XLNet学习:究极总结
XLNet:
XLNet方法介绍:
编码器-解码器的一体化
Objective: Permutation Language Modeling
Incorporating Ideas from Transformer-X
Discussion and Analysis
Comparison with BERT
Comparison with Language Model
Experiments
Pretraining and Implementation
Ablation Study
Important Design:
Conclusions
XLNet:
XLNet 的核心思想:PermutationLM 使用双向上下文 + Transformer-XL 对架构进行改进。
Bert在预训练阶段的两个问题:
- 自编码语言模型在预训练过程中会使用 MASK 符号,但在下游 NLP 任务中并不会使用,所以导致预训练和finetune不匹配;
- BERT 假设要预测的词之间是相互独立的,即 Mask 之间相互不影响。(独立性假设)
由于意识到BERT 这种自编码模型强大的理解能力,本质上是由于同时考虑了上下文信息,如何优化自回归模型使其也拥有在学习当前词时能结合上下文信息?
XLNet方法介绍:
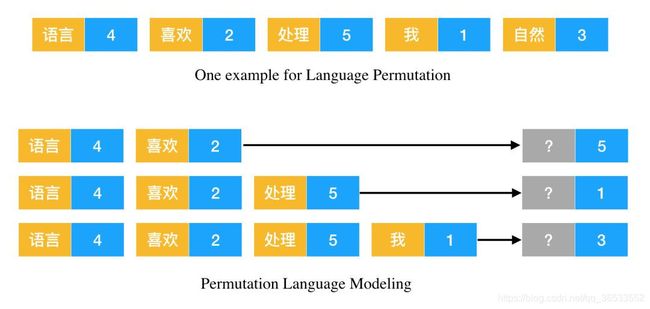
首先,如上图,因为随机排列是带有位置信息的,所以扰乱词顺序并不影响句子的序列建模。如果我们知道所有词的内容及位置,那么是不是顺序的拆解句子就不那么重要了。相反这种随机 分解顺序还会构建双向语义;如上利用[语言]和[喜欢]预测[处理]就利用了上下文的词。
这理解起来其实也非常直观,如果我们知道某些词及词的位置,那么完形填空式地猜某个位置可能出现哪些词也是没问题的。此外,我们可以发现,这种排列语言模型就是传统自回归语言模型的推广,它将自然语言的顺序拆解推广到随机拆解。当然这种随机拆解要保留每个词的原始位置信息,不然就和词袋模型没什么差别了。
如果读者了解一些 Transformer,那么就会知道某个 Token 的内容和位置向量在输入到模型前就已经加在一起了,后续的隐向量同时具有内容和位置的信息。但杨植麟说:「新任务希望在预测下一个词时只能提供位置信息,不能提供内容相关的信息。因此模型希望同时做两件事,首先它希望预测自己到底是哪个字符,其次还要能预测后面的字符是哪个。」
如果模型预测当前词,则只能使用位置向量;如果模型预测后续的词,那么使用位置加内容向量。因此这就像我们既需要标准 Transformer 提供内容向量,又要另一个网络提供对应的位置向量。
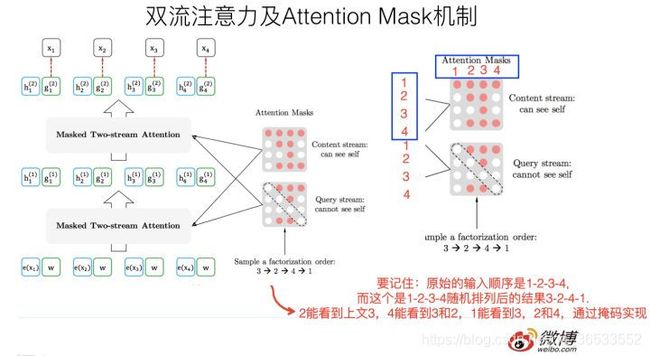
调整Transformer 以适应任务提出了 Two-Stream Self-Attention,它通过构建两条路径解决这个条件句。如上图所示为 Two-Stream 的结构,其中左上角的 a 为 Content 流,左下角的 b 为 Query 流,右边的 c 为排列语言模型的整体建模过程。
在 Content 流中,它和标准的 Transformer 是一样的,第 1 个位置的隐藏向量 h_1 同时编码了内容与位置。在 Query 流中,第 1 个位置的隐向量 g_1 只编码了位置信息,但它同时还需要利用其它 Token 的内容隐向量 h_2、h_3 和 h_4,它们都通过 Content 流计算得出。因此,我们可以直观理解为,Query 流就是为了预测当前词,而 Content 流主要为 Query 流提供其它词的内容向量。
在 finetuning 时可以丢掉 query representation,使用 content representation 作为标准 Transformer。
由于不同排列导致的 Language Modeling 优化问题,这里只选择预测最后一个 token,具体是将 z 分为目标和非目标两部分 (Partial Prediction):
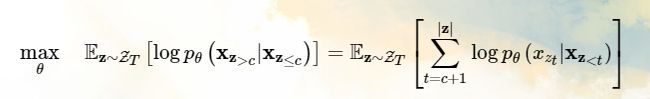
z > c 为 target,超参数 K 表示 1/K 的 tokens 被选中用来预测,|z| / (|z| − c) ≈ K,对于未选中的 tokens,query representation 不需要计算。 K一般可以取6;
上图 c 展示了 XLNet 的完整计算过程,e 和 w 分别是初始化的词向量的 Query 向量。注意排列语言模型的分解顺序是 3、2、4、1,因此 Content 流的 Mask 第一行全都是红色、第二行中间两个是红色,这表明 h_1 需要用所有词信息、h_2 需要用第 2 和 3 个词的信息。此外,Query 流的对角线都是空的,表示它们不能使用自己的内容向量 h。
编码器-解码器的一体化
XLNet 的另一大好处在于它相当于结合了编码器和解码器。因此理论上 XLNet 可以做一些 Seq2Seq 相关的任务,例如机器翻译和问答系统等。
首先对于 Encoder 部分,XLNet 和 BERT 是一样的,它们都在抽取数据特征并用于后续的 NLP 任务。其次对于 Decoder,因为 XLNet 直接做自回归建模,所以它对任何序列都能直接输出一个概率。这种 Decoder 的性质是 BERT 所不具有的,因为 BERT 所输出的概率具有独立性假设,会有很多偏差。
杨植麟说:「如果我们用 XLNet 来做机器翻译,那么一种简单做法即将 Source 和 Target 语言输入到 XLNet。然后将 Target 那边的 Attention Mask 改成自回归的 Attention Mask,将 Source 那一部分的 AttentionMask 改成只能关注 Source 本身。这样我们就能完成 Seq2Seq 的任务。」
Objective: Permutation Language Modeling
通过考虑给定序列所有可能的顺序(序列长度的阶乘种可能)来达到使用双向的上下文信息的目的,其直觉是:如果模型的参数在所有的顺序中共享,模型自然而然能够学习从所有位置(当然包括双向上下文)收集信息。
需要说明的是,这里并不会调整序列的顺序,而是使用对应于原始位置的位置编码,并依赖 Transformer 中适当的 Attention Mask。
Incorporating Ideas from Transformer-X
Transformer-XL 的两个重要技术被融合:
- relative positional encoding scheme(相对位置编码)
- segment recurrence mechanism(片段循环机制)
relative positional encoding scheme(相对位置编码)
bert的position embedding采用的是绝对位置编码,但是绝对位置编码在transformer-xl中有一个致命的问题,因为没法区分到底是哪一个片段里的,这就导致了一些位置信息的损失,这里被替换为了transformer-xl中的相对位置编码。假设给定一对位置i ii与j jj,如果i 和j 是同一个片段里的那么我们令这个片段编码 S(i,j) = S+; 如果不在一个片段里则令这个片段编码为S(i,j) = S; 这个值是在训练的过程中得到的,也是用来计算attention weight时候用到的,在传统的transformer中attention weight softmax((Q⋅K/d)V); 在引入相对位置编码后,首先要计算出 aij=((qi+b)^T) *sj, 其中b 也是一个需要训练得到的偏执量,最后把得到的aij 与传统的transformer的weight相加从而得到最终的attention weight。
segment recurrence mechanism(片段循环机制)
transformer-xl的提出主要是为了解决超长序列的依赖问题,对于普通的transformer由于有一个最长序列的超参数控制长度进行截断处理,对于特别长的序列就会导致丢失一些信息,transformer-xl就能解决这个问题。我们看个例子,假设我们有一个长度为1000的序列,如果我们设置transformer的最大序列长度是100,那么这个1000长度的序列需要计算十次,并且每一次的计算都没法考虑到每一个段之间的关系,如果采用transformer-xl,首先取第一个段进行计算,然后把得到的结果的隐藏层的值进行缓存,第二个段计算的过程中,把缓存的值拼接起来再进行计算。该机制不但能保留长依赖关系还能加快训练,因为每一个前置片段都保留了下来,不需要再重新计算,在transformer-xl的论文中,经过试验其速度比transformer快了1800倍。
接下来讨论第二个如何能够让模型从先前的分割中复用 hidden states。假设有一个长序列的两个分割:x˜ = s_{1:T} 和 x = s_{T+1:2T},z˜ 和 z 分别是对应的两个排列,然后基于排列 z˜,我们处理第一个分割,然后将每个 layer m 的 content representation h˜(m) 存起来。那么对于分割 x:
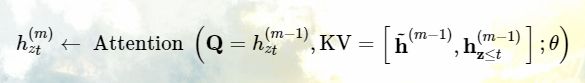
h~(m−1) 表示缓存值;
因为位置编码只依赖原始序列的实际位置,所以此 Attention 的更新在获得 h˜(m) 后与 z˜ 独立,这允许在不知道上一个分割的序列顺序的情况下重复使用 memory。query stream 也可以用同样的方法。
使用 Relative Segment Encodings,只关注两个位置是否来自同一个分割,这与相对编码的核心思想一致(只关注位置之间的关系),有两个好处:
- 改善了泛化
- 提供了两个以上分割 finetuning 的可能性
Discussion and Analysis
Comparison with BERT
都使用了 partial prediction,降低优化难度。例子:[New, York, is, a, city],假设 BERT 和 XLNet 都选择了 [New, York] 作为预测目标,最大化 log p(New York | is a city),假设 XLNet 采样的顺序是 [is, a, city, New, York]:
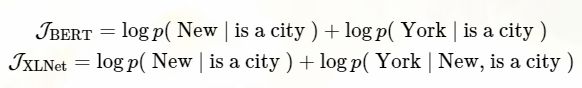
更加形式化的,给定序列:X = [x1, · · · , xT ],给定一组目标 tokens T 和非目标 tokens N=X\T,两个模型都需要最大化 log p(T | N):
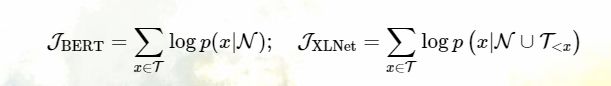
T
- 如果 U ⊆ N,(x, U) 能够被两个模型 cover
- 如果 U ⊆ N ∪ T
Comparison with Language Model
AR LM 顺序只能从前到后,XLNet 可以 cover 所有顺序,更正式的,考虑一个上下文-目标对 (x, U):
-
如果 U ∩ T
- XLNet 可以 cover
Experiments
Pretraining and Implementation
2.78B, 1.09B, 4.75B, 4.30B, and 19.97B subword pieces for Wikipedia, BooksCorpus, Giga5, ClueWeb, and Common Crawl, 共 32.89B
Sequence 和 Memory 的长度分别为 512 和 384
500k steps,Adam optimizer, linear learning rate decay, batch size of 2048
bidirectional data input pipeline, partial prediction constant K as 6
span-based prediction when finetuning
RACE Dataset
从中国中学生英文考试中选出的约 100k 个问题的数据集,答案由人工专家给出。
SQuAD Dataset
包含两个任务的大规模阅读理解数据集,SQuAD1.1 的问题在原文中有答案,SQuAD2.0 包括了不可回答的问题。
Text Classification
benchmarks: IMDB, Yelp-2, Yelp-5, DBpedia, AG, Amazon-2, and Amazon-5
GLUE Dataset
包含 9 个自然语言理解的任务:MNLI, QNLI, QQP, RTE, SST-2, MRPC, CoLA, STS-B, WNLI
ClueWeb09-B Dataset
用来评估文档排序。
Ablation Study
Important Design:
- memory caching mechanism
- span-based prediction
- bidirectional input pipeline
Conclusions
XLNet 使用了 permutation 语言模型来联合 AR 和 AE 模型的优点,融合了 Transformer-XL 的思想,提出了 two-stream attention mechanism(核心),并在几乎所有任务中达到了 sota 的结果。
Note:
与Bert的预训练过程异同问题:
Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词;而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单词在预测某个单词的时候不发生作用。所以,本质上两者并没什么太大的不同,只是Mask的位置,Bert更表面化一些,XLNet则把这个过程隐藏在了Transformer内部而已
BERT:
Bert目前的做法是,给定输入句子X,随机Mask掉15%的单词,然后要求利用剩下的85%的单词去预测任意一个被Mask掉的单词,被Mask掉的单词在这个过程中相互之间没有发挥作用。
XLNet在实现的时候,为了提升效率,其实也是选择每个句子最后末尾的1/K单词被预测,假设K=6,意味着一个句子X,只有末尾的1/7的单词会被预测,这意味着什么呢?意味着至少保留了6/7的Context单词去预测某个单词,对于最末尾的单词,意味着保留了所有的句子中X的其它单词,这其实和上面提到的Bert只保留一个被Mask单词是一样的
XLNet维持了表面看上去的自回归语言模型的自左向右的模式,对于生成任务还是有比较好的效果;
另外XLNet还引入了transformer_XL机制,对于长文档输入类型 的NLP任务比BERT更有优势;
另外采样操作是没办法的事情,因为排序后排列组合会极大增加训练数据,否则数据量太大;
哪些因素在起作用?
XLNet起作用的三个因素:
-
与BERT采用自编码的预训练不同,Permutation Language Model(PLM),可以理解是在自回归模型下,采取具体手段,融入了双向语言模型;PLM打开了新思路
- 引入了transformer_XL机制,相对位置编码和分段RNN机制;对于长文档学习很有帮助
- 加大了预训练阶段使用的数据规模;
对NLP应用任务的影响
XLNet本质上是ELMO/GPT/BERT这一系列的两阶段模型的进一步延申。和BERT相比,
-
对于bert长文档的应用,因为Transformer天然对长文档任务处理有弱点,所以XLNet对于长文档任务有比较明显的提升作用;
- 对于生成类NLP任务,BERT不是很好处理,XLNet则相对BERT能更好应付;
参考:
XLNet 论文笔记
(20 封私信 / 80 条消息) 如何评价在20个任务上超越BERT的XLNet?
https://zhuanlan.zhihu.com/p/70257427
他们创造了横扫NLP的XLNet:专访CMU博士杨植麟
https://blog.csdn.net/u012526436/article/details/93196139?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162069814816780261986113%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162069814816780261986113&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-2-93196139.first_rank_v2_pc_rank_v29&utm_term=XLNet