python 定时器
需求
我想在某一时刻完成某个任务,需要一个定时计划
调研了几种方式都不是很理想. 参考,python实现定时任务的8种方式详解
选择使用 apscheduler 库吧
- APScheduler简介
APScheduler是Python的一个定时任务框架,用于执行周期或者定时任务,该框架不仅可以添加、删除定时任务,还可以将任务存储到数据库中,实现任务的持久化,使用起来非常方便。
APscheduler全称Advanced Python Scheduler,作用为在指定的时间规则执行指定的作业,其是基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务. - 安装
pip install apscheduler - APScheduler组成
- 触发器(trigger):包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置以外,触发器完全是无状态的。
- 作业存储(job store):存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据将在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。
- 执行器(executor):处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
- 调度器(scheduler):其他的组成部分。通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。
3.1 触发器(trigger)
包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了它们自己初始配置以外,触发器完全是无状态的。
APScheduler 有三种内建的 trigger:
date: 特定的时间点触发
interval: 固定时间间隔触发
cron: 在特定时间周期性地触发
后边我们写代码会看到
3.2 作业存储(job store)
如果你的应用在每次启动的时候都会重新创建作业,那么使用默认的作业存储器(MemoryJobStore)即可,但是如果你需要在调度器重启或者应用程序奔溃的情况下任然保留作业,你应该根据你的应用环境来选择具体的作业存储器。例如:使用Mongo或者SQLAlchemy JobStore (用于支持大多数RDBMS)。
任务存储器是可以存储任务的地方,默认情况下任务保存在内存,也可将任务保存在各种数据库中。任务存储进去后,会进行序列化,然后也可以反序列化提取出来,继续执行。
3.3 执行器(executor)
Executor在scheduler中初始化,另外也可通过scheduler的add_executor动态添加Executor。
每个executor都会绑定一个alias,这个作为唯一标识绑定到Job,在实际执行时会根据Job绑定的executor。找到实际的执行器对象,然后根据执行器对象执行Job。
Executor的选择需要根据实际的scheduler来选择不同的执行器。
处理作业的运行,它们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
3.4 调度器(scheduler)
Scheduler是APScheduler的核心,所有相关组件通过其定义。scheduler启动之后,将开始按照配置的任务进行调度。除了依据所有定义Job的trigger生成的将要调度时间唤醒调度之外。当发生Job信息变更时也会触发调度。
scheduler可根据自身的需求选择不同的组件,如果是使用AsyncIO则选择AsyncIOScheduler,使用tornado则选择TornadoScheduler。
任务调度器是属于整个调度的总指挥官。它会合理安排作业存储器、执行器、触发器进行工作,并进行添加和删除任务等。调度器通常是只有一个的。开发人员很少直接操作触发器、存储器、执行器等。因为这些都由调度器自动来实现了。
4、常见的两种调度器
APScheduler中有很多种不同类型的调度器,BlockingScheduler与BackgroundScheduler是其中最常用的两种调度器。那他们之间有什么区别呢? 简单来说,区别主要在于BlockingScheduler会阻塞主线程的运行,而BackgroundScheduler不会阻塞。所以,在不同的情况下,选择不同的调度器:
BlockingScheduler: 调用start函数后会阻塞当前线程。当调度器是你应用中唯一要运行的东西时(如上例)使用。
BackgroundScheduler: 调用start后主线程不会阻塞。当你不运行任何其他框架时使用,并希望调度器在你应用的后台执行。
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.schedulers.background import BackgroundScheduler
直接看代码
from apscheduler.schedulers.blocking import BlockingScheduler
import time
from datetime import datetime
# from apscheduler.schedulers.background import BackgroundScheduler
def my_task(scheduler):
jobs = scheduler.get_jobs()
print("my_task--", jobs)
# 这里是你要执行的任务逻辑
# with open('ab.txt','a+',encoding='utf8') as f:
# f.write('{}\n'.format(time.time()))
def task():
now = datetime.now()
ts = now.strftime("%Y-%m-%d %H:%M:%S")
print(ts)
def task2():
now = datetime.now()
ts = now.strftime("%Y-%m-%d %H:%M:%S")
print(ts + '666!')
# 创建调度器BlockingScheduler()
scheduler = BlockingScheduler()
scheduler.add_job(task, 'date', run_date=datetime(2023, 10, 8, 14, 32, 50), id='test_job1')
scheduler.add_job(task2, 'date', run_date=datetime(2023, 10, 8, 14, 32, 40), id='test_job2')
# 添加定时任务
job = scheduler.add_job(my_task, 'interval', seconds=5, args=(scheduler,))
scheduler.start()
# 查看任务列表
# jobs = scheduler.get_jobs()
# print(jobs)
# 启动调度器
scheduler.start()
# 修改任务
job.modify(args=('hello', 'apscheduler'))
# 再次查看任务列表
jobs = scheduler.get_jobs()
print(jobs)
运行结果:
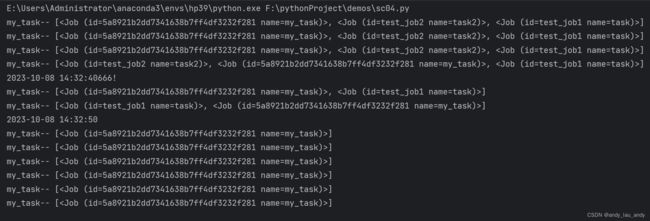
这里可以看到一个情况,就是一次性的任务,执行完,就从 scheduler 中踢除了
对于 add_job方法
def add_job(self, func, trigger=None, args=None, kwargs=None, id=None, name=None,
misfire_grace_time=undefined, coalesce=undefined, max_instances=undefined,
next_run_time=undefined, jobstore='default', executor='default',
replace_existing=False, **trigger_args):
"""
add_job(func, trigger=None, args=None, kwargs=None, id=None, \
name=None, misfire_grace_time=undefined, coalesce=undefined, \
max_instances=undefined, next_run_time=undefined, \
jobstore='default', executor='default', \
replace_existing=False, **trigger_args)
Adds the given job to the job list and wakes up the scheduler if it's already running.
Any option that defaults to ``undefined`` will be replaced with the corresponding default
value when the job is scheduled (which happens when the scheduler is started, or
immediately if the scheduler is already running).
The ``func`` argument can be given either as a callable object or a textual reference in
the ``package.module:some.object`` format, where the first half (separated by ``:``) is an
importable module and the second half is a reference to the callable object, relative to
the module.
The ``trigger`` argument can either be:
#. the alias name of the trigger (e.g. ``date``, ``interval`` or ``cron``), in which case
any extra keyword arguments to this method are passed on to the trigger's constructor
#. an instance of a trigger class
:param func: callable (or a textual reference to one) to run at the given time
:param str|apscheduler.triggers.base.BaseTrigger trigger: trigger that determines when
``func`` is called
:param list|tuple args: list of positional arguments to call func with
:param dict kwargs: dict of keyword arguments to call func with
:param str|unicode id: explicit identifier for the job (for modifying it later)
:param str|unicode name: textual description of the job
:param int misfire_grace_time: seconds after the designated runtime that the job is still
allowed to be run (or ``None`` to allow the job to run no matter how late it is)
:param bool coalesce: run once instead of many times if the scheduler determines that the
job should be run more than once in succession
:param int max_instances: maximum number of concurrently running instances allowed for this
job
:param datetime next_run_time: when to first run the job, regardless of the trigger (pass
``None`` to add the job as paused)
:param str|unicode jobstore: alias of the job store to store the job in
:param str|unicode executor: alias of the executor to run the job with
:param bool replace_existing: ``True`` to replace an existing job with the same ``id``
(but retain the number of runs from the existing one)
:rtype: Job
"""
job_kwargs = {
'trigger': self._create_trigger(trigger, trigger_args),
'executor': executor,
'func': func,
'args': tuple(args) if args is not None else (),
'kwargs': dict(kwargs) if kwargs is not None else {},
'id': id,
'name': name,
'misfire_grace_time': misfire_grace_time,
'coalesce': coalesce,
'max_instances': max_instances,
'next_run_time': next_run_time
}
job_kwargs = dict((key, value) for key, value in six.iteritems(job_kwargs) if
value is not undefined)
job = Job(self, **job_kwargs)
# Don't really add jobs to job stores before the scheduler is up and running
with self._jobstores_lock:
if self.state == STATE_STOPPED:
self._pending_jobs.append((job, jobstore, replace_existing))
self._logger.info('Adding job tentatively -- it will be properly scheduled when '
'the scheduler starts')
else:
self._real_add_job(job, jobstore, replace_existing)
return job
id:指定作业的唯一ID
name:指定作业的名字
trigger:apscheduler定义的触发器,用于确定Job的执行时间,根据设置的trigger规则,计算得到下次执行此job的时间, 满足时将会执行
executor:apscheduler定义的执行器,job创建时设置执行器的名字,根据字符串你名字到scheduler获取到执行此job的 执行器,执行job指定的函数
max_instances:执行此job的最大实例数,executor执行job时,根据job的id来计算执行次数,根据设置的最大实例数来确定是否可执行
next_run_time:Job下次的执行时间,创建Job时可以指定一个时间[datetime],不指定的话则默认根据trigger获取触发时间
misfire_grace_time:Job的延迟执行时间,例如Job的计划执行时间是21:00:00,但因服务重启或其他原因导致21:00:31才执行,如果设置此key为40,则该job会继续执行,否则将会丢弃此job
coalesce:Job是否合并执行,是一个bool值。例如scheduler停止20s后重启启动,而job的触发器设置为5s执行一次,因此此job错过了4个执行时间,如果设置为是,则会合并到一次执行,否则会逐个执行
func:Job执行的函数
args:Job执行函数需要的位置参数
kwargs:Job执行函数需要的关键字参数
触发器的三种
date: 特定的时间点触发
interval: 固定时间间隔触发
cron: 在特定时间周期性地触发
代码及参数
interval
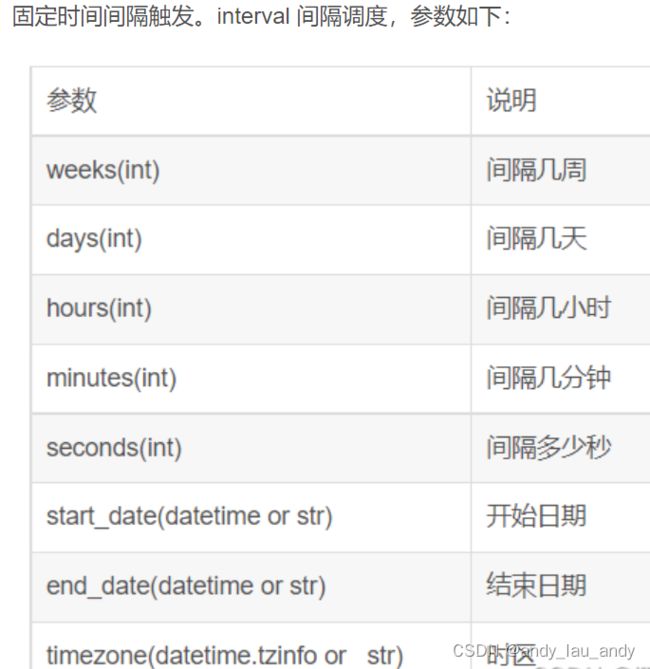
scheduler = BlockingScheduler()
scheduler.add_job(task, 'interval', seconds=3, id='test_job1')
# 添加任务,时间间隔为5秒
scheduler.add_job(task2, 'interval', seconds=5, id='test_job2')
# 在2022-10-27 21:50:30和2022-10-27 21:51:30之间,时间间隔为6秒
scheduler.add_job(task3, 'interval', seconds=6, start_date='2022-10-27 21:53:00', end_date='2022-10-27 21:53:30', id ='test_job3')
# 每小时(上下浮动20秒区间内)运行task
# jitter振动参数,给每次触发添加一个随机浮动秒数,一般适用于多服务器,避免同时运行造成服务拥堵。
scheduler.add_job(task, 'interval', hours=1, jitter=20, id='test_job4')
scheduler.start()
date
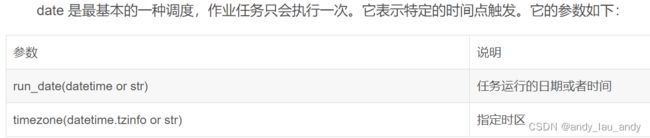
注意:run_date参数可以是date类型、datetime类型或文本类型。
scheduler = BlockingScheduler()
scheduler.add_job(task, 'date', run_date=datetime(2022, 10, 27, 21, 39, 00), id='test_job1')
scheduler.add_job(task2, 'date', run_date=datetime(2022, 10, 27, 21, 39, 50), id='test_job2')
scheduler.start()
cron

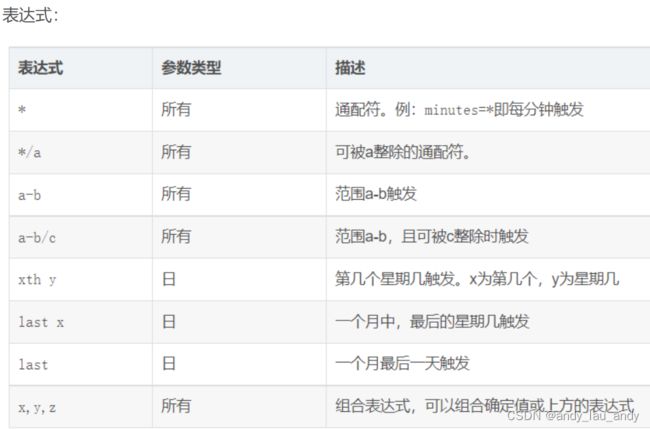
cron: 在特定时间周期性地触发,和Linux crontab格式兼容。它是功能最强大的触发器。
scheduler = BlockingScheduler()
# 在每年 1-3、7-9 月份中的每个星期一、二中的 00:00, 01:00, 02:00 和 03:00 执行 task 任务
scheduler.add_job(task, 'cron', month='1-3,7-9', day_of_week='1-2', hour='0-3', id='test_job1')
scheduler.start()
其他参考:apscheduler库用法详解