Spark多维分析去重计数场景优化案例【BitMap精确去重的应用与踩坑】
关注交流微信公众号:小满锅
场景
前几天遇到一个任务,从前也没太注意过这个任务,但是经常破9点了,执行时长正常也就2个小时。
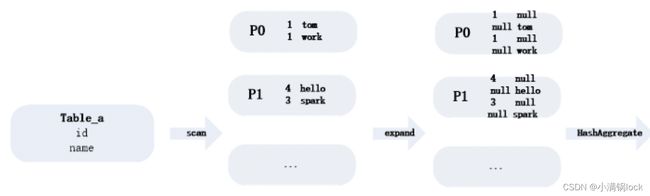
看逻辑并不复杂,基本是几段SQL的JOIN操作,其中一个最耗时间的就是要根据底表数据Lateral view explode(array(字段, ‘all’)),一共lateral了4个字段,相当于数据量要扩大16倍。并且可怕的场景,lateral view之后还对11个字段进行了去重。
select
a22 as a,
b22 as b,
c22 as c,
d22 as d,
e,
f,
,count(distinct g) as g
,count(distinct h) as h
,count(distinct i) as i
,count(distinct j) as j
,count(distinct k) as k
,count(distinct l) as l
,count(distinct m) as m
,count(distinct n) as n
,count(distinct o) as o
,count(distinct p) as p
,count(distinct q) as q
,count(distinct r) as r
,count(distinct s) as r
from
(
select
a
,b
,c
,d
,e
,f,g,h,i,j,k,l,...,r,s
from table
where dt='${etl_date}') t
lateral view explode(array(a, 'all')) a as a22
lateral view explode(array(b, 'all')) b as b22
lateral view explode(array(c, 'all')) c as c22
lateral view explode(array(d, 'all')) d as d22
group by 1,2,3,4,5,6,7,8,9,10,11,12,13
) t
group by a,b,c,d,e,f
定位问题
查看了执行计划,发现这个任务从Input:4亿多条数据 竟然expand到了700多亿,太夸张了,还以为Spark3.1.1能对这种多维分析场景有很好的优化呢。
但是我又百思不得其解了,从这个数据量来看,应该是一共扩大了176倍,其中Lateral View扩大了16倍我可以理解,剩下的11倍哪里来的?
突然觉得11这个数字很熟悉,就是那11个count(distinct)字段。仔细查看了执行计划,发现除了lateral view 有expand之外,Spark在对Count(distinct)处理时,根据11个字段的去重字段,对于每条记录会都会expand出11条记录,假设为A1-A11,那么每一条记录都对应唯一一个A字段有值,其他10个A字段为NULL,而count(distinct A)只需要计算count(1)即可,看似应该是为了结束数据倾斜的一个优化。这样就解释的通了。
相当于从Read->filter->expand->shuffle 原来的一条记录,变成了176条,也就是扩大了176倍。
解决问题
这种现象第一时间想到的是从两个方面入手,尽量减少这个任务在这个Stage消耗的时间。
- 第一种就是增加partition,这样减少每个partition的运行时间。
- 第二种就是减少expand的数据量,从根本上取解决问题。
第一种方案
设置参数
conf.spark.sql.shuffle.partitions = 4096
conf.spark.sql.files.maxPartitionBytes = 8m
conf.spark.shuffle.minNumPartitionsToHighlyCompress = 5000
conf.spark.sql.finalStage.adaptive.skewJoin.skewedPartitionFactor = 3
可以看到partition确实增加了,但是留有的风险比较多,这种就是要通过加资源保证任务快速运行,实际上这个任务不是那种P0任务,这个21min至少得保持1k多的task在并行跑才行,而实际任务在调度的时候,不可能抢到这么多资源,并且不能影响线上重要任务运行。因此这个方案暂时不去做深入研究了。
第二种方案
第二种方案是通过减少expand的量,这样下游处理的数据就会更少一些了。
尝试一
我原本想通过减少expand的量去解决这种问题,比如在子查询中聚合到最细的粒度,然后再去lateral view,但是在本地自己查询发现,即便是去重到最细粒度,仍然有4亿多条,经过那176倍之后,仍然会有700多亿条数据。这个想法失败。
尝试二
因为16个聚合多维分析这个必须存在,所以说扩大16倍是避免不了的(或者有啥其它办法也说不定呢)。
想办法从11个去重字段去入手,可以尝试分别分为两个stage各计算一半的字段,然后结果join起来,但是看起来会需要资源的支撑。
也可以看可不可以关掉count(distinct)的这个数据倾斜优化,找了半天没找到。
尝试三
改用bitmap对字段进行去重 大致就是自己写了一个UDAF,对于整个stage的每个阶段,实现UDAF抽象类的一些方法,比如处理原始数据,输出给下游采用byte[]形式,shuffle时merge,最终聚合输出。这里中间存储的数据结构为RoaringBitMap,听说这个存储和性能比较好,并且shuffle合并聚合时,可以直接利用它的OR操作进行位去重即可,快速且方便。
* BitmapDistinctUDAFBuffer 约定map和reduce的每个处理过程
* BitmapAggrBuffer 作为中间结果处理器。
*
* COMPLETE阶段:只要map阶段才调用
* PARTIAL1阶段:轻度汇总传给下游
* init方法 : 约定原始输入数据类型为Text 下游输出为byte[]
* iterate方法 : 将原始输入数据都拿过来 将其写入聚合去重中间结果处理器BitmapAggrBuffer
* terminatePartial: 将处理过后的BitmapAggrBuffer里面的RoaringBitmap处理成byte[]输出给下游
* PARTIAL2阶段:shuffle之后聚合
* init方法 : 约定下游输出为byte[]
* merge : 将iterate处理后的BitmapAggrBuffer稍微按照Group Key轻度聚合,即对不同的BitmapAggrBuffer里面的RoaringBitMap进行OR操作
* terminatePartial: 将处理过后的BitmapAggrBuffer里面的RoaringBitmap处理成byte[]输出给下游
* FINAL阶段 :最终结果聚合
* init方法 : 约定下游输出为byte[]
* merge : 将iterate处理后的BitmapAggrBuffer稍微按照Group Key轻度聚合,即对不同的BitmapAggrBuffer里面的RoaringBitMap进行OR操作
* terminate: 将处理过后的BitmapAggrBuffer里面的RoaringBitmap处理成byte[]输出
*/
资源非常充足的情况下,跑了很多次,基本30-40min跑完,申请不到资源仍然有50多min,这几次问题的共同点就是卡在了最后一个shuffle的时候,多维分析存在的问题就是,一旦分析维度存在较大差异,那么最细粒度和最粗粒度的数据一定会存在倾斜,可想而知,聚合粒度最粗的数据,要收集上游expand之后的所有数据,必定会导致这个分区长尾,执行时间也自然最长,并且这里打散还不能这样,多维分析时,得对最细的数据打散,一旦聚合到最细粒度之上了,最细粒度之下的数据无法计算,所以聚合到userid粒度时,再去打散,和上面Spark对其的优化一样,打散了多少呗,本身四亿多条数据,扩大16倍,再打散又扩大几倍,效果也不明显。
尝试四
第四种方式来源于第三种开发UDAF的时候看到RoaringBitMap可以进行一个OR操作,那么其实我读取数据的时候,上面一种方法是只能聚合到用户粒度,那聚合到用户粒度是为了多维分析时能够进行去重,那如果是基于这样的需求的话,我仍然可以聚合到多维分析的最细粒度,将用户信息存储到这个bitmap里面,就像下面这个图,很多用户id,标志0或者1,存储到RoaringBitMap数据结构中,那么下游多维分析时,只需要对轻度聚合之后的数据进行一个OR操作就可以了。

基于上面的方案,我又写了一个BitMapMerge的UDAF,主要是对BitMapDistinct出来的中间聚合结果(最细粒度的bitmap)进行合并操作(OR)。

心急如焚的跑了下,效果非常明显,在多维分析Expand之前,轻度聚合4亿多条到多维分析的最细粒度之后,发现只有3000多条数据了,效果非常明显,心想着如果执行lateral view expand之后应该也就是48000左右的数据,然后再聚合到多维分析的各个粒度,这样即便是数据倾斜了,应该也没事,处理的数据量比较小。这样从700亿数据到48000w左右的expand量,数据量上优化了145w倍
。。。完了,内存爆了,失败了,加到Excutor 12G都不行,而且发生在了Input Read的阶段,这里困扰了我,看了很久,发现一个问题就是,轻度聚合的数据只有3000左右了但是足足有11G?我直接计算出每条记录每个bitmap的数值,发现有的去重结果中,有个别千万级别有亿级别的去重数,所以想会不会就是这些个别的大数导致那一部分task失败了呢(因为我即便加了partition也没用,所以我猜测光一条数据就很大)。这个级别的去重数并不可怕,算一算即便是3亿的去重结果,按照bitmap来算的话,也就是300000000/8/1024/1024=35M左右的数据大小,但是越想越不对,就是这里有11个字段,每个都这么大,在expand,351116=6g,一条记录就要expand这么大的数据,那一个task读几条再加expand还不得起飞,这下我知道了,我遇到的不是数据量的倾斜,而是数据大小的倾斜,极个别数据太大了,导致input阶段在expand的时候超内存了。
为了验证自己的想法没错,我将11个字段减少几个比较大的bitmap字段,结果5min就跑完了,并且内存保持的相对不错这也太好了吧。于是就打算将多个结果拆分出来计算再JOIN了。

其它方案
其实为了解决上面expand的数据大小太大的问题,我们终究就是去一个数据量的倾斜和数据大小倾斜之间的一个平衡。加入我不进行轻度聚合,那么就是数据量的倾斜,假如进行轻度聚合,那么就是数据大小的倾斜。那其实就是为了这个平衡的话,可以在轻度聚合的时候,采用一个比较传统的方式,打散聚合,这样就可以平衡掉某条记录因为读取记录大小太大,导致expand出去的数据太大,假设打散100倍,那么最终expand出去的数据也就480w条,优化效果仍然比以前的700亿的数据量要好很多。
但是最终的数据还是一个task在处理,这样的话最粗粒度的key,将会聚集最大bitmap,处理时间会更久,导致长尾。
总结
对于多维分析切去重计数场景,需要尽可能减少expand的量,同时使用bitmap也有坑,一般来说,像这种多维分析场景中,粒度越粗的key总会是聚集用户数最多的,造成数据大小的倾斜,那么处理的时间也是最长的,直观上从平时打散的角度并不会有太多效果,最终处理的结果还是一样。
比较好的方式应该是拆分字段计算,最终再JOIN。最终加起来在资源不足的情况下差不多20min左右,比起资源不足的源代码至少得运行2小时-2个半小时,效果还是非常明显的,并且expand的数据量也从700亿降到了48000数据量。不过单条数据的数据大小确实变大了。
![]()
![]()
反思
这里利用BitMap分析多维场景,存在一个问题,就是说更粗粒度的计算过程中,其实已经经历了比它更细粒度的bitmap合并。这就是为什么要在内部先聚合到多维分析的最细粒度,来减少重复合并的这个过程。
那其实对于多维分析,其实每个维度本身也是嵌套的父子关系
比如分析维度
os, appver, source
那假如要分析os,appver的话其实就可以基于上面这个维度去进一步merge
加入要分析os维度,就可以基于os, appver再进一步分析。
那我优化的方式使用分JOIN计算Bitmap字段其实对于每个字段而言,还是存在数据大小的倾斜,就是说即便是一个字段,那么它的最粗粒度的分析一定是倾斜的,因为Group sets或者lateral view是将原始数据直接expand16倍,再进行聚合,那么最粗粒度一定是数据量最多(这里虽然不足48000),自然处理数据大小也最大,可能多大几个G,数据大小太大的原因就是因为BitMap存储还是占用太多空间了,其中一个更好的优化,要是可以基于最细粒度自由上卷下钻就好了,就好比一些外部存储一样,存储最细粒度,自动帮你上卷到最粗粒度,一层层叠加,不重复计算。
那Spark暂时没想到避免重复计算的方式,后面就从改善Bitmap存储大小入手,考虑用HLL优化试试,期待能够优化到10min以内。