C++_05_高级编程
C++编程05之高级编程
C++ 文件和流
到目前为止,我们已经使用了 iostream 标准库,它提供了 cin 和 cout 方法分别用于从标准输入读取流和向标准输出写入流。
本教程介绍如何从文件读取流和向文件写入流。
这就需要用到 C++ 中另一个标准库 fstream,它定义了三个新的数据类型:
| 数据类型 | 描述 |
|---|---|
| ofstream | 该数据类型表示输出文件流,用于创建文件并向文件写入信息。 |
| ifstream | 该数据类型表示输入文件流,用于从文件读取信息。 |
| fstream | 该数据类型通常表示文件流,且同时具有 ofstream 和 ifstream 两种功能,这意味着它可以创建文件,向文件写入信息,从文件读取信息。 |
要在 C++ 中进行文件处理,必须在 C++ 源代码文件中包含头文件
打开文件
在从文件读取信息或者向文件写入信息之前,必须先打开文件。
ofstream 和 fstream 对象都可以用来打开文件进行写操作,如果只需要打开文件进行读操作,则使用 ifstream 对象。
下面是 open() 函数的标准语法,open() 函数是 fstream、ifstream 和 ofstream 对象的一个成员函数。
void open(const char *filename, ios::openmode mode);
在这里,open() 成员函数的第一参数指定要打开的文件的名称和位置,第二个参数定义文件被打开的模式。
| 模式标志 | 描述 |
|---|---|
| ios::app | 追加模式。所有写入都追加到文件末尾。 |
| ios::ate | 文件打开后定位到文件末尾。 |
| ios::in | 打开文件用于读取。 |
| ios::out | 打开文件用于写入。 |
| ios::trunc | 如果该文件已经存在,其内容将在打开文件之前被截断,即把文件长度设为 0。 |
您可以把以上两种或两种以上的模式结合使用。例如,如果您想要以写入模式打开文件,并希望截断文件,以防文件已存在,那么您可以使用下面的语法:
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );
类似地,您如果想要打开一个文件用于读写,可以使用下面的语法:
fstream afile;
afile.open("file.dat", ios::out | ios::in );
关闭文件
当 C++ 程序终止时,它会自动关闭刷新所有流,释放所有分配的内存,并关闭所有打开的文件。
但程序员应该养成一个好习惯,在程序终止前关闭所有打开的文件。
下面是 close() 函数的标准语法,close() 函数是 fstream、ifstream 和 ofstream 对象的一个成员函数。
void close();
写入文件
在 C++ 编程中,我们使用流插入运算符( << )向文件写入信息,就像使用该运算符输出信息到屏幕上一样。唯一不同的是,在这里您使用的是 ofstream 或 fstream 对象,而不是 cout 对象。
读取文件
在 C++ 编程中,我们使用流提取运算符( >> )从文件读取信息,就像使用该运算符从键盘输入信息一样。唯一不同的是,在这里您使用的是 ifstream 或 fstream 对象,而不是 cin 对象。
读取 & 写入实例
下面的 C++ 程序以读写模式打开一个文件。
在向文件 afile.dat 写入用户输入的信息之后,程序从文件读取信息,并将其输出到屏幕上:
#include
当上面的代码被编译和执行时,它会产生下列输入和输出:
$./a.out
Writing to the file
Enter your name: Zara
Enter your age: 9
Reading from the file
Zara
9
代码如下 :
#include
using namespace std;
// 能读能写的666
#include
int main() {
char buf[100];
// 输出流,写模式
ofstream fos;
fos.open("abc.txt");
cout << "input anime_title to write to file:abc.txt" << endl;
// 读取到字符数组
cin.getline(buf,100);
// 写文件
fos << buf << endl;
// 继续输入
cout << "input anime_actress to write to file:abc.txt" << endl;
cin >> buf;
// 关键一句??? 有没有这一句,有啥区别啊???
cin.ignore();
// 写文件
fos << buf << endl;
fos.close();
return 0;
}运行效果如下:
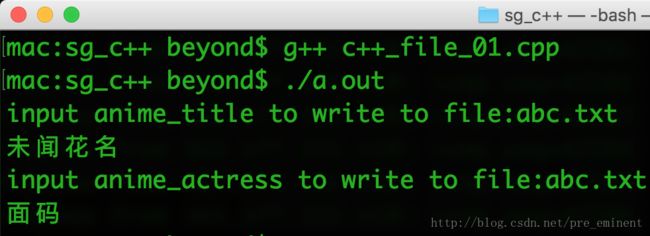

上面的实例中使用了 cin 对象的附加函数,比如 getline()函数从外部读取一行,ignore() 函数会忽略掉之前读语句留下的多余字符。
cin.ignore(a,ch)方法是从输入流(cin)中提取字符,提取的字符被忽略(ignore),将不会被使用。
每丢弃一个字符,它都要按如下方式,重新计数和比较字符:
如果计数值达到a或者被抛弃的字符是ch,则cin.ignore()函数执行终止;否则,它继续等待。
它的一个常用功能就是用来清除以回车结束的输入缓冲区的内容,消除上一次输入对下一次输入的影响。
比如可以这么用:cin.ignore(1024,'\n'),通常把第一个参数设置得足够大,这样实际上总是只有第二个参数'\n'起作用,所以这一句就是把回车(包括回车)之前的所有字符从输入缓冲(流)中清除出去。
如果不给参数,则默认参数为cin.ignore(1,EOF),即把EOF前的1个字符清掉,没有遇到EOF就清掉一个字符然后结束,就是这样啊,所以你每次都少一个字符.
文件位置指针
istream 和 ostream 都提供了用于重新定位文件位置指针的成员函数。这些成员函数包括关于 istream 的 seekg("seek get")和关于 ostream 的 seekp("seek put")。
seekg 和 seekp 的参数通常是一个长整型。第二个参数可以用于指定查找方向。
查找方向可以是 ios::beg(默认的,从流的开头开始定位),
也可以是 ios::cur(从流的当前位置开始定位),
也可以是 ios::end(从流的末尾开始定位)。
文件位置指针是一个整数值,指定了从文件的起始位置到指针所在位置的字节数。下面是关于定位 "get" 文件位置指针的实例:
// 定位到 fileObject 的第 n 个字节(假设是 ios::beg)
fileObject.seekg( n );
// 把文件的读指针从 fileObject 当前位置向后移 n 个字节
fileObject.seekg( n, ios::cur );
// 把文件的读指针从 fileObject 末尾往回移 n 个字节
fileObject.seekg( n, ios::end );
// 直接定位到 fileObject 的末尾
fileObject.seekg( 0, ios::end );打开文件,在末尾添加用户输入的内容,并关闭保存,代码如下:
#include
using namespace std;
// 能读能写的666
#include
int main() {
char buf[100];
// 输出流,追加模式
ofstream fos;
fos.open("abc.txt",ios::app);
// 定位到最后一个字符 seek put
// 从end往前0个字符,就是定位到最后一个字符
fos.seekp(0,ios::end);
cout << "input anime_content to write to file:abc.txt" << endl;
// 读取到字符数组
cin.getline(buf,100);
// 写文件
fos << buf << endl;
// 继续输入
cout << "input actress_age to write to file:abc.txt" << endl;
cin >> buf;
// 关键一句??? 有没有这一句,有啥区别啊???
cin.ignore();
// 写文件
fos << buf << endl;
// 关闭文件
fos.close();
return 0;
} 运行效果如下:

C++ 异常处理
异常是程序在执行期间产生的问题。C++ 异常是指在程序运行时发生的特殊情况,比如尝试除以零的操作。
异常提供了一种转移程序控制权的方式。
C++ 异常处理涉及到三个关键字:try、catch、throw。
- throw: 当问题出现时,程序会抛出一个异常。这是通过使用 throw 关键字来完成的。
- catch: 在您想要处理问题的地方,通过异常处理程序捕获异常。catch 关键字用于捕获异常。
- try: try 块中的代码标识将被激活的特定异常。它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try 和 catch 关键字。
try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。
使用 try/catch 语句的语法如下所示:
try
{
// 保护代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}
如果 try 块在不同的情境下会抛出不同的异常,这个时候可以尝试罗列多个 catch 语句,用于捕获不同类型的异常。
抛出异常
您可以使用 throw 语句在代码块中的任何地方抛出异常。throw 语句的操作数可以是任意的表达式,表达式的结果的类型决定了抛出的异常的类型。
以下是尝试除以零时抛出异常的实例:
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
捕获异常
catch 块跟在 try 块后面,用于捕获异常。
您可以指定想要捕捉的异常类型,这是由 catch 关键字后的括号内的异常声明决定的。
try
{
// 保护代码
}catch( ExceptionName e )
{
// 处理 ExceptionName 异常的代码
}
上面的代码会捕获一个类型为 ExceptionName 的异常。
如果您想让 catch 块能够处理 try 块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号 ...,如下所示:
try
{
// 保护代码
}catch(...)
{
// 能处理任何异常的代码
}
下面是一个实例,抛出一个除以零的异常,并在 catch 块中捕获该异常。
#include
由于我们抛出了一个类型为 const char* 的异常,因此,当捕获该异常时,我们必须在 catch 块中使用 const char*。
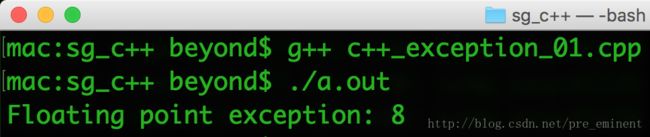
当上面的代码被编译和执行时,它会产生下列结果:???Excuse Me???
Division by zero condition! ???睁眼说瞎话!!!
#include
using namespace std;
double division(int a,int b)
{
if ( b == 0)
{
throw "除数为零 无法捕获,只能通过 硬件中断信号 来处理";
}
return (a/b);
}
int main() {
int x = 67;
int y = 0;
double result = 0;
try{
result = x/y;
cerr << "try:" << result << endl;
}catch(const char *msg){
cerr << "catch msg:" << msg << endl;
}
/*
对于c++ 除零错误, 内存错误等异常无法捕获。
除零错误,可以用signal函数处理 硬件中断信号 来处理。
*/
return 0;
} 
和java不一样,C++标准没有把除0错当成标准异常。
C++里要抓除零这样的异常,需要采用操作系统的结构化异常。
或者需要在编译选项上,加上让C++异常支持SEH(结构化异常处理)的参数。
C++之父在谈C++语言设计的书(The Design and Evolution of C++)里谈到:
"low-level events, such as arithmetic overflows and divide by zero, are assumed to be handled by a dedicated lower-level mechanism rather than by exceptions. This enables C++ to match the behaviour of other languages when it comes to arithmetic.
It also avoids the problems that occur onheavilypipelined architectures where events such as divide by zero are asynchronous."
简单翻译一下: “底层的事件,比如计算上的溢出和除0错,被认为应用有一个同样底层的机制去处理它们,而不是异常。这让C++在涉及到算术领域的性能,可以和其它语言竞争。再者,它也避免了当某些事件,比如除0错是异步的情况下(比如在别一个线程里发生)所可能造成的‘管道重X’的架构这一问题。???Excuse Me???”
所以,说起来,和原生数组访问越界为什么不是异常并无两样,主要还是为了“效率/性能”。对于大多数时候的除法操作,我们会让它出现除数为0的可能性很小,当你认为有这种可能,就自己检查吧,然后自己定义一个除0错的异常。
很多C++库,还是实现了EDivByZero之类异常,但仅限于这个库里的代码。它们做了检查。
总结一下:C++为什么抓不到除0错的“异常”? 答:因为C++标准眼里,除0错不是一个异常。再进一步:C++编译器,在编译除法操作时,没有为它加上额外的检查代码以抛出一个异常;也没有要求处理不同OS之间对(已经发生的)除0错的处理。
C++ 标准的异常
C++ 提供了一系列标准的异常,定义在
它们是以父子类层次结构组织起来的,如下所示:
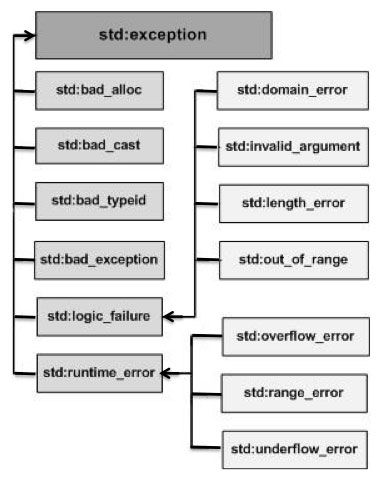
下表是对上面层次结构中出现的每个异常的说明:
| 异常 | 描述 |
|---|---|
| std::exception | 该异常是所有标准 C++ 异常的父类。 |
| std::bad_alloc | 该异常可以通过 new 抛出。 |
| std::bad_cast | 该异常可以通过 dynamic_cast 抛出。 |
| std::bad_exception | 这在处理 C++ 程序中无法预期的异常时非常有用。 |
| std::bad_typeid | 该异常可以通过 typeid 抛出。 |
| std::logic_error | 理论上可以通过读取代码来检测到的异常。 |
| std::domain_error | 当使用了一个无效的数学域时,会抛出该异常。 |
| std::invalid_argument | 当使用了无效的参数时,会抛出该异常。 |
| std::length_error | 当创建了太长的 std::string 时,会抛出该异常。 |
| std::out_of_range | 该异常可以通过方法抛出,例如 std::vector 和 std::bitset<>::operator[]()。 |
| std::runtime_error | 理论上不可以通过读取代码来检测到的异常。 |
| std::overflow_error | 当发生数学上溢时,会抛出该异常。 |
| std::range_error | 当尝试存储超出范围的值时,会抛出该异常。 |
| std::underflow_error | 当发生数学下溢时,会抛出该异常。 |
定义新的异常
您可以通过继承和重载 exception 类来定义新的异常。下面的实例演示了如何使用 std::exception 类来实现自己的异常:
#include
这将产生以下结果:
MyException caught
C++ Exception
在这里,what() 是异常类提供的一个公共方法,它已被所有子异常类重载。这将返回异常产生的原因。
代码如下:
#include
#include
using namespace std;
// 自定义异常,继承自exception
struct SGException:public exception
{
/*
说明:
1.后面的const throw()不是函数,这个东西叫 异常规格说明,表示what函数可以抛出异常的类型,类型说明放到()里
2.第一个const表示 what()返回的msg不容许轻易修改
如果没有第一个const,
在函数what里照样不能修改message的值。
但是调用what的函数得到message的指针可以修改message的内容。
3.第2个const表示该成员函数不容许轻易修改 成员变量的值
如果没有第二个const,
在函数what里可以修改message的值。
但是调用what的函数得到message的指针不能修改message的内容。
*/
const char* what() const throw(){
return "sg exception";
}
};
int main() {
try{
throw SGException();
}catch(SGException& e){
cout << e.what() << endl;
}catch(exception& e){
cout << "other exception" << endl;
}
return 0;
}运行效果如下:
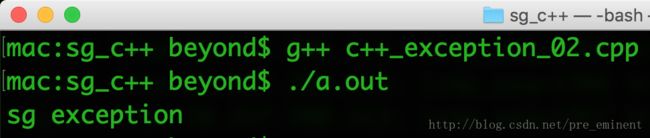
C++ 动态内存
了解动态内存在 C++ 中是如何工作的是成为一名合格的 C++ 程序员必不可少的。C++ 程序中的内存分为两个部分:
- 栈:在函数内部声明的所有局部变量都将占用栈内存。
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。
很多时候,您无法提前预知需要多少内存来存储某个定义变量中的特定信息,所需内存的大小需要在运行时才能确定。
在 C++ 中,您可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址。
这种运算符即 new 运算符。如果您不需要动态分配内存,可以使用 delete 运算符,删除之前由 new 运算符分配的内存。
new 和 delete 运算符
下面是使用 new 运算符来为任意的数据类型动态分配内存的通用语法:
new data-type;
在这里,data-type 可以是包括数组在内的任意内置的数据类型,也可以是包括类或结构在内的用户自定义的任何数据类型。
让我们先来看下内置的数据类型。
例如,我们可以定义一个指向 double 类型的指针,然后请求内存,该内存在执行时被分配。我们可以按照下面的语句使用 new 运算符来完成这点:
double* pvalue = NULL; // 初始化为 null 的指针
pvalue = new double; // 为变量请求内存
如果自由存储区已被用完,可能无法成功分配内存。
所以建议检查 new 运算符是否返回 NULL 指针,并采取以下适当的操作:
double* pvalue = NULL;
if( !(pvalue = new double ))
{
cout << "Error: out of memory." <<endl;
exit(1);
}
malloc() 函数在 C 语言中就出现了,在 C++ 中仍然存在,但建议尽量不要使用 malloc() 函数。
new 与 malloc() 函数相比,其主要的优点是,new 不只是分配了内存,它还创建了对象。
在任何时候,当您觉得某个已经动态分配内存的变量不再需要使用时,您可以使用 delete 操作符释放它所占用的内存,
如下所示:
delete pvalue; // 释放 pvalue 所指向的内存
下面的实例中使用了上面的概念,演示了如何使用 new 和 delete 运算符:
#include
当上面的代码被编译和执行时,它会产生下列结果:
Value of pvalue : 29495#include
using namespace std;
int main() {
double *p = NULL;
if(!(p = new double)){
cout << "无可用内存" << endl; exit(1);
}
cout << p << endl;
*p = 6.7;
cout << *p << endl;
delete p;
cout << p << endl;
return 0;
} 
数组的动态内存分配
假设我们要为一个字符数组(一个有 20 个字符的字符串)分配内存,我们可以使用上面实例中的语法来为数组动态地分配内存,如下所示:
char* pvalue = NULL; // 初始化为 null 的指针
pvalue = new char[20]; // 为变量请求内存
要删除我们刚才创建的数组,语句如下:
delete [] pvalue; // 删除 pvalue 所指向的数组
下面是 new 操作符的通用语法,可以为多维数组分配内存,如下所示:
int ROW = 2;
int COL = 3;
double **pvalue = new double* [ROW]; // 为行分配内存
// 为列分配内存
for(int i = 0; i < ROW; i++) {
pvalue[i] = new double[COL];
}
释放多维数组内存:
for(int i = 0; i < ROW; i++) {
delete[] pvalue[i];
}
delete [] pvalue; #include
using namespace std;
// 为数组动态分配内存
int main() {
// 2行5列
int row = 2;
int col = 5;
// 为行分配内存
double **pointOfArr = new double*[row];
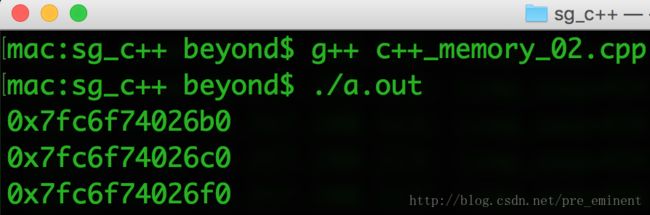
cout << pointOfArr << endl;
// 为列分配内存
for (int i = 0; i < row; ++i)
{
pointOfArr[i] = new double[col];
cout << pointOfArr[i] << endl;
}
// 删除内存
for (int i = 0; i < row; ++i)
{
// 先删除指向第2维的 指针
delete[] pointOfArr[i];
}
// 再删除 指向第1维的指针
delete[] pointOfArr;
return 0;
} 
对象的动态内存分配
对象与简单的数据类型没有什么不同。
例如,请看下面的代码,我们将使用一个对象数组来理清这一概念:
#include
如果要为一个包含四个 Box 对象的数组分配内存,构造函数将被调用 4 次,同样地,当删除这些对象时,析构函数也将被调用相同的次数(4次)。
当上面的代码被编译和执行时,它会产生下列结果:
调用构造函数!
调用构造函数!
调用构造函数!
调用构造函数!
调用析构函数!
调用析构函数!
调用析构函数!
调用析构函数!#include
using namespace std;
class Girl
{
public:
Girl();
~Girl();
};
Girl::Girl()
{
cout << "girl born!" << endl;
}
Girl::~Girl()
{
cout << "girl fade away!" << endl;
}
int main() {
// 对象数组
Girl *p = new Girl[5];
cout << "the twilight of the gods" << endl;
delete[] p;
return 0;
} 
C++ 命名空间
假设这样一种情况,当一个班上有两个名叫 Zara 的学生时,为了明确区分它们,我们在使用名字之外,不得不使用一些额外的信息,比如他们的家庭住址,或者他们父母的名字等等。
同样的情况也出现在 C++ 应用程序中。
例如,您可能会写一个名为 xyz() 的函数,在另一个可用的库中也存在一个相同的函数 xyz()。
这样,编译器就无法判断您所使用的是哪一个 xyz() 函数。
因此,引入了命名空间这个概念,专门用于解决上面的问题,它可作为附加信息来区分不同库中相同名称的函数、类、变量等。
使用了命名空间即定义了上下文。
本质上,命名空间就是定义了一个范围。
定义命名空间
命名空间的定义使用关键字 namespace,后跟命名空间的名称,如下所示:
namespace namespace_name {
// 代码声明
}
为了调用带有命名空间的函数或变量,需要在前面加上命名空间的名称,如下所示:
name::code; // code 可以是变量或函数
让我们来看看命名空间如何为变量或函数等实体定义范围:
#include
当上面的代码被编译和执行时,它会产生下列结果:
Inside first_space
Inside second_space#include
using namespace std;
namespace girl_space{
void show(){
cout << "god is a girl!" << endl;
}
}
namespace boya_space{
void show(){
cout << "no game no life!" << endl;
}
}
int main() {
// use of undeclared identifier 'show'
// show();
girl_space::show();
cout << "exchange" << endl;
boya_space::show();
return 0;
} 
using 指令
您可以使用 using namespace 指令,这样在使用命名空间时就可以不用在前面加上命名空间的名称。这个指令会告诉编译器,后续的代码将使用指定的命名空间中的名称。
#include
当上面的代码被编译和执行时,它会产生下列结果:
Inside first_space
代码如下:
#include
using namespace std;
namespace girl_space{
void show(){
cout << "god is a girl!" << endl;
}
}
namespace boya_space{
void show(){
cout << "no women no kids" << endl;
}
}
using namespace boya_space;
int main() {
show();
return 0;
} 效果如下:

using 指令也可以用来指定命名空间中的特定项目。
例如,如果您只打算使用 std 命名空间中的 cout 部分,您可以使用如下的语句:
using std::cout; // 注意:这儿没有了namespace字样
随后的代码中,在使用 cout 时就可以不用加上命名空间名称作为前缀,
但是 std 命名空间中的其他项目仍然需要加上命名空间名称作为前缀,如下所示:
#include
当上面的代码被编译和执行时,它会产生下列结果:
std::endl is used with std!
using 指令引入的名称遵循正常的范围规则。名称从使用 using 指令开始是可见的,直到该范围结束。
此时,在范围以外定义的同名实体是隐藏的。
不连续的命名空间
命名空间可以定义在几个不同的部分中,因此命名空间是由几个单独定义的部分组成的。
一个命名空间的各个组成部分可以分散在多个文件中。
所以,如果命名空间中的某个组成部分需要请求定义在另一个文件中的名称,则仍然需要声明该名称。
下面的命名空间定义可以是定义一个新的命名空间,也可以是为已有的命名空间增加新的元素:
namespace namespace_name {
// 代码声明
}
嵌套的命名空间
命名空间可以嵌套,您可以在一个命名空间中定义另一个命名空间,如下所示:
namespace namespace_name1 {
// 代码声明
namespace namespace_name2 {
// 代码声明
}
}
您可以通过使用 :: 运算符来访问嵌套的命名空间中的成员:
// 访问 namespace_name2 中的成员
using namespace namespace_name1::namespace_name2;
// 访问 namespace:name1 中的成员
using namespace namespace_name1;
在上面的语句中,如果使用的是 namespace_name1,那么在该范围内 namespace_name2 中的元素也是可用的,
代码如下所示:
#include
当上面的代码被编译和执行时,它会产生下列结果:
Inside second_space#include
using namespace std;
namespace human{
void show(){
cout << "human is everlasting" << endl;
}
// 嵌套的命名空间
namespace girl{
void show(){
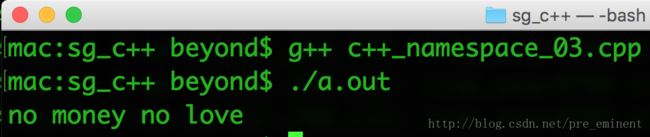
cout << "no money no love" << endl;
}
}
}
// 使用第2个命名空间
using namespace human::girl;
int main() {
show();
return 0;
} 
C++ 模板
模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。
模板是创建泛型类或函数的蓝图或公式。
库容器,比如迭代器和算法,都是泛型编程的例子,它们都使用了模板的概念。
每个容器都有一个单一的定义,比如 向量,我们可以定义许多不同类型的向量,比如 vector
您可以使用模板来定义函数和类,接下来让我们一起来看看如何使用。
函数模板
模板函数定义的一般形式如下所示:
template ret-type func-name(parameter list)
{
// 函数的主体
}
在这里,type 是函数所使用的数据类型的占位符名称。
这个名称可以在函数定义中使用。
下面是函数模板的实例,返回两个数种的最大值:
template <typename T>
#include
当上面的代码被编译和执行时,它会产生下列结果:
Max(i, j): 39
Max(f1, f2): 20.7
Max(s1, s2): World#include
using namespace std;
// 模板定义的第一行,标准写法,typename是类似class的关键字
template
// 第二行,才是模板函数的定义
// 内联函数,返回值类型是T,不可轻易更改的引用
inline T const& giveMeWinner(T const& a, T const& b)
{
return a < b ? a : b;
}
int main() {
int girl_01_age = 14;
int girl_02_age = 16;
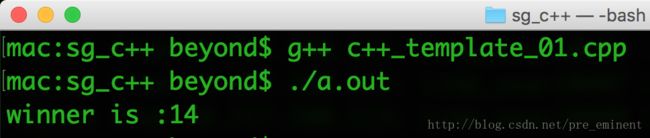
cout << "winner is :" << giveMeWinner(girl_01_age,girl_02_age) << endl;
return 0;
} 
类模板
正如我们定义函数模板一样,我们也可以定义类模板。泛型类声明的一般形式如下所示:
template class class-name {
.
.
.
}
在这里,type 是占位符类型名称,可以在类被实例化的时候进行指定。
您可以使用一个逗号分隔的列表来定义多个泛型数据类型。
下面的实例定义了类 Stack<>,并实现了泛型方法来对元素进行入栈出栈操作:
#include elems; // 元素
public:
void push(T const&); // 入栈
void pop(); // 出栈
T top() const; // 返回栈顶元素
bool empty() const{ // 如果为空则返回真。
return elems.empty();
}
};
template <class T>
void Stack::push (T const& elem)
{
// 追加传入元素的副本
elems.push_back(elem);
}
template <class T>
void Stack::pop ()
{
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// 删除最后一个元素
elems.pop_back();
}
template <class T>
T Stack::top () const
{
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// 返回最后一个元素的副本
return elems.back();
}
int main()
{
try {
Stack<int> intStack; // int 类型的栈
Stack<string> stringStack; // string 类型的栈
// 操作 int 类型的栈
intStack.push(7);
cout << intStack.top() <<endl;
// 操作 string 类型的栈
stringStack.push("hello");
cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
}
catch (exception const& ex) {
cerr << "Exception: " << ex.what() <<endl;
return -1;
}
}
当上面的代码被编译和执行时,它会产生下列结果:
7
hello
Exception: Stack<>::pop(): empty stack#include
#include
using namespace std;
// #include
// 包含两个新的头文件
// #include
// #include
// 定义一个类模板
// 第一行标准写法
template
class SGGroup{
private:
vector _modelArr;
public:
// 压栈(五笔编码:sgt)
void push(T const&);
// 出栈
void pop();
// 获取栈顶元素
// 这个const表示:????
T giveMeTop() const;
};
// 定义函数 压栈(五笔编码:sgt)
// 使用泛型之前都必须加上这一句标准声明
template
// 类名和范围解析符号之间的必不可少,否则不认为是同一个类
void SGGroup::push(T const&girl)
{
_modelArr.push_back(girl);
}
// 定义函数出栈
// 使用泛型之前都必须加上这一句标准声明
template
// 类名和范围解析符号之间的必不可少,否则不认为是同一个类
void SGGroup::pop()
{
if(_modelArr.empty()){
// 已经空了
throw out_of_range("No Women No Kids");
}else{
_modelArr.pop_back();
}
}
// 定义函数 获取栈顶元素
// 使用泛型之前都必须加上这一句标准声明
template
// 类名和范围解析符号之间的必不可少,否则不认为是同一个类,为啥要加那么多const???
T SGGroup::giveMeTop() const
{
if(_modelArr.empty()){
throw out_of_range("No Women No Kids");
}else{
return _modelArr.back();
}
}
int main() {
try{
SGGroup intSGGroup;
intSGGroup.push(6);
cout << intSGGroup.giveMeTop() << endl;
intSGGroup.push(7);
cout << intSGGroup.giveMeTop() << endl;
cout << "----clean start----" << endl;
intSGGroup.pop();
cout << intSGGroup.giveMeTop() << endl;
intSGGroup.pop();
cout << intSGGroup.giveMeTop() << endl;
// 当T是csting类型时,类似
}catch(exception const& msg){
cerr << msg.what() << endl;
return -1;
}
return 0;
} 
C++ 预处理器
预处理器是一些指令,指示编译器在实际编译之前所需完成的预处理。
所有的预处理器指令都是以井号(#)开头,只有空格字符可以出现在预处理指令之前。
预处理指令不是 C++ 语句,所以它们不会以分号(;)结尾。
我们已经看到,之前所有的实例中都有 #include 指令。这个宏用于把头文件包含到源文件中。
C++ 还支持很多预处理指令,比如 #include、#define、#if、#else、#line 等,让我们一起看看这些重要指令。
#define 预处理
#define 预处理指令用于创建符号常量。该符号常量通常称为宏,指令的一般形式是:
#define macro-name replacement-text
当这一行代码出现在一个文件中时,在该文件中后续出现的所有宏都将会在程序编译之前被替换为 replacement-text。例如:
#include
现在,让我们测试这段代码,看看预处理的结果。假设源代码文件已经存在,接下来使用 -E 选项进行编译,并把结果重定向到 test.p。现在,如果您查看 test.p 文件,将会看到它已经包含大量的信息,而且在文件底部的值被改为如下:
$gcc -E test.cpp > test.p
...
int main ()
{
cout << "Value of PI :" << 3.14159 << endl;
return 0;
}
#include
#include
using namespace std;
#define PI 3.1415926
int main() {
cout << PI << endl;
return 0;
} 

函数宏
您可以使用 #define 来定义一个带有参数的宏,如下所示:
#include
当上面的代码被编译和执行时,它会产生下列结果:
The minimum is 30
#include
#include
using namespace std;
// 年轻即王道
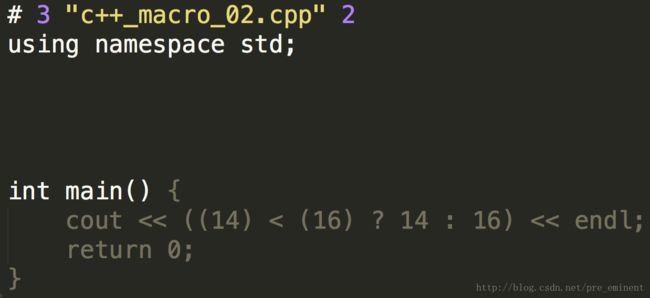
#define Winner(girl_1,girl_2) ((girl_1) < (girl_2) ? girl_1 : girl_2)
int main() {
cout << Winner(14,16) << endl;
return 0;
} 
条件编译
有几个指令可以用来有选择地对部分程序源代码进行编译。这个过程被称为条件编译。
条件预处理器的结构与 if 选择结构很像。
请看下面这段预处理器的代码:
#ifndef NULL
#define NULL 0
#endif
您可以只在调试时进行编译,调试开关可以使用一个宏来实现,如下所示:
#ifdef DEBUG
cerr <<"Variable x = " << x << endl; #endif // 必须有头有尾如果在指令 #ifdef DEBUG 之前已经定义了符号常量 DEBUG,则会对程序中的 cerr 语句进行编译。您可以使用 #if 0 语句注释掉程序的一部分,如下所示:
#if 0
不进行编译的代码
#endif
代码如下:
#include
#include
using namespace std;
// 年轻即王道
#define Winner(girl_1,girl_2) ((girl_1) < (girl_2) ? girl_1 : girl_2)
#ifndef NULL
#define NULL 0
#endif
#define DEBUG 1
int main() {
cout << Winner(14,16) << endl;
if (DEBUG)
{
cout << "现在是debug" << endl;
}
#if 0
#ifdef DEBUG
cout << "de bug" << endl;
#endif
#endif
return 0;
} 让我们尝试下面的实例:
#include
当上面的代码被编译和执行时,它会产生下列结果:
Trace: Inside main function
The minimum is 30
Trace: Coming out of main function#include
#include
using namespace std;
#define DEBUG 1
// 年轻即王道
#define Winner(girl_1,girl_2) ((girl_1) < (girl_2) ? girl_1 : girl_2)
int main() {
int girlAge_1 = 14;
int girlAge_2 = 16;
#ifdef DEBUG
cerr << "this is main loop" << endl;
#endif
#if 0
这是注释部分
#endif
cout << "winner is :" << Winner(girlAge_1,girlAge_2) << endl;
return 0;
} 
# 和 ## 运算符
# 和 ## 预处理运算符在 C++ 和 ANSI/ISO C 中都是可用的。
# 运算符会把 replacement-text 令牌转换为用引号引起来的字符串。
死记住就行
#define makeString(x) #x
这里最后面的#x 会变成 " x "
请看下面的宏定义:
#include
当上面的代码被编译和执行时,它会产生下列结果:
HELLO C++
让我们来看看它是如何工作的。不难理解,C++ 预处理器把下面这行:
cout << MKSTR(HELLO C++) << endl; 转换成了:
cout << "HELLO C++" << endl; 代码如下:
#include
using namespace std;
// 注意: 这儿最后的#x 会变成 " x "
#define makeString(x) #x
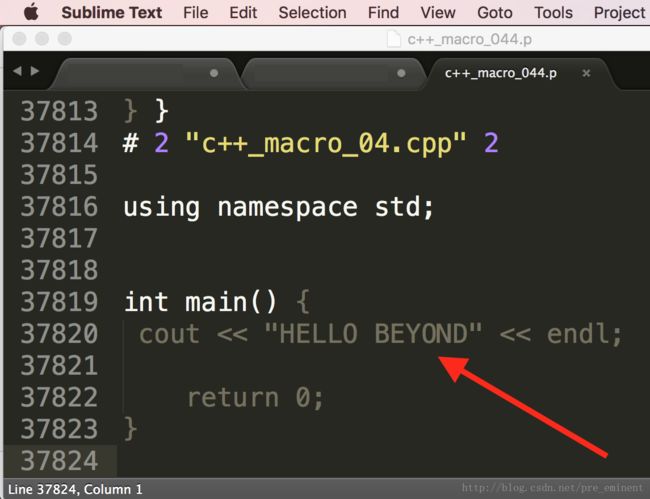
int main() {
cout << makeString(HELLO BEYOND) << endl;
return 0;
} 运行效果如下:

## 运算符用于连接两个令牌。
下面是一个实例:
#define CONCAT( x, y ) x ## y
当 CONCAT 出现在程序中时,它的参数会被连接起来,并用来取代宏。
例如,程序中 CONCAT(HELLO, C++) 会被替换为 "HELLO C++",如下面实例所示。
#include
当上面的代码被编译和执行时,它会产生下列结果:
100
让我们来看看它是如何工作的。不难理解,C++ 预处理器把下面这行:
cout << concat(x, y); 转换成了:
cout << xy; #include
using namespace std;
// ## 会将前后的字母连接在一起,形成新的变量
#define kMakeNewVariable(a,b) a##b
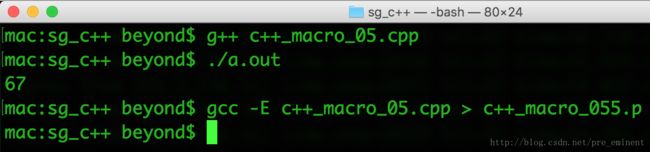
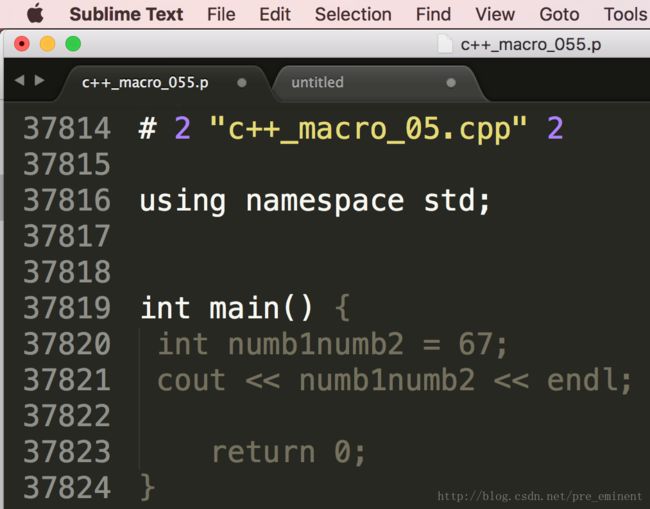
int main() {
int numb1numb2 = 67;
cout << kMakeNewVariable(numb1,numb2) << endl;
return 0;
} 
C++ 中的预定义宏
C++ 提供了下表所示的一些预定义宏:
| 宏 | 描述 |
|---|---|
| __LINE__ | 这会在程序编译时包含当前行号。 |
| __FILE__ | 这会在程序编译时包含当前文件名。 |
| __DATE__ | 这会包含一个形式为 month/day/year 的字符串,它表示把源文件转换为目标代码的日期。 |
| __TIME__ | 这会包含一个形式为 hour:minute:second 的字符串,它表示程序被编译的时间。 |
让我们看看上述这些宏的实例:
#include
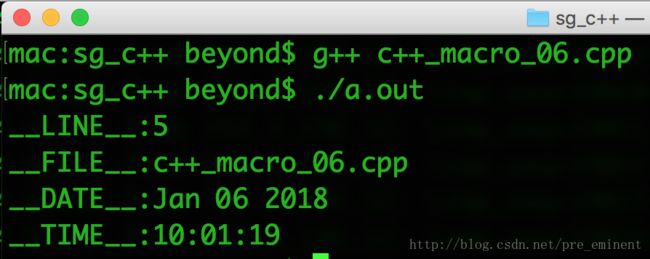
当上面的代码被编译和执行时,它会产生下列结果:
Value of __LINE__ : 6
Value of __FILE__ : test.cpp
Value of __DATE__ : Feb 28 2011
Value of __TIME__ : 18:52:48#include
using namespace std;
int main() {
cout << "__LINE__:" << __LINE__ << endl;
cout << "__FILE__:" << __FILE__ << endl;
cout << "__DATE__:" << __DATE__ << endl;
cout << "__TIME__:" << __TIME__ << endl;
return 0;
} 
C++ 信号处理
信号是由操作系统传给进程的中断,会提早终止一个程序。
在 UNIX、LINUX、Mac OS X 或 Windows 系统上,可以通过按 Ctrl+C 产生中断。
有些信号不能被程序捕获,但是下表所列信号可以在程序中捕获,并可以基于信号采取适当的动作。
这些信号是定义在 C++ 头文件
| 信号 | 描述 |
|---|---|
| SIG ABRT | 程序的异常终止,如调用 abort。 |
| SIG FPE | 错误的算术运算,比如除以零或导致溢出的操作。 |
| SIG ILL | 检测非法指令。 |
| SIG INT | 接收到交互注意信号。(如ctrl+c取消 interrrupt) |
| SIG SEGV | 非法访问内存。(段错误) |
| SIG TERM | 发送到程序的终止请求。 |

signal() 函数
C++ 信号处理库提供了 signal 函数,用来捕获突发事件。以下是 signal() 函数的语法:
void (*signal (int sig, void (*func)(int)))(int);
这个函数接收两个参数:
第一个参数是一个整数,代表了信号的编号;
第二个参数是一个指向信号处理函数的指针。
让我们编写一个简单的 C++ 程序,使用 signal() 函数捕获 SIGINT 信号。(用户按ctrl+c取消 interrupt)
不管您想在程序中捕获什么信号,您都必须使用 signal 函数来注册信号,并将其与信号处理程序相关联。
看看下面的实例:
#include
当上面的代码被编译和执行时,它会产生下列结果:
Going to sleep....
Going to sleep....
Going to sleep....
现在,按 Ctrl+C 来中断程序,您会看到程序捕获信号,程序打印如下内容并退出:
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.#include
#include
// sleep函数用到的头文件
#include
using namespace std;
// 补获用户的ctrl + c取消的信号interrupt
void catchSignalHandler(int signalNumber);
int main() {
// 1.第一步,必须注册信号
signal(SIGINT,catchSignalHandler);
// 进入死循环,等待用户ctrl + c
while(1){
cout << "来打我呀" << endl;
sleep(3);
}
return 0;
}
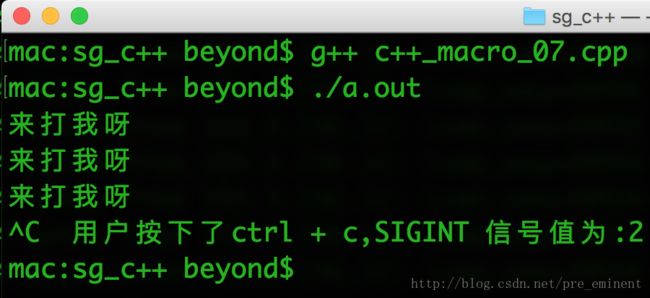
// 补获用户的ctrl + c取消的信号interrupt
void catchSignalHandler(int signalNumber)
{
cout << "用户按下了ctrl + c" << signalNumber << endl;
// 这行代码是什么意思?
exit(signalNumber);
} 
raise() 函数
您可以使用函数 raise() 生成信号,该函数带有一个整数信号编号作为参数,语法如下:
int raise (signal sig);
在这里,sig 是要发送的信号的编号,这些信号包括:
SIGINT、用户取消如interrupt
SIGABRT、异常终止,如abort()
SIGFPE、算术运算错误,如除零
SIGILL、非法指令
SIGSEGV、非法内存访问,如段错误
SIGTERM、终止请求
SIGHUP。挂起信号
以下是我们使用 raise() 函数内部生成信号的实例:
#include
当上面的代码被编译和执行时,它会产生下列结果,并会自动退出:
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.附Linux信号列表
下面我们对编号小于SIGRTMIN的信号进行讨论。
1) SIGHUP
本信号在用户终端连接(正常或非正常)结束时发出, 通常是在终端的控制进程结束时, 通知同一session内的各个作业, 这时它们与控制终端不再关联。
登录Linux时,系统会分配给登录用户一个终端(Session)。
2) SIGINT
程序终止(interrupt)信号, 在用户键入INTR字符(通常是Ctrl-C)时发出,用于通知前台进程组终止进程。
和SIGINT类似, 但由QUIT字符(通常是Ctrl-\)来控制. 进程在因收到SIGQUIT退出时会产生core文件, 在这个意义上类似于一个程序错误信号。
4) SIGILL
执行了 非法指令. 通常是因为可执行文件本身出现错误, 或者试图执行数据段. 堆栈溢出时也有可能产生这个信号。
由断点指令或其它trap指令产生. 由debugger使用。
6) SIGABRT
调用abort函数生成的信号。
7) SIGBUS
非法地址, 包括内存地址对齐(alignment)出错。比如访问一个四个字长的整数, 但其地址不是4的倍数。
8) SIGFPE
在发生致命的算术运算错误时发出. 不仅包括浮点运算错误, 还包括溢出及除数为0等其它所有的算术的错误。
9) SIGKILL
用来立即结束程序的运行. 本信号不能被阻塞、处理和忽略。如果管理员发现某个进程终止不了,可尝试发送这个信号。
10) SIGUSR1
留给用户使用
11) SIGSEGV
试图访问未分配给自己的内存, 或试图往没有写权限的内存地址写数据.由于 对合法存储地址的非法访问触发的(如访问不属于自己存储空间或只读存储空间)。 段错误
12) SIGUSR2
留给用户使用
13) SIGPIPE
管道破裂。这个信号通常在进程间通信产生,
14) SIGALRM
时钟定时信号, 计算的是实际的时间或时钟时间. alarm函数使用该信号.
15) SIGTERM
程序结束(terminate)信号, 与SIGKILL不同的是该信号可以被阻塞和处理。
17) SIGCHLD
子进程结束时, 父进程会收到这个信号。
如果父进程没有处理这个信号,也没有等待(wait)子进程,子进程虽然终止,但是还会在内核进程表中占有表项,这时的子进程称为 僵尸进程。
让一个停止(stopped)的进程继续执行. 本信号不能被阻塞. 可以用一个handler来让程序在由stopped状态变为继续执行时完成特定的工作. 例如, 重新显示提示符
19) SIGSTOP
停止(stopped)进程的执行. 注意它和terminate以及interrupt的区别:该进程还未结束, 只是暂停执行. 本信号不能被阻塞, 处理或忽略.
20) SIGTSTP
停止进程的运行, 但该信号可以被处理和忽略. 用户键入SUSP字符时(通常是Ctrl-Z)发出这个信号
21) SIGTTIN
当后台作业要从用户终端读数据时, 该作业中的所有进程会收到SIGTTIN信号. 缺省时这些进程会停止执行.
22) SIGTTOU
类似于SIGTTIN, 但在写终端(或修改终端模式)时收到.
23) SIGURG
有"紧急"数据或out-of-band数据到达socket时产生.
24) SIGXCPU
超过CPU时间资源限制. 这个限制可以由getrlimit/setrlimit来读取/改变。
25) SIGXFSZ
当进程企图扩大文件以至于超过文件大小资源限制。
26) SIGVTALRM
虚拟时钟信号. 类似于SIGALRM, 但是计算的是该进程占用的CPU时间.
27) SIGPROF
类似于SIGALRM/SIGVTALRM, 但包括该进程用的CPU时间以及系统调用的时间.
28) SIGWINCH
窗口大小改变时发出.
29) SIGIO
文件描述符准备就绪, 可以开始进行输入/输出操作.
30) SIGPWR
Power failure
31) SIGSYS
非法的系统调用。
在以上列出的信号中,
不能恢复至默认动作的信号有:SIGILL,SIGTRAP
默认会导致进程流产的信号有:SIGABRT,SIGBUS,SIGFPE,SIGILL,SIGIOT,SIGQUIT,SIGSEGV,SIGTRAP,SIGXCPU,SIGXFSZ
默认会导致进程退出的信号有:SIGALRM,SIGHUP,SIGINT,SIGKILL,SIGPIPE,SIGPOLL,SIGPROF,SIGSYS,SIGTERM,SIGUSR1,SIGUSR2,SIGVTALRM
默认会导致进程停止的信号有:SIGSTOP,SIGTSTP,SIGTTIN,SIGTTOU
默认进程忽略的信号有:SIGCHLD,SIGPWR,SIGURG,SIGWINCH
此外,SIGIO在SVR4是退出,在4.3BSD中是忽略;SIGCONT在进程挂起时是继续,否则是忽略,不能被阻塞
Linux下编程(尤其是服务端程序)若由于内存越界或其他原因产生“非法操作”,会导致程序悄无声息地死去。其实“非法操作”在绝大多数时候是因为“段错误”,即 SIGSEGV。而找到SIGSEGV信号抛出的位置,也就找到了程序死掉的原因。
下面列出一些捕获SIGSEGV的方法。
假设程序名为 myprg,其进程ID(pid)为 5267。方法一:
# ./myprg // 运行程序
# ps -ef | grep myprg // 找出 myprg 的 pid
# gdb myprg 5267 > debug.log // 让 gdb 接管 myprg 的运行
# (gdb) continue
此方法利用gdb调试器捕获SIGSEGV。上例中,将gdb输出信息存入debug.log,关闭终端,gdb并不退出,继续运行直到 myprg 出错退出。gdb将捕获到出错点。
代码如下:
#include
#include
// sleep函数用到的头文件
#include
using namespace std;
// 补获用户的ctrl + c取消的信号interrupt
void catchSignalHandler(int signalNumber);
int main() {
// 1.第一步,必须注册信号
signal(SIGINT,catchSignalHandler);
int i = 0;
while(++i){
cout << "来打我呀" << endl;
if (i == 5)
{
// 主动发出信号
raise(SIGINT);
}
sleep(1);
}
return 0;
}
// 补获用户的ctrl + c取消的信号interrupt
void catchSignalHandler(int signalNumber)
{
cout << " 用户按下了ctrl + c,\n或者主动raise了信号 SIGINT 信号值为:" << signalNumber << endl;
// 这行代码是什么意思?
exit(signalNumber);
} 运行效果如下:

C++ STL 教程
在前面的章节中,我们已经学习了 C++ 模板的概念。
C++ STL(标准 模板 库)是一套功能强大的 C++ 模板类,提供了通用的模板类和函数,
这些模板类和函数可以实现多种流行和常用的算法和数据结构,如向量、链表、队列、栈。
C++ 标准模板库的核心包括以下三个组件:
| 组件 | 描述 |
|---|---|
| 容器(Containers) | 容器是用来管理某一类对象的集合。C++ 提供了各种不同类型的容器, 比如 deque、list、vector、map 等。 |
| 算法(Algorithms) | 算法作用于容器。它们提供了执行各种操作的方式, 包括对容器内容执行初始化、排序、搜索和转换等操作。 |
| 迭代器(iterators) | 迭代器用于遍历对象集合的元素。 这些集合可能是容器,也可能是容器的子集。 |
这三个组件都带有非常丰富的预定义函数,帮助我们通过简单的方式处理复杂的任务。
下面的程序随随便便地就演示了向量容器(一个 C++ 标准的模板),
它与数组十分相似,唯一不同的是,向量在需要扩展大小的时候,会自动处理它自己的存储需求:
#include
当上面的代码被编译和执行时,它会产生下列结果:
vector size = 0
extended vector size = 5
value of vec [0] = 0
value of vec [1] = 1
value of vec [2] = 2
value of vec [3] = 3
value of vec [4] = 4
value of v = 0
value of v = 1
value of v = 2
value of v = 3
value of v = 4
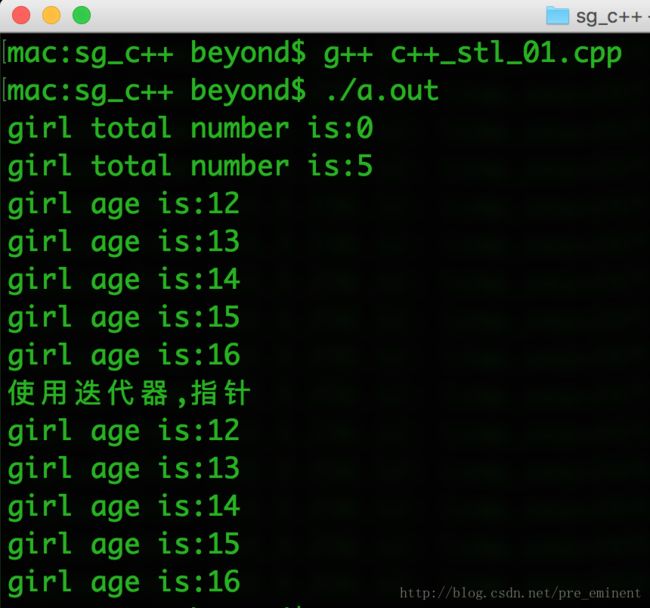
代码如下:
#include
#include
using namespace std;
int main() {
vector girlVector;
cout << "girl total number is:" << girlVector.size() << endl;
for (int age = 12; age < 17; ++age)
{
girlVector.push_back(age);
}
cout << "girl total number is:" << girlVector.size() << endl;
for (int i = 0; i < 5; ++i)
{
cout << "girl age is:" << girlVector[i] << endl;
}
cout << "使用迭代器,指针" << endl;
// 使用迭代器,指针
vector::iterator p = girlVector.begin();
while(p != girlVector.end()){
cout << "girl age is:" << *p << endl;
// 指针++
p++;
}
return 0;
} 运行效果如下:
关于上面实例中所使用的各种函数,有几点要注意:
- push_back( ) 成员函数在向量的末尾插入值,如果有必要会扩展向量的大小。
- size( ) 函数显示向量的大小。
- begin( ) 函数返回一个指向向量开头的迭代器(指针)。
- end( ) 函数返回一个指向向量末尾的迭代器(指针)。
C++ 标准库
C++ 标准库可以分为两部分:
- 标准函数库: 这个库是由通用的、独立的、不属于任何类的函数组成的。函数库继承自 C 语言。
- 面向对象类库: 这个库是类及其相关函数的集合。
C++ 标准库包含了所有的 C 标准库,为了支持类型安全,做了一定的添加和修改。
标准函数库
标准函数库分为以下几类:
- 输入/输出 I/O
- 字符串和字符处理
- 数学
- 时间、日期和本地化
- 动态分配
- 其他
- 宽字符函数
面向对象类库
标准的 C++ 面向对象类库定义了大量支持一些常见操作的类,比如输入/输出 I/O、字符串处理、数值处理。面向对象类库包含以下内容:
- 标准的 C++ I/O 类
- String 类
- 数值类
- STL 容器类
- STL 算法
- STL 函数对象
- STL 迭代器
- STL 分配器
- 本地化库
- 异常处理类
- 杂项支持库