Unity渲染管线,初探SRP
渲染管线流程图

应用阶段
主要任务:
- 手动准备好场景数据,摄像机位置,视锥体,包含哪些模型,使用哪些光源等等。
- 把不可见的物体,剔除出去
- 设置模型的渲染状态,包括材质(漫反射颜色、高光反射颜色),使用的纹理,Shader等,还有其他
作用:输出几何信息,即渲染图元,点,线,三角面等
阶段:
- 把数据加载到显存中
- 设置渲染状态
- 调用DrawCall(渲染命令)
几何阶段
主要任务:
- 主要处理要绘制的几何相关的事情,例如,需要绘制的图元是什么,怎么,在哪绘制它们,几何阶段负责和每个渲染图元打交道
- 输出屏幕的二维顶点坐标,每个顶点对应的深度值,着色等相关信息,并传递给下一个阶段
阶段:
- 顶点着色器(可编程):顶点的空间变换和顶点着色
- 曲面细分着色器(可选):细分图元(对于一些有大量曲面的模型,进行曲面细分可以让曲面更加圆润;如果为这些细分的顶点再准备一些位置信息,那么这些细分的顶点将有助于我们展现一个细节更加丰富的模型。这也是贴图置换(Displacement Mapping)的基本思路。)
- 几何着色器(可选):执行逐图元的着色操作,或者用于产生更多的图元。在这个阶段,开发者可以控制GPU对顶点进行增删改操作。几何着色器与顶点着色器都可以对顶点的坐标进行修改,但几何体着色器并行调用硬件困难,并行程度低,效率和顶点着色器有很大的差距;如果不是要做顶点增、删这些仅仅能用几何着色器实现的效果,那么还是用顶点着色器来完成吧。
- 投影:GPU将顶点从摄像机观察空间转换到裁剪空间(又被称为齐次裁剪空间),为之后的剔除过程以及投射到二维平面做准备
- 裁剪(可配置):可自定义裁剪区域,比如裁剪正面还是背面,不在摄像机视野内的顶点裁剪掉,并剔除某些三角形图元的面片
- 屏幕映射:负责每个图元的坐标转换到屏幕坐标系中
光栅化阶段
主要任务:
- 使用上个阶段传递的数据来产生屏幕上的像素,并渲染出最终的图像
- 决定每个渲染图元中的哪些像素应该被绘制在屏幕上
- 对上一个阶段得到的逐顶点数据(纹理坐标、顶点颜色等)进行插值,然后在进行逐像素处理
阶段:
- 三角形设置:把顶点数据收集并组装为简单的基本体(线、点或三角形)
- 三角形遍历:这个过程将检验屏幕上的某个像素是否被一个三角形网格所覆盖,被覆盖的区域将生成一个片元(Fragment)
- 片元着色器(可编程):实现逐片元的着色操作
- 逐片元操作(可配置):对每个片元进行操作,将它们的颜色以某种形式合并,得到最终在屏幕上像素显示的颜色。主要的工作有两个:对片元进行测试(Test)并进行合并。测试步骤决定了片元最终会不会被显示出来。在OpenGL中,主要的测试有:裁剪测试(Scissor Test)、透明度测试(Alpha Test)、模板测试(Stencil Test)以及深度测试(Depth Test)。这个阶段是高度可配置的。如果一个片元通过了上面所有的测试,那它终于可以来到合并环节了。合并有两种主要的方式,一种是直接进行颜色的替换,另一种是根据不透明度进行混合(Blend),而混合操作同样是可配置的,程序员可以设定是把这两种颜色进行相加、相减还是相乘等等。在经过上面的层层测试后,片元颜色就会被送到颜色缓冲区。GPU会使用双重缓冲(Double Buffering)的策略,即屏幕上显示前置缓冲(Front Buffer),而渲染好的颜色先被送入后置缓冲(Back Buffer),再替换前置缓冲,以此避免在屏幕上显示正在光栅化的图元。
- 最终屏幕图像
SRP/URP/HDRP之间的关系
下图是各个管线的关系图

根据上图所示,URP是Unity可编程渲染管线(SRP)的一种,所以了解URP之前需要先了解SRP是什么。
SRP是什么
SRP全称为Scriptable Render Pipeline(可编程渲染管线/脚本化渲染管线),是Unity提供的新渲染系统,可以在Unity通过C#脚本调用一系列API配置和执行渲染命令的方式来实现渲染流程,SRP将这些命令传递给Unity底层图形体系结构,然后再将指令发送给图形API。
说白了就是我们可以用SRP的API来创建自定义的渲染管线,可用来调整渲染流程或修改或增加功能。
它主要把渲染管线拆分成二层:
- 一层是比较底层的渲染API层,像OpenGL,D3D等相关的都封装起来。
- 另一层是渲染管线上层,上层代码使用C#来编写。在C#这层不需要关注底层在不同平台上渲染API的差别,也不需要关注具体如何做一个Draw Call
URP是什么
它的全称为Universal Render Pipeline(通用渲染管线), 它是Unity官方基于SRP提供的模板,它的前身是LWRP(Lightweight RP即轻量级渲染管线), 在2019.3开始改名为URP,它涵盖了范围广泛的不同平台,是针对跨平台开发而构建的,性能比内置管线要好,另外可以进行自定义,实现不同风格的渲染,通用渲染管线未来将成为在Unity中进行渲染的基础 。
平台范围:可以在Unity当前支持的任何平台上使用
HDRP是什么
它的全称为High Definition Render Pipeline(高清晰度渲染管线),它也是Unity官方基于SRP提供的模板,它更多是针对高端设备,如游戏主机和高端台式机,它更关注于真实感图形和渲染,该管线仅于以下平台兼容:
- Windows和Windows Store,带有DirectX 11或DirectX 12和Shader Model 5.0
- 现代游戏机(Sony PS4和Microsoft Xbox One)
- 使用金属图形的MacOS(最低版本10.13)
- 具有Vulkan的Linux和Windows平台
在此文章对HDRP不过多描述。
为什么诞生SRP
内置渲染管线的缺陷
- 定制性差:过去,Unity有一套内置渲染管线,渲染管线全部写在引擎的源码里。大家基本上不能改动,除非是买了Unity源码客户,当然大部分开发者是不会去改源码,所以过去的管线对开发者来说,很难进行定制。
- 代码脓肿,效果效率无法做到最佳:内置渲染管线在一个渲染管线里面支持所有的二十多个平台,包括非常高端的PC平台,也包括非常低端的平台,很老的手机也要支持,所以代码越来越浓肿,很难做到使效率和效果做到最佳。
目的:
- 为了解决仅有一个默认渲染管线,造成的可配置型、可发现性、灵活性等问题。决定在C++端保留一个非常小的渲染内核,让C#端可以通过API暴露出更多的选择性,也就是说,Unity会提供一系列的C# API以及内置渲染管线的C#实现;这样一来,一方面可以保证C++端的代码都能严格通过各种白盒测试,另一方面C#端代码就可以在实际项目中调整。

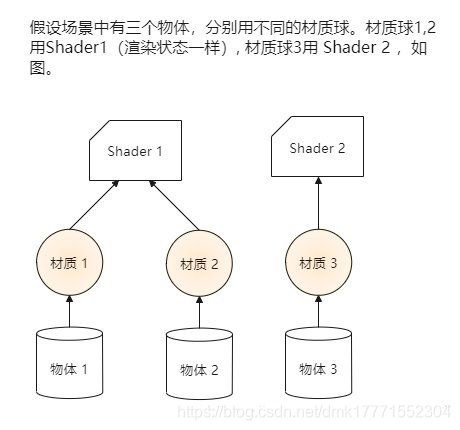
DrawCall Batch SetPassCalls
在看URP 和 内置渲染管线 性能对比之前最好先了解DrawCall,Batches,SetPassCalls分别是什么值。
Set Pass Call代表渲染状态切换,主要出现在材质不一致的时候,进行渲染状态切换。我们知道一个batch包括,提交vbo(顶点缓冲区对象),提交ibo(索引缓冲区对象),提交shader,设置好硬件渲染状态,设置好光源属性等(注意提交纹理严格意义上并不包括在一个batch内,纹理可以被缓存并多帧复用)。如果一个batch和另一个batch使用的不是同种材质或者同一个材质的不同pass,那么就要触发一次set pass call来重新设定渲染状态。例如,Unity要渲染20个物体,这20个物体使用同种材质(但不一定mesh等价),假设两次dynamic batch各自合批了10个物体,则对于这次渲染,set pass call为1(只需要渲染一个材质),batch为2(向GPU提交了两次VBO,IBO等数据)。
Draw call严格意义上,CPU每次调用图形API的渲染函数(使用OpenGL举例,是glDrawElements或者DrawIndexedPrimitive)都算作一次Draw Call,但是对于Unity而言,它可以多个Draw Call合并成一个Batch去渲染。
真正造成开销较大的地方,第一个在于在于切换渲染状态,第二在于整理和提交数据。在真正的实践过程当中,可以不用过于介意Draw call这个数字(因为没有提交数据或者切换渲染状态的话,其实多来几个draw call没什么所谓),但是Set Pass Call和Batch两个数字都要想办法降低。由于二者存在强相关性,那么通常降低一个,就一并可以降低第二个。
Unity提供了三种批次合并的方法,分别是Static Batching,GPU Instancing和Dynamic Batching。它们的原理分别如下:
Static Batching,将静态物体集合成一个大号vbo提交,但是只对要渲染的物体提交其IBO。这么做不是没有代价。比如说,四个物体要静态批次合并前三个物体每个顶点只需要位置,第一套uv坐标信息,法线信息,而第四个物体除了以上信息,还多出来切线信息,则这个VBO会在每个顶点都包括所有的四套信息,毫无疑问组合这个VBO是要对CPU和显存有额外开销的。要求每一次Static Batching使用同样的material,但是对mesh不要求相同。
Dynamic Batching将物体动态组装成一个个稍大的vbo+ibo提交。这个过程不要求使用同样的mesh,但是也一样要求同样的材质。但是,由于每一帧CPU都要将每个物体的顶点从模型坐标空间变换到组装后的模型的坐标空间,这样做会带来一定的计算压力。所以对于Unity引擎,一个批次的动态物体顶点数是有限制的。
GPU Instancing是只提交一个物体的mesh,但是将多个使用同种mesh和material的物体的差异化信息(包括位置,缩放,旋转,shader上面的参数等。shader参数不包括纹理)组合成一个PIA(per instanced attribute实例属性)提交。在GPU侧,通过读取每个物体的PIA数据,对同一个mesh进行各种变换后绘制。这种方式相比static和dynamic节约显存,又相比dynamic节约CPU开销。但是相比这两种批次合并方案,会略微给GPU带来一定的计算压力。但这种压力通常可以忽略不计。限制是必须相同材质相同物体,但是不同物体的材质上的参数可以不同。
所以Unity默认策略是优先static,其次gpu instancing,最后dynamic。当然如果顶点数过于巨大(比如渲染它几千颗使用同种mesh的树),那么gpu instancing或许比static batching是一个更加合适的方案。
URP 和 内置渲染管线 性能对比
主要提速的有两个方面
1. 光照处理(包括阴影)
2. SRP Bacher (SRP 批处理)(重点)
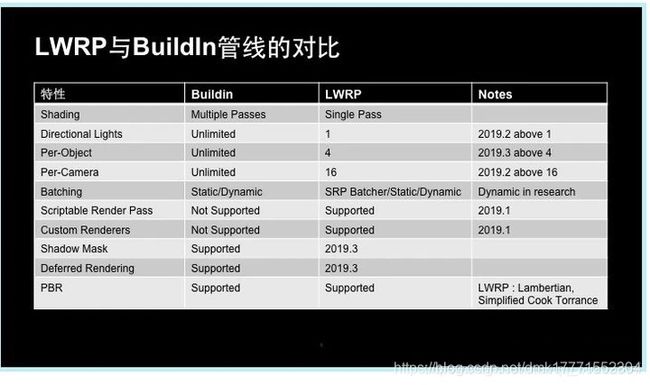
首先来说说光照处理部分

如上图所示,老的渲染管线使用Multi-Pass的Forward Rendering,就是多Pass的前向渲染。最大的问题是如果要在场景里要加很多动态光的话,每一个动态光都有可能会增加一个Pass,这个动态光所影响的物体要多画一遍。
这就导致如果游戏里想要有多个动态光的话,可能这个场景会被画很多遍,性能会很差。它带来的问题是所有的游戏几乎都不会用多个动态光,因为实在太费性能了。
在过去制作移动的游戏的过程中,大家的标准做法都是烘焙Lightmap。
现在URP就解决了这个问题。实现了一个单PASS的正向渲染。可以支持多盏动态光,但是全部动态灯光都会放在一个Pass里渲染,这样带来的问题是要限制灯光的数量,因为每次Draw Call去画的时候,传给GPU的参数是有限的。
如果灯光数量特别多,参数太多,那就会无法在一次Draw Call里完成很多个灯光。所以我们有一些限制,在轻量级渲染管线LWRP里,目前是支持1盏平行光,每个对象可能只能接受4个动态光。每个摄像机也有一些限制,这是为了我们可以把所有的计算放在一个Pass里面。
接下来看看内置渲染管线和URP各种情况下的光照处理对比
以下是分别在四种情况下对比所得出的结论
- 无光源。 (没区别)
- 一个平行光,无阴影。(没区别)
- 一个平行光,一个点光源,无阴影。
结论:内置渲染管线跟只有一个平行光时比起来Batches将近增加了一倍,而URP的Batches和SetPass calls跟一个平行光时一样,一点都没有增加。 - 一个动态光,有阴影。
结论:在阴影的处理方面URP性能比内置渲染管线好很多。
URP光照处理最终结论:
1. 性能上阴影处理方面比内置渲染管线好很多。
2. URP平行光基础上添加动态光没有带来额外的Batches和SetPass calls性能开销。
接下来看看SRP Batcher(重点)
SRP Batcher 是什么
SRP Batcher 是一个底层渲染循环,可通过许多使用同一着色器变体的材质来加快场景中的 CPU 渲染速度。
就算是不同的材质球,只要是用一个着色器变体的物体都可以批处理到一块。(在2019.3.4版本 渲染顺序也会打断批处理,这点上官网没有说明,也许后续版本已经处理了),它的主要目的是减少渲染状态设置的开销,还有就是把物体属性用专用代码快速更新。
上面解释都提到了变体,那么变体怎么理解呢?
multi_compile和shader_feature这两个关键字就是实现着色器变体的指令。
下面是自定义的multi_compile 关键字。

上图中定义了两个multi_complie,white和black两个关键字,此时Unity会生成两个变体,一个是走white逻辑的变体,另外一个是走black逻辑的变体。然后在脚本中通过Material.EnableKeyWord和Shader.EnableKeyword来开启某功能,通过Material.DisableKeyword和Shader.DisableKeyword来关闭某功能。为什么这么做呢?主要是为了避免分支语句(if )导致的性能下降。
。
除了关键字还有这些
参数不一致的话也无法批处理到一块。
shader_feature关键字跟multi_compile不一样的是未被选择的变体会在打包的时候被舍弃(multi_complie不会),shader_feature主要是在材质球选项上控制开关,比如

这个选项。
URP的Lit Shader里有很多实现变体指令,所以这些Shader生成的变体也有很多。如图:

过去,Unity 中,可以在一帧内的任何时间修改任何材质的属性。但是,这种做法有一些缺点。当Draw Calls使用新材质时,需要进行很多处理。场景内的材质越多,设置GPU数据所需的CPU资源就越多。解决此问题的传统方法是减少 DrawCall 的数量以优化 CPU 渲染成本,因为 Unity 在发出 DrawCall 之前必须进行很多设置。实际的 CPU 成本来自该设置,而不是来自 GPU DrawCall 本身(DrawCall 只是 Unity 需要推送到 GPU 命令缓冲区的少量字节)。
这是官网说的提速效果:
Unity 2018引入了可编程渲染管线SRP,其中包含新的底层渲染循环SRP Batcher批处理器,它可以大幅提高CPU在渲染时的处理速度,根据场景内容的不同,提升效果为原来的1.2~4倍不等。
SRP Batcher是怎么优化的?
SRP Batcher使材质数据持久保留在 GPU 内存中。如果材质内容不变,SRP Batcher 不需要设置缓冲区并将缓冲区上传到 GPU。还有 SRP Batcher 会使用专用的代码路径来快速更新大型 GPU 缓冲区中的 Unity 引擎属性,如下图。

上面的功能能解决什么问题呢?也就是CPU不需要再设置渲染状态和一大堆渲染数据设置,只需要物体跟缓冲区的数据绑定就可以了。
SRP Batcher 正是通过批处理一系列 Bind 和 Draw GPU 命令来减少 DrawCall 之间的 GPU 设置。
内置渲染管线和URP的CPU原理图对比
内置渲染管线:(红框部分就是SRP Batcher优化的性能部分)

URP:
在把材质数据和物体数据上传好后的流程图:(GPU没有详细画,主要看CPU)
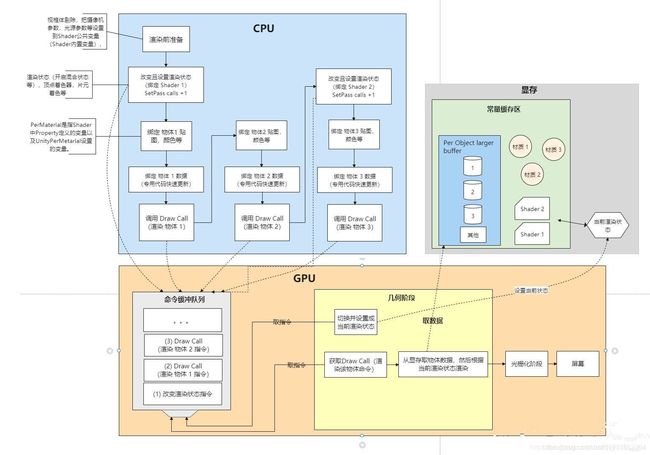
上面流程图中绑定的意思是大家都知道Shader里有很多变量,如纹理贴图,Property定义的变量以及内置变量等,个人理解是把缓冲区里存的渲染数据设置给了Shader变量。
根据上面内容我们可以知道SRP Batcher并没有减少DrawCall,而是优化了DrawCall之前的设置开销。
SRP Batch值我们可以在Frame Debug窗口可以看得到。
SRP Batcher 兼容性
为了使 SRP Batcher 代码路径能够渲染对象:
- 渲染的对象必须是mesh或者skinned mesh。该对象不能是粒子。
- 着色器必须与 SRP Batcher 兼容。HDRP 和 URP 中的所有光照和无光照着色器均符合此要求(这些着色器的“粒子”版本除外)。
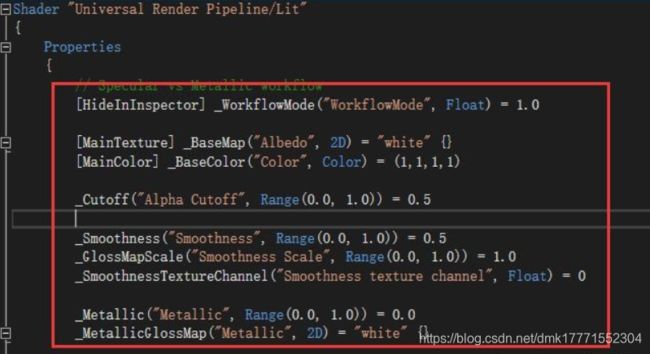
为了使着色器与 SRP Batcher 兼容:
- 必须在一个名为“UnityPerDraw”的 CBUFFER 中声明所有内置引擎属性。例如:
unity_ObjectToWorld。 - 必须在一个名为
UnityPerMaterial的 CBUFFER 中声明所有材质属性。

Property定义的属性也是属于PerMaterial.
可以在 Inspector 面板中查看着色器的兼容性状态。
