三、Flink使用累加器在WordCount中统计单词数量
目录
累加器使用概述
代码案例
1、概述
1)累加器使用概述
1.概述
累加器是具有加法运算和最终累加结果的一种简单结构,可在作业结束后使用。
最简单的累加器就是计数器: 你可以使用 Accumulator.add(V value) 方法将其递增。在作业结束时,Flink 会汇总(合并)所有部分的结果并将其发送给客户端。 适用于调试过程或在你想快速了解有关数据更多信息时。
Flink 目前有如下内置累加器。
IntCounter、 LongCounter、DoubleCounter
Histogram:直方图。在内部,它只是整形到整形的映射。你可以使用它来计算值的分布,例如,word_count的每行单词的分布情况。
2.使用累加器
a) 创建一个累加器对象(此处是计数器)
private IntCounter numLines = new IntCounter();
b) 在 rich function 的 open() 方法中注册累加器对象。也可以在此处定义名称。
getRuntimeContext().addAccumulator("num-lines", this.numLines);
c) 在操作 function 中的任何位置(包括 open() 和 close() 方法中)使用累加器
this.numLines.add(1);
d) 最终整体结果会存储在由执行环境的 execute() 方法返回的 JobExecutionResult 对象中(当前只有等待作业完成后执行才起作用)
myJobExecutionResult.getAccumulatorResult("num-lines")
e) 在 rich function 中获得单个并行的累加器结果
getRuntimeContext().getAccumulator("num-lines")
3.注意
单个作业的所有累加器共享一个命名空间。因此你可以在不同的操作 function 里面使用同一个累加器。Flink 会在内部将所有具有相同名称的累加器合并起来。
当前累加器的结果只有在整个作业结束后才可用。可以配合使用 聚合器 来计算每次迭代的统计信息,并基于此类统计信息来终止迭代。
2)版本说明

2、代码实现
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
/**
* 使用 累加器计算 word_count 出现的单词数
*/
public class CustomAccumulator {
public static void main(String[] args) throws Exception {
// 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从端口接入数据
DataStreamSource<String> line = env.socketTextStream("localhost", 8888);
line.keyBy(e -> e.split(",")[0])
.process(
new KeyedProcessFunction<String, String, Tuple2<String, Integer>>() {
private ValueState<Integer> valueState;
// 创建一个累加器对象
private IntCounter wordCount = new IntCounter();
@Override
public void open(Configuration parameters) throws Exception {
// 使用 ValueState
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("count_state", Integer.class);
// Managed Keyed State 方式 所有类型的状态均可以使用
stateDescriptor.setQueryable("query_count");
valueState = getRuntimeContext().getState(stateDescriptor);
// 注册累加器对象
getRuntimeContext().addAccumulator("word_count", wordCount);
}
@Override
public void processElement(String line, KeyedProcessFunction<String, String, Tuple2<String, Integer>>.Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] fields = line.split(",");
String name = fields[0];
Integer count = Integer.valueOf(fields[1]);
//每处理一个元素,累加器+1
wordCount.add(1);
//统计相同单词的值的和
Integer oldResult = valueState.value();
if (oldResult == null) {
oldResult = 0;
}
count = oldResult + count;
valueState.update(count);
// 通过运行时上下文获取累加器结果
System.out.println("累加器结果-每个单词出现的数量:"+getRuntimeContext().getAccumulator("word_count"));
out.collect(new Tuple2<>(name, count));
}
}
).print();
JobExecutionResult result = env.execute();
Integer num = result.getAccumulatorResult("word_count");
// 通过 JobExecutionResult 获取累加器执行结果
System.out.println("累加器结果-出现的单词数量:" + num);
}
}
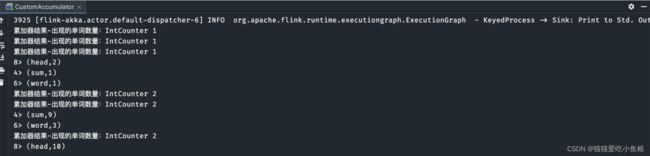
3、执行结果
1)输入测试数据
nc -lk 8888
word,1
word,2
sum,1
sum,8
head,2
head,8
2)word_count 执行结果 和 每个单词出现的个数
3)程序结束时,在返回的 JobExecutionResult 中获取,总计出现的单词个数
