自然语言处理:XLNet 模型
论文
XLNet: Generalized Autoregressive Pretraining for Language Understanding
开源代码
xlnet
模型介绍
语言模型划分为
- 自回归语言模型(Autoregressive LM),根据上文预测下文,或反过来(例如GPT)
- 自编码语言模型(Autoencoder LM),同时利用上下文,例如bert
bert 模型缺点
- 要引入mask,使得预训练和和fine-tuning阶段不一致(tuning阶段没有mask)
- 若多个单词被mask掉,则无法学习到这部分单词的相互关系
XLNet 模型的改进:
- 相比bert在输入引入mask,XLNet引入双流注意力机制和attention mask,是模型内部的mask(掩码矩阵),这样在输入看起来还是从前往后的预测,即自回归。
如何利用上下文
XLNet 属于自回归语言模型 ,如果想同时利用上下文,XLNet做法是将词语随机排列(permutation),然后选取其中一些排列作为样本,例如一句话:[x1, x2, x3, x4],所有可能的排列方式有:
[('x1', 'x2', 'x3', 'x4'),
('x1', 'x2', 'x4', 'x3'),
('x1', 'x3', 'x2', 'x4'),
('x1', 'x3', 'x4', 'x2'),
('x1', 'x4', 'x2', 'x3'),
('x1', 'x4', 'x3', 'x2'),
('x2', 'x1', 'x3', 'x4'),
('x2', 'x1', 'x4', 'x3'),
('x2', 'x3', 'x1', 'x4'),
('x2', 'x3', 'x4', 'x1'),
('x2', 'x4', 'x1', 'x3'),
('x2', 'x4', 'x3', 'x1'),
('x3', 'x1', 'x2', 'x4'),
('x3', 'x1', 'x4', 'x2'),
('x3', 'x2', 'x1', 'x4'),
('x3', 'x2', 'x4', 'x1'),
('x3', 'x4', 'x1', 'x2'),
('x3', 'x4', 'x2', 'x1'),
('x4', 'x1', 'x2', 'x3'),
('x4', 'x1', 'x3', 'x2'),
('x4', 'x2', 'x1', 'x3'),
('x4', 'x2', 'x3', 'x1'),
('x4', 'x3', 'x1', 'x2'),
('x4', 'x3', 'x2', 'x1')]随机选择几条排列:
('x1', 'x2', 'x4', 'x3'),
('x1', 'x4', 'x3', 'x2'),
('x2', 'x3', 'x4', 'x1'),
('x4', 'x2', 'x3', 'x1'),
('x3', 'x2', 'x4', 'x1'),对于单词t3而言,t1,t2,t4 都可能在它前面出现,这样就同时利用了上下文。
双流注意力机制(Two-Stream Self-Attention)
根据上下文预测某个位置的单词,bert用的是mask,使得预训练和和fine-tuning阶段不一致。XLNet 利用了双流注意力,其中一个是内容流注意力机制(content stream attention),另一个是查询流注意力机制(query stream attention)。前者用于学习每个单词的表示,后者用于预测某个单词的出现,例如对于t3的预测,前者应该包含t3,后者则应该包含t3之前的单词还有t3的位置。正是查询流注意力机制 + Attention mask 取代了bert的mask。
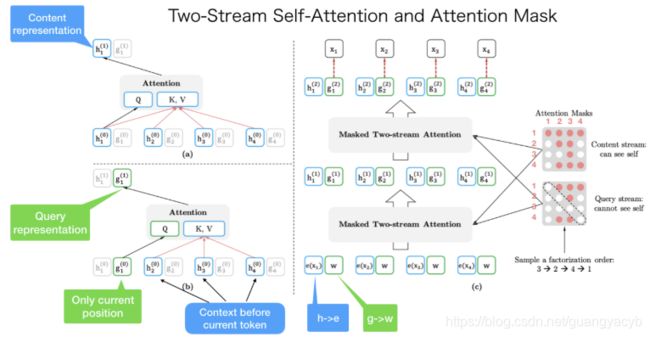
如图所示,左下方学习的是t1的查询表示,因此用到的是t1之前的单词还有t1的位置。左上方学习的是t1的内容表示,所以用到t1自身还有之前的词,这也就是双流注意力机制。双流是因为每个词在训练任务中有两个角色,一个是被预测,一个是用于预测其他词。所以这个学习学的是两个表示,g:只包含位置信息,h:包含了内容信息;
右边是整个网络的结构,其中涉及两个掩码矩阵,上面的content 掩码矩阵包含了对角元素,即词语自身,用于单词内容表示(content representation)的学习;另一个query 掩码矩阵不包含对角元素,用于查询表示(query representation)的学习。经过两层结构,根据最终内容表示的输入作为单词的预测。
相关阅读
XLNet:运行机制及和Bert的异同比较 具体说明了XLNet 相对bert 改进的地方,还有其他优化的点,也有一些思考,推荐阅读
需要看的两篇文章,解释的也浅显易懂
What is XLNet and why it outperforms BERT
What is Two-Stream Self-Attention in XLNet
XLNet原理 李理的博客 应该算比较详细了