RAG:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 论文阅读

2020 NeuralPS
文章地址:https://arxiv.org/abs/2005.11401
源码地址:GitHub - huggingface/transformers: Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX. - 142 RAG
目录
0、背景
1、摘要
2、导言
3、结论
4、模型
5、实验
6、与REALM比较
7、想法
0、背景
Language Models as Knowledge Bases?(LAMA)这篇论文作者认为现如今经过预训练之后的语言模型可以看做是一个知识库,但是也引来了模型的局限性:各种知识都隐藏在模型庞大的参数中, 并不知道知识如何获取到的,以及模型给出答案的理由。从这篇论文之后,NLP研究者们就开始致力于从增强模型的可解释性方面入手来提高模型的效果。本篇就是其中的一篇代表作。主要思路和2020.2发表的REALM很类似(在我的nlp专栏里有对REALM这篇文章的讲解)。
1、摘要
很多参数知识存储在LLMs中的参数中(LAMA这篇文章证明),针对下游任务微调之后可以取得SOTA效果。但是这种方式具有一定的劣势:在Open-QA任务上,仍然还很欠缺,(语言模型还不能很好的获取精确知识)、给出的答案不具有可解释性,对于知识库无法实现实时更新的效果,不便于更新。论文提出RAG:参数化知识(BART预训练学到的知识) + 非参数化知识(维基百科的密集向量索引)结合的方式来解决这三类问题。
2、导言
现如今语言模型缺点
(1) 不能轻易扩展或修改“记忆”
(2) 模型给出的预测不具有可解释性
(3) 可能产生“幻觉”(幻觉的解释:生成了不可靠的文本,即一 本正经的胡说八道)。幻觉的官方定义:在给定的信息源下是无意义的,不可靠的
综上,在当前的知识密集型任务的研究中,具有实用价值的模型基本都依赖于外部知识库。开放域问答系统(Open-domain QA)是最经典也最重要的知识密集型任务之一,目前的SOTA模型基本都包含两个模块:文档检索器和文档阅读器,前者负责检索重排和输入相关的文档,后者负责从这些文档中抽取或生成出答案片段。
3、结论
(1) 虽然可以直接从文档中抽取答案片段,但直接生成答案有一些额外的好处,比如有些文档并不直接包含整个答案,但包含答案的线索,这些线索就能帮助模型生成更正确的答案;
(2) 与REALM相比,RAG是参数化知识+非参数化知识的结合,所以即是检索不到有用的相关文档z,也可以单凭参数化的知识(BART),根据模型学到的知识回答出正确的答案;
(3) RAG的灵活性很高。要改变预训练的语言模型所知道的内容,需要用新的文档对整个模型进行再训练。通过 RAG,我们可以通过交换知识检索所用的文档来控制它所知道的内容。
4、模型
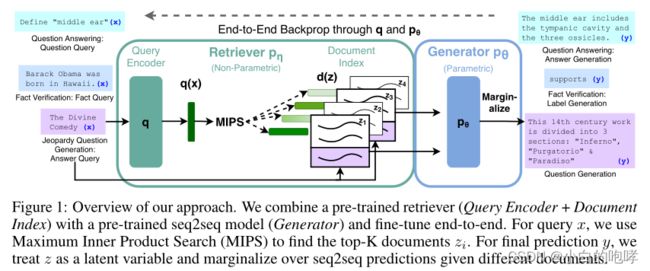
(1) 检索器:DPR模型(Dense Passage Retriever), 用以检索和输入相关的文档,遵循双编码器结构。![]()
![]()
d(z)是Bert产生的文档的密集表示,q(x)也是经过BERT embedding之后产生的向量
使用DPR的预先训练的双编码器来初始化检索器并构建文档索引。这种检索器被训练来检索包含TriviaQA问题和自然问题的答案的文档。
检索器检索到的相关文档经过BERT embedding之后即非参数化知识。
(2) 生成器:seq2seq模型(使用预训练的BART-large作为生成模型),经过预训练已具备一定的参数知识的模型,将上面检索器得到的相关文档和输入一起进行处理,得到输出。
这里是将dz和qx简单拼接之后送入生成器中得到答案。
生成器使用预训练之后的BART即参数化知识。
5、实验
在下面的实验中,模型使用的外部知识库均为2100万个Wikipedia文档,每个文档包含100个词。在训练之前,首先用文档编码器获取文档的稠密向量表示,然后利用FAISS构建MIPS索引实现文档的快速检索。作者在开放域问答(Open-domain QA)、摘要式问答(Abstractive QA)、开放域问题生成(Open-domain QG)和事实验证(Fact Verification)这四类知识密集型任务上测试了不同模型。

table 2第一列是开放域问题生成,第二列是摘要式问答,第三列是事实验证
关于实验的主要结论:
开放域问答:RAG在所有四个开放域QA任务上都实现了SOTA,与REALM和T5+SSM不同的是,RAG不需要昂贵的专门“salient span mask”预训练,依靠现成的组件,就可以获得强大的效果。RAG证明,对于最先进的机器阅读性能来说,重新排序器和提取阅读器都不是必需的。此外,虽然可以直接从文档中抽取答案片段,但直接生成答案有一些额外的好处,比如有些文档并不直接包含整个答案,但包含答案的线索,这些线索就能帮助模型生成更正确的答案,而这对抽取式模型来说是做不到的。
开放域问题生成:在引入了外部知识后,RAG模型的表现明显优于BART,证明了引入外部知识的有效性。在Table 3的人工评价中,RAG生成的问题更符合事实(factual),也更具体(specific),同样证明了引入外部知识的有效性。
在摘要式问答和事实验证任务中:由于模型没有使用任务数据集提供的外部知识文档(有些问题如果不使用任务数据集提供的外部知识文档就无法回答)且没有像SOTA模型一样进行针对文本检索结果的fine-fune,RAG能取得与SOTA模型接近的结果仍然是令人印象深刻的。

另外值得注意的是,作者发现在生成实体名的第一个token之后,外部文档对生成结果的贡献再次趋于平缓。这一观察结果表明,生成器无需依赖于特定的文档就可以完成实体生成。换句话说,模型的参数知识足以完成实体生成,文档信息仅仅起到了提示和引导的作用,因此整个RAG模型主要依靠的还是参数知识,而在生成实体时非参数知识才会起到作用。
6、与REALM比较
本篇文章(2020.6)和同年2月发表的REALM之间的区别
(1) 一个是生成式的任务(RAG),一个是抽取式的任务(REALM)。抽取式的弊端就是,如果检索不到问题q相关的文档z,那么模型将无法输出正确的答案。因为REALM输出答案都默认是从文档z中抽取出来的。但是RAG就解决了这个问题,即使没有正确答案,也能根据预训练好的BART生成正确答案。
(2) REALM在预训练期间需要实时更新文档索引,这会造成很大的开销。而RAG作者保持文档编码和索引固定不变,只微调查询编码器BERTq和BART生成器。
相同点
(1) 在检索部分都使用计算向量内积的方式计算相似度得分;
(2) 都使用维基百科作为外部知识库。
7、想法
1.研究模型中的两个组件是否可以从头开始联合预训练,无论是使用类似于BART的去噪目标还是其他目标,都可能是富有成效的;
2.参数记忆 + 非参数记忆如何相互作用以及如何最有效的组合他们开辟了新的研究方向,有望应用于各种NLP任务;
3.从某种程度上讲,这种将相关文档和问题拼接进行预测结果的方式有些类似于提示学习,有没有一种可能,这些相关文档可以替代我们人类给出的提示来提升LMs的效果。