LLM大模型训练加速利器FlashAttention详解
FlashAttention论文地址:https://arxiv.org/pdf/2205.14135.pdf
1. 背景介绍
因为Transformer的自注意力机制(self-attention)的计算的时间复杂度和空间复杂度都与序列长度有关,所以在处理长序列的时候会变的更慢,同时内存会增长更多。通常的优化是针对计算复杂度(通过 F L O P s FLOPs FLOPs 数衡量), 优化会权衡模型质量和计算速度。
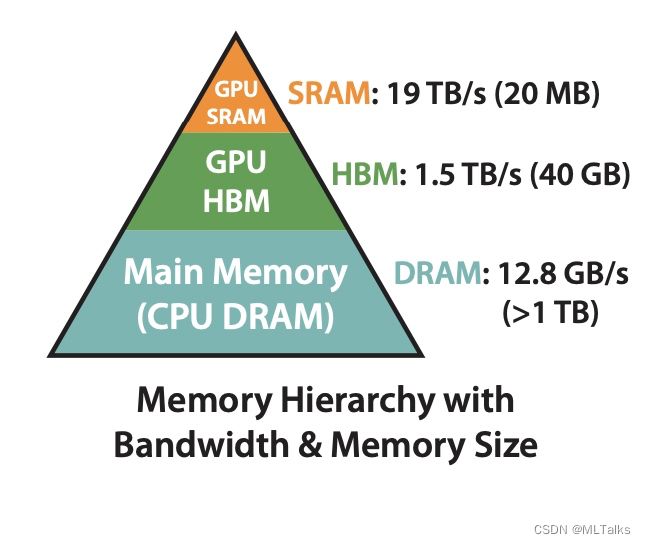
在FlashAttention中考虑到attention算法也是IO敏感的,通过对GPU显存访问的改进来对attention算法的实现进行优化。如下图,在GPU中片上存储SRAM访问速度最快,对应的HBM(high bandwidth memory)访问速度较慢,为了加速要尽量减少HBM的访问次数。
2. 详细解读
2.1 标准的attention算法实现
首先回顾下标准的attention算法实现,有 Q , K , V Q, K, V Q,K,V 三个矩阵,计算有以下三步,都是跟HBM交互:
S = Q K T P = s o f t m a x ( S ) O = P V \begin{gather*} S = QK^T \\ P = softmax(S) \\ O = PV \end{gather*} S=QKTP=softmax(S)O=PV

2.2 FlashAttention算法实现
FlashAttention算法实现的关键在于以下三点:
- softmax的tiling展开,可以支持softmax的拆分并行计算,从而提升计算效率
- 反向过程中的重计算,减少大量的显存占用,节省显存开销。
- 通过CUDA编程实现fusion kernel
2.2.1 softmax展开(tiling)
- 基本softmax。在计算 x i x_i xi 的值的时候需要用到所有的 X = { x 1 , . . . , x N } X=\{x_1, ..., x_N\} X={x1,...,xN} 值,计算公式如下:
X = [ x 1 , . . . , x N ] f ( X ) = [ e x 1 , . . . , e x N ] l ( X ) = ∑ f ( X ) s o f t m a x ( X ) = f ( X ) l ( X ) = s o f t m a x ( x 1 , . . . , x N ) = { e x i ∑ j = 1 N e x j } i = 1 N \begin{gather*} X = \left[ x_1, ..., x_N \right] \\ f(X) = \left[ e^{x_1}, ..., e^{x_N} \right] \\ l(X) = \sum f(X) \\ softmax(X) = \frac{f(X)}{l(X)} = softmax({x_1, ..., x_N}) = \left\{ \frac{e^{x_i}}{\sum^N_{j=1}e^{x_j}} \right\}^N_{i=1} \\ \end{gather*} X=[x1,...,xN]f(X)=[ex1,...,exN]l(X)=∑f(X)softmax(X)=l(X)f(X)=softmax(x1,...,xN)={∑j=1Nexjexi}i=1N
- 安全(safe) softmax。由于 e x i e^{x_i} exi 很容易溢出, 比如FP16支持范围是 2 − 24 ∼ 65504 2^{-24} \sim 65504 2−24∼65504 ,当 x i ≥ 11 x_i \ge 11 xi≥11 的时候, e x i e^{x_i} exi 会超过float16的有效位。为解决这个问题提出
safesoftmax, 对每个 x i x_i xi 都减去一个 m = m a x j = 1 N ( x j ) m = max^N_{j=1}(x_j) m=maxj=1N(xj) , 使得 x i − m ≪ 0 x_i - m \ll 0 xi−m≪0, 这时幂操作符对负数输入的计算是准确且安全的。
m ( X ) = m a x j = 1 N ( x j ) s o f t m a x ( X ) = e x i − m ( X ) ∑ j = 1 N e x j − m ( X ) m ( X ) = m a x j = 1 N ( x j ) \begin{gather*} m(X) = max^N_{j=1}(x_j) softmax(X) = \frac{e^{x_i - m(X)}}{\sum_{j=1}^{N}e^{x_j - m(X)}} m(X) = max^N_{j=1}(x_j) \end{gather*} m(X)=maxj=1N(xj)softmax(X)=∑j=1Nexj−m(X)exi−m(X)m(X)=maxj=1N(xj)
- Safe softmax tiling。对于 X X X 分为两组情况进行说明,其中 X = [ X ( 1 ) , X ( 2 ) ] X=\left[ X^{(1)}, X^{(2)}\right] X=[X(1),X(2)] 。
m ( X ) = m ( [ X ( 1 ) , X ( 2 ) ] ) = m a x ( m ( X ( 1 ) ) , m ( X ( 2 ) ) ) f ( X ) = [ e m ( X ( 1 ) ) − m ( X ) f ( X ( 1 ) ) , e m ( X ( 2 ) ) − m ( X ) f ( X ( 2 ) ) ] l ( X ) = l ( [ X ( 1 ) , X ( 2 ) ] ) = e m ( X ( 1 ) ) − m ( X ) f ( X ( 1 ) ) + e m ( X ( 2 ) ) − m ( X ) f ( X ( 2 ) ) s o f t m a x ( X ) = f ( X ) l ( X ) \begin{gather*} m(X) = m(\left[ X^{(1)}, X^{(2)} \right]) = max(m(X^{(1)}), m(X^{(2)})) \\ f(X) = \left[ e^{m(X^{(1)}) - m(X)} f(X^{(1)}), e^{m(X^{(2)}) - m(X)} f(X^{(2)}) \right] \\ l(X) = l(\left[ X^{(1)}, X^{(2)} \right]) = e^{m(X^{(1)}) - m(X)}f(X^{(1)}) + e^{m(X^{(2)}) - m(X)} f(X^{(2)}) \\ softmax(X) = \frac{f(X)}{l(X)} \\ \end{gather*} m(X)=m([X(1),X(2)])=max(m(X(1)),m(X(2)))f(X)=[em(X(1))−m(X)f(X(1)),em(X(2))−m(X)f(X(2))]l(X)=l([X(1),X(2)])=em(X(1))−m(X)f(X(1))+em(X(2))−m(X)f(X(2))softmax(X)=l(X)f(X)
- safe softmax基本计算示例
X = [ 1 , 2 , 3 , 4 ] m ( X ) = 4 f ( X ) = [ e 1 − 4 , e 2 − 4 , e 3 − 4 , e 4 − 4 ] l ( X ) = ∑ f ( X ) s o f t m a x ( X ) = f ( X ) l ( X ) \begin{gather*} X = \left[ 1, 2, 3, 4 \right]\\ m(X) = 4\\ f(X) = \left[ e^{1-4}, e^{2-4}, e^{3-4}, e^{4-4} \right] \\ l(X) = \sum f(X) \\ softmax(X) = \frac{f(X)}{l(X)} \\ \end{gather*} X=[1,2,3,4]m(X)=4f(X)=[e1−4,e2−4,e3−4,e4−4]l(X)=∑f(X)softmax(X)=l(X)f(X)
- safe softmax tiling计算示例(结果跟基本计算示例一致)
X = [ 1 , 2 , 3 , 4 ] = [ X ( 1 ) , X ( 2 ) ] , m ( X ) = 4 X ( 1 ) = [ 1 , 2 ] , m ( X ( 1 ) ) = 2 X ( 2 ) = [ 3 , 4 ] , m ( X ( 2 ) ) = 4 f ( X ( 1 ) ) = [ e 1 − 2 , e 2 − 2 ] f ( X ( 2 ) ) = [ e 3 − 4 , e 4 − 4 ] f ( X ) = [ e 2 − 4 f ( X ( 1 ) ) , e 4 − 4 f ( X ( 2 ) ) ] = [ e 1 − 4 , e 2 − 4 , e 3 − 4 , e 4 − 4 ] l ( X ) = ∑ f ( X ) s o f t m a x ( X ) = f ( X ) l ( X ) \begin{gather*} X = \left[ 1, 2, 3, 4 \right] = \left[ X^{(1)}, X^{(2)} \right], m(X) = 4 \\ X^{(1)} = \left[ 1, 2 \right], m(X^{(1)}) = 2 \\ X^{(2)} = \left[ 3, 4 \right], m(X^{(2)}) = 4 \\ f(X^{(1)}) = \left[ e^{1-2}, e^{2-2} \right] \\ f(X^{(2)}) = \left[ e^{3-4}, e^{4-4} \right] \\ f(X) = \left[ e^{2-4}f(X^{(1)}), e^{4-4}f(X^{(2)}) \right] = \left[ e^{1-4}, e^{2-4}, e^{3-4}, e^{4-4} \right] \\ l(X) = \sum f(X) \\ softmax(X) = \frac{f(X)}{l(X)} \\ \end{gather*} X=[1,2,3,4]=[X(1),X(2)],m(X)=4X(1)=[1,2],m(X(1))=2X(2)=[3,4],m(X(2))=4f(X(1))=[e1−2,e2−2]f(X(2))=[e3−4,e4−4]f(X)=[e2−4f(X(1)),e4−4f(X(2))]=[e1−4,e2−4,e3−4,e4−4]l(X)=∑f(X)softmax(X)=l(X)f(X)
有了softmax tiling的基础以后,在执行的时候可以对 Q 、 K 、 V Q、K、V Q、K、V 三个矩阵进行分块操作并行计算了。

2.2.2 反向过程中的重计算
类似于gradient checkpoint方法,在前向的时候把输出结果 O = s o f t m a x ( Q K T ) V 、 l 、 m O = softmax(QK^T)V、l、m O=softmax(QKT)V、l、m 存入HBM中, 在反向时候重新计算需要的数据。
2.2.3 最终完整的算法说明如下:

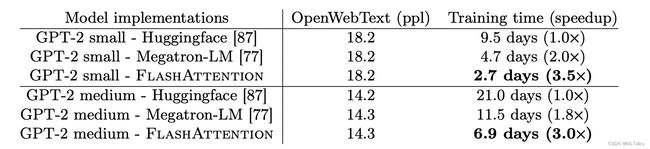
2.2.4 结果展示