代码随想录算法训练营第六天|哈希表part01|242.349.202.1
2023/7/31 任务
哈希表理论基础 ,242.有效的字母异位词,349. 两个数组的交集,202. 快乐数,1. 两数之和
哈希表理论基础
哈希表/散列表(Hash table)
一般哈希表都是用来快速判断一个元素是否出现在集合里

哈希函数(Hash Function)
把学生的姓名直接映射为哈希表上的索引,然后就可以通过查询索引下标快速知道这位同学是否在这所学校里了。
通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。

当hashCode得到的数值大于 哈希表的大小(tableSize)时,为了保证映射出来的索引数值都落在哈希表上,我们会在再次对数值做一个取模的操作,就要我们就保证了学生姓名一定可以映射到哈希表上了。
如果学生的数量大于哈希表的大小,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表同一个索引下标的位置,由哈希碰撞解决。
哈希碰撞
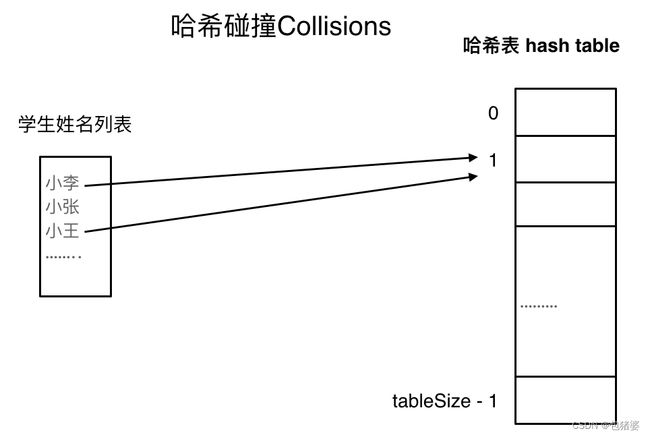
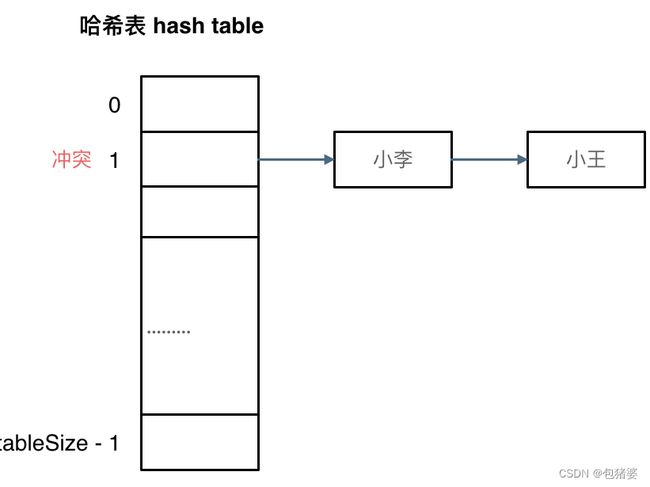
- 拉链法
小李和小王在索引1的位置发生了冲突,发生冲突的元素都被存储在链表中。 这样我们就可以通过索引找到小李和小王了
(数据规模是dataSize, 哈希表的大小为tableSize)
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
- 线性探测法
使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息。所以要求tableSize一定要大于dataSize ,要不然哈希表上就没有空置的位置来存放冲突的数据了。

三种哈希结构
- 数组
- set (集合)
- map(映射)
总结
哈希法——快速判断一个元素是否出现
牺牲空间换取了时间,因为要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
242.有效的字母异位词
题目链接/文章讲解/视频讲解
思路:
数组其实就是一个简单哈希表,而且这道题中字符串只有小写字符,那么就可以定义一个长为26的数组,来记录字符串s里字符出现的次数。
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0。
遍历字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做 +1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。
然后检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对 t 中出现的字符映射哈希表索引上的数值再做 -1 的操作。
最后数组中如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。如果数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
class Solution {
public boolean isAnagram(String s, String t) {
int[] record = new int[26];
for (int i = 0; i < s.length(); i++) {
int tmp = s.charAt(i) - 'a';
record[tmp]++;
}
for (int i = 0; i < t.length(); i++) {
int tmp = t.charAt(i) - 'a';
record[tmp]--;
}
for (int i : record) {
if (i != 0) {
return false;
}
}
return true;
}
}
时间复杂度为O(n),空间上因为定义的是一个常量大小的辅助数组,所以空间复杂度为O(1)。
349. 两个数组的交集
如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费,可以考虑set。使用数组来做哈希的题目,是因为题目都限制了数值的大小。
题目链接/文章讲解/视频讲解
思路:
题目要求输出结果的元素唯一、可无序,因此选用HashSet。它的底层实现是哈希表,读写效率是最高的,并不需要对数据进行排序,而且还不会让数据重复。
(解法一)set
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
Set<Integer> set = new HashSet<>();
Set<Integer> resSet = new HashSet<>();
for (int i : nums1) {
set.add(i);
}
for (int i : nums2) {
if (set.contains(i)) {
resSet.add(i);
}
}
//方法1:将结果集合转为数组
return resSet.stream().mapToInt(x -> x).toArray();
//方法2:另外申请一个数组存放setRes中的元素,最后返回数组
int[] resInt = new int[resSet.size()];
int j = 0;
for (int i : resSet) {
resInt[j++] = i;
}
return resInt;
}
}
直接使用 set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。因此能够使用数组的情况可能用数组会快。
(解法二)数组
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
Set<Integer> res = new HashSet<>();
int[] record = new int[1001];
for (int i : nums1) {
record[i] = 1;
}
for (int i : nums2) {
if (record[i] == 1) {
res.add(i);
}
}
return res.stream().mapToInt(x -> x).toArray();
}
}
202. 快乐数 ⭐
题目链接/文章讲解/视频讲解
思路:
题目中提到了无限循环,那么也就是说求和的过程中,sum会重复出现。
正如前文所说,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
所以这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
判断sum是否重复出现就可以使用Hashset。
还有一个难点就是求和的过程,需要对取数值各个位上的单数操作熟悉。
class Solution {
public static boolean isHappy(int n) {
Set<Integer> set = new HashSet<>();
while (n != 1) {
set.add(n);
n = getSum(n);
if (set.contains(n)) {
return false;
}
}
return true;
}
public static int getSum(int n) {
int sum = 0;
while (n > 0) {
int tmp = n % 10;
sum += tmp * tmp;
n = n / 10;
}
return sum;
}
}
时间复杂度: O(logn)
空间复杂度: O(logn)
1. 两数之和 ⭐
使用map作为哈希表来解决哈希问题。
题目链接/文章讲解/视频讲解
思路:
首先强调什么时候使用哈希法?
当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
本题需要一个集合来存放我们遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是 是否出现在这个集合。
那么我们就应该想到使用哈希法了。
本题不仅要知道元素有没有遍历过,还要知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
再来看一下使用数组和set来做哈希法的局限。
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value在保存数值所在的下标。
这道题目中并不需要key有序,所以用HashMap。
想清楚四个重点:
为什么会想到用哈希表
哈希表为什么用map
本题map是用来存什么的
map中的key和value用来存什么的
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] res = new int[2];
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int need = target - nums[i];
if (map.containsKey(need)) {
res = new int[]{i, map.get(need)};
break;
}
// 注意不要在循环刚开始就put进去,不然当[3,3]求6的时候,两个下标都是1了。
map.put(nums[i], i);
}
return res;
}
}
时间复杂度: O(n)
空间复杂度: O(n)