干货 | 携程监控系统Hickwall演进之路
作者简介
大伟,携程软件技术专家,关注企业级监控,日志,可观测性领域。
一、背景
监控领域有三大块,分别是Metrics,Tracing,Logging。这三者作为IT可观测性数据的三剑客,基本可以满足各类监控、告警、分析、问题排查等需求。
Logs:我们对于Logs是更加宽泛的定义,即记录事物变化的载体,包括常见的访问日志、交易日志、内核日志等文本型以及GPS、音视频等泛型数据。日志在调用链场景结构化后其实可以转变为Trace,在进行聚合、降采样操作后会变成Metrics。
Metrics:是聚合后的数值,相对比较离散,一般有name、labels、time、values组成,Metrics数据量一般很小,相对成本更低,查询的速度比较快。
Traces:是最标准的调用日志,除了定义调用的父子关系外(一般通过TraceID、SpanID、ParentSpanID),一般还会定义操作的服务、方法、属性、状态、耗时等详细信息,通过Trace能够代替一部分Logs的功能,通过Trace的聚合也能得到每个服务、方法的Metrics指标。
近年来,可观测性这个概念如火如荼,可以看作是对监控的一次大升级。CNCF也发布了OpenTelemetry标准,旨在提供可观测性领域的标准化方案。那么相比传统的监控告警,监控和可观测性有啥区别和联系呢?个人理解,可观测性能够以更加白盒的方式看透整个复杂的系统,帮助我们更好的观察系统的运行状况,快速定位和解决问题。
简单理解,监控和可观测性的关系。监控告诉我们系统的哪些部分是正常工作的,可观测性告诉我们那里为什么不工作了。监控侧重宏观,可观测性包括微观能力。监控是可观测性的子集。
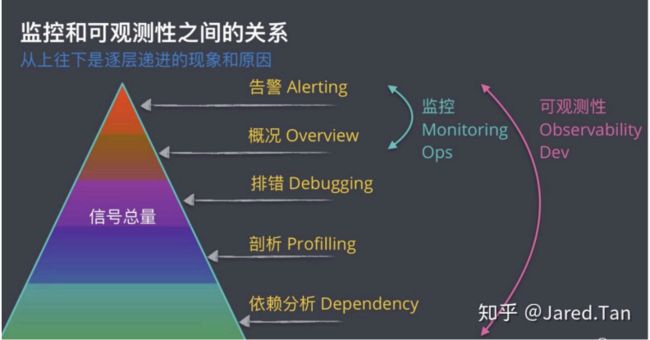
图1
近些年,随着携程集团对线上故障1-5-10目标的提出(即第1分钟发现故障,第5分钟定位故障,第10分钟解决故障),对监控系统提出了更高的要求。监控系统最重要的三个特点可以定义为,系统稳定性,数据及时性,数据精准性,三者缺一不可。
携程监控系统 Hickwall 是一个企业级的指标监控告警系统,兼容了业界的 Prometheus监控标准,覆盖携程所有的指标监控数据,包括系统层和应用层。主要目标是实现指标数据的采集、接入、存储、展现,并在此基础上配置告警和通知,告警治理等,同时为第三方平台提供第一手的监控数据和告警事件。
二、遇到的问题
随着业务不断膨胀,系统规模的持续扩大,Hickwall遇到了一些问题:
高基数查询,指标维度过多,导致整体查询慢,用户体验不佳。
云原生的监控方案缺乏,需要支持开源PromQL业界标准,Prometheus SDK指标接入。
监控粒度粗,一些毛刺无法洞察,需要提高数据采样粒度。
告警系统多,技术方案杂,难维护,产品使用上用户到处找入口,规则和阈值定义不一样,很困惑。
监控数据延迟,导致误告警。
告警多,重复告警,缺乏治理。
容器大规模HPA带来的指标基数膨胀问题。
三、主要的演进
针对上述问题和痛点,Hickwall过去两年进行了一些针对性的优化和演进。
3.1 云原生监控
1)TSDB升级,经过三次演进,现在是基于VictoriaMetrics实现的第四代的TSDB解决方案。完全兼容Prometheus查询语法。
2)提供了自研Beacon容器监控组件,和k8s体系高度集成,不仅支持容器系统指标,JVM指标,也支持自定义的PrometheusSDK埋点接入。
3.2 解决高基数问题
1)产品升级,新增日志/指标预聚合能力,产品开放配置能力,根据一定配置策略,通过将多维原始数据降维,收敛指标维度,聚合输出预聚合数据,通过这种方式可以缩减指标量级,对后续链路的处理都有性能提升。目前系统配置了166条聚合规则,生成了209个指标。
2)指标治理:监控统计指标维度,应用维度的高基数检测,对非法写入进行封禁。非法写入包括了tag的value使用了随机数,字符内容超过256个字符,指标名称使用了中文命名等。
3)容量规划:做好集群的自监控,进行妥善的容量规划,主要是监控ts增长数量和datapoint数据量,以应对日益增长的指标数据。
4)忽略有问题的tag:治理平台能够按需配置ignore tag,例如针对HPA场景下的应用埋点,忽略value容易发生变化的hostname和ip这两种tag(一般不会关心这种维度),可以大大减少基数。
3.3 数据粒度提升
为了响应集团1-5-10目标,核心指标采集上秒级,目前主要涉及的是核心的系统指标,业务订单指标和部分应用指标,其他非关键可以按需自行配置。
3.4 告警中台接入
自研新一代统一的pull告警系统,统一各类老的告警技术方案,目前接入告警规则10万+,同时对接了告警中心,对用户提供一站式的告警治理能力。
3.5 解决数据延迟问题
数据延迟问题主要是数据链路还依赖了消费Kafka来写入TSDB。因此我们将核心链路改造成最短路径,从数据网关分发数据直接写到TSDB,从根本上解决了延迟问题。
3.6 时序存储的演进
Hickwall存储这块主要经历了下面四个阶段。
第一阶段:ES存储,Graphite查询语法
第一个版本的架构主要以数据写Kafka,消费Kafka进ES的套路来设计。这个方案的好处:
可以容忍比较大的系统downtime
数据可以多次多种方式加以利用
ES存储的写入性能最大化
ES的聚合能力比较强,所以不少聚合都可以实时来做
ES非常稳定可靠,运维工作较少
第一个版本已经初步实现了监控系统的功能,但是在使用过程中同样暴露了一些问题:
1)ES存储导致数据容易堆积
ES是一个非常稳定的全文索引工具,比较适合日志,搜索的场景。但是却不是最好的监控数据的存储方式,主要是写入性能不是很好,必须大批量,高等待的方式写才能达到比较大的量,但是这个比较大的量相对监控数据的场景也略显不够。
而且为了提高写的性能,还需要牺牲数据的实时性(提高refresh time来减少磁盘操作,提高写入量)。实时性又是一个高质量的监控系统所需要努力提高的。这就是一个矛盾点,虽然当时能够做到勉强接受,但肯定不是最理想的,当时的数据latency需要30s以上。
2)数据链路过长
监控数据主要是从Proxy进来到Trigger告警需要依次经过6个组件,任何一个组件出现问题,都可能导致告警漏告或误告。
第二阶段:基于InfluxDB存储,打造自研的Incluster集群方案,Graphite查询语法
ES用于时间序列存储存在不少问题,例如磁盘空间使用大,磁盘IO使用多,索引维护复杂,写入和查询速度慢等。当时InfluxDB是排名第一的时序数据库,到2017年的时候已经比较稳定,所以我们萌生了用InfluxDB替换ES作为存储的方案。但是InfluxDB并没有开源的集群方案,因此我们自研了Incluster集群方案。
在元数据管理这块使用了Raft来保证一致性和分区容错性。集群大致的实现思路是,客户端通过Incluster节点写入数据,Incluster按照数据分布策略将写入请求转发到相关的InfluxDB节点上,查询的时候按照数据分布策略进行数据读取和合并。在用户查询方面,实现了类Graphite语法用于配图,兼容上一代语法,从而可以减少用户迁移配图的成本。
第三阶段:ClickHouse列式存储,SQL查询语法
2019年,我们逐步开始推进应用埋点存储的统一接入。在这个阶段,InfluxDB在高基数场景下,查询表现并不是很好,集群稳定性也受到了较大的挑战。因此我们调研了当时大火的ClickHouse,开始接入应用埋点,并且提供SQL语法查询。携程的机票部门率先接入,在自定义应用埋点场景取得了比较好的效果。
第四阶段:基于开源的VictoriaMetrics TSDB,PromQL查询语法
2020年,随着云原生技术的发展,内部对云监控的需求越来越强烈。因此我们在2020年调研并测试了业界开源的VictoriaMetrics TSDB,这款TSDB作为Prometheus的远端持久存储解决方案,提供了相较于传统TSDB较好的性能和天然兼容Prometheus协议的查询语法和接口。
这款TSDB经过测试在综合写入性能和查询方面表现较好。目前我们内部主要分了三个大集群,集群规模已经达百余台物理机,成为携程统一的Metrics存储方案。
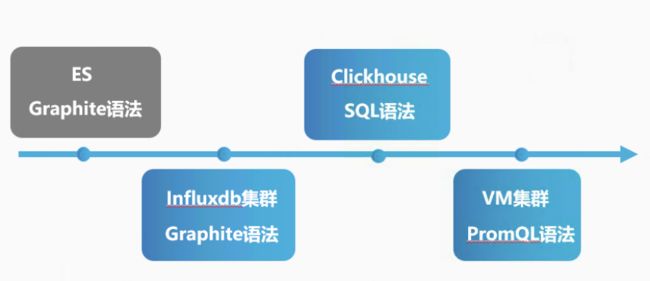
图2
3.7 监控可视化的演进
由于内部使用的可视化工具是基于Grafana二次开发,伴随着存储技术的升级,2020年我们还进行了一次Grafana2版本到6版本的全面升级,新版本增加了多种新的数据源,所见即所得的告警能力,更多的图表类型展现,可视化方面大大提升了用户体验。

图3
四、平台现状
随着多年的发展,目前平台指标数据量写入量峰值在千万级/秒,查询量数千qps,接入各类告警规则10万+,查询P99控制在1s内。数据粒度最小支持到10s级,时序数据默认保存一年。计算+存储集群规模达百余台物理机,并且主要组件都上了k8s平台。数据统计如图4所示。


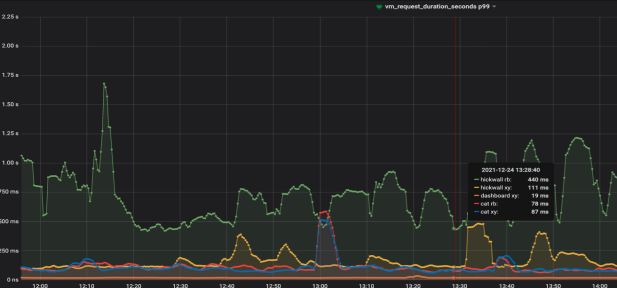
图4
五、目前架构
从数据流向看,目前总体大致架构如图5所示,可见数据流和告警是走的最短路径。
1)数据:data->Proxy->TSDB
2)告警:data->Proxy->Trigger
这从根本上规避数据延迟和告警延迟问题。下面会主要介绍Hickwall所依赖的几个核心组件。
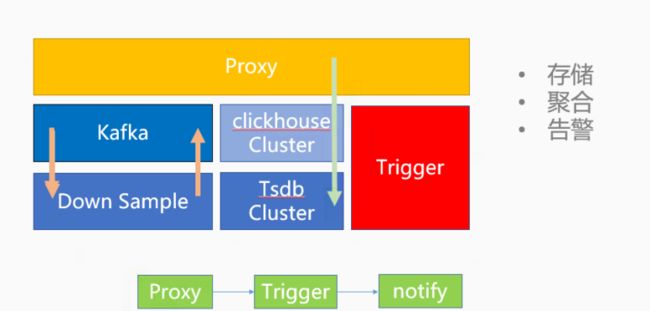
图5
Collector组件:
数据采集,提供多种客户端,包括了Hickwall SDK(应用埋点),Hickwall agent(机器数据采集),Prometheus SDK,Beacon(容器数据采集)。
Proxy组件:
提供给Hickwall SDK,Hickwall agent,Prometheus SDK的统一支持多协议的数据收集服务,主要是thrift protocol和line protocol。作为数据接收的统一入口,承担了流量接入,分发,流量保护,数据统计等功能。Proxy默认为每个应用ID提供了固定的流量配额,具备了基于指标,应用ID的限流能力,目前是基于固定时间窗口进行数据量流控。
告警组件:
提供了Trigger流式告警和基于Bosun的统一pull告警。通过推拉结合的告警引擎解决了大规模阈值告警和复杂同环比告警场景。
DownSample组件:
数据降采样,支持可以配置的聚合采样粒度,节省存储成本。同时提供数据保存更长的时间。
Piper组件:
统一的告警通知服务,支持告警通知升级。
Transfer组件:
负责监控数据分发给第三方系统,供数据分析,容量规则,AI智能告警等用途。
Grafana看板服务:
所见即所得的查询,提供丰富的图表展现以及监控大盘。
TSDB Cluster:
是最核心的时序存储集群,时序类的查询一般QPS都比较高(主要有很多告警规则),通常都是range查询,每次查询某一个单一的指标/时间线,或者一组时间线进行聚合。所以对于这类数据都会有专门的时序引擎来支撑,目前主流的时序引擎基本上都是用类似于LSM Tree的思想来实现,以适应高吞吐的写入和查询。
ClickHouse Cluster:
ClickHouse作为优秀的OLAP列式数据库,早期是我们采用的第三代时序存储引擎,现在慢慢退居二线,目前现在用来导入一些时序数据和高基数指标数据,提供一些额外的数据分析能力。
Hickwall Portal:
一站式的监控日志告警治理平台,目前提供了指标接入,指标查询,告警配置,通知配置,日志接入,日志管理,机器agent治理等模块。
从存储集群来看,TSDB Cluster的架构如下:
1)总体架构分为三层结构,vminsert写入层,vmstorage存储层,vmselect查询层。这三个组件都可以单独进行扩展,并运行在大多数合适软件上。
2)写入层无状态,支持多协议的写入,写入层支持多协议,包括InfluxDB,OpenTSDB,Prometheus,Graphite等。接受程序写入的数据,通过对metric+tag组合进行一致性hash写入到对应的存储节点,当有存储节点失联,会进行数据重路由分发到好的节点上面。重路由的过程中,由于数据分发策略的变化,可能会导致写入变慢,等待存储节点倒排索引重建完成,就会恢复写入速度正常。
3)存储层有状态,采用shared nothing的结构,每个节点数据不共享,独立存储,增加了集群的可用性,简化集群的运维和集群的扩展。支持多租户,采用了ZSTD压缩,列式存储,支持副本配置。
存储层的基本原理可以理解为存储了原始的数据,并且会依据查询层发来的time range和label filter进行数据查找并且返回。在存储层,针对时序数据做了很多存储优化。存储层要求配置一个数据保存的时间,俗称Retention Period。Retention Period到期后,会进行倒排索引的清理和重建,cpu和io通常会大幅提升,会影响写入效率。
从压缩来看,压缩能够很好节省内存和磁盘空间,时序数据的压缩特征比较明显,TSDB Cluster采用先做时序压缩,再做通用压缩的方法。比如,先做delta-of-delta计算或者异或计算,然后根据情况做zig-zag,最后再根据情况做一次ZSTD压缩。据测试统计,在生产环境中,每个数据点(8字节时间戳 + 8字节value共计16字节)压缩后小于1个字节,最高可达 0.4字节,能提供比Gorilla算法更好的压缩率。
4)查询层无状态,支持PromQL查询。
基本原理可以理解为进行查询语法解析,从存储层获取时序数据并且返回标准的格式,查询层往往会进行一些查询QPS,查询耗时的限制,以保证后端服务不被拖垮。
TSDB的部署架构图如下:

图6
六、未来规划
随着可观测性技术的不断发展,仅仅局限于Metrics监控是不行的,我们对未来的展望如下。
1)指标分级
指标管理没有优先级,希望提供分级管理的模式。
2)云原生可观测性的探索
eBPF指标采集的引入,提升主机端的可观测性能力。
3)Logging,Metrics,Tracing的结合。
多套方案交织:可能要使用至少Metrics、Logging、Tracing3种方案,维护代价巨大。在这种多套方案组合的场景下,问题排查需要和多套系统打交道,若这些系统归属不同的团队,还需要和多个团队进行交互才能解决问题,整体的维护和使用代价非常巨大。因此我们希望能够使用一套系统去解决所有类型可观测性数据的采集、存储、分析的功能。
4)兼容业界主流协议,OpenTelemetry的标准。
OpenTelemetry旨在提供统一的可观测性数据收集,未来服务端可以提供兼容OpenTelemetry协议的接入,拥抱开源社区,我们在保持关注中。
5)agent边缘计算,前置数据聚合。
现在是服务端基于Flink做预聚合,希望可以在agent端提供一些预聚合能力,比如采集日志的agent能够聚合Metrics输出。
团队招聘信息
我们是携程技术保障中心系统研发团队,主要负责携程私有云,混合云和PaaS平台的建设,管理数以万计服务器规模的集群,负责数万台计算/存储混合部署和在线/离线混合部署,支持海量数据的稳定存储。
团队积极拥抱开源和创新的软硬件架构,在这里你除了可以学习到业界最流行最先进的技术,还能接触到最新最酷的硬件产品,我们长期招聘有志于从事基础设施方向并愿意深耕的同学,目前容器/存储/大数据等方向都有均有开放职位。
简历投递邮箱:[email protected],邮件标题:【姓名】-【系统研发】-【投递职位方向】。
【推荐阅读】
高效线上问题排查——套路化和工具化
携程持久化KV存储实践
携程数据库发布系统演进之路
数万实例数百TB数据量,携程Redis治理演进之路

“携程技术”公众号
分享,交流,成长