音视频面试题集锦一
1)如何根据 NALU 裸流数据来判断其是 H.264 编码还是 H.265 编码?
1)通常在处理音视频数据时,我们如何选择解码器?
通常我们不是根据 NALU 裸流数据中的信息来选择解码器,而是根据媒体封装层的信息来确定解码器。
媒体封装层是表示媒体数据是什么封装格式的,比如 MP4、FLV。在这层信息里,通常会携带码流编码格式的信息。
拿 MP4 来说,我们可以根据 Sample Description Box(moov/trak/mdia/minf/stbl/stsd) 中的信息来确定其封装的码流的编码格式。
对于 FLV,我们可以根据 VideoTagHeader 中的 CodecID 等信息来确定其封装的码流的编码格式。
这样的好处是效率比较高,解封装的时候就可以确定选择何种解码器了。
2)怎么识别 NALU 裸流数据的编码格式是 H.264 还是 H.265?
但是,如果出现题目中的情况,没有对码流进行封装,而是直接传输码流时,这时候 NALU 中有什么字段能标识自己的编码格式吗?答案是,没有这样明确的字段能标识码流的编码格式。
但是这个问题也不是不能解决,因为 H.264、H.265 码流本身也是遵循一定格式规范的,我们可以按照它的格式规范进行探测,如果能解析出来正确的信息,那也可以确定它的编码格式。
比如,拿 H.265 来说,FFmpeg 中 hevcdec.c 就有对其码流数据进行探测的函数 hevc_probe(...)。
所以,我们可以按照编码格式规范探测,比如 H.265 如果解析出了 pps、sps、vps 的各字段信息符合规范,就认为它是 H.265 的编码;如果不是,在你们的码流格式范围中就只剩 H.264 了;接下来将码流数据交给对应的解码器解码即可。
2)为什么视频会议用 UDP?如果用 TCP 实现音视频,需要建立几次连接?用 UDP 实现音视频,有什么方法可以保证通话质量?
1)为什么视频会议用 UDP?
视频会议场景最重要的体验指标一般是『通话延时』和『语音音质』两方面。
在传输层使用 UDP 的主要考虑是为了降低通话延时。因为 UDP 的不需要 TCP 那样的面向连接、可靠传输、拥塞控制等机制,这些机制(比如三次握手建连、丢包重传等)通常都会带来相对 UDP 更高的延时。
当然,另外一方面原因是人们对视频会议中图像信息的损失容忍度是比较高的,这样即使 UDP 无法保证可靠性,有时候还是可以接受的。
2)如果用 TCP 实现音视频,需要建立几次连接?
可以做到只建连一次,多路复用。
也可以音频和视频各使用一路连接。
3)用 UDP 实现音视频,有什么方法可以保证通话质量?
使用 UDP 享受了低延时,牺牲了可靠性。但可靠性牺牲太多导致不可用也是不可接受的,所以还需要做一些机制来保证一定的可靠性,比如我们可以参考 WebRTC 的机制:
-
NACK:通过丢包重传解决丢包问题,会增加延时。
-
FEC:通过冗余数据解决丢包问题,会增加带宽占用。
-
JitterBuffer:通过队列对接收到的数据进行缓冲,出队时将数据包均匀平滑的取出,解决视频的乱序与抖动。
-
NetEQ:类似 JitterBuffer,解决音频的乱序与抖动。
3)CDN 在直播中有哪些运用?
CDN 的全称为 Content Delivery Network,即内容分发网络,是一个策略性部署的整体系统,主要用来解决由于网络带宽小、用户访问量大、网点分布不均匀等导致用户访问网站速度慢的问题。这中间就有了很多的 CDN 节点。
具体实现是通过在现有的网络中,增加一层新的网络架构,将网站的内容发布到离用户最近的网络节点上,这样用户可以就近获取所需的内容,解决之前网络拥塞、访问延迟高的问题,提高用户体验。
图一:CDN 各节点的协议

如图一所示,不同的流媒体走的节点和协议做了区分,网络拥塞减少,访问延迟降低,带宽得到良好的控制等等。CDN 直播中常用的流媒体协议包括 RTMP、HLS、HTTP FLV 等。RTMP(Real Time Messaging Protocol)是基于 TCP 的,由 Adobe 公司为 Flash 播放器和服务器之间音频、视频传输开发的开放协议。HLS(HTTP Live Streaming)是基于 HTTP 的,是 Apple 公司开放的音视频传输协议。HTTP FLV 则是将 RTMP 封装在 HTTP 协议之上的,可以更好的穿透防火墙等。
CDN 架构设计比较复杂,不同的 CDN 厂商,也在对其架构进行不断的优化,所以架构不能统一而论。这里只是对一些基本的架构进行简单的剖析。CDN 主要包含:源站、缓存服务器、智能 DNS、客户端等几个主要组成部分。
-
源站:是指发布内容的原始站点。添加、删除和更改网站的文件,都是在源站上进行的;另外缓存服务器所抓取的对象也全部来自于源站。对于直播来说,源站为主播客户端。
-
缓存服务器:是直接提供给用户访问的站点资源,由一台或数台服务器组成;当用户发起访问时,他的访问请求被智能 DNS 定位到离他较近的缓存服务器。如果用户所请求的内容刚好在缓存里面,则直接把内容返还给用户;如果访问所需的内容没有被缓存,则缓存服务器向邻近的缓存服务器或直接向源站抓取内容,然后再返还给用户。
-
智能 DNS:是整个 CDN 技术的核心,它主要根据用户的来源,以及当前缓存服务器的负载情况等,将其访问请求指向离用户比较近且负载较小的缓存服务器。通过智能 DNS 解析,让用户访问同服务商下、负载较小的服务器,可以消除网络访问慢的问题,达到加速作用。
-
客户端:即发起访问的普通用户。对于直播来说,就是观众客户端,例如手机客户端,PC 客户端。
图二:CDN 数据请求流程
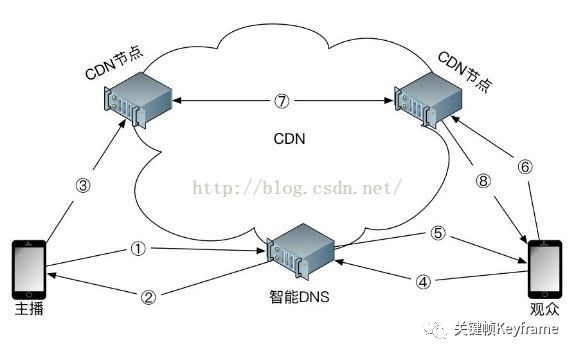
用图二表示整个流程描述如下:主播开始进行直播,向智能 DNS 发送解析请求,智能 DNS 返回最优 CDN 节点,IP 地址,主播端采集音视频数据,发送给 CDN 节点,CDN 节点进行缓存等处理,观众端要观看此主播的视频,向智能 DNS 发送解析请求,智能 DNS 返回最优 CDN 节点 IP 地址,观众端向 CDN 节点请求音视频数据,CDN 节点同步其他节点的音视频数据,CDN 节点将音视频数据发送给观众端。
4)为什么会有 YUV 这种数据?它相比 RGB 数据有什么优点?
RGB 工业显示器要求一幅彩色图像由分开的 R、G、B 信号组成,而电视显示器则需要混合信号输入,为了实现对这两种标准的兼容,NTSC(美国国家电视系统委员会)制定了 YIQ 颜色模型,它的主要优点是可以实现对彩色电视和黑白电视的兼容,即可以用黑白电视收看彩色电视信号。YUV 颜色模型则是在 YIQ 的基础上发展而来。
YUV 颜色模型中用亮度、色度来表示颜色。它的亮度信息和色度信息是分离的,其中 Y 表示亮度通道,U 和 V 则表示色度通道。如果只有 Y 信息,没有 U、V 信息,那么表示的图像就是灰度图像。YUV 常用在各种影像处理场景中。YUV 在对照片或视频编码时,考虑到人眼对亮度信息的敏感度高于色度信息,允许降低色度的带宽。这样一来就可以对色度信息进行压缩,所以 YUV 可以相对 RGB 使用更少的数据带宽。比如常见的采样格式有:4:2:1、4:1:1、4:2:0 等,它们分别相对 RGB 压缩了 33.3%、50%、50% 的数据量。
如果你也对音视频技术感兴趣,比如,符合下面的情况:
-
在校大学生 → 学习音视频开发
-
iOS/Android 客户端开发 → 转入音视频领域
-
直播/短视频业务开发 → 深入音视频底层 SDK 开发
-
音视频 SDK 开发 → 提升技能,解决优化瓶颈