R语言基础编程技巧汇编 - 25
1. 使用rClr包访问.NET库
下载地址:http://r2clr.codeplex.com/
library(rClr)
clrLoadAssembly('c:/path/to/myassembly.dll')
myObj <-clrNew('MyNamespace.MyClass,MyAssemblyName')
clrCall(myObj, 'SayHelloWorld')
2. 向C语言代码传递数据框参数示例
data.frame是一个list对象
#include
SEXP df_fun(SEXP df)
{
int i, len = Rf_length(df);
SEXP result;
PROTECT(result = NEW_CHARACTER(len));
for (i = 0; i < len; ++i)
switch(TYPEOF(VECTOR_ELT(df, i))) {
case INTSXP:
SET_STRING_ELT(result, i, mkChar("integer"));
break;
case REALSXP:
SET_STRING_ELT(result, i, mkChar("numeric"));
break;
default:
SET_STRING_ELT(result, i, mkChar("other"));
break;
};
UNPROTECT(1);
return result;
}
然后使用 R CMD SHLIB来编译df_fun.c文件成库。
> dyn.load("df_fun.so")
> df=data.frame(x=1:5, y=letters[1:5],z=pi, stringsAsFactors=FALSE)
> .Call("df_fun", df)
[1] "integer""other" "numeric"
在Rdefines.h文件中定义的宏GET_CLASS, GET_ATTR等,可以用来访问数据框的各种属性。
3. 通过代码获取帮助文件文本
hs <- help(survey)
tools:::Rd2txt(utils:::.getHelpFile(as.character(hs)))
Student Survey Data
Description:
This data frame containsthe responses of 237 Statistics I
students at the University of Adelaide to a number of questions.
Usage:
survey
Format:
The components of the data frame are:
'Sex' The sex of thestudent. (Factor with levels '"Male"' and
'"Female"'.)
'Wr.Hnd' span (distancefrom tip of thumb to tip of little finger
of spread hand) of writing hand, in centimetres.
'NW.Hnd' span ofnon-writing hand.
'W.Hnd' writing hand ofstudent. (Factor, with levels '"Left"' and
'"Right"'.)
'Fold' "Fold yourarms! Which is on top" (Factor, with levels '"R
on L"', '"L on R"', '"Neither"'.)
'Pulse' pulse rate ofstudent (beats per minute).
'Clap' 'Clap yourhands! Which hand is on top?' (Factor,with
levels '"Right"', '"Left"', '"Neither"'.)
'Exer' how often thestudent exercises. (Factor, with levels
'"Freq"' (frequently), '"Some"','"None"'.)
'Smoke' how much the student smokes. (Factor, levels'"Heavy"',
'"Regul"' (regularly), '"Occas"' (occasionally),'"Never"'.)
'Height' height of thestudent in centimetres.
'M.I' whether the studentexpressed height in imperial
(feet/inches) or metric (centimetres/metres) units. (Factor,
levels '"Metric"', '"Imperial"'.)
'Age' age of the student inyears.
References:
Venables, W. N. and Ripley,B. D. (1999) _Modern Applied
Statistics with S-PLUS._ Third Edition. Springer.
4. 得到R环境的临时文件夹
tempdir()
[1]"C:\\Users\\sliu\\AppData\\Local\\Temp\\RtmpgJtwWX"
5. 计算Gradient向量和Hessian矩阵
函数的Gradient向量定义如下:

Hessian矩阵定义如下:
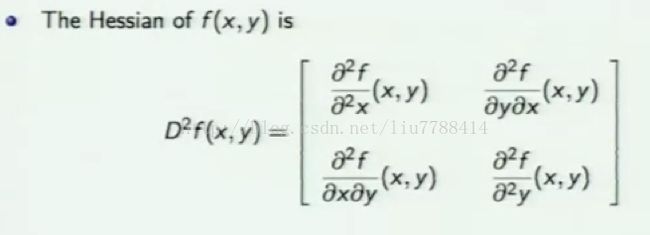
library(pracma)
dummy <- function(x) {
z<- x[1]; y <- x[2]
rez<- (z^2)*(y^3)
rez
}
grad(dummy, c(1,2))
[1] 16 12
hessian(dummy, c(1,2))
[,1] [,2]
[1,] 16 24
[2,] 24 12
6. 寻求帮助的包sos
sos包是专门用于查找R语言帮助信息的包,远比基础的help函数强大,查找范围包括所有的R语言包,比如搜索下面的信息,搜索结果会以网页的形式返回,其他更高级的使用方法请查看sos包的帮助文档。
library(sos)
???"Dickey-Fuller"

7. 只读取文件中的部分列
比如文件data.txt的内容如下,
"Year" "Jan" "Feb" "Mar""Apr" "May" "Jun" "Jul" "Aug""Sep" "Oct" "Nov" "Dec"
2009 -41 -27 -25 -31 -31 -39 -25 -15 -30-27 -21 -25
2010 -41 -27 -25 -31 -31 -39 -25 -15 -30-27 -21 -25
2011 -21 -27 -2 -6 -10 -32 -13 -12 -27 -30-38 -29
#我只希望读取前七列的数据,可以把不需要的列的类型设置为NULL
read.table("data.txt", colClasses =c(rep("integer", 7), rep("NULL", 6)), header = TRUE)
Year Jan Feb Mar Apr May Jun
1 2009 -41 -27 -25 -31 -31 -39
2 2010 -41 -27 -25 -31 -31 -39
3 2011 -21 -27 -2 -6 -10 -32
8. 用rank函数实现并列排名
对如下向量,实现并列排名,即如果并列第一名有两个,则下一个是第三名。
x <- c(0.64, 0.64, 0.63, 0.62, 0.62, 0.62, 0.61, 0.6, 0.6, 0.58)
rank(-x, ties="min")
#[1] 1 1 3 4 4 4 7 8 8 10
9. 用split函数对数据框进行分组
df <- data.frame(ids=c(1,1,2,2,3),x=1:5,y=letters[1:5])
split(df, df$ids)
# $`1`
# ids x y
# 1 1 1 a
# 2 1 2 b
#
# $`2`
# ids x y
# 3 2 3 c
# 4 2 4 d
#
# $`3`
# ids x y
# 5 3 5 e
10. 字符形式的进度条
imax<-c(10)
#字符形式的进度条
pb <- txtProgressBar(min = 0, max = imax, style = 3)
for(i in 1:imax) {
Sys.sleep(1)
# 更新进度
setTxtProgressBar(pb, i)
}
cat("\n")
效果:
![]()
11. 用approxfun函数求出density函数曲线上的点坐标
dat<-c(5,7,4,6,4,3,55,6,7,5,4,3,33,44,5,2,33,22)
hist (dat,freq=FALSE)
d<-density(dat)
lines(d, col="red", lwd=2)
#get density function
dd<-approxfun(d$x, d$y)
#plot results
abline(v=mean(dat), lty=2)
points(0:60, dd(0:60), cex=1.2, pch=20, col="blue")

12. 趣味实现:生成乘法口诀表
#有很多种方法生成乘法口诀表,这里提供两例,第一例使用sapply和paste0函数;第二例使用#outer函数
例一:
A <- 1:9
B <- 1:9
FunOut <- function(x)
{
FunIn <- function(y)
{
paste0(x, 'X',y,'=',x * y)
}
sapply(B, FunIn)
}
AB <- sapply(A,FunOut)
例二:
outer(1:9, 1:9, function(X, Y) noquote(sprintf("%dX%d=%d",X, Y, X*Y)))

13. 在基础绘图包中,把坐标轴标签显示成两行
## data
N <- 10
dnow <- data.frame(x=1:N, y=runif(N), labels=paste("This is\nobservation ",1:N))
## make margins wide
par(mfrow=c(1,1), mar=c(10,10,6,4))
## plot without axix labels or ticks
with(dnow, plot(x,y, xaxt="n", xlab=""))
## the positions we ant to plot
atn <- seq(1,N,3)
## the label for these positions
lab <- dnow$labels[atn]
## plot the axis, but do not plot labels
axis(1, at=atn, labels=FALSE)
## plot labels
text(atn, ## x position
par("usr")[3]-.05, ## position of the low axis
srt=45, ## angle
labels=lab, ##labels
xpd=TRUE, ## allowsplotting outside the region
pos=2)
## par("usr")[3]

14. 使用rle函数统计字符的连续出现次数
a<-c(1,1,2,2,2,3,3,3,5,5,5,6,6,6)
rle(a)
#Run Length Encoding
# lengths: int [1:5] 2 3 3 3 3
# values : num [1:5] 1 2 3 5 6
结果解释,上面是计数,下面是字符,1两个,2三个,3三个,5三个,6三个
15. 利用parse函数和eval函数动态执行不同的运算符
parse函数可以解析字符串形式的表达式,并转化为expression类型,eval函数可以计算expression类型的表达式:
A <- 1
B <- 2
for(i in c('/','+','-','*'))
{
S <- paste0('A', i,'B')
print(S)
E <- parse(text = S)
print(E)
print(eval(E))
}
# [1] "A/B"
# expression(A/B)
# [1] 0.5
# [1] "A+B"
# expression(A+B)
# [1] 3
# [1] "A-B"
# expression(A-B)
# [1] -1
# [1] "A*B"
# expression(A*B)
# [1] 2