深度分析c+引用的本质以及引用与指针的区别
文章目录
- 引用的概念
- 引用的定义
- 引用的特性
- 引用的权限问题
- 引用的使用方式
- 引用作参数
- 引用作返回值
- 指针的本质
- 引用和指针的区别
引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。简单理解为:在语法层面上,引用就是给变量重新取一个名字
引用的定义
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟另外的内存空间进行存储,它与引用的变量共用的是同一块内存空间的地址。
格式如下:
类型& 引用变量名(对象名) = 引用实体;
而此处的&不是取地址操作符,而是起标志作用,标志所定义的标识符是个引用.
int main() {
int a = 1;
int& b = a; //此处就是引用的定义
return 0;
}
此处就相当于变量a,b共用同一块内存地址空间
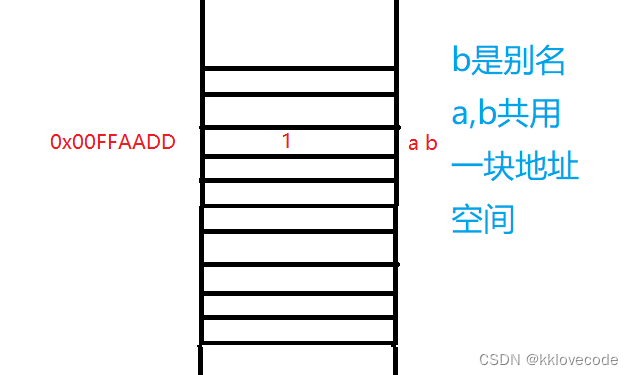
引用的特性
- 引用在定义时必须初始化
- 不能有空引用
- 一个变量可以有多个引用(相当于有多个别名)
- 引用一旦引用一个实体,不能引用其他实体
- 没有多级引用,再不能引用其他实体
如图

引用的权限问题
先看图代码

为什么图中不加const会发生报错呢???这就不得不提到引用的权限问题
接下来我们来分析一下
int main()
{
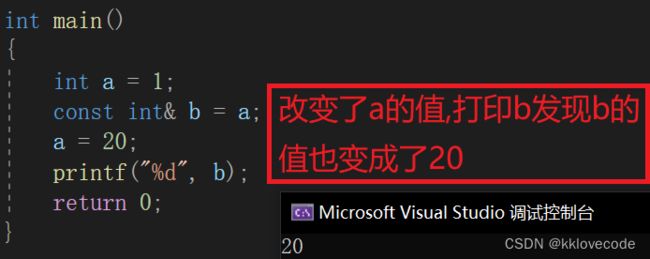
const int a = 1;//变量a被const修饰,a的值不能改,权限是只读
int&d = a;//d是a的别名,但d的改变会改变a,也就变成了可读可写,扩大了权限
const int& d = a;//d被const修饰,所以d也只可读,权限与a相同,不存在扩大权限
return 0;
}
所以之所以不加const会报错,就是因为权限被放大了
再看这个代码

这个代码能够顺利通过,为什么?
int main()
{
int a = 1;//权限是可读可写
const int& b = a;//b被const修饰,权限为可读,但不可写
return 0;
}
通过这段代码我们可以得出,权限是可以被缩小的
注意:这段代码如果你想修改a的值,可以通过a来进行修改,但不能通过b,并且修改了之后,b的值仍然会跟随着a进行改变
如图:
接下来我们再看看一个特殊的例子

如果没有const这一行代码,可能大家会认为是a的类型(int)和b的类型(double)不匹配而导致的错误,但事实并非如此.当你加了const之后,便不会有报错,这是为什么呢?
这其中就要提到C语言中的类型转换(包括隐式类型转换和显式类型转换)
如下面这个例子

又比如:

总结:类型转换的时候都会产生一个临时变量,而这个临时变量是会被const修饰的,具有常性
所以现在我们知道了,上图那个例子报错就是因为权限被放大了,所以我们应该加上const
最后需要补充的是:权限问题只针对于引用和指针
引用的使用方式
1.引用普通变量(最常见的)
int main()
{
int a = 10; //a是一个普通整型变量
int & b = a;
return 0;
}
2.常引用
int main()
{
const int a = 1;
const int& c = a;//保持权限相等
const int& z =10;//常数只可读,所以要用const限制成只读
return 0;
}
3.指针引用
int main()
{
int a = 100;
int* p = &a;
int*& k = p;//这是个指针引用,k就是个指针p的别名
return 0;
}
引用作参数
在使用带参函数的时候,由于一般函数的参数是实参的拷贝,但有些函数的操作可能是要对原变量进行改变的,C语言常用的做法是指针来传递原变量地址,这样的好处是如果需要将改变传回或者改变原变量则不需要返回值,可以通过传入指针直接改变。而C++提供了引用的新特性,可以使用引用传参
比如对于交换两数:
void swap(int *a, int *b) //c语言的老方法
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void swap(int &a, int &b) //c++新引入的特性-引用
{
int tmp = a;
a = b;
b = tmp;
}
其实在c++中分两种情况看待
①如果变量是内置类型,如char,int等,那么推荐值传递
因为编译器将直接使用寄存器进行操作,显然这是最快的,如果要用指针和引用,那么会多一次放存操作
②如果变量是对象,那么使用引用将是首选,并且参数里面的引用最好加上const
当需要传递的值很大,寄存器不够用时,那么使用指针或者引用,将只需要传递变量的地址就可以了
引用作返回值
说到传引用返回又不得不提到传值返回,那接下来我们对两者进行分析
1.对于传值返回,一般返回值都会建立一个临时变量,产生一个拷贝副本,而大多数情况下这个临时拷贝也是通过寄存器返回.

2.而传引用返回,不会产生值的副本,而是将其返回值直接传递给这个return后面的值(原因是因为本身是传引用返回,传的变量的别名,可以想成这个函数的最终效果就是一个变量),所以传引用返回可以直接当左值使用
//函数fun
int& fun()
{
//...
}
//main函数
int main()
{
fun()++; //当左值使用,直接进行++
return 0;
}
指针的本质
在开始讲引用的概念时,我们强调了,在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间.但其实语法概念只是帮助我们更加方便的使用引用.
在底层实现上实际是有空间的,引用的内部实现机制其实就是指针
通过下图底层汇编代码的角度也能够看到,指针和引用在底层汇编角度一模一样

指针和引用其实是一样的,但我们还能单独使用引用,原因就是编译器帮我们做了很多工作
就以上面代码为例:
int & ra = a;,编译器会自动转化成 int * const ra= a;(注意这是指针常数,这也解释了引用特性中的第4条为什么不能更改)
a = 20;,编译器会自动转化成 *a = 20;
下面这段引用的代码我们用底层指针进行分析
void func(int& ref)
//编译器发现参数为引用,便会转化成int* const ref = &a
{
ref = 100; //ref为引用,编译器转化为*ref = 100
}
int main()
{
int a = 10;
int& ref = a;
ref = 20;//内部发现ref是引用,故编译器转为*ref = 20
func(a);
return 0;
}
总结:虽然引用的本质是指针但更为准确来说是加了const修饰的指针,也就是指针常量! ! !
引用和指针的区别
所以正是因为引用本质是指针,但又并非普通指针,所以引用和指针也就有了一些区别
- 引用语法概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全(只能说是相对安全)