实录分享 | Alluxio 在网易大数据的应用与优化

欢迎来到【微直播间】,2min纵览大咖观点
本次分享主要包括四个方面:
- 背景介绍;
- 对象存储场景优化;
- Impala 引擎适配;
- 通用功能增强。
一、 背景介绍
网易有数大数据基础平台NDH:NDH 是网易对标 Cloudera CDH 的一个内部实现,是网易内部广泛使用的一个基础平台。
分布式大数据查询引擎 Impala:NDH 底层的 OLAP 引擎是 Impala, Impala 是 MPP 的架构,有着强悍的查询性能。
在网易的使用场景中,Alluxio 可以让整个云上大数据系统的性能提升很多倍,降低云上场景的接入成本,在整个系统的稳定运行中发挥了应有的作用,同时很好地融入到了整个产品体系中。
二、对象存储场景优化
- 流上传优化;
方案:对象存储流式上传功能 - Rename性能优化;
- OBS 场景删除性能优化。
三、Impala引擎适配
网易数帆 NDH 使用 Impala 作为 OLAP查询引擎,使用 Alluxio 作为离线大数据的分布式缓存加速层。在 Impala 引擎适配上,主要做了如下相关工作:
- 文件句柄缓存;
- Transparent URI;
- getFileBlockLocations 优化。
四、通用功能增强
- 运维能力增强 - 动态修改代理用户配置
- 运维能力增强 - UFS 性能指标
- 运维能力增强 - 审计日志增强
- 运维能力增强 - 文件上传感知
- 运维能力增强 - 缓存行为控制
以上仅为大咖演讲概览,完整内容点击视频观看:

点击观看
附件:大咖分享文字版完整内容可见下文
一、背景介绍
网易有数大数据基础平台 NDH
NDH 是网易对标 Cloudera CDH 的一个内部实现,是网易内部广泛使用的基础平台。有如下特点:
- 可从 CDH 集群平滑迁移;
- 运维智能化;
- 核心代码完全掌控;
- 任务运行优化和资源隔离;
- 多层安全保障。
分布式大数据查询引擎 Impala

NDH 底层的 OLAP 引擎是 Impala, Impala 是 MPP 的架构,有着强悍的查询性能。
为什么选择 Alluxio
NDH 使用 Alluxio 作为缓存加速层的原因有如下几点:
- Alluxio 是第一个面向基于云的数据分析和人工智能的开源数据编排系统;
- 可降低云上场景的接入成本;
- 基于内存 + SSD + HDD 的多级缓存可以大幅提高数据访问速度。
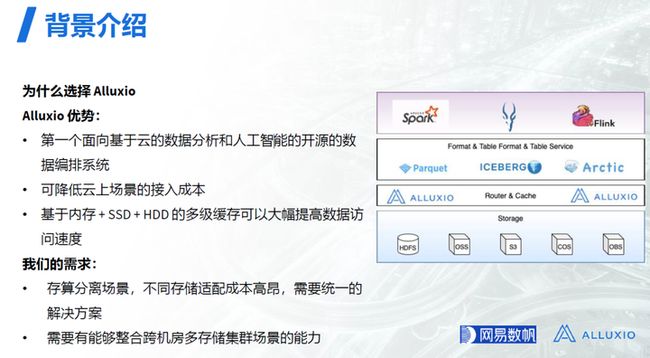
NDH 在公有云部署时,通过 Alluxio 提供的统一标准的存储接口,可以对接 HDFS 以及 OSS,S3,COS,OBS 等对象存储。在该方案中,Alluxio 也发挥了一个存储层的文件管理、IO 路由和缓存加速的作用。计算引擎和查询引擎,如 Spark, Impala, Flink等,会通过Hadoop compatible 接口访问 Alluxio。
在网易的使用场景中,Alluxio 可以让整个云上大数据系统的性能提升很多倍,降低云上场景的接入成本,在整个系统的稳定运行中发挥了应有的作用,同时很好地融入到了整个产品体系中。
二、对象存储场景优化
流上传优化
目前我们所遇到的难题:
- 在大数据场景下,通过Spark执行ETL任务时, 会通过 Alluxio上传文件到对象存储中。在使用过程中发现,当上传超过5GB的文件时, Alluxio 会报错导致任务失败,我们必须通过参数调整等方式避免ETL 产生超过5GB的文件,而这些调整对业务用户的影响较大;
- Hive SQL任务尝试向Alluxio写入大文件时,会导致 Alluxio Worker节点磁盘写满,直接引起集群大量写入失败,并影响同节点上其他服务的稳定性。

当前文件上传在内部实现上,客户端会首先将数据写到 Alluxio Worker 节点的一个临时目录上, 然后在客户端调用 Close 方法时,才会将这些 Alluxio Worker 节点的本地文件上传到对象存储中。这种实现方式会带来如下问题:
- 上传性能慢:Alluxio 客户端向 Alluxio Worker 发送数据,同时Alluxio Worker向对象存储发送数据,是一个串行的过程,所以上传流量和下载流量是分开的,无法充分利用网络带宽;
- 上传文件的大小受到 Worker 节点磁盘容量的限制,在上传大文件时可能引起 Worker 节点磁盘满的故障,进而导致整个集群停止服务:比如上传 1T 的数据时,如果 worker节点磁盘容量只有100G,此时在写满Worker节点磁盘后,就会影响Worker节点的其它服务如Spark、Impala等,进而导致整个集群停服;
- 上传大文件受到对象存储putObject接口大小限制,在上传超过5GB大小的文件时,任务会失败;
- 上传重试行为低效:上传过程中如果出现网络异常导致作业失败,重试时需要把整个文件重新再上传一遍,比如一个10G的文件上传了8G后失败了,则整个10G的数据都需要重新上传,这无疑是低效的;

针对上述问题,网易开发了一套流上传优化的解决方案替代现有的机制(目前已经贡献给开源社区)。该方案在 Worker 中对上传的文件进行分片,如果上传到的文件已经达到了一个分片大小,就会调用UploadPart 异步上传文件分片到对象存储中,该方案的优势如下:
- 客户端发送数据到Worker的过程和Worker上传文件到 UFS 的过程异步,可以更充分地利用网络带宽,整体 I/O 性能提升 40%;
- 上传超大文件时无Worker磁盘容量限制:上传超大文件时,Worker中已经上传成功的文件分片可以被删除掉,所以文件大小没有Worker磁盘容量的限制;
- 单文件上传时无putObject接口大小限制,允许上传更大的单个文件;
- 按文件分片重试,更高效:上传过程中如果出现网络异常导致作业失败,重试时只需要重试上传失败的文件分片,而不需要把整个文件重新再上传一遍;
Rename性能优化

在大数据 ETL 作业中,首先会把一些批量任务的结果存储到临时目录中,然后在整个作业完成后再将临时目录 Rename 为正式目录。由于大多数的对象存储没有原生 Rename 接口,所以在内部实现上会结合 Copy 和 Delete 来实现。原先的实现会对每一个对象都发送一个 Copy 和 Delete 请求,所以Rename 性能较慢,尤其是对拥有大量文件的目录进行操作时,会造成严重的性能问题。
网易利用了 UFS 对象存储的批量删除接口,通过合并删除请求批量删除对象,此时整体的 rpc 调用会减少很多,以此来优化 Rename 的整体性能。测试结果显示,针对大目录(文件数40万++),其 Rename 操作获得了 30% 的性能提升。
OBS 场景删除性能优化

有些客户会将网易 NDH 部署在华为云上,此时底层使用了华为 OBS 对象存储 (Object Storage Service),对接时发现 Spark 作业删除 OBS 大目录时性能较慢。经与华为云相关人员沟通,了解到 OBS 的 PFS 提供了针对目录的原生 Rename 接口,且 PFS 的 Rename 接口性能比 delete 接口快。
在优化方案中,先将文件Rename 到指定目录,然后再定期延迟删除,从而优化了 delete 性能。
三、Impala 引擎适配
网易数帆 NDH 使用 Impala 作为 OLAP查询引擎, 使用 Alluxio 作为离线大数据的分布式缓存加速层。在 Impala 引擎适配上,主要做了如下相关工作。

文件句柄缓存
Impala 等 OLAP框架,普遍会使用文件句柄缓存机制提升打开文件的性能,并降低元数据服务(比如HDFS 的 namenode)的负载压力,但开源的 Impala 对 Alluxio 的支持不足,网易通过调整 Impala 代码支持了调整 Alluxio I/O 线程数、文件句柄缓存等功能。开启 Impala 的文件句柄缓存机制后我们发现,过段时间后所有查询都会卡住,造成 Impala 服务不可用,同时在 Impala 日志中可以发现大量客户端 OOM 日志。

在 Impala 的文件句柄缓存机制中,Impala 读取文件时,会首先判断是否缓存了文件句柄,如果没有就调用 Open 方法向 Master 发起请求以获取文件的元数据信息(如文件的长度,文件块的位置信息等),此后会向 Worker 发起读取请求并调用 read 方法读取数据块,此后会调用 unbuffer 方法并缓存文件句柄,最后会返回读取的数据;后续再次读取相同文件时,如果已经缓存了文件句柄,就不需要再次向 Master 发起请求以获取文件的元数据信息。
而 Alluxio 客户端的实现中其实并没有 unbuffer 方法,查看接口 CanUnbuffer 的声明可以发现,此处可以释放网络连接以及文件句柄。网易修改实现了 Hadoop 客户端的 unbuffer 接口,在缓存文件句柄时断开了与 Worker 之间的长连接和清除预读的数据缓存,避免了连接池和内存耗尽。在 profile 中查看效果可见,启用文件句柄缓存后,打开文件的耗时指标有了大幅下降。
Transparent URI
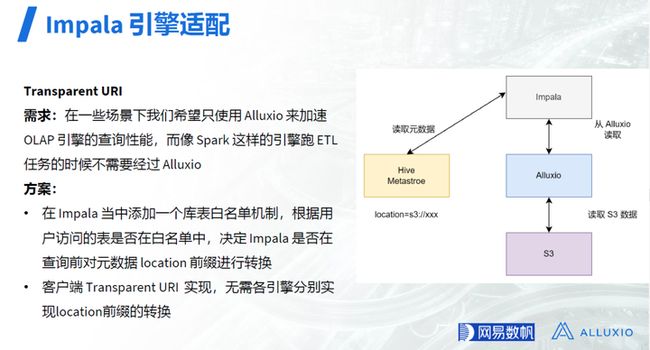
OLAP 引擎和 Spark 查询数据时都需要访问元数据引擎 HMS 以获得库和表的元数据,包括其在存储系统中的具体路径。针对对象存储S3,分布式文件系统HDFS,以及 Alluxio, 其存储系统和存储路径相关信息分别为 location=s3://xx,location=hdfs://xxx,和 location=alluxio://xx。在一些场景下,我们希望只使用 Alluxio 来加速 OLAP 引擎的查询性能,而像 Spark 这样的引擎跑 ETL 任务的时候不需要经过 Alluxio。
为满足上述需求,网易首先采用了白名单方案:即在 Impala 查询引擎当中添加一个库表白名单机制,根据用户访问的表是否在白名单中,决定 Impala 是否在查询前对元数据中的 location 前缀进行转换。
由于上述白名单机制对查询引擎有侵入(若要实现类似功能,每个查询引擎都要进行修改以引入白名单机制),网易后续又参考了企业版的 Transparent URI 机制,在内部版本中实现了类似功能,该方案无需各引擎分别实现 location 前缀的转换,业务无感知,对业务更加友好。
getFileBlockLocations 优化

Impala 在元数据加载时会调用Hadoop 的 getFileBlockLocations 接口,用于在调度时通过块位置信息优先将对应的 scan range 下发到与 Worker 混部的 Impalad ,尽可能利用短路读取来优化查询 I/O 性能。而在实际使用时发现,Impala 在加载文件数较多的表时 getFileBlockLocations 返回较慢,同时发现 Master 上有大量的 getFileInfo 请求,对元数据加载的性能产生较大影响。

分析源码实现可以发现,Alluxio 在 listStatus 时已经将 BlockLocation 放到 FileStatus 当中,无需再调用 getFileInfo RPC 接口获取块位置信息。网易优化了 Alluxio 客户端的实现逻辑,去除了冗余的 RPC 调用,为 Impala 加载元数据时的性能带来了提升。
四、通用功能增强
数据资产

在数据资产相关服务中,用户需要对存储资源进行各种分析,优化资源配置,降低存储成本,这需要实时查询指定路径下的元数据信息,而直接遍历目录计算会对集群造成很大压力,直接影响服务性能和稳定性。

为解决上述问题,网易在 Apache Ratis 上开发了 listener 功能,Ratis listener 只参与日志复制过程,而不参与主节点选举 (Alluxio 的高可用是基于Apache Ratis 提供的 Raft 协议来实现的)。由于 Raft Listener 不响应客户端的请求,只负责计算 Alluxio 元数据信息并写入到 HBase 当中,所以可以做到不影响集群的性能和稳定性。
Ratis listener 写入到 HBase 中的 Alluxio 元数据信息,可以通过 Meta API 实时响应用户的查询请求,也可以通过 Spark 同步到Hive中以满足T+1类的离线数据分析需求。
Hadoop 生态兼容-回收站

Hadoop 生态的计算框架为了提升数据安全性,在执行删除操作时,会先将删除的文件或者目录移动到回收站目录(/user//.Trash/Current)下,一段时间后由 NameNode 负责清理相应的文件。而 Alluxio 没有相同机制,需要手动进行清理操作,操作繁琐,容易误删数据。出于易用性的考量,网易为 Alluxio 添加了相同的清理逻辑,提供了与 HDFS 回收站功能相同的特性。
Hadoop 生态兼容-目录冻结

为防止有更新权限的用户误删除特定数据目录,网易结合元数据功能和其内部的 Ranger(开源的 Ranger 只区分 Read 和 Write,对 Write 操作不区分具体是 create 还是rename/delete),实现了目录冻结功能,能够冻结指定目录或者超过一定大小的目录,从而禁止任何用户对该目录的 Rename 或 delete 操作,避免了数据误删除,提升了数据安全性。
运维能力增强-动态修改代理用户配置
由于之前业务经常有修改和新增代理用户的需求,之前需要重启集群才能生效,影响范围大。因此我们实现了监听配置文件并动态修改代理用户功能,降低Alluxio的重启次数,提升集群稳定性。
运维能力增强 - UFS 性能指标
我们发现 Alluxio 在 UFS 上经常出现底层存储性能的瓶颈,为了用于排查提升 Alluxio 可观测性,我们开发了UFS性能指标增强的功能。
运维能力增强 - 审计日志增强
使用过程中发现目前 Alluxio 缺少管理客户端能力,如果一些老的客户端版本有 BUG,难以确定需要通知哪些业务方升级。我们在客户端上增加了上报版本和客户端配置等信息的功能,并将这些信息在审计日志中打印,增强客户端管理能力。
运维能力增强- 文件上传感知
添加了命令行识别 Worker 节点正在上传的文件,方便定位排查问题。
运维能力增强 - 缓存行为控制
为了更好的控制缓存空间,开发允许在 Free 和 Load 命令中指定 Worker 节点的功能,增强缓存控制能力。
五、总结与展望
使用 Alluxio 作为统一存储入口的网易 NDH 云上大数据方案已经服务了在 AWS 、阿里云和华为云上的多个用户。网易 Alluxio 团队积极参与社区共建,包括及时反馈 Issue 、贡献特性 PR 和修复已知 Bug 等,目前累计已为 Alluxio 贡献了 40+ PR。
想要了解更多关于Alluxio的干货文章、热门活动、专家分享,可点进入【Alluxio智库】:
