综述:大规模小目标检测
- 论文地址:
Towards Large-Scale Small Object Detection: Survey and Benchmarksarxiv.org/abs/2207.14096
目录
摘要
1.Introduction
1.1 与之前综述的比较
1.2 总结
2.小目标检测回顾
2.1 问题定义
2.2 主要挑战
2.3 小目标检测算法回顾
3.小目标检测的数据集
3.1 数据集
3.2 评估指标 - 平均精度
4.SODA-D和SODA-A数据集构建
5.实验
6.总结和展望
摘要
随着深度卷积神经网络的兴起,目标检测在过去几年取得了显著的进展。然而,这样的繁荣并不能掩盖小目标检测(SOD)不理想的情况,这是计算机视觉中最具挑战性的任务之一,因为小目标的内在结构导致视觉外观差和噪声表示。此外,大规模数据集对小目标检测方法的基准测试仍然是一个瓶颈。在本文中,我们首先对小目标检测进行了全面的综述。然后,为了促进SOD的发展,我们构建了两个大型小目标检测数据集SODA (Small Object Detection dAtasets), SODA-D和SODA-A,分别针对Driving和Aerial场景。SODA-D包括24704个高质量流量图像和277596个9类实例。对于SODA-A,我们获取了2510张高分辨率航空图像,并在9个类上注释了800203个实例。正如我们所知,提出的数据集是首次尝试使用为多类别SOD定制的大量注释详尽的实例集合进行大规模基准测试。最后,我们评估了主流方法在SODA上的性能。我们期望发布的基准能够促进SOD的发展,并在该领域产生更多的突破。
1.Introduction
目标检测是对图像/视频中感兴趣的目标进行分类和定位的一项重要任务。由于深度卷积神经网络(deep Convolutional Neural Networks, CNNs)拥有庞大的数据量和强大的学习能力,近年来目标检测取得了显著的成就。小目标检测(Small Object Detection, SOD)作为通用目标检测的一个子领域,专注于对小尺寸目标的检测,在监控、无人机场景分析、行人检测、自动驾驶中的交通标志检测等各种场景中都具有重要的理论和现实意义。
虽然在一般目标检测方面已经取得了长足的进展,但SOD的研究进展相对缓慢。更具体地说,即使是领先的检测器,在检测小尺寸物体和正常大小物体方面仍然存在巨大的性能差距。以目前最先进的检测器之一DyHead为例,在COCO测试开发集上,DyHead获得的小尺寸物体的mean Average Precision (mAP)度量仅为28.3%,明显落后于中尺寸和大尺寸物体(50.3%和57.5%)。我们认为这种性能下降源于以下两个方面: 1)从有限和扭曲的小物体信息中学习正确表示的内在困难; 2)用于小目标检测的大规模数据集的稀缺。
小物体的特征表示质量不高的原因是它们的尺寸有限和一般的特征提取范式。具体而言,目前流行的特征提取器通常对特征映射进行下采样,以减少空间冗余和学习高维特征,这不可避免地会减少小物体的表示。而且小目标的特征在卷积处理后容易被背景等实例污染,使得网络难以捕捉到对后续任务至关重要的判别性信息。针对这一问题,研究人员提出了一系列的工作,可分为6类: 数据操作方法、尺度感知方法、特征融合方法、超分辨率方法、上下文建模方法和其他方法。我们将在综述部分详尽地讨论这些方法,并将提供深入的分析。为了缓解数据的不足,一些针对小目标检测的数据集被提出,如SOD和TinyPerson。
然而,这些小规模的数据集不能满足训练监督的基于CNN的算法的需求,这些算法渴望大量的标记数据。此外,一些公共数据集包含相当数量的小对象,如WiderFace、SeaPerson和DOTA等。不幸的是,这些数据集要么是为通常遵循相对确定的模式的单类别检测任务(人脸检测或行人检测)设计的,要么是其中微小的物体仅仅分布在几个类别中(DOTA数据集中的小型车辆)。总而言之,目前可用的数据集无法支持定制小目标检测的基于深度学习的模型训练,也无法作为评估多类SOD算法的公正基准。同时,PASCAL VOC、ImageNet、COCO和DOTA等大规模数据集的可访问性作为构建数据驱动的深度CNN模型的基础,对学术界和工业界都具有重要意义,它们都显著促进了相关领域的目标检测的发展。这启发我们思考: 我们是否可以建立一个大规模的数据集,其中多个类别的对象的大小都非常有限,作为一个基准,用来验证小目标检测框架的设计,方便对SOD的进一步研究?
考虑到上述问题,我们构建了两个大型小目标检测数据集, SODA-D和SODA-A,分别针对驾驶场景和空中场景。提出的SODA-D建立在MVD和我们的数据之上,其中前者是一个专门用于街道场景像素级理解的数据集,而后者主要由车载摄像头和手机捕获。利用24704张精心挑选的高质量驾驶场景图像,我们用水平边框标注了9个类别的277596个实例。SODA-A是专门用于空中场景下的小目标检测任务的基准测试,它在9个类中有800203个实例,具有面向矩形框注释。它包含了2510张从谷歌地球提取的高分辨率图像。
1.1 与之前综述的比较
- 全面、及时的回顾,专门针对跨多个领域的小目标检测任务。以前的综述大多数集中于通用物体检测或特定物体检测,如行人检测、文本检测、遥感图像检测和交通场景检测等。此外,已经有几篇文章关注小目标检测,但其仅对有限的区域进行了部分总结,因此未能进行全面和深入的分析。本文通过回顾数百篇与小目标检测相关的文献,涵盖了广泛的研究领域,包括人脸检测、行人检测、交通标志检测、车辆检测、航空图像中的目标检测等,我们提供了一个小目标检测的系统调查和一个可理解的分类法,该分类法根据所使用的技术将SOD方法分为六大类。
- 提出了两个针对小目标检测定制的大规模基准,并在此基础上对几个代表性的检测算法进行了深入评估和分析。我们提出了大规模的Benchmark SODA,能够对几种代表性方法进行全面评估,此外,我们还提供了公正的性能比较和详细分析,这在以前的综述中是缺乏的。
1.2 总结
本文的主要贡献有三个方面:
- 回顾了深度学习时代小目标检测的发展,系统地综述了该领域的最新进展,主要分为6类: 数据操作方法、尺度感知方法、特征融合方法、超分辨率方法、上下文建模方法和其他方法。除分类法外,还对这些方法的优缺点进行了深入分析。同时,我们回顾了十几组数据集,这些数据集跨越多个领域,涉及到小目标检测。
- 发布了两个用于小目标检测的大型基准,第一个用于驾驶场景,另一个用于空中场景。提议的数据集是首次尝试为SOD定制大规模基准。我们希望这两个详尽注释的基准能够帮助研究人员开发和验证SOD的有效框架,并促进该领域的更多突破。
- 研究了几种具有代表性的目标检测方法在我们的数据集上的性能,并根据定量和定性的结果进行深入分析,为后续的小目标检测算法设计提供借鉴。
2.小目标检测回顾
2.1 问题定义
目标检测旨在对实例进行分类和定位。小物体检测或微小物体检测仅仅关注于检测具有有限尺寸的物体。在本任务中,通常通过面积阈值或长度阈值来定义小(即如何确定一个目标为小目标)。以COCO为例,面积小于等于1024像素的对象属于小类。考虑到目前为止,关于小对象还没有统一和明确的定义,除非在本节中有所规定,我们遵循原始论文中关于小对象和小对象的表达式。
2.2 主要挑战
- 信息损失。当前流行的目标检测器通常包括主干网络和检测头,后者根据前者输出的表示做出决定。这种范式被证明是有效的,并带来了前所未有的成功。然而,通用特征提取器常利用子采样操作来过滤噪声激活,并降低特征图的空间分辨率,从而不可避免地丢失对象的信息。这种信息损失几乎不会在一定程度上影响大中型物体的性能,因为最终特征仍保留了足够的信息。不幸的是,这对于小物体来说是致命的,因为探测头很难对高度结构化的表示做出准确的预测,在这些表示中,小物体的微弱信号几乎被抹去。
- 噪声特征表示。区分特征对于分类和定位任务都至关重要。小物体通常具有低分辨率和低质量外观,因此很难从其扭曲结构中辨别出图像。同时,小物体的区域特征容易受到背景和其他情况的污染,从而进一步为学习的表示引入噪声。总之,小目标的特征表示容易受到噪声的影响,阻碍后续检测。
- 边界框扰动的低容忍性。定位作为检测的主要任务之一,在大多数检测范式中被视为一个回归问题,其中定位分支被设计为输出边界框偏移或对象大小,并且通常采用并集(IoU)度量来评估精度。然而,定位小对象比定位大对象更困难。如图1所示,与中等和大型对象(56.6%和71.8%)相比,小对象预测框的轻微偏差(沿方向的6个像素)导致IoU显著下降(从100%到32.5%)。同时,更大的差异(比如12像素)进一步加剧了这种情况,对于小对象,IoU下降到8.7%。也就是说,与较大对象相比,较小对象对边界框扰动的容忍度较低,从而加剧了回归分支的学习难度。左上角、左下角和右下角分别表示小对象(20×20像素,agridnotestwo像素)、中对象(40×40像素)和大对象(70×70像素)。A表示GroundTruth(GT)框,B和C表示沿中间方向(分别为6像素和12像素)具有较小设备的预测框。IoU表示Union值上的交集。

图1 A是GT,B、C是预测框
2.3 小目标检测算法回顾
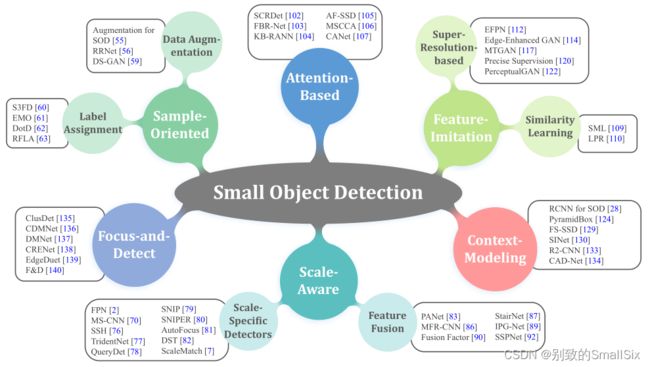
图2 为现有的基于深度学习的小对象检测方法构建了一个框架
- 数据数理方法。(Sample-oriented methods)增加小物体的数量,过采样和自动增强方案。
- 尺度感知方法。(Scale-aware methods)利用多尺度特征以分而治之的方式检测各种尺寸的物体,设计适合多尺度物体有效训练的方案。
- 特征融合方法。(Feature-imitation methods)自顶向下的信息交互和精细特征融合。
- 超分。(Focus-and-detect methods)基于学习的上采样和基于GAN的超分辨率框架。
- 上下文建模方法。(Context-modeling methods)
- 其他。(Attention-based methods)基于注意力的方法和定位驱动优化。
3.小目标检测的数据集
3.1 数据集
表2 可用于小对象检测的一些基准的统计信息。
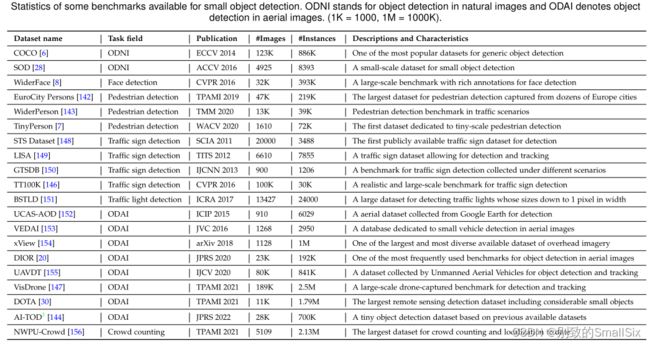
ODNI表示自然图像中的目标检测,ODAI表示航空图像中的目标检测(1K=1000,1M=1000K)。
表3 Area 子集尺寸大小

3.2 评估指标 - 平均精度
4.SODA-D和SODA-A数据集构建
在本节中,我们阐述了构建SODA-D和SODA-A的数据采集和注释过程。此外,我们还阐明了我们基准的特点以及我们的数据集与相关现有数据集之间的主要差异。
表4 每个类别的实例数以及SODA-D(左)和SODA-A(右)的实例数。
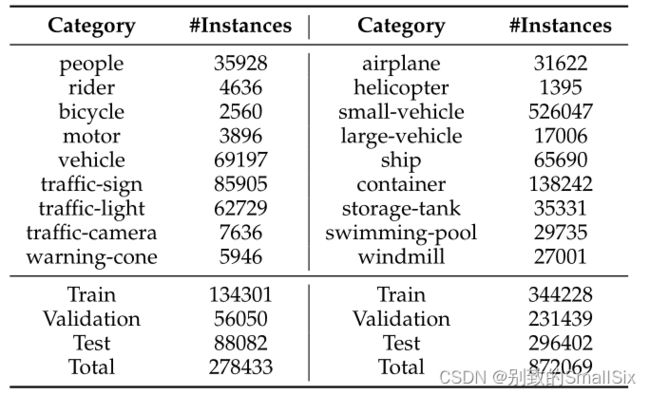
表5 SODA-D和车载场景下的几个相关检测数据集之间的比较(顶部),类似于SODA-A和航空场景下的其他检测数据集(底部)。
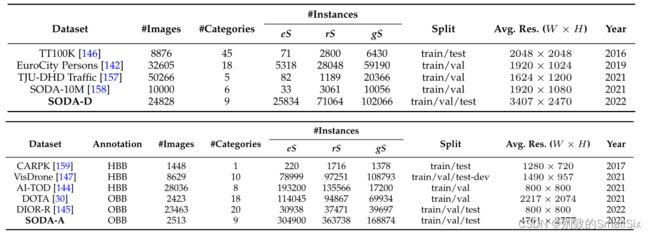

图3 SODA-D(顶部)和SODA-A(底部)中每个类别的示例。
5.实验
按照COCO中的评估标准,我们使用平均精度(AP)来评估检测器的性能。具体地说,作为最高度量,通过在0.5和0.95之间(间隔为0.05)的10个IoU阈值上平均AP获得的超视差。AP50和AP75分别在0.5和0.75的单个IoU阈值下计算。此外,我们报告了细分类的AP,即APT,以突出我们对微小对象的关注,并且还演示了四个区域子集的AP,分别是APeT、APrT、APgTandAPS。
表6 基线是SODA-D测试集的结果。

除YOLOX(CSPNet)[161]和CornerNet(HourglassNet-104)[51]外,所有模型都以ResNet-50[10]为骨干。计划在训练过程中进行测试,其中“1×”表示12个时期,“50”表示50个时期。
表7 SODA-D测试集上基线检测器的类别AP。

培训设置与表6一致。类别缩写区域的全名如下:t-sign(traffic-sign),t-light(traffic-light),t-camera(traffic-camera)andw-cone(warning-cone)。
6.总结和展望
我们对小目标检测进行了系统的研究。具体而言,我们从算法和数据集的角度详尽地回顾了数百篇有关SOD的文献。此外,为了促进SOD的发展,我们在驾驶场景和空中场景下构建了两个大规模基准,称为SODA-D和SODA-A。SODA-D包含277596个带有水平框注释的实例,而SODA-A包含800203个带有定向框的对象。据我们所知,注释良好的数据集是为小对象检测量身定制的大规模基准测试的首次尝试,可以作为对各种SOD方法进行基准测试的平台。在SODA上,我们对几种典型算法进行了全面的评估和比较。基于这些结果,我们讨论了SOD任务未来发展的几个潜在解决方案和方向。
- 有效的骨干(Effective feature extractor for small objects)。正如结果中提到的,深度Backbone网络可能不利于提取小对象的高质量特征表示。设计一个有效的主干网具有强大的特征提取能力,同时避免高计算成本和信息损失,这一点至关重要。
- 有效的分层特征表示(High-quality hierarchical representation)。FPN是小目标检测中不可缺少的一部分。然而,当前的特征金字塔结构对于SOD来说是次优的,因为启发式金字塔层次分配策略,顶层是冗余和未使用的。此外,对低层特征图的检测带来了沉重的计算负担。因此,对为SOD任务量身定制的高效分层特征体系结构的需求很高。
- 优化标签对齐策略(Optimized label assignment strategy)。
- SOD合适的评估指标(ProperevaluationmetricforSOD)。
- 功能强大的单阶段检测器(Powerlful one-stage detector)。两级检测器和一级检测器之间存在明显的性能差距,而后者由于其较高的计算效率而在现实世界中具有重要意义。当涉及到小目标检测时,单阶段方法中常见的不平衡和未对准问题也被放大。因此,一个强大的单阶段SOD范式对于研究和应用都至关重要。
具体实现可以看一下