单目3D目标检测综述
0 安装ffmpeg
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
sudo apt-get update
sudo apt-get install ffmpeg
视频抽成图片:ffmpeg -i output-processed.avi -q:v 2 -f image2 frame_%06d.jpg
(注:上述代码中,
-i 是用来获取输入的文件,-i “*.avi” 就是获取这个叫做星号的avi视频文件;
此外还有一些参数:
-r 是设置每秒提取图片的帧数,-r 1的意思就是设置为每秒获取一帧;
-q:v 2 这个据说是提高抽取到的图片的质量的;
-f 据说是强迫采用格式fmt
)
截取指定起始和截止点的视频片段:
ffmpeg -i 123.mp4 -vcodec copy -acodec copy -ss 00:00:10 -to 00:00:15 123_output.mp4 -y图片合成视频
ffmpeg -f image2 -i %*.jpg 123.mp41 3D目标检测 任务:
3D检测任务一般通过图像、点云等输入数据,预测目标相比于相机或lidar坐标系的[x,y,z]、[h,w,l],[θ,φ,ψ](中心坐标,box长宽高信息,相对于xyz轴的旋转角度)。
 相机
相机
图像特点:捕捉W×H×3大小的图像。其中W和H是一幅图像的宽高,每个像素有3个RGB通道
优点:便宜且容易使用
缺点:无法捕捉深度信息,鲁棒性低
LiDAR传感器(激光雷达)
原理:通过发射一束激光束,然后测量其反射信息来获得场景的细粒度3D结构信息。
图像特点:产生深度图像,每个像素有3个通道,分别为球坐标系中的深度r、方位角α和倾角φ。
球坐标系转换成笛卡尔坐标系,生成点云。一个点云可以表示为N×3,其中N表示一个场景中的点数,每个点有3个xyz坐标通道。
优点:适合3D目标检测
缺点:价格贵,不适合大规模应用
2 单目3D检测
单目无法提供足够的3D信息,很多方法利用几何约束和形状先验从图像中推断深度信息,检测性能比激光雷达相比较差。
- 单目3D检测通常会生成中间的特征表示形式,主要可以划分为以下三类:
- 直接法(Direct Methods): 结合2D图像平面和3D空间的几何关系从图像中估计出3D检测框。直接法的缺点也比较明显,由于检测框直接从2D图像中获取,没有明确的深度信息,因此定位能力相对较差。
- 基于深度的方法(Depth-Based Methods): 利用深度估计网络估计出图像的中每个像素对应的深度图,再将深度图直接作为输入or与原图结合or转换成3D点云数据(伪激光雷达Pseudo-LiDAR)用于3D目标检测任务。该方法的缺点是其深度和目标检测分离训练的结构,导致其可能会丢失一些隐含的信息。
- 基于网格的方法(Grid-Based Methods) : 通过预测出BEV网格表示替代通过深度估计作为3D检测输入的方法,通常转化步骤是通过利用体素网格把体素投影到图像平面上然后采样图像特征将其转换成BEV的形式。这种方法可能会导致大量体素和特征的重叠从而降低检测的准确性。
01纯图像单目3D检测(Image-only monocular 3D object detection)
检测方法:直接回归法,通过卷积神经网络从图像中直接回归3D框参数,端到端训练
方法分类:
- 基于anchor的方法:
- 预先设置好3D-anchor、2D-anchor、深度anchor,然后图像经过卷积网络后得到2D和3D的预测偏置
- anchor-free的方法:
- 通过2D卷积对图像进行处理,利用多个头去预测3D目标。
- 具体包括一个分类头、一个关键点头预测粗粒度中心点、一个预测基于粗粒度中心点的偏置的头、预测深度的头、预测目标尺寸的头以及预测观测角的头。
- 两阶段单目检测方法:
- 第一阶段利用2D检测器从输入图像生成2D目标框。
- 第二阶段,通过从2D的ROI中预测3D目标参数,将2D框提升到3D空间。
02深度辅助的单目3D检测(Depth-assisted monocular 3D object detection) ,需要额外的像素级别的深度标注,成本高。而且泛化能力差。
- 深度估计
- 首先通过预训练的深度估计器,如MonoDepth或DORN,生成深度图像
- 然后两类方法处理深度图像和单目图像
- 基于深度图像的方法:将图像和深度映射与专门的神经网络融合,生成深度感知特征,可以提高检测性能。
- 基于伪激光雷达的方法:将深度图像转换为伪激光雷达点云,然后在点云上应用基于激光雷达的3D检测器来检测3D目标。
3 Deep3DBox
Deep3DBox是论文3D Bounding Box Estimation Using Deep Learning and Geometry中的方法,被CVPR2017收录,首先使用网络回归出相对稳定的3D目标的特性,再利用估计出来的3D特征和由2D bounding box转换为3D bounding box时的几何约束来产生最终的结果。文章先回归方向和尺寸,再结合几何约束产生3D位姿。Deep3DBox能从单目中恢复3D距离尺寸信息,但是它需要学习全连接层的参数,与使用附加信息的方法相比,需要更多的训练数据。GS3D是CVPR2019上的一篇paper,论文发现3D的大致的位置其实是可以从2D检测以及一些先验知识中进行恢复的,(这些先验知识包含了3D-2D的投影矩阵),因此作者设计了有效的算法,通过2D的检测去获取一个基本的长方体,而这个长方体可以引导我们去确定3D物体的尺寸,称为Guidance。除此之外,基本的3D信息可以被使用(通过使用3D bbox投影之后在2D图像上的surface等细节)。基于上述的观察,作者认为更进一步的分类以及回归的网络对bbox进行refinement对于减少FP以及回归的精度是非常必要的。论文使用CNN预测目标物的2D BBox,观察角,并根据先验知识(物体的长宽高、3D框底面中心在2D下边框中心偏上)和相机内参矩阵求得物体在相机坐标系下的3D坐标,根据3D坐标位置和观察角得到物体可视面,并将其投影至2D特征平面提取特征进一步优化3D预测框结果,如下图所示!
4 SMOKE
SMOKE是纵目科技在2020年提出的单目3D检测新方法,论文展示了一种新的3D目标检测方法,该方法通过将单个关键点估计与回归3D变量相结合来预测每个检测到的目标3D bounding box。SMOKE延续了centernet的key-point做法,认为2d检测模块是多余的,只保留了3d检测模块,预测投影下来的3dbox中心点和其他属性变量得到3dbox。整体来说SMOKE框架简洁,性能当年还算不错,推理速度快,部署起来方便!
5 FCOS3D
FCOS3D是基于 FCOS 改进的 3d 目标检测方案,在 NeurIPS 2020 中的nuScenes 3d 检测比赛上取得了第一名成绩,论文将 7-DoF 3D 目标解耦为 2D 和 3D 的属性,考虑到目标的二维比例,将目标分布到不同的特征级别,并仅根据训练过程的投影三维中心进行分配,除此之外,centerness 根据三维中心重新定义为二维高斯分布,以适应三维目标公式,网络结构如下所示:

6 FCOS3D++
FCOS3D++是CoRL 2021的单目三维目标检测算法,继承FCOS3D思路,论文提出单目三维目标检测可以简化为实例深度估计问题。不精确的实例深度估计阻碍了所有其他三维特性预测,限制了整体检测性能提高。前面的工作直接基于孤立的实例或者像素估计深度,忽略了不同目标之间的几何关系。因此,FCOS3D++构建了预测的目标之间的几何关系图,促进深度预测。FCOS3D++结合概率表示来捕获深度估计的不确定性,首先将深度值划分为一系列离散的区间,然后通过分布的期望来计算深度值,从分布中得到的top-k的置信度的平均值视作深度的不确定性。为了建模几何关系,构建了一个深度传播图来利用上下文信息促进深度估计。每个实例深度的不确定性为实例深度传播提供了有效指引。利用这一整体机制,可以很容易地利用高置信度确定预测。更重要的是,利用基于图的协同机制可以更精确地预测深度。论文提出的方法在KITTI和nuScenes基准上单目第一!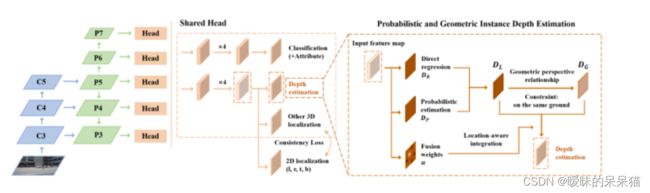
7 MonoFlex
MonoFlex作者考虑到了目标的截断属性,提出了一种灵活的单目3D目标检测框架,使用边缘特征解耦了截断目标和正常目标,分开处理,在比较重要的深度估计方面,作者使用了直接预测法、基于关键点的几何计算法,同时结合不确定性,使深度估计的更准确。也是引入深度估计来提升单目3D检测性能!KITTI上SOTA!
8 CaDDN
单目3D检测通常会生成中间的特征表示形式,主要可以划分为以下三类:
- 直接法(Direct Methods): 结合2D图像平面和3D空间的几何关系从图像中估计出3D检测框。直接法的缺点也比较明显,由于检测框直接从2D图像中获取,没有明确的深度信息,因此定位能力相对较差。
- 基于深度的方法(Depth-Based Methods): 利用深度估计网络估计出图像的中每个像素对应的深度图,再将深度图直接作为输入or与原图结合or转换成3D点云数据(伪激光雷达Pseudo-LiDAR)用于3D目标检测任务。该方法的缺点是其深度和目标检测分离训练的结构,导致其可能会丢失一些隐含的信息。
- 基于网格的方法(Grid-Based Methods) : 通过预测出BEV网格表示替代通过深度估计作为3D检测输入的方法,通常转化步骤是通过利用体素网格把体素投影到图像平面上然后采样图像特征将其转换成BEV的形式。这种方法可能会导致大量体素和特征的重叠从而降低检测的准确性。
CaDDN 网络尝试结合以上方法的长处,整体网络同时训练深度预测和3D检测以期待其能够解决基于深度的方法中的问题,同时利用也将图像平面转换成了BEV的形式来提高检测的准确性。

9 MonoRCNN
单目3D目标检测的核心难点是估计目标的距离,MonoRCNN提出了一个基于几何的距离分解方法,将目标距离分解为与目标的物理高度(physical height)和图像平面上的投影高度(visual height)相关的量,使得距离的估计具有可解释性,精度和鲁棒性也更高;除此之外,论文还对导致距离估计不确定性的原因进行了理论和实验分析。
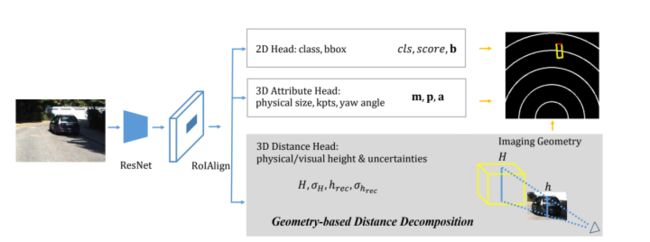
论文所提出来的基于分解的目标距离估计方案,本质上还是在自动驾驶中的一些前提假设(如目标只有yaw angle的变化)下,选取一些受未知参数影响较小的量作为网络学习的预测值,从而计算距离,这种学习方法与先前的一些工作选择预测目标尺寸一脉相承,但是论文中把距离的预测与目标的高度关联起来,还是很有创新的,这个思路应该还可以继续挖掘。另外论文中选择将不确定性引入进来做多任务优化提升性能,也是以往工作在单目3D目标检测领域的体现。
基于伪激光雷达数据
主要有Pseudo-LiDAR、Pseudo-LiDAR++、E2E Pseudo-LiDAR,伪激光雷达方法本质是还是通过深度图生成伪激光雷达数据,辅助3D检测模型训练!
参考:https://blog.csdn.net/CV_Autobot/article/details/126672844?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522167646617916782425163928%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=167646617916782425163928&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-21-126672844-null-null.142^v73^control_1,201^v4^add_ask,239^v1^control&utm_term=%E5%8D%95%E7%9B%AE3d%E6%A3%80%E6%B5%8B&spm=1018.2226.3001.4187