最近公共祖先LCA 【@Abandon】
参考:
1.《算法艺术与信息学竞赛》 --- 刘汝佳
2. 博客:http://kmplayer.iteye.com/blog/604518
3. 博客:http://blog.163.com/kevinlee_2010/blog/static/16982082020120794613496/
最近公共祖先(LCA)问题
最近公共祖先(Least Common Ancestors,缩写为LCA)是一个有关树的基本问题,该问题的描述如下:
给出一棵有根树T,对于T中的任意两个节点u和v,求出LCA(T,u,v),即离根最远的节点(或者说,是离u和v最近的节点)r,使得r同时是u和v的祖先。
此问题可以看作是一种“询问—回答”式的问题。可以用两种方式来解决这种题目:一种是先进行充分的预处理,然后在每次回答询问的问题时,只需花少量的时间即可。这种算法叫做“在线算法”(online algorithm)。另一种是先将所有的询问收集(读入),然后再完成所有的回答。这种算法叫离线算法(Offline algorithm)。
最朴素的在线算法:
将节点u到根节点的路径(所有经过的节点)存到一个链表中,然后从v开始向根走,发现的第一个链表中的节点就是最近公共祖先。显然这两步最坏情况下都需要O(n),所以整个算法的最坏时间复杂度是O(Q*n),Q是询问的次数。
(用这个方法过POJ 1330无压力,因为那道题只有一个询问。。。)
一种在线O(n2)-O(1)递推想法:
令L(u)为节点u的深度(离根的距离)。则有如下结论:
if L(u) < L(v) then
if u == father(v) then LCA(u,v) = u;
else LCA(u,v) = LCA(u,father(v));
这样预处理的时间将达到O(n2),而询问只需要O(1)。
★离线的Tarjan算法:
tarjan算法利用了一个用于集合操作的数据结构-并查集(union-find set or disjoint set). 不过这里这个数据结构只是辅助性的,对于理解算法并无影响,理解了算法可以在去了解并查集是怎么一回事。
tarjan算法基于这样一个规律:假设当前节点为root,root节点肯定有很多子树了,那么我们从最左边的子树开始研究,如果要查询的两个节点u,v都在最左子树,那么这变成了一个更小规模的问题了。如果u在最左子树,而v在其他的子树,那么LCA(v,u)=father(u)了。那么如果u在最左子树的一个子树里边,那么LCA(v,u) = father(father(u)). 看到这里,熟悉并查集的同学,可能就知道了这就有点象查找集合的father信息。没错,这就是tarjan算法核心思想。
上述的方法看上去比较难处理,怎么样预先保存好father(u),怎么样知道LCA(u,v) = father(...father(...father(u)))?
这就是Tarjan算法的巧妙之处:利用递归的LCA(过程)。
伪代码:
void LCA(u){ MAKE-SET(u); ancestor(u) = u; for (u的每个儿子v){ LCA(v); Union(u,v); ancestor[FIND-SET[u]] = u; } color[u] = BLACK; //初始颜色都为白色,表示没有被访问过。 for (Q[u]中的所有v) if color[v] == BLACK ans_LCA(u,v) = ancestor[FIND-SET(v)]; }
考虑当我们完成LCA(u)后,以u为根的树的所有节点FIND-SET的father都是u了。那么对于每一个询问v,如果v已经被访问过,那么不外乎有两种情况:
1.v在u的子树中;
2.v不在u的子树中。
情况1好说,FIND-SET(v)自然就是u,v所在集合(子树)的father --- u。
那么考虑情况2。因为v已经被访问过,所以他可能出现在①以father(u)为根,u的左兄弟的子树中(我们默认树的遍历顺序是从左往右),此时FIND-SET(v) = father(u)(因为此时LCA过程已经到u,则说明u的左兄弟已经完成LCA过程并且被合并到了father(u)的集合中),而答案也确实应该如此不是么;②以father(father(u))为根,father(u)的左兄弟的子树中(因为如果不是①,则已经排除在father(u)中了嘛),同理,因为father(u)的左兄弟已经完成LCA过程,所以他们已经被合并到了father(father(u))代表的集合中,所以FIND-SET(v) = father(father(u))。这样就和实际应该的答案对应上了。
那么有人就会问了,①时的father(u),②时的father(father(u))就代表他们自己么?没被合并到他们的父亲中?显然没有。因为LCA(u)还正在进行,也就是说LCA(father(u))还没完成,LCA(father(father(u)))当然也还没完成。。。此时father(u),father(father(u))就在他自己的集合里,还没合并到父亲的集合中。
还是附个图比较好说明:(同一颜色表示同一集合)
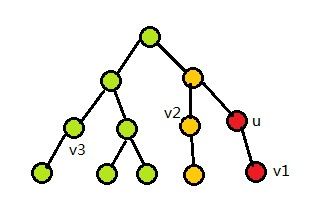
LCA习题:
POJ 1330 Nearest Common Ancestors (模板)
虽然这题水到朴素方法就可以而且很快,不过当入门LCA不错的。
 LCA模板---POJ 1330
LCA模板---POJ 1330

1 /* 2 LCA Tarjan模板 --- POJ 1330. 3 调用方法:离线把树的邻接表读进V.询问读进Q(Q[u],Q[v]两边都要存进去).然后对树根root调用LCA(root)即可得出这颗树的所有答案。当存在多个询问时可以考虑用map< pair<int ,int> int > ans;存储答案,不过同时也要注意pair<u,v>和pair<v,u>都要存。 4 @AbandonZHANG 5 */ 6 7 #include <iostream> 8 #include <cstdio> 9 #include <cstdlib> 10 #include <cmath> 11 #include <vector> 12 #include <stack> 13 #include <queue> 14 #include <map> 15 #include <algorithm> 16 #include <string> 17 #include <cstring> 18 #define MID(x,y) ((x+y)>>1) 19 20 using namespace std; 21 22 const int maxn = 10005; 23 struct Disjoint_Sets 24 { 25 int parent; 26 int rank; 27 }elem[maxn]; 28 void init() 29 { 30 for(int i = 0;i < maxn; i ++) 31 elem[i].parent = i, elem[i].rank = 1; 32 } 33 int Find(int x) 34 { 35 if (elem[x].parent != x) //路径压缩 36 elem[x].parent = Find(elem[x].parent); 37 return elem[x].parent; 38 } 39 void Union(int a,int b) //合并两个集合 40 { 41 int x,y; 42 x = Find(a), y = Find(b); 43 if(elem[x].rank >= elem[y].rank) 44 { 45 elem[y].parent = elem[x].parent; 46 elem[x].rank += elem[y].rank; 47 } 48 else 49 { 50 elem[x].parent = elem[y].parent; 51 elem[y].rank += elem[x].rank; 52 } 53 } 54 //LCA 55 int ancestor[maxn]; 56 bool vis[maxn]; 57 vector <int> Q[maxn]; 58 vector <int> V[maxn]; 59 struct Query 60 { 61 int u,v; 62 }que[maxn]; 63 void initLCA() 64 { 65 memset(ancestor,0,sizeof(ancestor)); 66 memset(vis,0,sizeof(vis)); 67 for (int i = 0; i < maxn; i ++) 68 { 69 V[i].clear(); 70 Q[i].clear(); 71 } 72 } 73 void LCA(int u) 74 { 75 ancestor[u] = u; 76 for (size_t i = 0; i < V[u].size(); i ++) 77 { 78 int v = V[u][i]; 79 LCA(v); 80 Union(u,v); 81 ancestor[Find(u)] = u; 82 } 83 vis[u] = 1; 84 for (size_t i = 0; i < Q[u].size(); i ++) 85 if (vis[Q[u][i]]) 86 { 87 printf("%d\n",ancestor[Find(Q[u][i])]); 88 return; 89 } 90 } 91 int indegree[maxn]; 92 int main() 93 { 94 //freopen("data.txt","r+",stdin); 95 int t; 96 scanf("%d",&t); 97 int n; 98 while(t--) 99 { 100 init(); 101 initLCA(); 102 memset(indegree,0,sizeof(indegree)); 103 scanf("%d",&n); 104 for (int i = 0; i < n - 1; i ++) 105 { 106 int s,t; 107 scanf("%d%d",&s,&t); 108 V[s].push_back(t); 109 indegree[t] ++; 110 } 111 int s,t; 112 scanf("%d%d",&s,&t); 113 Q[s].push_back(t); 114 Q[t].push_back(s); 115 for (int i = 1; i <= n; i ++) 116 if (indegree[i] == 0) 117 { 118 LCA(i); 119 break; 120 } 121 } 122 return 0; 123 }
其他待做题目:
POJ:
1330和1470是入门系列,可以说基本上时用来测试板子的
1986 比上面两个稍微多了一个距离,但是本质还是一样的对于一个询问d[u,v]=dis[u]+dis[v]-dis[LCA(u,v)]可以一边LCA一边动态修改当前点到根的距离
3728 其实就是记录的东西多了一点(1)孩子到父亲最大价格(2)孩子到父亲最小价格(3)从自己到祖先的最大收益 (4)从祖先到自己的最大收益,这里的分情况讨论只需要手动的画下草图,在使用并查集的同时,做更新操作,维护上面提到的四个变量,对于一个查询,我们用 爬山坡的方式保留最优值,这里画图会显的更为直观
3694 说实在的和LCA没有特别大的关系,就是dfs找割点,然后不是割点的点缩点,最后继续爬山坡,大概跑了1s多把,爬山坡顾名思义就是暴力的爬到祖先的意思
3417 LCA+DP
//对于新添加的m条边,我们来考虑其两个端点在树上的路径,加入新边后,显然在树上产生了环,如果去掉新边,在从原树中
//删除任何一条,那么整个图的连通性就会被破坏,从这点出发我们来看最后添加完m条边后的图,对于一条树上的边,如果他
//多于1个环所包围,那么删除一条边时无法使得图不连通的,故问题转化成了统计每条树边被多少个环所包含,这里的统计需
//要用到树形DP,dp[x]表示从x到跟的边背环覆盖的次数,那么对于新添加的一条边(x,y)对统计结果的影响就是 dp[x]++,dp[y]++,
//dp[lca(x,y)]-2,再来分析最终结果,对于被环包含为0的边,显然在图中是割边,那么删除它,然后从m条边中选择任意一条边
//都可以使徒步连通,对于被环包含一次的边,删除它,且删除环中且在m条边中的边就可以使边部连通,最后结果就是这两部分
//这里要注意的是,对于一个x=y的边,直接忽略它,我没加这句死活过不了
3237
LCA+RMQ,朴素的Tarjan应该也可以,把所有的查询预处理出来,但是写起来太烦了,正好借这个机会学习了RMQ的形式,先dfs将树化成欧拉序列,然后预处理rmq,对于取反,查询操作,同样采用爬山坡的方式,这样子问题就变的简单多了
2763
//具体做法:首先对于0操作,可以看成是与前一个位置形成的查询对
//然后记录下来,接着做LCA,在做LCA的时候,利用dfs记录下时间戳,
//这样我们就获得了一个区间,这个区间的表示代表了一颗子树,当然这里是可以用一颗线段树来维护的
//在每次搜到一条边时,把这个边的权值插入到树状数组中,往根上加,表示从子节点到跟的距离,由于根的起始时间必然是1
//那么很显然的我们只需要把当前结点的终止时间出加入当前边的权值,又从这个点之前的那个时间段,删除,这样实际上的效果就是
//把一条边的权值插入了,这里想了很久,那么修改操作呢,同样的道理 这里的时间戳n起始代表的就是根,为什么呢,每次添加边调整的都是
//子树,由于dfs,最后更新的必定是1这棵树
ZOJ 3195
//问题描述,给定一棵带边权的树,给定三个点的查询,求把他们连起来的最小代价
//两两求得距离之和除2,联系在数轴上的三个点,是不是也这么求
HDU 3078
标准做法应该是LCA+treap+线段树,这里可以用爬山坡的方式水,用一个栈记录、
HDU 2586
这道题题意是,给定一棵树,每条边都有一定的权值,q次询问,每次询问某两点间的距离。这样就可以用LCA来解,首先找到u, v 两点的lca,然后计算一下距离值就可以了。这里的计算方法是,记下根结点到任意一点的距离dis[],这样ans = dis[u] + dis[v] - 2 * dis[lca(v, v)]了,这个表达式还是比较容易理解的。。