深入理解C++11 | 第二章:保证稳定性和兼容性
文章目录
-
- 一、保持与C99兼容
-
- 1.1 预定义宏
- 1.2 __func__预定义标识符
- 1.3 _Pragma操作符
- 1.4 变长参数的宏定义以及 __VA_ARGS__
- 1.5 宽窄字符串的连接
- 二、long long整型
- 三、扩展的整型
- 四、宏__cplusplus
- 五、静态断言
-
- 5.1 断言:运行时与预处理时
- 5.2 静态断言与static_assert
- 六、noexcept修饰符与noexcept操作符
- 七、快速初始化成员变量
- 八、非静态成员的sizeof
- 九、扩展的friend语法
- 十、final/override控制
- 十一、模板函数的默认模板参数
- 十二、外部模板
-
- 12.2 显式的实例化与外部模板的声明
- 十三、局部和匿名类型作模板实参
- 十四、本章小结
注:本博客内容大多引用自原书,这里只做部分归纳和总结。其中,每个标题对应每章的一个小节。本篇博客仅用作学习用途 ,推荐阅读原书 《深入理解C++11:C++11新持性解析与应用》进行深入理解。
一、保持与C99兼容
C++11将对以下C99特性的支持也都纳入了新标准中:
❑ C99中的预定义宏
❑ __func__预定义标识符
❑ _Pragma操作符
❑ 不定参数宏定义以及__VA_ARGS__
❑ 宽窄字符串连接
1.1 预定义宏
C++11中与C99兼容的宏

使用这些宏,我们可以查验机器环境对C标准和C库的支持状况,如代码清单2-1所示。
#include 在我的试验机上(vs 2019 版本号:1923)没有 __STDC__ 与 __STDC_ISO_10646__ 这两个宏的定义。

预定义宏对于多目标平台代码的编写通常具有重大意义。通过以上的宏,程序员通过使用#ifdef/#endif等预处理指令,就可使得平台相关代码只在适合于当前平台的代码上编译,从而在同一套代码中完成对多平台的支持。从这个意义上讲,平台信息相关的宏越丰富,代码的多平台支持越准确。
不过值得注意的是,与所有预定义宏相同的,如果用户重定义(#define)或#undef了预定义的宏,那么后果是“未定义”的。因此在代码编写中,程序员应该注意避免自定义宏与预定义宏同名的情况。
1.2 __func__预定义标识符
func 预定义标识符功能,其基本功能就是返回所在函数的名字。我们可以看看下面这个例子,如代码清单2-2所示。
#include 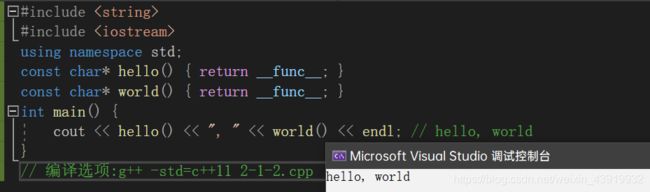
在代码清单2-2中,我们定义了两个函数hello和world。利用__func__预定义标识符,我们返回了函数的名字,并将其打印出来。事实上,按照标准定义,编译器会隐式地在函数的定义之后定义__func__标识符。比如上述例子中的hello函数,其实际的定义等同于如下代码:
const char* hello() {
static const char* __func__ = "hello";
return __func__;
}
__func__预定义标识符对于轻量级的调试代码具有十分重要的作用。而在C++11中,标准甚至允许其使用在类或者结构体中。我们可以看看下面这个例子,如代码清单2-3所示。
#include 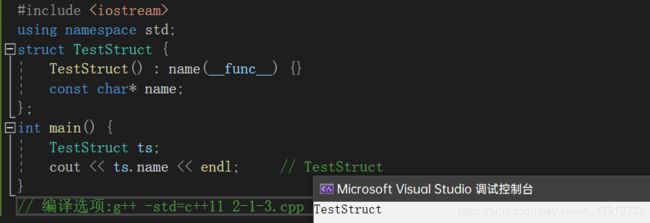
从代码清单2-3可以看到,在结构体的构造函数中,初始化成员列表使用__func__预定义标识符是可行的,其效果跟在函数中使用一样。不过将__fun__标识符作为函数参数的默认值是不允许的,如下例所示:
void FuncFail( string func_name = __func__) {};// 无法通过编译
这是由于在参数声明时,__func__还未被定义。
1.3 _Pragma操作符
#pragma是一条预处理的指令,用来向编译器传达语言标准以外的一些信息。举个简单的例子,以下是一些常用的 #pragma() 用法。
#pragma once // 确保头文件只展开一次
#pragma message(messageString) // 不中断编译的情况下,发送一个字符串文字量到标准输出
#pragma warning(disable:4996) // 不发出指定(4996)的警告信息
/* 可以使用以下条件编译方式代替 #pragma once 语句
#ifndef THIS_HEADER // 如果没有定义该宏(THIS_HEADER)
#define THIS_HEADER // 定义一个宏(THIS_HEADER)
// 一些头文件的定义
#endif // endif
*/
在C++11中,标准定义了与预处理指令#pragma功能相同的操作符_Pragma。_Pragma操作符的格式如下所示:
_Pragma (字符串字面量)
其使用方法跟sizeof等操作符一样,将字符串字面量作为参数写在括号内即可。那么要达到与上例#pragma类似的效果,则只需要如下代码即可。
_Pragma("once");
而相比预处理指令#pragma,由于_Pragma是一个操作符,因此可以用在一些宏中。我们可以看看下面这个例子:
#define CONCAT(x) PRAGMA(concat on #x)
#define PRAGMA(x) _Pragma(#x)
CONCAT( ..\concat.dir )
/* 关于#define,预编译阶段通过预处理器进行替换与展开,没有安全(类型)检查
用法:
1. #define 字符串
2. #define 宏名 字符串
3. #define 宏名(参数) 表达式
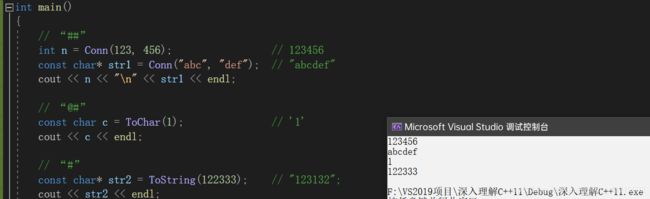
define中的三个特殊符号:#,##,#@
1."##"可用于“连接”两个宏参数 例如:#define Conn(x,y) x##y
int n = Conn(123,456); // 结果 n = 123456;
char* str1 = Conn("abc", "def"); // 结果 str1 = "abcdef";
2."#@x"给变量加上单引号,结果返回是一个const char
#define ToChar(x) #@x
const char c = ToChar(1); // 结果 c = '1';
3."#"给变量加上双引号,结果返回一个const char*
#define ToString(x) #x
const char* str2 = ToString(122333); // 结果 str2 = "122333";
// 示例参考自:https://www.cnblogs.com/fnlingnzb-learner/p/6903966.html
*/
注:这里的 _Pragma 宏定义编译不通过,只展示#define定义的三种宏函数用法。
CONCAT( …\concat.dir )最终会产生_Pragma(concaton “…\concat.dir”)这样的效果(这里只是显示语法效果,应该没有编译器支持这样的_Pragma语法)。
而#pragma则不能在宏中展开,因此从灵活性上来讲,C++11的_Pragma具有更大的灵活性。
1.4 变长参数的宏定义以及 VA_ARGS
在C99标准中,程序员可以使用变长参数的宏定义。变长参数的宏定义是指在宏定义中参数列表的最后一个参数为省略号,而预定义宏__VA_ARGS__则可以在宏定义的实现部分替换省略号所代表的字符串。比如:
#define PR(...) printf(__VA_ARGS__)
就可以定义一个printf的别名PR。事实上,变长参数宏与printf是一对好搭档。我们可以看如代码清单2-4所示的一个简单的变长参数宏的应用。
#include 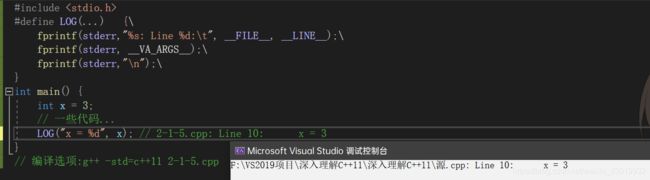
注:FILE 是编译器内置宏,表示包含当前程序文件名的字符串。 其相关宏有1 。
1.5 宽窄字符串的连接
在之前的C++标准中,将窄字符串(char)转换成宽字符串(wchar_t)是未定义的行为。而在C++11标准中,在将窄字符串和宽字符串进行连接时,支持C++11标准的编译器会将窄字符串转换成宽字符串,然后再与宽字符串进行连接。
对于字符的分类主要有单字节字符(窄字符)、多字节字符,以及宽字符。
- 窄字符字面量或普通字符字面量,例如
'a'或\n'或'\13'。这种字面量具有 char 类型,且其值等于 c-字符 在执行字符集中的表示。若 c-字符 在执行字符集中无法以单字节表示,则字面量具有 int 类型和实现定义的值。 - 宽字符字面量,例如 L’β’ 或 L’字’。这种字面量具有 wchar_t 类型,且其值等于 c-字符 在执行宽字符集中的值。若 c-字符 在执行宽字符集中无法表示(例如在 wchar_t 为 16 位的 Windows 上的非 BMP 值),则字面量的值是实现定义的。
- 多字符字面量,例如 ‘AB’,具有 int 类型和实现定义的值。
在C++11还定义了更多种类的字符串类型,在《深入理解C++11:C++11新持性解析与应用》一书中第8.3 、8.4节 中有详细介绍。
其中主要介绍了字符集、编码和Unicode,以及C++11引入的新的内置数据类型来存储不同编码长度的Unicode数据。如:
❑ char16_t:用于存储UTF-16编码的Unicode数据。
❑ char32_t:用于存储UTF-32编码的Unicode数据。
此外,C++11还定义了一些常量字符串的前缀。在声明常量字符串的时候,这些前缀声明可以让编译器使字符串按照前缀类型产生数据。事实上,C++11一共定义了3种这样的前缀:
❑ u8表示为UTF-8编码。
❑ u表示为UTF-16编码。
❑ U表示为UTF-32编码。
同时宽字符字面量用L前缀表示。如wchar ch[3] = L"你好";
二、long long整型
long long整型有两种:long long和unsigned long long。
在C++11中,标准要求long long整型可以在不同平台上有不同的长度,但至少有64位。我们在写常数字面量时,可以使用LL后缀(或是ll)标识一个long long类型的字面量,而ULL(或ull、Ull、uLL)表示一个unsigned long long类型的字面量。比如:
long long int lli = -9000000000000000000LL;
unsigned long long int ulli = -9000000000000000000ULL;
注:这里会有一个 “warning C4146: 一元负运算符应用于无符号类型,结果仍为无符号类型” 的警告,这是由于我们对无符号整形取负的操作造成的。如果在vs下编译显示报错而非警告的话,我们只需要关闭安全开发生命周期检查以解决这个错误。右键项目的名称——》属性 /C\C++ /常规——》点击SDL安全检查,选择否即可。

在C++11中,还有很多与longlong等价的类型。比如对于有符号的,下面的类型是等价的:long long、signed long long、long long int、signedlong long int;而unsigned long long和unsigned longlong int也是等价的。
同其他的整型一样,要了解平台上long long大小的方法就是查看(或
#include 
在代码清单2-5中,将以上3个宏打印了出来,对于printf函数来说,输出有符号的long long类型变量可以用符号%lld,而无符号的unsigned long long则可以采用%llu。18446744073709551615用16进制表示是0xFFFFFFFFFFFFFFFF(16个F),可知在我们的实验机上,long long是一个64位的类型。
三、扩展的整型
我们经常在代码中发现一些整型的名字,比如 UINT、__int16、u64、int64_t,等等。
这些类型有的源自编译器的自行扩展,有的则是来自某些编程环境(比如工作在Linux内核代码中),不一而足。而事实上,在C++11中一共只定义了以下5种标准的有符号整型:
❑ signed char
❑ short int
❑ int
❑ long int
❑ long long int
标准同时规定,每一种有符号整型都有一种对应的无符号整型(unsigned)版本,且有符号整型与其对应的无符号整型具有相同的存储空间大小。比如与signed int对应的无符号版本的整型是unsigned int。
在实际的编程中,由于这5种基本的整型适用性有限,所以有时编译器出于需要,也会自行扩展一些整型。在C++11中,标准对这样的扩展做出了一些规定。具体地讲,除了标准整型(standard integer type)之外,C++11标准允许编译器扩展自有的所谓扩展整型(extended integer type)。这些扩展整型的长度(占用内存的位数)可以比最长的标准整型(long long int,通常是一个64位长度的数据)还长,也可以介于两个标准整数的位数之间。比如在128位的架构上,编译器可以定义一个扩展整型来对应128位的的整数;而在一些嵌入式平台上,也可能需要扩展出48位的整型;不过C++11标准并没有对扩展出的类型的名称有任何的规定或建议,只是对扩展整型的使用规则做出了一定的限制。
C++11规定,扩展的整型必须和标准类型一样,有符号类型和无符号类型占用同样大小的内存空间。而由于C/C++是一种弱类型语言[插图],当运算、传参等类型不匹配的时候,整型间会发生隐式的转换,这种过程通常被称为整型的提升(Integral promotion)。比如如下表达式:
(int) a + (long long)b
通常就会导致变量(int)a被提升为long long类型后才与(longlong)b进行运算。而无论是扩展的整型还是标准的整型,其转化的规则会由它们的“等级”(rank)决定。
而通常情况,我们认为有如下原则:
❑ 长度越大的整型等级越高,比如long long int的等级会高于int。
❑ 长度相同的情况下,标准整型的等级高于扩展类型,比如long long int和_int64如果都是64位长度,则longlong int类型的等级更高。
❑ 相同大小的有符号类型和无符号类型的等级相同,long long int和unsigned long long int的等级就相同。
而在进行隐式的整型转换的时候,一般是按照低等级整型转换为高等级整型,有符号的转换为无符号。这种规则其实跟C++98的整型转换规则是一致的。

在这样的规则支持下,如果编译器定义一些自有的整型,即使这样自定义的整型由于名称并没有被标准收入,因而可移植性并不能得到保证,但至少编译器开发者和程序员不用担心自定义的扩展整型与标准整型间在使用规则上(尤其是整型提升)存在着不同的认识了。
比如在一个128位的构架上,编译器可以定义_int128_t为128位的有符号整型(对应的无符号类型为_uint128_t)。于是程序员可以使用_int128_t类型保存形如+92233720368547758070的超长整数(长于64位的自然数)。而不用查看编译器文档我们也会知道,一旦遇到整型提升,按照上面的规则,比如_int128_t a,与任何短于它的类型的数据b进行运算(比如加法)时,都会导致b被隐式地转换为_int128_t的整型,因为扩展的整型必须遵守C++11的规范。
四、宏__cplusplus
在C与C++混合编写的代码中,我们常常会在头文件里看到如下的声明:
#ifdef __cplusplus
extern "C" {
#endif
// 一些代码
#ifdef __cplusplus
}
#endif
这种类型的头文件可以被#include到C文件中进行编译,也可以被#include到C++文件中进行编译。
由于 extern “C” 可以抑制C++对函数名、变量名等符号(symbol)进行名称重整(name mangling),因此编译出的C目标文件和C++目标文件中的变量、函数名称等符号都是相同的(否则不相同),链接器可以可靠地对两种类型的目标文件进行链接。这样该做法成为了C与C++混用头文件的典型做法。
__cplusplus这个宏通常被定义为一个整型值。而且随着标准变化,__cplusplus宏一般会是一个比以往标准中更大的值。比如在C++03标准中,__cplusplus的值被预定为199711L,而在C++11标准中,宏__cplusplus被预定义为201103L。这点变化可以为代码所用。比如程序员在想确定代码是使用支持C++11编译器进行编译时,那么可以按下面的方法进行检测:
#if __cplusplus < 201103L
#error "should use C++11 implementation"
#endif
这里也可以直接输出 __cplusplus 宏的值。由于VS编译器在2017 版本 15.7 开始便已提供 /Zc:__cplusplus 选项,该选项在默认情况下处于禁用状态。并且在默认情况下或者在指定了 /Zc:__cplusplus- 的情况下,Visual Studio 针对 __cplusplus 预处理器宏返回值“199711L”。参考链接:/Zc:__cplusplus(启用更新的 __cplusplus 宏)

在/Zc:__cplusplus(启用更新的 __cplusplus 宏)中提到 默认情况下,Visual Studio 始终为 __cplusplus 预处理器宏返回值“199711L”如果启用 /Zc:__cplusplus,则 __cplusplus == _MSVC_LANG 则我们可以用 _MSVC_LANG 表示当前编译器所使用的的C++版本。如下图所示:
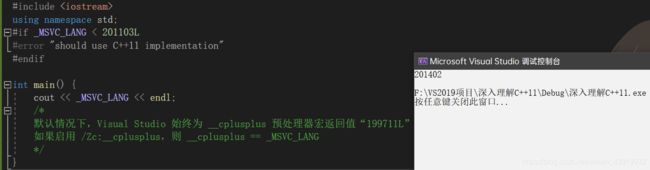
使用了预处理指令#error,这使得不支持C++11的代码编译立即报错并终止编译。
五、静态断言
5.1 断言:运行时与预处理时
断言(assertion)是一种编程中常用的手段。在通常情况下,断言就是将一个返回值总是需要为真的判别式放在语句中,用于排除在设计的逻辑上不应该产生的情况。比如一个函数总需要输入在一定的范围内的参数,那么程序员就可以对该参数使用断言,以迫使在该参数发生异常的时候程序退出,从而避免程序陷入逻辑的混乱。
从一些意义上讲,断言并不是正常程序所必需的,不过对于程序调试来说,通常断言能够帮助程序开发者快速定位那些违反了某些前提条件的程序错误。在C++中,标准在或
#include 
在C++中,程序员也可以定义宏NDEBUG来禁用assert宏。
用户对程序退出总是敏感的,而且部分的程序错误也未必会导致程序全部功能失效。我们可以通过定义NDEBUG宏,发布程序就可以尽量避免程序退出的状况。而当程序有问题时,通过没有定义宏NDEBUG的版本,程序员则可以比较容易地找到出问题的位置。事实上,assert宏在中的实现方式类似于下列形式:
#ifdef NDEBUG
# define assert(expr) (static_cast (0))
#else
...
#endif
可以看到,一旦定义了NDBUG宏,assert宏将被展开为一条无意义的C语句(通常会被编译器优化掉)。
在前面的代码中,我们还看到了#error这样的预处理指令,而事实上,通过预处理指令#if和#error的配合,也可以让程序员在预处理阶段进行断言。这样的用法也是极为常见的,比如GNU的cmathcalls.h头文件中(在我们实验机上,该文件位于/usr/include/bits/cmathcalls.h),我们会看到如下代码:
#ifndef _COMPLEX_H
#error "Never use directly; include instead."
#endif
如果程序员直接包含头文件
5.2 静态断言与static_assert
通过上面的例子可以看到,断言assert宏只有在程序运行时才能起作用。而**#error只在编译器预处理时才能起作用**。有的时候,我们希望在编译时能做一些断言。比如下面这个例子,如代码清单2-7所示。
#include 代码清单2-7所示的是C代码中常见的“按位存储属性”的例子。在该例中,我们编写了一个枚举类型FeatureSupports,用于列举编译器对各种特性的支持。而结构体Compiler则包含了一个int类型成员spp。由于各种特性都具有“支持”和“不支持”两种状态,所以为了节省存储空间,我们让每个FeatureSupports的枚举值占据一个特定的比特位置,并在使用时通过“或”运算压缩地存储在Compiler的spp成员中(即bitset的概念)。在使用时,则可以通过检查spp的某位来判断编译器对特性是否支持。
有的时候这样的枚举值会非常多,而且还会在代码维护中不断增加。那么代码编写者必须想出办法来对这些枚举进行校验,比如查验一下是否有重位等。在本例中程序员的做法是使用一个“最大枚举”SMAX,并通过比较SMAX -1与所有其他枚举的或运算值来验证是否有枚举值重位。可以想象,如果SAssert被误定义为0x0001,表达式(SMAX -1) == (C99|ExtInt | SAssert | NoExcept)将不再成立。
在本例中我们使用了断言assert。但assert是一个运行时的断言,这意味着不运行程序我们将无法得知是否有枚举重位。在一些情况下,这是不可接受的,因为可能单次运行代码并不会调用到assert相关的代码路径。因此这样的校验最好是在编译时期就能完成。
在一些C++的模板的编写中,我们可能也会遇到相同的情况,比如下面这个例子,如代码清单2-8所示。
#include 代码清单2-8中的assert是要保证a和b两种类型的长度一致,这样bit_copy才能够保证复制操作不会遇到越界等问题。这里我们还是使用assert的这样的运行时断言,但如果bit_copy不被调用,我们将无法触发该断言。实际上,正确产生断言的时机应该在模板实例化时,即编译时期。
在C++11标准中,引入了static_assert断言来解决这个问题。static_assert使用起来非常简单,它接收两个参数,一个是断言表达式,这个表达式通常需要返回一个bool值;一个则是警告信息,它通常也就是一段字符串。我们可以用static_assert替换一下代码清单2-8中bit_copy的声明。
#include 编译器错误 C2338:此错误可能是 static_assert 编译期间出错引起的。 消息由 static_assert 参数提供。参考自:编译器错误 C2338

这样的错误信息就非常清楚,也非常有利于程序员排错。而由于static_assert是编译时期的断言,其使用范围不像assert一样受到限制。在通常情况下,static_assert可以用于任何名字空间,如代码清单2-10所示。
static_assert(sizeof(int) == 8, "This 64-bit machine should follow this!");
int main() {
return 0;
}
// 编译选项:g++ -std=c++11 2-5-5.cpp
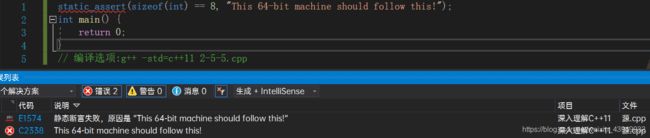
而在C++中,函数则不可能像代码清单2-10中的static_assert这样独立于任何调用之外运行。因此将static_assert写在函数体外通常是较好的选择,这让代码阅读者可以较容易发现static_assert为断言而非用户定义的函数。而反过来讲,必须注意的是,static_assert的断言表达式的结果必须是在编译时期可以计算的表达式,即必须是常量表达式。如果读者使用了变量,则会导致错误,如代码清单2-11所示。
int positive(const int n) {
static_assert(n > 0, "value must >0");
}
// 编译选项:g++ -std=c++11-c 2-5-6.cpp
代码清单2-11使用了参数变量n(虽然是个const参数),因而static_assert无法通过编译。对于此例,如果程序员需要的只是运行时的检查,那么还是应该使用assert宏。
六、noexcept修饰符与noexcept操作符
相比于断言适用于排除逻辑上不可能存在的状态,异常通常是用于逻辑上可能发生的错误。在C++98中,我们看到了一套完整的不同于C的异常处理系统。通过这套异常处理系统,C++拥有了远比C强大的异常处理功能。
在异常处理的代码中,程序员有可能看到过如下的异常声明表达形式:
void excpt_func() throw(int, double) { ... }
在excpt_func函数声明之后,我们定义了一个动态异常声明throw(int, double),该声明指出了excpt_func可能抛出的异常的类型。事实上,该特性很少被使用,因此在C++11中被弃用了(参见附录B),而表示函数不会抛出异常的动态异常声明throw()也被新的noexcept异常声明所取代。
noexcept形如其名地,表示其修饰的函数不会抛出异常。不过与throw()动态异常声明不同的是,在C++11中如果noexcept修饰的函数抛出了异常,编译器可以选择直接调用std::terminate()函数来终止程序的运行,这比基于异常机制的throw()在效率上会高一些。这是因为异常机制会带来一些额外开销,比如函数抛出异常,会导致函数栈被依次地展开(unwind),并依帧调用在本帧中已构造的自动变量的析构函数等。
从语法上讲,noexcept修饰符有两种形式,一种就是简单地在函数声明后加上noexcept关键字。比如:
void excpt_func() noexcept;
另外一种则可以接受一个常量表达式作为参数,如下所示:
void excpt_func() noexcept (常量表达式);
常量表达式的结果会被转换成一个bool类型的值。该值为true,表示函数不会抛出异常,反之,则有可能抛出异常。这里,不带常量表达式的noexcept相当于声明了noexcept(true),即不会抛出异常。
在通常情况下,在C++11中使用noexcept可以有效地阻止异常的传播与扩散。我们可以看看下面这个例子,如代码清单2-12所示。
#include 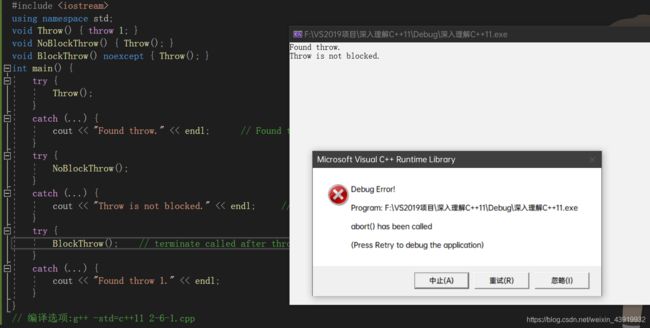
在代码清单2-12中,我们定义了Throw函数,该函数的唯一作用是抛出一个异常。而NoBlockThrow是一个调用Throw的普通函数,BlockThrow则是一个noexcept修饰的函数。从main的运行中我们可以看到,NoBlockThrow会让Throw函数抛出的异常继续抛出,直到main中的catch语句将其捕捉。而BlockThrow则会直接调用std::terminate中断程序的执行,从而阻止了异常的继续传播。从使用效果上看,这与C++98中的throw()是一样的。
noexcept作为一个操作符时,通常可以用于模板。比如:
template <class T>
void fun() noexcept(noexcept(T())) {}
这里,fun函数是否是一个noexcept的函数,将由T()表达式是否会抛出异常所决定。这里的第二个noexcept就是一个noexcept操作符。当其参数是一个有可能抛出异常的表达式的时候,其返回值为false,反之为true。这样一来,我们就可以使模板函数根据条件实现noexcept修饰的版本或无noexcept修饰的版本。从泛型编程的角度看来,这样的设计保证了关于“函数是否抛出异常”这样的问题可以通过表达式进行推导。因此这也可以视作C++11为了更好地支持泛型编程而引入的特性。
虽然noexcept修饰的函数通过std::terminate的调用来结束程序的执行的方式可能会带来很多问题,比如无法保证对象的析构函数的正常调用,无法保证栈的自动释放等,但很多时候,“暴力”地终止整个程序确实是很简单有效的做法。事实上,noexcept被广泛地、系统地应用在C++11的标准库中,用于提高标准库的性能,以及满足一些阻止异常扩散的需求。
比如在C++98中,存在着使用throw()来声明不抛出异常的函数。
template<class T> class A {
public:
static constexpr T min() throw() { return T(); }
static constexpr T max() throw() { return T(); }
static constexpr T lowest() throw() { return T(); }
...
而在C++11中,则使用noexcept来替换throw()。
template<class T> class A {
public:
static constexpr T min() noexcept { return T(); }
static constexpr T max() noexcept { return T(); }
static constexpr T lowest() noexcept { return T(); }
...
又比如,在C++98中,new可能会包含一些抛出的std::bad_alloc异常。
void* operator new(std::size_t) throw(std::bad_alloc);
void* operator new[](std::size_t) throw(std::bad_alloc);
而在C++11中,则使用noexcept(false)来进行替代。
void* operator new(std::size_t) noexcept(false);
void* operator new[](std::size_t) noexcept(false);
当然,noexcept更大的作用是保证应用程序的安全。比如一个类析构函数不应该抛出异常,那么对于常被析构函数调用的delete函数来说,C++11默认将delete函数设置成noexcept,就可以提高应用程序的安全性。
void operator delete(void*) noexcept;
void operator delete[](void*) noexcept;
而同样出于安全考虑,C++11标准中让类的析构函数默认也是noexcept(true)的。当然,如果程序员显式地为析构函数指定了noexcept,或者类的基类或成员有noexcept(false)的析构函数,析构函数就不会再保持默认值。我们可以看看下面的例子,如代码清单2-13所示。
#include 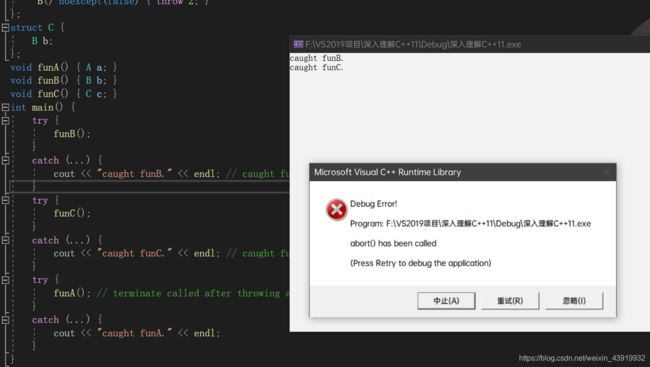
在代码清单2-13中,无论是析构函数声明为noexcept(false)的类B,还是包含了B类型成员的类C,其析构函数都是可以抛出异常的。只有什么都没有声明的类A,其析构函数被默认为noexcept(true),从而阻止了异常的扩散。这在实际的使用中,应该引起程序员的注意。
七、快速初始化成员变量
在C++98中,支持了在类声明中使用等号“=”加初始值的方式,来初始化类中静态成员常量。这种声明方式我们也称之为“就地”声明。就地声明在代码编写时非常便利,不过C++98对类中就地声明的要求却非常高。如果静态成员不满足常量性,则不可以就地声明,而且即使常量的静态成员也只能是整型或者枚举型才能就地初始化。而非静态成员变量的初始化则必须在构造函数中进行。我们来看看下面的例子,如代码清单2-14所示。
class Init {
public:
Init() : a(0) {}
Init(int d) : a(d) {}
private:
int a;
const static int b = 0;
int c = 1; // 成员,无法通过编译
static int d = 0; // 成员,无法通过编译
static const double e = 1.3; // 非整型或者枚举,无法通过编译
static const char* const f = "e"; // 非整型或者枚举,无法通过编译
};
// 编译选项:g++ -c 2-7-1.cpp
在代码清单2-14中,成员c、静态成员d、静态常量成员e以及静态常量指针f的就地初始化都无法通过编译(这里,使用g++的读者可能发现就地初始化double类型静态常量e是可以通过编译的,不过这实际是GNU对C++的一个扩展,并不遵从C++标准)。在C++11中,标准允许非静态成员变量的初始化有多种形式。具体而言,除了初始化列表外,在C++11中,标准还允许使用等号=或者花括号{}进行就地的非静态成员变量初始化。比如:
struct init{ int a = 1; double b {1.2}; };
在这个名叫init的结构体中,我们给了非静态成员a和b分别赋予初值1和1.2。这在C++11中是一个合法的结构体声明。虽然这里采用的一对花括号{}的初始化方法读者第一次见到,不过在第3章(下一篇博客)中,读者会在C++对于初始化表达式的改动发现,花括号式的集合(列表)初始化已经成为C++11中初始化声明的一种通用形式,而其效果类似于C++98中使用圆括号()对自定义变量的表达式列表初始化。不过在C++11中,对于非静态成员进行就地初始化,两者却并非等价的,如代码清单2-15所示。
#include 从代码清单2-15中可以看到,就地圆括号式的表达式列表初始化非静态成员b和c都会导致编译出错。
// 补充:在代码清单2-15中,可以使用 = ,{} ,的方式初始化
//string b("hello"); // 无法通过编译
string b1 = "hello";
string b{ "hello" };
//C c(1); // 无法通过编译
C c1 = 1;
C c2 = { 1 };
在C++11标准支持了就地初始化非静态成员的同时,初始化列表这个手段也被保留下来了。如果两者都使用,是否会发生冲突呢?我们来看下面这个例子,如代码清单2-16所示。
#include 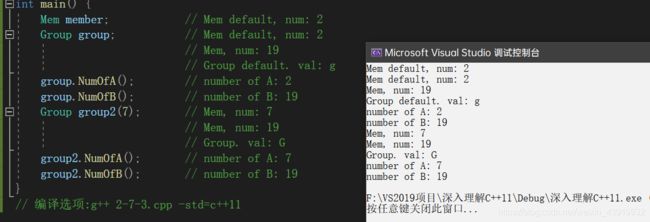
在代码清单2-16中,我们定义了有两个初始化函数的类Mem,此外还定义了包含两个Mem对象的Group类。类Mem中的成员变量num,以及class Group中的成员变量a、b、val,采用了与C++98完全不同的初始化方式。读者可以从main函数的打印输出中看到,就地初始化和初始化列表并不冲突。程序员可以为同一成员变量既声明就地的列表初始化,又在初始化列表中进行初始化,只不过初始化列表总是看起来“后作用于”非静态成员。也就是说,初始化列表的效果总是优先于就地初始化的(就是说:如果不存在初始化列表,先使用就地初始化的默认值,如果存在初始化列表,直接使用初始化列表赋值。之后在执行构造函数的函数体)。
相对于传统的初始化列表,在类声明中对非静态成员变量进行就地列表初始化可以降低程序员的工作量。当然,我们只在有多个构造函数,且有多个成员变量的时候可以看到新方式带来的便利。我们来看看下面的例子,如代码清单2-17所示。
#include 在代码清单2-17中,Group有4个构造函数。可以想象,如果我们使用的是C++98的编译器,我们不得不在Group()、Group(int a),以及Group(Mem m)这3个构造函数中将data、mem、name这3个成员都写进初始化列表。但如果使用的是C++11的编译器,那么通过对非静态成员变量的就地初始化,我们就可以避免重复地在初始化列表中写上每个非静态成员了(在C++98中,我们还可以通过调用公共的初始化函数来达到类似的目的,不过目前在书写的复杂性及效率性上远低于C++11改进后的做法)。
此外,值得注意的是,对于非常量的静态成员变量,C++11则与C++98保持了一致。程序员还是需要到头文件以外去定义它,这会保证编译时,类静态成员的定义最后只存在于一个目标文件中。不过对于静态常量成员,除了const关键字外,在本书第6章中我们会看到还可以使用constexpr来对静态常量成员进行声明。
八、非静态成员的sizeof
从C语言被发明开始,sizeof就是一个运算符,也是C语言中除了加减乘除以外为数不多的特殊运算符之一。而在C++引入类(class)类型之后,sizeof的定义也随之进行了拓展。不过在C++98标准中,对非静态成员变量使用sizeof是不能够通过编译的。我们可以看看下面的例子,如代码清单2-18所示。
#include 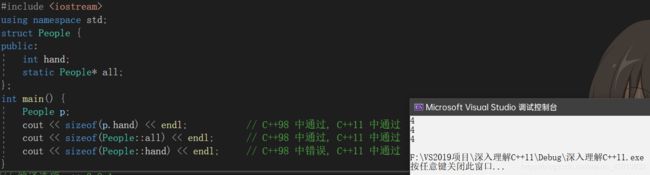
注意最后一个sizeof操作。在C++11中,对非静态成员变量使用sizeof操作是合法的。而在C++98中,只有静态成员,或者对象的实例才能对其成员进行sizeof操作。因此如果读者只有一个支持C++98标准的编译器,在没有定义类实例的时候,要获得类成员的大小,我们通常会采用以下的代码:
sizeof(((People*)0)->hand);
这里我们强制转换0为一个People类的指针,继而通过指针的解引用获得其成员变量,并用sizeof求得该成员变量的大小。而在C++11中,我们无需这样的技巧,因为sizeof可以作用的表达式包括了类成员表达式。
sizeof(People::hand);
可以看到,无论从代码的可读性还是编写的便利性,C++11的规则都比强制指针转换的方案更胜一筹。
九、扩展的friend语法
friend关键字在C++中是一个比较特别的存在。因为我们常常会发现,一些面向对象程序语言,比如Java,就没有定义friend关键字。friend关键字用于声明类的友元,友元可以无视类中成员的属性。无论成员是public、protected或是private的,友元类或友元函数都可以访问,这就完全破坏了面向对象编程中封装性的概念。因此,使用friend关键字充满了争议性。在通常情况下,面向对象程序开发的专家会建议程序员使用Get/Set接口来访问类的成员,但有的时候,friend关键字确实会让程序员少写很多代码。因此即使存在争论,friend还是在很多程序中被使用到。而C++11对friend关键字进行了一些改进,以保证其更加好用。我们可以看看下面的例子,如代码清单2-19所示。
class Poly;
typedef Poly P;
class LiLei {
friend class Poly; // C++98通过, C++11通过
};
class Jim {
friend Poly; // C++98失败, C++11通过
};
class HanMeiMei {
friend P; // C++98失败, C++11通过
};
// 编译选项:g++ -std=c++11 2-9-1.cpp
在C++11中,声明一个类为另外一个类的友元时,不再需要使用class关键字。
本例中的Jim和HanMeiMei就是这样一种情况,在HanMeiMei的声明中,我们甚至还使用了Poly的别名P,这同样是可行的。
虽然在C++11中这是一个小的改进,却会带来一点应用的变化—程序员可以为类模板声明友元了。这在C++98中是无法做到的。比如下面这个例子,如代码清单2-20所示。
class P;
template <typename T> class People {
friend T;
};
People<P> PP; // 类型P在这里是People类型的友元
People<int> Pi; // 对于int类型模板参数,友元声明被忽略
// 编译选项:g++ -std=c++11 2-9-2.cpp
从代码清单2-20中我们看到,对于People这个模板类,在使用类P为模板参数时,P是People
的一个friend类。而在使用内置类型int作为模板参数的时候,People会被实例化为一个普通的没有友元定义的类型。这样一来,我们就可以在模板实例化时才确定一个模板类是否有友元,以及谁是这个模板类的友元。这是一个非常有趣的小特性,在编写一些测试用例的时候,使用该特性是很有好处的。我们看看下面的例子,该例子源自一个实际的测试用例,如代码清单2-21所示。
// 为了方便测试,进行了危险的定义
#ifdef UNIT_TEST
#define private public
class Defender {
#endif
public:
void Defence(int x, int y) {}
void Tackle(int x, int y) {}
private:
int pos_x = 15;
int pos_y = 0;
int speed = 2;
int stamina = 120;
};
class Attacker {
public:
void Move(int x, int y) {}
void SpeedUp(float ratio) {}
private:
int pos_x = 0;
int pos_y = -30;
int speed = 3;
int stamina = 100;
};
#ifdef UNIT_TEST
class Validator {
public:
void Validate(int x, int y, Defender& d) {}
void Validate(int x, int y, Attacker& a) {}
};
int main() {
Defender d;
Attacker a;
a.Move(15, 30);
d.Defence(15, 30);
a.SpeedUp(1.5f);
d.Defence(15, 30);
Validator v;
v.Validate(7, 0, d);
v.Validate(1, -10, a);
return 0;
}
#endif
// 编译选项:g++ 2-9-3.cpp -std=c++11-DUNIT_TEST
测试人员为了能够快速写出测试程序,采用了比较危险的做法,即使用宏将private关键字统一替换为public关键字。这样一来,类中的private成员就都成了public的。
这样的做法存在4个缺点:
一是如果侥幸程序中没有变量包含private字符串,该方法可以正常工作,但反之,则有可能导致严重的编译时错误;
二是这种做法会降低代码可读性,因为改变了一个常见关键字的意义,没有注意到这个宏的程序员可能会非常迷惑程序的行为;
三是如果在类的成员定义时不指定关键字(如public、private、protect等),而使用默认的private成员访问限制,那么该方法也不能达到目的;
四则很简单,这样的做法看起来也并不漂亮。
不过由于有了扩展的friend声明,在C++11中,我们可以将Defender和Attacker类改良一下。我们看看下面的例子,如代码清单2-22所示。
template <typename T> class DefenderT {
public:
friend T;
void Defence(int x, int y) {}
void Tackle(int x, int y) {}
private:
int pos_x = 15;
int pos_y = 0;
int speed = 2;
int stamina = 120;
};
template <typename T> class AttackerT {
public:
friend T;
void Move(int x, int y) {}
void SpeedUp(float ratio) {}
private:
int pos_x = 0;
int pos_y = -30;
int speed = 3;
int stamina = 100;
};
using Defender = DefenderT<int>; // 普通的类定义,使用int做参数
using Attacker = AttackerT<int>;
#ifdef UNIT_TEST
class Validator; // 声明类 class Validator;
using DefenderTest = DefenderT<Validator>; // 测试专用的定义,Validator类成为友元
using AttackerTest = AttackerT<Validator>;
class Validator {
public:
void Validate(int x, int y, DefenderTest& d) {}
void Validate(int x, int y, AttackerTest& a) {}
};
int main() {
DefenderTest d;
AttackerTest a;
a.Move(15, 30);
d.Defence(15, 30);
a.SpeedUp(1.5f);
d.Defence(15, 30);
Validator v;
v.Validate(7, 0, d);
v.Validate(1, -10, a);
return 0;
}
#endif
// 编译选项:g++ 2-9-4.cpp -std=c++11-DUNIT_TEST
注:如果在编译器上以编译,请手动定义一个#define UNIT_TEST 宏。在命令行编译使用命令 g++ 2-9-4.cpp -std=c++11-DUNIT_TEST
在代码清单2-22中,我们把原有的Defender和Attacker类定义为模板类DefenderT和AttackerT。
其中模板类DefenderT和AttackerT最终生成了两个版本的类:
- DefenderTest及AttackerTest版本,使用Validator为模板参数。特点:Validator是它们的友元,可以任意访问任何成员函数。
- Defender和Attacker版本,使用int为模板参数。特点:该版本的类没有友元,保持了良好的封装性,可以用于提供接口用于常规使用。
在代码清单2-22中,我们使用了using来定义类型的别名,这跟使用typedef的定义类型的别名是完全一样的。使用using定义类型别名是C++11中的一个新特性,我们可以在3.10节(下一篇博客)中看到相关的描述。
十、final/override控制
在了解C++11中的final/override关键字之前,我们先回顾一下C++关于重写的概念。
注:原书中把override 翻译为重载,而根据博主所查阅的资料显示类中函数关系有三种,分别为重载、隐藏、覆盖(重写)
重载:是指同一可访问区内被声明的几个具有不同参数列(参数的类型,个数,顺序不同)的同名函数,根据参数列表确定调用哪个函数,重载不关心函数返回类型。
隐藏:是指派生类的函数屏蔽了与其同名的基类函数,注意只要同名函数,不管参数列表是否相同,基类函数都会被隐藏。
重写(覆盖):是指派生类中存在重新定义的函数。其函数名,参数列表,返回值类型,所有都必须同基类中被重写的函数一致。只有函数体不同(花括号内),派生类调用时会调用派生类的重写函数,不会调用被重写函数。重写的基类中被重写的函数必须有virtual修饰。
根据本节知识点为动多态,类的继承和虚函数相关,因此在这里把原文中的“重载”一词统一替换成了“重写”一词。
简单地说,一个类A中声明的虚函数fun在其派生类B中再次被定义,且B中的函数fun跟A中fun的原型一样(函数名、参数列表等一样),那么我们就称B重写(overload)了A的fun函数。对于任何B类型的变量,调用成员函数fun都是调用了B重写的版本。而如果同时有A的派生类C,却并没有重写A的fun函数,那么调用成员函数fun则会调用A中的版本。这在C++中就实现多态。
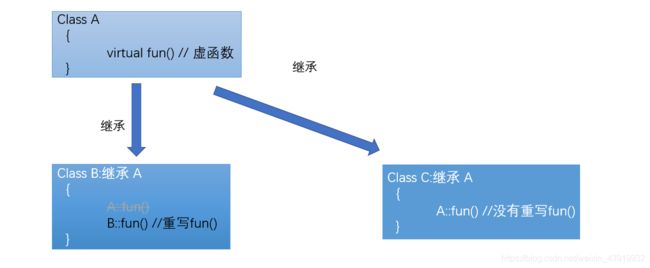
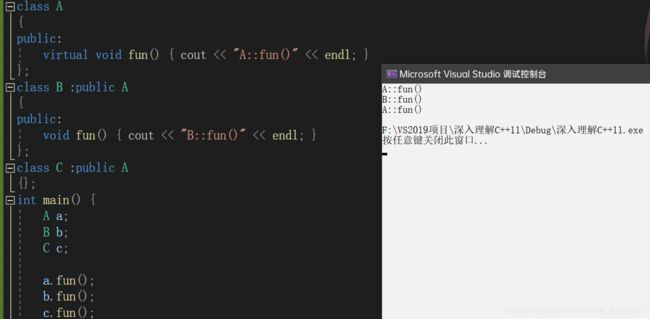
在通常情况下,一旦在基类A中的成员函数fun被声明为virtual的,那么对于其派生类B而言,fun总是能够被重写的。有的时候我们并不想fun在B类型派生类中被重写,那么,C++98没有方法对此进行限制。我们看看下面这个具体的例子,如代码清单2-23所示。
#include 在代码清单2-23中,我们的基础类MathObject定义了两个接口:Arith和Print。类Printable则继承于MathObject并实现了Print接口。接下来,Add2和Mul3为了使用MathObject的接口和Printable的Print的实现,于是都继承了Printable。这样的类派生结构,在面向对象的编程中非常典型。不过倘若这里的Printable和Add2是由两个程序员完成的,Printable的编写者不禁会有一些忧虑,如果Add2的编写者重写了Print函数,那么他所期望的统一风格的打印方式将不复存在。
对于Java这种所有类型派生于单一元类型(Object)的语言来说,这种问题早就出现了。因此Java语言使用了final关键字来阻止函数继续重写。final关键字的作用是使派生类不可覆盖它所修饰的虚函数。C++11也采用了类似的做法,如代码清单2-24所示的例子。
struct Object{
virtual void fun() = 0;
};
struct Base : public Object {
void fun() final; // 声明为final
};
struct Derived : public Base {
void fun(); // 无法通过编译
};
// 编译选项:g++ -c -std=c++11 2-10-2.cpp
类成员函数声明为final表示这是最后一次重写,那么派生于Base的Derived类对接口fun的重写则会导致编译时的错误。同理,在代码清单2-23中,Printable的编写者如果要阻止派生类重写Print函数,只需要在定义时使用final进行修饰就可以了。
有意思的是final关键字也可以作用于基类中的虚函数,不过这样将使用该虚函数无法被重写,也就失去了虚函数的意义。如果不想成员函数被重写,程序员可以直接将该成员函数定义为非虚的。而final通常只在继承关系的“中途”终止派生类的重写中有意义。从接口派生的角度而言,final可以在派生过程中任意地阻止一个接口的可重写性,这就给面向对象的程序员带来了更大的控制力。
如何得知某个继承来的函数是虚函数还是非虚函数?
C++中重写还有一个特点,就是对于基类声明为virtual的函数,之后的重写版本都不需要再声明该重写函数为virtual。即使在派生类中声明了virtual,该关键字也是编译器可以忽略的。这带来了一些书写上的便利,却带来了一些阅读上的困难。比如代码清单2-23中的Printable的Print函数,程序员无法从Printable的定义中看出Print是一个虚函数还是非虚函数。另外一点就是,在C++中有的虚函数会“跨层”,没有在父类中声明的接口有可能是祖先的虚函数接口。比如在代码清单2-23中,如果Printable不声明Arith函数,其接口在Add2和Mul3中依然是可重写的,这同样是在父类中无法读到的信息。这样一来,如果类的继承结构比较长(不断地派生)或者比较复杂(比如偶尔多重继承),派生类的编写者会遇到信息分散、难以阅读的问题(虽然有时候编辑器会进行提示,不过编辑器不是总是那么有效)。而自己是否在重写一个接口,以及自己重写的接口的名字是否有拼写错误等,都非常不容易检查。
在C++11中为了帮助程序员写继承结构复杂的类型,引入了虚函数描述符override,如果派生类在虚函数声明时使用了override描述符,那么该函数必须重写其基类中的同名函数,否则代码将无法通过编译。我们来看一下如代码清单2-25所示的这个简单的例子。
struct Base {
virtual void Turing() = 0;
virtual void Dijkstra() = 0;
virtual void VNeumann(int g) = 0;
virtual void DKnuth() const;
void Print();
};
struct DerivedMid : public Base {
// void VNeumann(double g);
// 接口被隔离了,曾想多一个版本的VNeumann函数
};
struct DerivedTop : public DerivedMid {
void Turing() override;
void Dikjstra() override; // 无法通过编译,拼写错误,并非重写
void VNeumann(double g) override; // 无法通过编译,参数不一致,并非重写
void DKnuth() override; // 无法通过编译,常量性不一致,并非重写
void Print() override; // 无法通过编译,非虚函数重写
};
// 编译选项:g++ -c -std=c++11 2-10-3.cpp
可以看到DerivedTop的作者在重写所有Base类的接口的时候,犯下了3种不同的错误:
❑ 函数名拼写错,Dijkstra误写作了Dikjstra。
❑ 函数原型不匹配,VNeumann函数的参数类型误做了double类型,而DKnuth的常量性在派生类中被取消了。
❑ 重写了非虚函数Print。
如果没有override修饰符,DerivedTop的作者可能在编译后都没有意识到自己犯了这么多错误。因为编译器对以上3种错误不会有任何的警示。这里override修饰符则可以保证编译器辅助地做一些检查。我们可以看到,在代码清单2-25中,DerivedTop作者的4处错误都无法通过编译。
值得注意的是,final/override也可以定义为正常变量名,只有在其出现在函数后时才是能够控制继承/派生的关键字。通过这样的设计,很多含有final/override变量或者函数名的C++98代码就能够被C++编译器编译通过了。但出于安全考虑,建议读者在C++11代码中应该尽可能地避免这样的变量名称或将其定义在宏中,以防发生不必要的错误。
十一、模板函数的默认模板参数
在C++11中模板和函数一样,可以有默认的参数。这就带来了一定的复杂性。我可以通过代码清单2-26所示的这个简单的模板函数的例子来回顾一下函数模板的定义。
#include (1))
TempFun("1"); // 1, (实例化为TempFun("1"))
}
// 编译选项:g++ 2-11-1.cpp
在代码清单2-26中,当编译器解析到函数调用fun(1)的时候,发现fun是一个函数模板。这时候编译器就会根据实参1的类型const int推导实例化出模板函数void TempFun(int),再进行调用。相应的,对于fun(“1”)来说也是类似的,不过编译器实例化出的模板函数的参数的类型将是const char *。
函数模板在C++98中与类模板一起被引入,不过在模板类声明的时候,标准允许其有默认模板参数。默认的模板参数的作用好比函数的默认形参。然而由于种种原因,C++98标准却不支持函数模板的默认模板参数。不过在C++11中,这一限制已经被解除了,我们可以看看下面这个例子,如代码清单2-27所示。
void DefParm(int m = 3) {} // c++98编译通过,c++11编译通过
template <typename T = int>
class DefClass {}; // c++98编译通过,c++11编译通过
template <typename T = int>
void DefTempParm() {}; // c++98编译失败,c++11编译通过
// 编译选项:g++ -c -std=c++11 2-11-1.cpp
不过在语法上,与类模板有些不同的是,类模板在为多个默认模板参数声明指定默认值的时候,程序员必须遵照“从右往左”的规则进行指定。而这个条件对函数模板来说并不是必须的,如代码清单2-28所示。
template<typename T1, typename T2 = int> class DefClass1;
template<typename T1 = int, typename T2> class DefClass2; // 无法通过编译
template<typename T, int i = 0> class DefClass3;
template<int i = 0, typename T> class DefClass4; // 无法通过编译
template<typename T1 = int, typename T2> void DefFunc1(T1 a, T2 b);
template<int i = 0, typename T> void DefFunc2(T a);
// 编译选项:g++ -c -std=c++11 2-11-2.cpp
从代码清单2-28中可以看到,不按照从右往左定义默认类模板参数的模板类DefClass2和DefClass4都无法通过编译。而对于函数模板来说,默认模板参数的位置则比较随意。
函数模板的参数推导规则也并不复杂。简单地讲,如果能够从函数实参中推导出类型的话,那么默认模板参数就不会被使用,反之,默认模板参数则可能会被使用。我们可以看看下面这个来自于C++11标准草案的例子,如代码清单2-29所示。
template <class T, class U = double>
void f(T t = 0, U u = 0);
void g() {
f(1, 'c'); // f(1,'c')
f(1); // f(1,0), 使用了默认模板参数double
f(); // 错误: T无法被推导出来
f<int>(); // f(0,0), 使用了默认模板参数double
f<int,char>(); // f(0,0)
}
// 编译选项:g++ -std=c++11 2-11-3.cpp
还有一点应该强调一下,模板函数的默认形参不是模板参数推导的依据。函数模板参数的选择,总是由函数的实参推导而来的 。
十二、外部模板
外部模板”是C++11中一个关于模板性能上的改进。实际上,“外部”(extern)这个概念早在C的时候已经就有了。通常情况下,我们在一个文件中a.c中定义了一个变量int i,而在另外一个文件b.c中想使用它,这个时候我们就会在没有定义变量i的b.c文件中做一个外部变量的声明。比如:
extern int i;
这样做的好处是,在分别编译了a.c和b.c之后,其生成的目标文件a.o和b.o中只有i这个符号的一份定义。
具体地,a.o中的i是实在存在于a.o目标文件的数据区中的数据,而在b.o中,只是记录了i符号会引用其他目标文件中数据区中的名为i的数据。这样一来,在链接器(通常由编译器代为调用)将a.o和b.o链接成单个可执行文件(或者库文件)c的时候,c文件的数据区也只会有一个i的数据(供a.c和b.c的代码共享)。
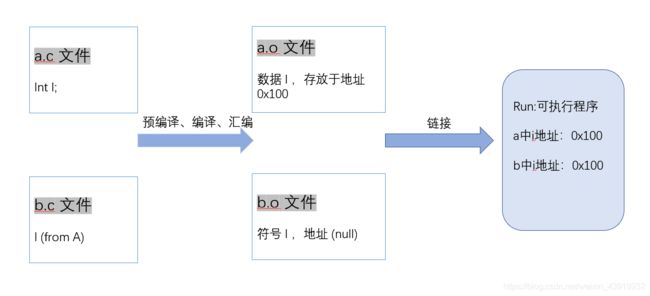
而如果b.c中我们声明int i的时候不加上extern的话,那么i就会实实在在地既存在于a.o的数据区中,也存在于b.o的数据区中。那么链接器在链接a.o和b.o的时候,就会报告错误,因为无法决定相同的符号是否需要合并。
而对于函数模板来说,现在我们遇到的几乎是一模一样的问题。不同的是,发生问题的不是变量(数据),而是函数(代码)。这样的困境是由于模板的实例化带来的。
注意 这里我们以函数模板为例,因为其只涉及代码,讲解起来比较直观。如果是类模板,则有可能涉及数据,不过其原理都是类似的。
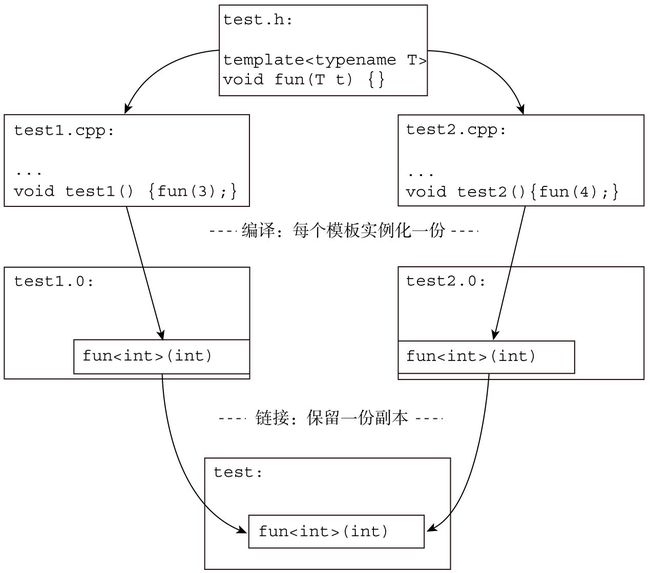
比如,我们在一个test.h的文件中声明了如下一个模板函数:
template <typename T> void fun(T) {}
在第一个test1.cpp文件中,我们定义了以下代码:
#include "test.h"
void test1() { fun(3); }
而在另一个test2.cpp文件中,我们定义了以下代码:
#include "test.h"
void test2() { fun(4); }
由于两个源代码使用的模板函数的参数类型一致,所以在编译test1.cpp的时候,编译器实例化出了函数fun(int),而当编译test2.cpp的时候,编译器又再一次实例化出了函数fun(int)。那么可以想象,在test1.o目标文件和test2.o目标文件中,会有两份一模一样的函数fun(int)代码。
代码重复和数据重复不同。数据重复,编译器往往无法分辨是否是要共享的数据;而代码重复,为了节省空间,保留其中之一就可以了(只要代码完全相同)。事实上,大部分链接器也是这样做的。在链接的时候,链接器通过一些编译器辅助的手段将重复的模板函数代码fun(int)删除掉,只保留了单个副本。这样一来,就解决了模板实例化时产生的代码冗余问题。我们可以看看图2-1中的模板函数的编译与链接的过程示意。
不过读者也注意到了,对于源代码中出现的每一处模板实例化,编译器都需要去做实例化的工作;而在链接时,链接器还需要移除重复的实例化代码。很明显,这样的工作太过冗余,而在广泛使用模板的项目中,由于编译器会产生大量冗余代码,会极大地增加编译器的编译时间和链接时间。解决这个问题的方法基本跟变量共享的思路是一样的,就是使用“外部的”模板。
12.2 显式的实例化与外部模板的声明
外部模板的使用实际依赖于C++98中一个已有的特性,即显式实例化(Explicit Instantiation)。显式实例化的语法很简单,比如对于以下模板:
template <typename T> void fun(T) {}
我们只需要声明:
template void fun<int>(int);
这就可以使编译器在本编译单元中实例化出一个fun(int)版本的函数(这种做法也被称为强制实例化)。而在C++11标准中,又加入了外部模板(Extern Template)的声明。语法上,外部模板的声明跟显式的实例化差不多,只是多了一个关键字extern。对于上面的例子,我们可以通过:
extern template void fun<int>(int);
这样的语法完成一个外部模板的声明。
那么回到一开始我们的例子,来修改一下我们的代码。首先,在test1.cpp做显式地实例化:
#include "test.h"
template void fun<int>(int); // 显示地实例化
void test1() { fun(3); }
接下来,在test2.cpp中做外部模板的声明:
#include "test.h"
extern template void fun<int>(int); // 外部模板的声明
void test1() { fun(3); }
这样一来,在test2.o中不会再生成fun(int)的实例代码。整个模板的实例化流程如图2-2所示。
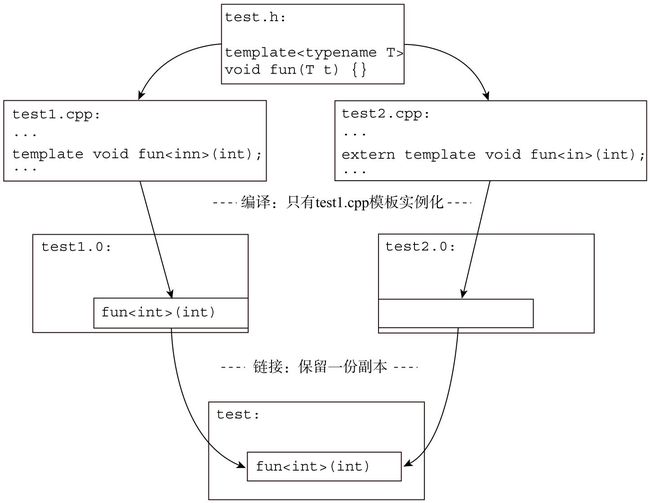
由于test2.o不再包含fun(int)的实例,因此链接器的工作很轻松,基本跟外部变量的做法是一样的,即只需要保证让test1.cpp和test2.cpp共享一份代码位置即可。而同时,编译器也不用每次都产生一份fun(int)的代码,所以可以减少编译时间。这里也可以把外部模板声明放在头文件中,这样所有包含test.h的头文件就可以共享这个外部模板声明了。这一点跟使用外部变量声明是完全一致的。
在使用外部模板的时候,我们还需要注意以下问题:
如果外部模板声明出现于某个编译单元中,那么与之对应的显示实例化必须出现于另一个编译单元中或者同一个编译单元的后续代码中;
外部模板声明不能用于一个静态函数(即文件域函数),但可以用于类静态成员函数(这一点是显而易见的,因为静态函数没有外部链接属性,不可能在本编译单元之外出现)。
在实际上,C++11中“模板的显式实例化定义、外部模板声明和使用”好比“全局变量的定义、外部声明和使用”方式的再次应用。不过相比于外部变量声明,不使用外部模板声明并不会导致任何问题。如我们在本节开始讲到的,外部模板定义更应该算作一种针对编译器的编译时间及空间的优化手段。很多时候,由于程序员低估了模板实例化展开的开销,因此大量的模板使用会在代码中产生大量的冗余。这种冗余,有的时候已经使得编译器和链接器力不从心。但这并不意味着程序员需要为四五十行的代码写很多显式模板声明及外部模板声明。只有在项目比较大的情况下。我们才建议用户进行这样的优化。总的来说,就是在既不忽视模板实例化产生的编译及链接开销的同时,也不要过分担心模板展开的开销。
十三、局部和匿名类型作模板实参
在C++98中,标准对模板实参的类型还有一些限制。具体地讲,局部的类型和匿名的类型在C++98中都不能做模板类的实参。比如,如代码清单2-30所示的代码在C++98中很多都无法编译通过。
template <typename T> class X {};
template <typename T> void TempFun(T t){};
struct A{} a;
struct {int i;}b; // b是匿名类型变量
typedef struct {int i;}B; // B是匿名类型
void Fun()
{
struct C {} c; // C是局部类型
X<A> x1; // C++98通过,C++11通过
X<B> x2; // C++98错误,C++11通过
X<C> x3; // C++98错误,C++11通过
TempFun(a); // C++98通过,C++11通过
TempFun(b); // C++98错误,C++11通过
TempFun(c); // C++98错误,C++11通过
}
// 编译选项:g++ -std=c++11 2-13-1.cpp
可以看到,使用了局部的结构体C及变量c,以及匿名的结构体B及变量b的模板类和模板函数,在C++98标准下都无法通过编译。而除了匿名的结构体之外,匿名的联合体以及枚举类型,在C++98标准下也都是无法做模板的实参的。如今看来这都是不必要的限制。所以在C++11中标准允许了以上类型做模板参数的做法,故而用支持C++11标准的编译器编译以上代码,代码清单2-30所示代码可以通过编译。
不过值得指出的是,虽然匿名类型可以被模板参数所接受了,但并不意味着以下写法可以被接受,如代码清单2-31所示。
template <typename T> struct MyTemplate { };
int main() {
MyTemplate<struct { int a; }> t; // 无法编译通过, 匿名类型的声明不能在模板实参位置
return 0;
}
// 编译选项:g++ -std=c++11 2-13-2.cpp
在代码清单2-31中,我们把匿名的结构体直接声明在了模板实参的位置。这种做法非常直观,但却不符合C/C++的语法。在C/C++中,即使是匿名类型的声明,也需要独立的表达式语句。要使用匿名结构体作为模板参数,则可如同代码清单2-30一样对匿名结构体作别名。此外在第4章我们还会看到使用C++11独有的类型推导decltype,也可以完成相同的功能。
十四、本章小结
以下全部引用自书中 2.14 本章小结 内容 。
在本章中,我们可以看到C++11大大小小共17处改动。这17处改动,主要都是为保持C++的稳定性以及兼容性而增加的。
比如为了兼容C99,C++11引入了4个C99的预定的宏、__func__预定义标识符、_Pragma操作符、变长参数定义,以及宽窄字符连接等概念。这些都是错过了C++98标准,却进入了C99的一些标准,为了最大程度地兼容C,C++将这些特性全都纳入C++11。而由于标准的更新,C++11也更新了__cplusplus宏的值,以表示新的标准的到来。而为了稳定性,C++11不仅纳入了C99中的long long类型,还将扩展整型的规则预先定义好。这样一来,就保证了各个编译器扩展内置类型遵守统一的规则。此外,C++11还将做法不一的静态断言做成了编译器级别的支持,以方便程序员使用。而通过抛弃throw()异常描述符和新增可以推导是否抛出异常的noexcept异常描述符,C++11又对标准库大量代码做了改进。
在类方面,C++11先是对非静态成员的初始化做了改进,同时允许sizeof直接作用于类的成员,再者C++11对friend的声明予以了一定扩展,以方便通过模板的方式指定某个类是否是其他类或者函数的友元。而final和override两个关键字的引入,则又为对象编程增加了实用的功能。而在模板方面,C++11则把默认模板参数的概念延伸到了模板函数上。而且局部类型和匿名类型也可以用做模板的实参。这两个约束的解除,使得模板的使用中需要记忆的规则又少了一些。而外部模板声明的引入,C++11又为很看重编译性能的用户提供了一些优化编译时间和内存消耗的方法。
在读者读完并理解了这些特性之后,会发现它们几乎像是一台轰鸣作响的机器上的螺丝钉、润滑油、电线丝。C++标准委员会则通过这些小修小补,让C++11已有的特性看起来更加成熟,更加完美。在这一章里,虽然有的特性会带来一些“小欣喜”,但我们还看不到脱胎换骨、让人眼前一亮的新特性。不过这些零散的特性又确实非常重要,是C++发展中必要的“维护”过程的必然结果。
不过如同我们讲到的,C++11其实已经看起来像一门新的语言了。在接下来的几章中,我们会看到更多更“闪亮”的新特性。如果读者已经等不及了,那么请现在就翻开下一页。
| 宏 | 说明 |
|---|---|
__FILE__ |
包含当前程序文件名的字符串 |
__LINE__ |
表示当前行号的整数 |
__DATE__ |
包含当前日期的字符串 |
__STDC__ |
如果编译器遵循ANSI C标准,它就是个非零值 |
__TIME__ |
包含当前时间的字符串 |
__cplusplus |
当编写C++程序时该标识符被定义。 |
与代码编译有关的宏: ↩︎