user_trade
WHERE dt = ‘2019-04-01’;
2、如何计算日期间隔
函数:
datediff(string enddate, string startdate)
结束日期减去开始日期的间隔天数
函数:
date_add(string startdate, int days)
起始日期加上间隔日期的最终日期
date_sub(string startdate, int days)
起始日期减去间隔日期的最终日期
如:查询用户首次激活日期与2019-05-01的日期间隔
SELECT user_name,
datediff(‘2019-05-01’, to_date(firstactivetime))
FROM user_info
limit 10;
3、条件函数
1)case when
如:在用户信息表中统计四个年龄段:
20岁以下,30-40岁, 40岁以上的用户数
SELECT case when age < 20 then ‘20岁以下’
when age >= 20 and age < 30 then ‘20-30岁’
when age >= 30 and age < 40 then ‘30-40岁’
else ‘40岁以上’ end as age_type,
count(distinct user_id) user_num
FROM user_info
GROUP BY case when age < 20 then ‘20岁以下’
when age >= 20 and age < 30 then ‘20-30岁’
when age >= 30 and age < 40 then ‘30-40岁’
else ‘40岁以上’ end;
2)if
如:用户信息表中根据每个用户性别,用户等级高低统计用户分布情况(level大于5为高级 )
SELECT sex,
if(level > 5, ‘高’, ‘低’) as level_type,
count(distinct user_id) as user_num
FROM user_info
GROUP BY sex,
if(level > 5, ‘高’, ‘低’);
4、字符串函数
1)substr字符串截取函数
函数 :
substr(string A, int start, int len)
截取字符串起始位置start长度len的字符串
如:根据user_info用户表中激活日期统计每个月的新用户数
SELECT substr(firstactivetime, 1, 7) as active_month,
count(distinct user_id) as user_num
FROM user_info
GROUP BY substr(firstactivetime, 1, 7);
2)获取json字符串函数
有些数据表字段值含有很多信息如:
字段1:
extra1(string):
{“systemtype”: “ios”, “education”: “master”, “marriage_status”: “1”, “phonebrand”: “Android”}
字段2:
extra2(map
{“systemtype”: “ios”, “education”: “master”, “marriage_status”: “1”, “phonebrand”: “Android”}
字段1可用json解析函数根据$.key取值
字段2可用字段[key]取出想要的值
函数:
get_json_object(string json_string, string path)
如:
根据user_info表中extra1或extra2中手机品牌信息统计用户分布情况
方法一:
SELECT get_json_object(extra1, ’ $.phonebrand’) as
phone_brand,
count(distinct user_id) as user_num
FROM user_info
GROUP BY get_json_object(extra1, ’ $.phonebrand ');
方法二:
SELECT extra2[‘phonebrand’] as phone_brand,
count(distinct user_id) as user_num
FROM user_info
GROUP BY extra2[‘phonebrand’];
5、聚合统计函数
常用聚合函数:
count():计数 (count(distinct…)去重计数
sum():求和
avg():平均值
max():最大值
min():最小值
如:名为’MARY‘的用户2018年平均每次支付 金额,以及2018年最大的支付日期与最小的支付日期间隔
SELECT avg(pay_amount) as avg_amount,
datediff(max(from_unixtime(pay_time, ‘yyyy-MM-dd’)), min(from_unixtime(pay_time, ‘yyyy-MM-dd’)))
FROM user_trade
WHERE year(dt) = ‘2018’ and user_name = ‘MARY’;
习题集
一、激活天数距今超过300天的男,女用户性别分布情况
注:
user_info:
firstactivetime首次激活时间
sex用户性别
SELECT sex,
count(distinct user_id)
FROM user_info
WHERE datediff(current_date(), to_date(firstactivetime)) > 300
GROUP BY sex;
二、不同性别,教育程度的分布情况
方法一:
SELECT sex,
get_json_object(extra1, ‘$.education’) as education,
count(distinct user_id)
FROM user_info
GROUP BY sex, get_json_object(extra1, ’ $.education’);
方法二:
SELECT sex,
extra2[‘education’] as education,
count(distinct user_id)
FROM user_info
GROUP BY sex, extra2[‘education’];
三、2019年1月1日到2019年4月30日全天时间段的不同品类购买金额分布
全天时间段应把时间用from_unixtime()转换为24小时制格式
注:12小时制格式:yyyy-MM-dd hh
24小时制格式:yyyy-MM-dd HH
user_trade(用户交易表):
pay_time付款时间
goods_category购买物品品类
SELECT substr(from_unixtie(pay_time, ‘yyyy-MM-dd HH’), 12) as pay_hour,
goods_category,
sum(pay_amount) as sum_amount
FROM user_trade
WHERE dt between ‘2019-01-01’ and ‘2019-04-30’
GROUP BY substr(from_unixtie(pay_time, ‘yyyy-MM-dd HH’), 12), goods_category;