第三章 ArcGIS Pro创建 python 脚本工具(二)
原著链接
3.4 创建脚本工具的步骤
简单的步骤:
- 创建一个执行预期任务的 Python 脚本,并将其保存为 .py。
- 创建一个自定义工具箱(.tbx文件),可以存储脚本工具。
- 将脚本工具添加到自定义工具箱。
- 配置 工具的属性和参数。
- 修改脚本,使其可以接收工具参数。
- 测试您的脚本工具是否按预期工作。根据需要修改脚本和/或工具的参数,以使脚本工具正常工作。
相对详细的过程如下:
创建工具箱可以在Catalog的工具箱导航中创建,也可以直接在数据库或文件夹中创建新的工具箱。但是在数据库中新建工具箱后,要共享工具箱只能通过共享整个数据库,独立的工具箱保存为.tbx文件,能够更轻松的共享。地理数据库中的工具箱并不会有文件拓展名,而其他会有.tbx的后缀名。
之后在自定义工具箱右击,新建脚本。因为添加新的脚本工具需要对工具箱的权限,所以会无法将工具添加到系统工具箱中。只能添加到自己自定义的工具箱。
新建脚本对话框有三个面板:常规、参数与验证
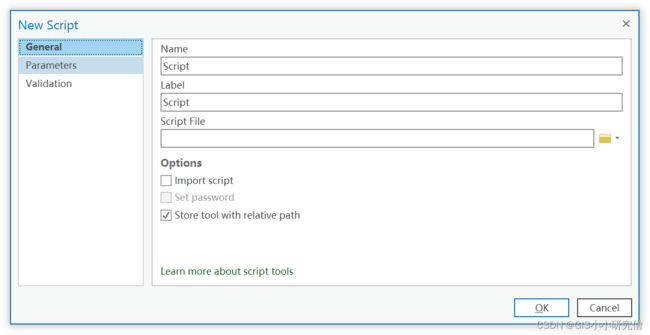
内容如图所示,常规包括:名称、标签、脚本文件等。参数指定工具参数,控制用户与工具交互的方式。验证面板提供更多选项来进行工具的行为和外观设置。可以仅仅设置文件名称等,之后对其他内容进行编辑。
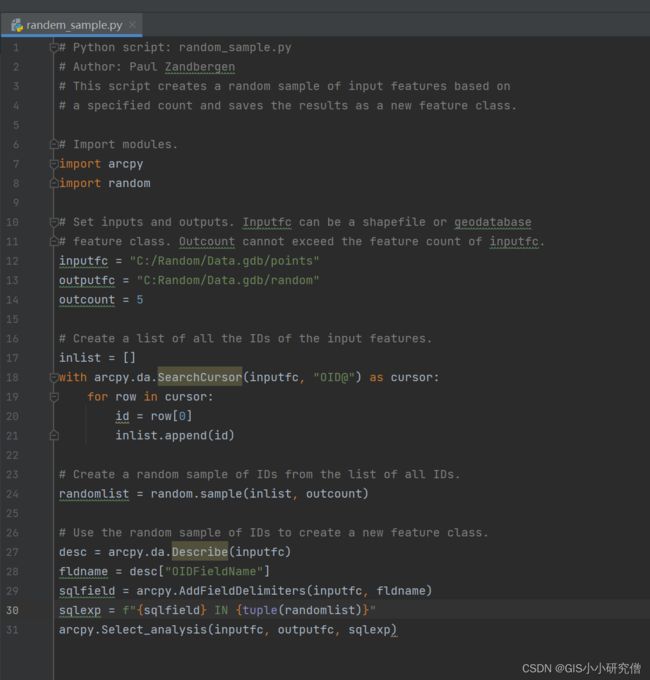
本章详细介绍了创建脚本需要的多有的信息。首先关于示例脚本,在实例情况下脚本更加有意义。示例脚本已经新建好,是一个独立的.py脚本文件,这个脚本根据用户指定的计数从输入要素类中创建随机要素样本,并将生成的样本保存为新要素类。下面是完整的代码,然后是脚本的窗口图,窗口中的颜色突出有助于理解与阅读。
# Python script: random_sample.py
# Author: Paul Zandbergen
# This script creates a random sample of input features based on
# a specified count and saves the results as a new feature class.
# Import modules.
import arcpy
import random
# Set inputs and outputs. Inputfc can be a shapefile or geodatabase
# feature class. Outcount cannot exceed the feature count of inputfc.
inputfc = "C:/Random/Data.gdb/points"
outputfc = "C:Random/Data.gdb/random"
outcount = 5
# Create a list of all the IDs of the input features.
inlist = []
with arcpy.da.SearchCursor(inputfc, "OID@") as cursor:
for row in cursor:
id = row[0]
inlist.append(id)
# Create a random sample of IDs from the list of all IDs.
randomlist = random.sample(inlist, outcount)
# Use the random sample of IDs to create a new feature class.
desc = arcpy.da.Describe(inputfc)
fldname = desc["OIDFieldName"]
sqlfield = arcpy.AddFieldDelimiters(inputfc, fldname)
sqlexp = f"{sqlfield} IN {tuple(randomlist)}"
arcpy.Select_analysis(inputfc, outputfc, sqlexp)
关于脚本有几点要注意:
1、脚本的逻辑。这个脚本创建输入特征的所有唯一ID的列表,并使用random模块的sample()函数创建具有随机样本唯一ID的新列表。这个列表用于从输入要素中选择要素,并将结果保存为新的要素类。
2、输入要素类、输出要素类、要选择的要素类进行了硬编码。
3、这个脚本适用于shp文件和数据库要素类。其通过在设置搜索光标时使用OID@来实现,通过使用OIDFieldName属性来读取存储唯一的ID的字段的名称。并且使用AddFieldDelimiters()函数来确保正确的SQL语法而不管要素类的类型。
SQL语句中的WHERE语句使用IN运算符将特征的唯一ID与随机选择的ID列表进行比较,如下所示:
sqlexp = f"{sqlfield} IN {tuple(randomlist}}"
在SQL中,这个列表必须在一组括号中,相当于Python中的元组。为了保证争取的字符串格式,使用f字符串,这种格式可以使用.format()来完成。在测试脚本时,可以添加以下内容检测where子句。
print(sqlexp)
对于地理数据库要素类,WHERE子句如下所示:
OBJECTID IN (1302, 236, 951, 913, 837)
对于shp文件,where子句:
"FID" IN (820, 1095, 7, 409, 145)
shp与要素类的唯一值,一个是用的FID字段,一个是OBJECTID,这在前面也提过了。
每次运行脚本时要选择的实际 ID 值都会发生变化,因为 sample() 函数会创建一个新的随机选择,而不管之前的结果如何。
WHERE 子句用作创建输出要素类的选择工具的第三个参数。 该脚本不适用于独立表,因为选择工具仅适用于要素类。要使用独立表,要改用按属性选择图层工具。
尽管直接使用脚本可以正常工作,但对输入进行更改需要在 Python 编辑器中打开脚本、修改输入并运行脚本。但是使用工具对话框使共享此脚本的功能变得更加容易。 脚本工具的目标是让用户能够指定要用于采样的输入要素类、用于保存结果的输出要素类以及要包含在随机样本中的要素数量。
换句话说,目标是拥有一个脚本工具,其中工具对话框包含这些功能,如下图所示。
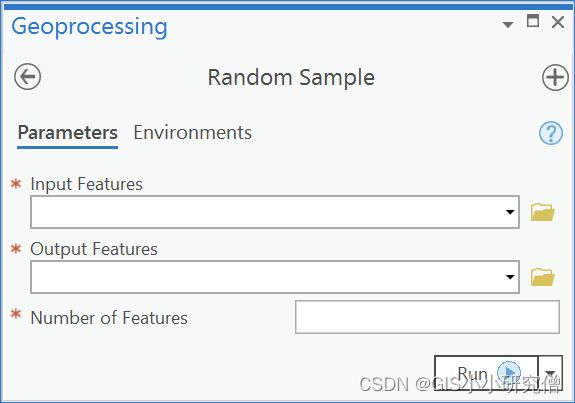
对于最后要设计的工具的对话框有一个初步的期望很重要,有助于准备脚本。关于示例脚本有几点要注意,首先脚本被分为及部分,每个部分前面都有注释。虽然脚本工作时不需要,但是如果需要查看代码时,注释会帮助理解。其次,脚本使用硬编码,包括输入要素类、输出要素类与要素的数量。这类硬编码很重要,硬编码仅限于成为工具参数的变量。
在将脚本转换为脚本工具时,要遵循以下原则:
首先确保您的脚本作为独立脚本 能正常工作。
工作正确地使用硬编码值。
确定哪些值将成为脚本工具中的参数。在脚本顶部附近为这些值创建变量,并确保硬编码值仅使用一次以将值分配给变量。 脚本的其余部分不应包含任何硬编码值并且仅使用变量。
尽管输入要素类存在,独立脚本将正常运行,但是脚本需要进行一些更改才能用作脚本工具的一部分。这些更改通过将值的硬编码限制为将用作工具参数的变量来促成。
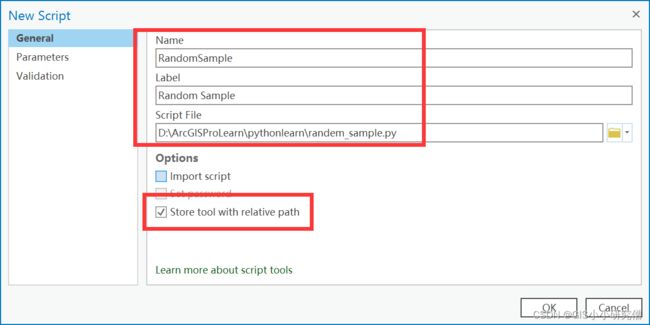
返回新建脚本对话框窗口,接下来是要完成窗口内的信息。以下信息是必须的:
1、工具名:名称有一定的要求,不能有空格、_等,遵循适用于python函数名称的大多数规则。
2、标签:标签可以有空格,在示例中,该工具显示时带有其标签Get Count(带空格),但对于从Python调用的工具,其名称不带有空格。
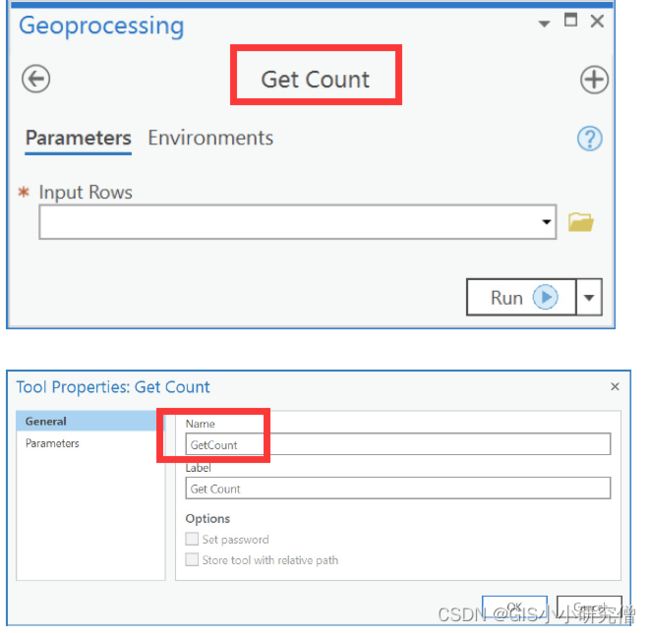
注:Get Count 不是脚本工具,而是系统工具,因此没有脚本。您可以查看任何内置地理处理工具的属性,包括系统工具和脚本工具。查看现有工具的属性是了解工具设计和为自己的工具获取创意的好方法。
3、脚本文件是只从工具时要运行的脚本的完成路径。
4、有三种不同的选项,第一个是是否导入脚本,在创建脚本工具时最好不要导入脚本文件,但是在进行分享时应该导入。设置密码的选项只有在选择导入脚本时才会被激活,默认情况下,大多数的脚本工具不导入脚本。
5、第三个选项,表示是使用相对的路径来存储工具。这个选项通常选上,在脚本文件和脚本工具在一个文件夹时,使用相对路径能保证在移动文件夹后,仍能成功打开工具。使用绝对路径,在移动文件夹后就要重新设置才行。
设置如图所示:
现在就可以保存了,其他的参数和验证可以再后面再修改。
虽然它看起来像一个 Anished 脚本工具,但该工具远未完成。双击脚本工具时,工具对话框打开,但没有参数。

所以需要添加参数,右击工具,选择属性后打开参数对话框
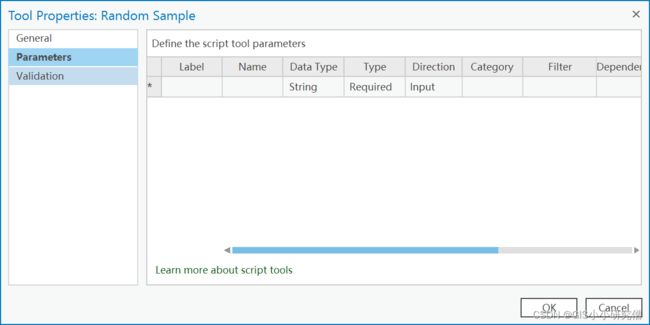
默认情况下,不列出任何参数,但大多数工具至少需要一个输入参数和一个输出参数。 脚本工具参数以表格形式组织。表格中的每一行是一个参数,表格中的每一列是参数的一个属性。 下一节将详细介绍工具参数。