《随笔 一》
千峰教程:https://pan.baidu.com/s/1LGX4O5hDGkbLlg2GYHk4gQ 提取码pw99
包括:jave基础-进阶-高级-工具, HTML5 基础-进阶-高级-工具, web前端 基础-进阶-高级-工具 ,
python 基础-进阶-高级 -工具 大数据 基础-进阶-高级-工具 UI 基础-进阶-高级-工具
Linux 云计算 基础-进阶-高级-工具 软件测试 基础-进阶-高级-工具 Unity 游戏开发 基础-进阶-高级-工具
物联网 基础-进阶-高级-工具 区块链 基础-进阶-高级-工具 php 基础-进阶-高级-工具
查看电脑连接过的wifi密码 cmd指令: 显示所有储存的信息 :netsh wlan show profile * key=clear
显示单个信息: (1) netsh wlan show profiles
(2)netsh wlan show profile name = " wifi_name " key=clear
1, %23 是# 的URL 标识符 ;%27 是 ' 的标识符。
2, DBMS :数据库管理系统; RDBMS: 指关系型数据库管理系统。
3,sql 关键字 order by :select *from table_name order by column_name1,column_name2;
对表进行排序,以 name1 为主,name2 为辐 进行升序 排序,,加DESC 变为降序。
4, Ubuntu 更改时间/时区 命令:timedatectl set-timezone "Asia/Shanghai"
查看时间状态: timedatectl status
5,域名解析是将域名指向网站空间IP,让人们通过注册的域名可以方便地访问到网站的一种服务。IP地址是网络上标识站点的数字地址,为方便记忆,采用域名来代替IP地址标识站点地址。域名解析就是域名到IP地址的转换过程。域名的解析工作由DNS服务器完成。
6,hosts是一个没有扩展名的系统文件,可以用记事本等工具打开,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”,当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从Hosts文件中寻找对应的IP地址,一旦找到,系统会立即打开对应网页,如果没有找到,则系统会再将网址提交DNS域名解析服务器进行IP地址的解析。
需要注意的是,Hosts文件配置的映射是静态的,如果网络上的计算机更改了请及时更新IP地址,否则将不能访问。
7,X-Forwarded-For(XFF)是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的IP地址的HTTP请求头字段。通俗来说,就是浏览器访问网站的IP。
利用:X-Forwarded-For:127.0.0.1 来伪造本地IP
8,winHEX 文件头 50 4B 03 04可以得知这是一个压缩包
9,winHEX 文件头 89 50 4E 47 PE头应该是png图片
第二行的前八位 是 图片的 宽 和高 修改可以改变 图片的宽和高
10,如果你打开一个文件发现是一堆乱码,就可以猜想是不是一个压缩包,进行解压试试,
word文档本身就是一个压缩包,如果打开一个word文档发现是乱码,就尝试这解压试试
11,Binwalk是一个固件分析工具,用于协助研究人员对固件进行分析,文件提取等,功能:过滤功能,提取文件,比较功能,字符串分析,插件功能。
12,EXIF:可交换图像文件格式,是专门为数码相机的照片设定的,可以记录数码照片的属性信息和拍摄数据。Exif可以附加于JPEG、TIFF、RIFF等文件之中,为其增加有关数码相机拍摄信息的内容和索引图或图像处理软件的版本信息。Exif信息以0xFFE1作为开头标记,后两个字节表示Exif信息的长度。所以Exif信息最大为64 kB,而内部采用TIFF格式
13,Access :关系数据库管理系统 是微软把数据库引擎的图形用户界面和软件开发工具结合在一起的一个数据库管理系统
14,子网掩码(subnet mask)又叫网络掩码、地址掩码、子网络遮罩,它是一种用来指明一个IP地址的哪些位标识的是主机所在的子网,以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合IP地址一起使用。子网掩码只有一个作用,就是将某个IP地址划分成网络地址和主机地址两部分。 [1]
子网掩码是一个32位地址,用于屏蔽IP地址的一部分以区别网络标识和主机标识,并说明该IP地址是在局域网上,还是在远程网上。
15,GitHub是通过Git进行版本控制的软件源代码托管服务,世界上最大的代码存放网站和开源社区。
16,PHP 文件读取: $file = fopen(fname, moshi ) 不是以文本的形式打开,而是将文件读取并执行后的结果显示出来,除非以单个字符读取
- "r" (只读方式打开,将文件指针指向文件头)
- "r+" (读写方式打开,将文件指针指向文件头)
- "w" (写入方式打开,清除文件内容,如果文件不存在则尝试创建之)
- "w+" (读写方式打开,清除文件内容,如果文件不存在则尝试创建之)
- "a" (写入方式打开,将文件指针指向文件末尾进行写入,如果文件不存在则尝试创建之)
- "a+" (读写方式打开,通过将文件指针指向文件末尾进行写入来保存文件内容)
- "x" (创建一个新的文件并以写入方式打开,如果文件已存在则返回 FALSE 和一个错误)
- "x+" (创建一个新的文件并以读写方式打开,如果文件已存在则返回 FALSE 和一个错误)
17,PHP 中explode(分隔符,字符串) 函数 : 将字符串变量打散为 数组,依据分隔符
PHP end() 函数获取文件的后缀名
18, ./configure 是用来检测你的安装平台的目标特征的。比如它会检测你是不是有CC或GCC,并不是需要CC或GCC,它是个 shell脚本。
make 是用来编译的,它从Makefile中读取指令,然后编译。
make install是用来安装的,它也从Makefile中读取指令,安装到指定的位置
19, 用 linux 编译执行 c / c++ 用命令 vim mian.c 编译 : gcc -o 执行文件名 mian
执行 : ./ 执行文件名
20,创建文件 命令 : mkdir -m 777 filename
21, 修改文件权限 : chmod 777 filename -R 修改文件夹及其子文件夹的权限22,
22, .cdf 文件 .cdf 文件是数据文件 , 可以包含不同的文本格式的属性和多媒体元素的交互式文档的多媒体编码标准。这些多媒体元素是像图表和图形也可以与互动功能,这可以通过由CDF播放器软件提供的功能来完成集成大多可视对象。
23, 图片中木马的插入方法:打开 cmd :
copy doram.jpg/b+lubr.php/a xiaoma.jpg将lubr.php 木马插入到 doram.jpg 图片中 生成新文件 xiaoma.jpg
24,web容器 是一种服务程序,在服务器一个端口就有一个提供相应服务的程序,而这个程序就是处理从客户端发出的请求,如tomcat、apache、nginx等等。(可以理解为给编程语言提供环境)
25,服务器:www服务器或http服务器。提供web信息游览服务。它只需支持http协议、html文档格式以及url,向游览器提供服务的程序
26,IIS全称是互联网信息服务,包括FTP/FTPS、NNTP、HTTP/HTTPS、SMTP等服务。
.net Framework是基础类库,是程序运行的底层框架。
IIS是架设Web服务器用来提供网页游览服务的,属于系统环境。
一般用ASP.NET开发软件,然后靠IIS对公网提供服务。
27,Hash
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。 也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。 这个映射函数称做散列函数,存放记录的数组称做散列表。
28,
information_schema
系统数据库,记录当前数据库的数据库,表,列,用户权限等信息
SCHEMATA
储存mysql所有数据库的基本信息,包括数据库名,编码类型路径等
TABLES
储存mysql中的表信息,包括这个表是基本表还是系统表,数据库的引擎是什么,表有多少行,创建时间,最后更新时间等
COLUMNS
储存mysql中表的列信息,包括这个表的所有列以及每个列的信息,该列是表中的第几列,列的数据类型,列的编码类型,列的权限,列的注释等
29,PHP配置文件中session.save_path负责session文件的存放位置。
30,WAF:Web应用防护系统,例如安全狗就是waf的一种。waf通常以关键字判断是否为一句话木马,但是一句话木马的变形有很多种,waf根本不可能全部拦截
31,一句话木马有很多,也有些一句话木马非常的隐蔽,经典的一句话木马有:
32,.htaccess文件是运行Apache Web Server的Web服务器的配置文件,对配置和重定向Apache Web Server文件系统很有用。一般我们将.htaccess文件放置在网站的根目录,控制所在目录及所有子目录,而如果放置在子目录中,会受上级目录中.htaccess文件影响,是不起任何作用的。
.htaccess 文件有很多的功能,如:文件夹密码保护、用户自动重定向、自定义错误页面、改变你的文件扩展名、封禁特定IP地址的用户、只允许特定IP地址的用户、禁止目录列表,以及使用其他文件作为index文件
这用来重写文件解析:
SetHandler application/x-httpd-php
33,PHP move_uploaded_file() 函数
move_uploaded_file() 函数把上传的文件移动到新位置。
如果成功该函数返回 TRUE,如果失败则返回 FALSE。
move_uploaded_file(file,newloc)
| 参数 | 描述 |
|---|---|
| file | 必需。规定要移动的文件。 |
| newloc | 必需。规定文件的新位置。 |
34,move_uploaded_file会忽略掉/. 1.php/. 会被保存为1.php
35,
str_ireplace() 函数替换字符串中的一些字符(不区分大小写)。
str_ireplace(find,replace,string,count)
该函数必须遵循下列规则:
- 如果搜索的字符串是一个数组,那么它将返回一个数组。
- 如果搜索的字符串是一个数组,那么它将对数组中的每个元素进行查找和替换。
- 如果同时需要对某个数组进行查找和替换,并且需要执行替换的元素少于查找到的元素的数量,那么多余的元素将用空字符串进行替换。
- 如果是对一个数组进行查找,但只对一个字符串进行替换,那么替代字符串将对所有查找到的值起作用。
注释:该函数是不区分大小写的。请使用 str_replace() 函数执行区分大小写的搜索。
36,图片马 也可以用菜刀正常连接
37,
大概存在几个通杀情况:
1.php%aa 通杀黑名单
1.php:jpg生成1.php空文件.然后将文件名改为1.<<< 可成功上传webshell
38, __init__ (构造函数) : 初始化某个类的实例。
__call__(调用函数): 的作用是使实例能够像函数一样被调用,同时不影响实例本身的生命周期(__call__()不影响一个实例的构造和析构)。但是__call__()可以用来改变实例的内部成员的值。
实例: 他们两个的调用方式不同所以不会引起冲突
class X(object):
def __init__(self, a, b, range):
self.a = a
self.b = b
self.range = range
print("调用__init__构造函数")
def __call__(self, a, b):
self.a = a
self.b = b
print("调用__call__函数:",end="")
print(' __call__ with ({}, {})'.format(self.a, self.b))
def __del__(self ):
print("调用析构函数")
xInstance = X(1, 2, 3) #调用构造函数__init__
xInstance(1,2) # 调用函数__call__
输出结果:
调用__init__构造函数
调用__call__函数: __call__ with (1, 2)
调用析构函数39,在python 面向对象中 父类的方法被重写 时 主函数 调用 父类被重写的方法 的方法为 :
超类 super.(父类名,实例名). 方法名()
或者 可以用__class__ 去指定 类对象
比如 person.__class__ = A (这里A为父类名)
person. run() #这样就可以调用被重写的方法了
单下划线开始的 代表保护成员 只有类对象和子类对象自己能访问到这些变量
"双下划线" 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据
以双下划线开头和结尾的(__foo__)代表python里特殊方法专用的标识,如 __init__()代表类的构造函数
发现一个Python 与 c ++ 不同的地方: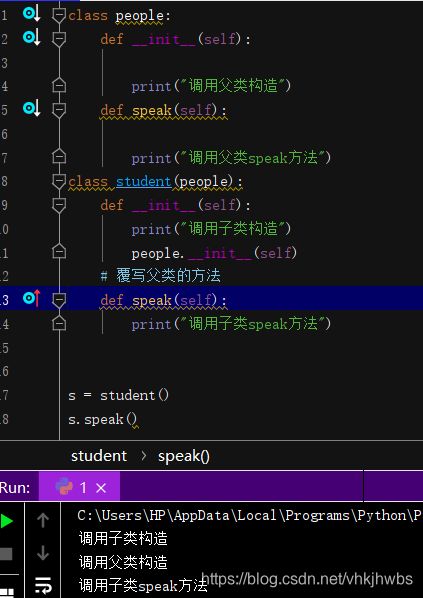
这个是正常的派生类,子类的构造函数的同时也调用了父类的构造函数
但 从输出可以看出来 在定义子类对象时是先调用的 子类的构造函数 后调用的父类的构造 (这点与c++不同)
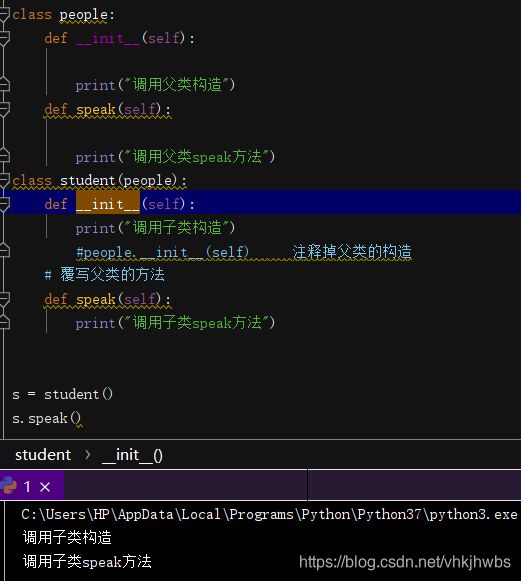
这是注释掉 在子类构造函数中的 父类构造函数
输出 发现 竟然没有 调用父类的构造函数
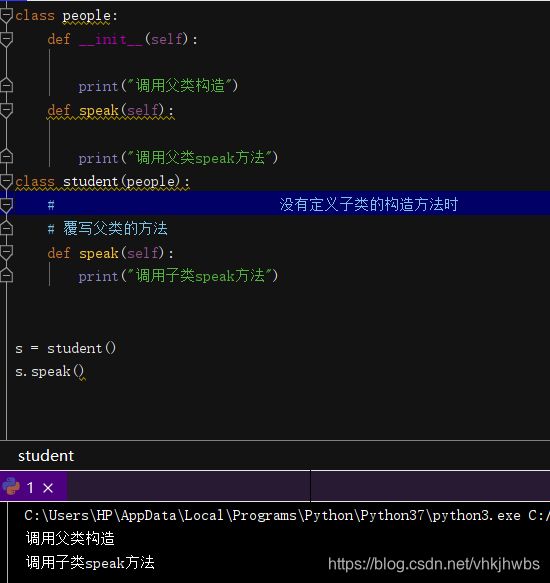
在没有定义子类构造函数的情况下
竟然自动调用了 父类的构造函数
似乎可以得出结论 在定义子类对象时 只会自动调用一个 __init__()函数 且 子类的优先于父类的构造
当子类 没有 定义__init__()函数时 就自动调用 父类的
40,
extractvalue()
extractvalue() :对XML文档进行查询的函数
其实就是相当于我们熟悉的HTML文件中用
语法:extractvalue(目标xml文档,xml路径) extractvalue()能查询字符串的最大长度为32
第二个参数 xml中的位置是可操作的地方,xml文档中查找字符位置是用 /xxx/xxx/xxx/…这种格式,如果我们写入其他格式,就会报错,并且会返回我们写入的非法格式内容,而这个非法的内容就是我们想要查询的内容。
正常查询 第二个参数的位置格式 为 /xxx/xx/xx/xx ,即使查询不到也不会报错
updatexml()
updatexml()函数与extractvalue()类似,是更新xml文档的函数。
语法updatexml(目标xml文档,xml路径,更新的内容)
select username from security.user where id=1 and (updatexml(‘anything’,’/xx/xx’,’anything’))
41,
三种报错注入:
(1). 通过floor报错
and (select 1 from (select count(*),concat((payload),floor (rand(0)*2))x from information_schema.tables group by x)a)
其中payload为你要插入的SQL语句
需要注意的是该语句将 输出字符长度限制为64个字符
(2). 通过updatexml报错
and updatexml(1,payload,1)
同样该语句对输出的字符长度也做了限制,其最长输出32位
并且该语句对payload的返回类型也做了限制,只有在payload返回的不是xml格式才会生效
(3). 通过ExtractValue报错
and extractvalue(1, payload)
输出字符有长度限制,最长32位。
payload即我们要输入的sql查询语句
42,win 环境下 切换python 2 和3 命令 : py -2 py -3
PHP 序列化和反序列化:
43, file_put_contents (生成的文件名,字符串) 将一个字符串写入文件
和依次调用 fopen(),fwrite() 以及 fclose() 功能一样
44,
序列化(串行化):是将变量转换为可保存或传输的字符串的过程;
反序列化(反串行化):就是在适当的时候把这个字符串再转化成原来的变量使用。
这两个过程结合起来,可以轻松地存储和传输数据,使程序更具维护性。
常见的php系列化和反系列化方式主要有:serialize,unserialize;json_encode,json_decode
45,gzcompress($data, level)此函数使用zlib 数据格式压缩给定的字符串,这是不一样gzip压缩,它包括一些报头数据
data
要压缩的数据。
level
压缩程度。可以给出为0表示无压缩,最高压缩为9。
如果使用-1,则使用zlib库的默认压缩,即6。
46,
1. serialize和unserialize函数
这两个是序列化和反序列化PHP中数据的常用函数。
2. json_encode 和 json_decode
使用JSON格式序列化和反序列化是一个不错的选择:
- 使用json_encode和json_decode格式输出要serialize和unserialize格式快得多。
- JSON格式是可读的。
- JSON格式比serialize返回数据结果小。
- JSON格式是开放的、可移植的。其他语言也可以使用它
3. var_export 和 eval
var_export 函数把变量作为一个字符串输出;eval把字符串当成PHP代码来执行,反序列化得到最初变量的内容。
4. wddx_serialize_value 和 wddx deserialize
wddx_serialize_value函数可以序列化数组变量,并以XML字符串形式输出
47,file_put_contents() 函数把一个字符串写入文件中
file_get_contents() 把整个文件读入一个字符串中。
该函数是用于把文件的内容读入到一个字符串中的首选方法
48, 序列化生成字符串时:对象私有化成员会自动添加了类名,以区分他们是Private 变量;如果是Protected 变量则会添加* 号。并且前缀添加空字节
49,
-
public string __toString:用于一个类被当成字符串输出时调用本函数(5.2以前只针对ehco ,print,5.2后针对所有字符串情况)
-
public array __sleep:serialize() 函数会检查是否存在魔术方法 sleep()。如果存在,该方法会先被调用,然后才执行序列化操作。此功能可以用于清理对象,并返回一个包含对象中所有应被序列化的变量名称的数组。如果该方法未返回任何内容,则 NULL 被序列化,并产生一个 E_NOTICE 级别的错误(不会打断脚本执行)。
-
public void __wakeup:unserialize() 函数会检查是否存在魔法方法 wakeup()。如果存在,则会先调用 wakeup 方法,预先准备对象需要的资源。wakeup() 经常用在反序列化操作中,例如重新建立数据库连接,或执行其它初始化操作。
-
__call:在对象中调用一个不可访问方法时被调用
-
__invoke() 当脚本尝试将对象调用为函数时,调用__invoke()方法。+
50,
反序列化漏洞
由前面可以看出,当传给 un
serialize() 的参数可控时,我们可以通过传入一个精心构造的序列化字符串,从而控制对象内部的变量甚至是函数。
由前可以看到,unserialize()后会导致__wakeup() 或__destruct()的直接调用,中间无需其他过程。因此最理想的情况就是一些漏洞/危害代码在__wakeup() 或__destruct()中,从而当我们控制序列化字符串时可以去直接触发它们
51,
__wakeup() //使用unserialize时触发
__sleep() //使用serialize时触发
__destruct() //对象被销毁时触发
__call() //在对象上下文中调用不可访问的方法时触发
__callStatic() //在静态上下文中调用不可访问的方法时触发
__get() //用于从不可访问的属性读取数据
__set() //用于将数据写入不可访问的属性
__isset() //在不可访问的属性上调用isset()或empty()触发
__unset() //在不可访问的属性上使用unset()时触发
__toString() //把类当作字符串使用时触发
__invoke() //当脚本尝试将对象调用为函数时触发52,
成也布尔,败也布尔‘,布尔类型的true跟任意字符串在‘==’下都成立
53,
var_dump() 函数用于输出变量的相关信息。
函数显示关于一个或多个表达式的结构信息,包括表达式的类型与值。数组将递归展开值,通过缩进显示其结构
var_export( , ) 此函数返回关于传递给该函数的变量的结构信息,它和 var_dump() 类似,不同的是其返回的表示是合法的 PHP 代码 . 您可以通过将函数的第二个参数设置为 TRUE,从而返回变量的表示
54, eval ( string $code ) : mixed
把字符串 code 作为PHP代码执行。
函数eval()语言结构是 非常危险的, 因为它允许执行任意 PHP 代码。 它这样用是很危险的。 如果您仔细的确认过,除了使用此结构以外 别无方法, 请多加注意,不要允许传入任何由用户 提供的、未经完整验证过的数据
55, file_exists ( string $filename ) : bool
检查文件或目录是否存在。
56, feof ( resource $handle ) : bool
测试文件指针是否到了文件结束的位。
57,phar//: PHAR(PHP归档)文件是一种打包格式,通过将许多PHP代码文件和其他资源(例如图像,样式表等)捆绑到一个归档文件中来实现应用程序和库的分发。 PHAR文件可以是三种格式之一:tar和ZIP(它们与各自的工具相兼容),以及自定义的PHAR格式
58,die() 函数输出一条消息,并退出当前脚本。 该函数是 exit() 函数的别名。
59,requests 库其实只有一个方法 request ,其他的方法(get , post, head, put, patch,delect)都是调用的request 方法
60,平行遍历必须再同一个父类标签下
61,(1)字符串中出现 很多%,或者出现%23,%20 等 都可以尝试 url 解码
(2)字符串的结尾出现== 时,可以尝试 base 64 解码
(3)字符串中出现大量数字时 ,可以尝试 16进制转字符 解码
(4)
62,
stripos(字符串a,字符串b) 函数查找字符串b在字符串a中第一次出现的位置(不区分大小写)。
file_get_contents 将整个文件读入一个字符串
strlen() 函数返回字符串的长度
substr() 函数返回字符串的一部分。 substr(string,start,length) ,length参数可选。如 substr($b,0,1) 就是在参数b里面 ,从0开始返回1个长度的字符串
eregi() — 不区分大小写的正则表达式匹配,本函数和 ereg() 完全相同,只除了在匹配字母字符时忽略大小写的区别。
63,preg_match() 正则表达的匹配函数,会在给定字符串中全局匹配
64,trim(字符串,字符) 移除字符串两侧的空白字符或其他预定义相匹配的字符(可以是正则匹配)
例如:
";
echo trim($str,"Hed!");
?>
执行结果:
Hello World!
llo Worl65,Python :preg_match(正则表达式,被匹配的字符串,变量):
被匹配到的字符串被放在变量中,返回 pattern 的匹配次数。 它的值将是 0 次(不匹配)或 1 次,因为 preg_match() 在第一次匹配后 将会停止搜索。preg_match_all() 不同于此,它会一直搜索subject 直到到达结尾。 如果发生错误preg_match()返回 FALSE。
$IM= preg_match("/key.*key.{4,7}key:\/.\/(.*key)[a-z][[:punct:]]/i", trim($_GET["id"]), $match);
. 匹配除 "\n" 之外的任何单个字符
* 匹配它前面的表达式0次或多次,等价于{0,}
{4,7} 最少匹配 4 次且最多匹配 7 次,结合前面的 . 也就是匹配 4 到 7 个任意字符
\/ 匹配 / ,这里的 \ 是为了转义
[a-z] 匹配所有小写字母
[:punct:] 匹配任何标点符号
\i 表示不分大小写
\b 标记一个单词的边界
\B 非单词边界
? 匹配0个或1个字符
$ 为匹配字符结束的位置
+ 匹配1 个或多个字符
\f 匹配一个换页符
\s 匹 配任何空白字符,包括空格、制表符、换页符等等
\S 匹配任何非空白字符
\r 匹配一个回车符
() 标记一个子表达式的开始和结束位置
[ 标记一个中括号表达式的开始
| 指明两项之间的一个选择
{n} n 是一个非负整数。匹配确定的 n 次
{n,m} 匹配n至m次
g 正则表达式后面的全局标记 g 指定将该表达式应用到输入字符串中能够查找到的尽可能多的匹配
\1 指定第一个子匹配项
\d 匹配一个数字字符
\B 匹配一个非数字字符
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]' |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用 |
模式修正符
在最后一个细线‘/’之后使用,如 /php/i
| 模式修正符 | 含义 |
|---|---|
| i | 不区分大小写 |
| m | 将字符视为多行 |
| s | 将字符串视为单行,换行符作为普通的字符 |
| x | 忽略空白 |
| u | 取消贪婪模式,等同于在数量符之后添加一个问号,比如 .*? |
[0-9\.\-] 匹配所有的数字,句号和减号
[ \f\r\t\n] 匹配所有的白字符-
. 匹配任意单个字符
-
[] 匹配中括号内指定范围的任意单个字符
-
[^] 匹配中括号指定范围外的任意单个字符
-
[:alnum:] 匹配字母和数字
-
[:alpha:] 匹配任何英文
-
[:lower:] 小写英文字母
-
[:upper:] 大写英文字母
-
[:blank:] 空白字符(空格和字表符)
-
[:space:] 水平和垂直的空白字符(范围比blank的广)
-
[:cntrl:] 不可打印的控制字符(退格、删除、警铃等)
-
[:digit:] 十进制数字
-
[:xdigit:] 十六进制数字
-
[:graph:] 可打印的非空白字符
-
[:print:] 可打印的字符
-
[:punct:] 标点符号
66,
strcmp($d,$ds),比较两个字符串是否相等,漏洞:在传入的参数类型不是字符串时,会报错,但是却判定相等!66,md5($ss,ture/false)漏洞:
ture :为16位,false:为32位
首先是md5()函数漏洞
第一种
$_GET['a'] != $_GET['b']
&&
MD5($_GET['a']) == MD5($_GET['b'])
要让上面的等式成立,a和b的值不能相等,但是md5后的值相等。(php弱类型)因为是 == 比较,只判断值是否相等,不判断类型是否相同。如果类型不同先转换为相同类型再进行比较而PHP在处理哈希字符串时后,会把0E开头的哈希值解释为0。所以如果两个值通过md5后值都已0E开头,就会相等。
那么这些值有哪些呢?
QNKCDZO
0e830400451993494058024219903391
s878926199a
0e545993274517709034328855841020
s155964671a
0e342768416822451524974117254469
s214587387a
0e848240448830537924465865611904
s214587387a
0e848240448830537924465865611904
s878926199a
0e545993274517709034328855841020
第二种
$_POST['a1']!==$_POST['a2']
&&
md5($_POST['a1'])===md5($_POST['a2'])=== 不仅比较值相等还会要求类型比较
但是
md5无法处理数组!所以构建数组就可以了
第三种
(string)$_POST['a1']!==(string)$_POST['a2']
&&
md5($_POST['a1'])===md5($_POST['a2'])
}
这里比较的是字符串
那么md5值相同的字符串有哪些呢?
#仔细看,数值均不同
#强网杯某大牛wp
$Param1="\x4d\xc9\x68\xff\x0e\xe3\x5c\x20\x95\x72\xd4\x77\x7b\x72\x15\x87\xd3\x6f\xa7\xb2\x1b\xdc\x56\xb7\x4a\x3d\xc0\x78\x3e\x7b\x95\x18\xaf\xbf\xa2\x00\xa8\x28\x4b\xf3\x6e\x8e\x4b\x55\xb3\x5f\x42\x75\x93\xd8\x49\x67\x6d\xa0\xd1\x55\x5d\x83\x60\xfb\x5f\x07\xfe\xa2";
$Param2="\x4d\xc9\x68\xff\x0e\xe3\x5c\x20\x95\x72\xd4\x77\x7b\x72\x15\x87\xd3\x6f\xa7\xb2\x1b\xdc\x56\xb7\x4a\x3d\xc0\x78\x3e\x7b\x95\x18\xaf\xbf\xa2\x02\xa8\x28\x4b\xf3\x6e\x8e\x4b\x55\xb3\x5f\x42\x75\x93\xd8\x49\x67\x6d\xa0\xd1\xd5\x5d\x83\x60\xfb\x5f\x07\xfe\xa2";
#008ee33a9d58b51cfeb425b0959121c9
#知乎Belleve
$data1="\xd1\x31\xdd\x02\xc5\xe6\xee\xc4\x69\x3d\x9a\x06\x98\xaf\xf9\x5c\x2f\xca\xb5\x07\x12\x46\x7e\xab\x40\x04\x58\x3e\xb8\xfb\x7f\x89\x55\xad\x34\x06\x09\xf4\xb3\x02\x83\xe4\x88\x83\x25\xf1\x41\x5a\x08\x51\x25\xe8\xf7\xcd\xc9\x9f\xd9\x1d\xbd\x72\x80\x37\x3c\x5b\xd8\x82\x3e\x31\x56\x34\x8f\x5b\xae\x6d\xac\xd4\x36\xc9\x19\xc6\xdd\x53\xe2\x34\x87\xda\x03\xfd\x02\x39\x63\x06\xd2\x48\xcd\xa0\xe9\x9f\x33\x42\x0f\x57\x7e\xe8\xce\x54\xb6\x70\x80\x28\x0d\x1e\xc6\x98\x21\xbc\xb6\xa8\x83\x93\x96\xf9\x65\xab\x6f\xf7\x2a\x70";
$data2="\xd1\x31\xdd\x02\xc5\xe6\xee\xc4\x69\x3d\x9a\x06\x98\xaf\xf9\x5c\x2f\xca\xb5\x87\x12\x46\x7e\xab\x40\x04\x58\x3e\xb8\xfb\x7f\x89\x55\xad\x34\x06\x09\xf4\xb3\x02\x83\xe4\x88\x83\x25\x71\x41\x5a\x08\x51\x25\xe8\xf7\xcd\xc9\x9f\xd9\x1d\xbd\xf2\x80\x37\x3c\x5b\xd8\x82\x3e\x31\x56\x34\x8f\x5b\xae\x6d\xac\xd4\x36\xc9\x19\xc6\xdd\x53\xe2\xb4\x87\xda\x03\xfd\x02\x39\x63\x06\xd2\x48\xcd\xa0\xe9\x9f\x33\x42\x0f\x57\x7e\xe8\xce\x54\xb6\x70\x80\xa8\x0d\x1e\xc6\x98\x21\xbc\xb6\xa8\x83\x93\x96\xf9\x65\x2b\x6f\xf7\x2a\x70";
#79054025255fb1a26e4bc422aef54eb4
新的加密函数
sha1()漏洞:
sha1()也不能处理数组,处理数组会返回false,
67,
mysqli_query(connection,query,resultmode)
| connection | 必需。规定要使用的 MySQL 连接。 |
| query | 必需,规定查询字符串。 |
| resultmode | 可选。一个常量 |
68,HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器基此可以获得一些信息用于处理。(这里可以通过修改referer来设置虚假浏览器)

这里的referer:是自己手动添加的 bugku中的一个题
69,
当题目的源代码中既有get【】传参 又有post【】传参时,get传入的参数就直接在url中加入,post传入的参数就用harkber去传
70,
extract() 函数从数组中将变量导入到当前的符号表。
该函数使用数组键名作为变量名,使用数组键值作为变量值。针对数组中的每个元素,将在当前符号表中创建对应的一个变量。
71,密码:
| 密码: | 密文: | 原文: | 备注: |
| 栅栏密码: | fg2ivyo}l{2s3_o@aw__rcl@ | flag{w22_is_v3ry_cool} | 所谓栅栏密码,就是把要加密的明文分成N个一组,然后把每组的第1个字连起来,形成一段无规律的话。 不过栅栏密码本身有一个潜规则,就是组成栅栏的字母一般不会太多。(一般不超过30个,也就是一、两句话) (用一定的规则把原文打乱然后用@连接)
|
| md5 | 18414996c5377f5f4419a40eba901789 | flag{hello_world!} | 一般为32位 由数字和小写字母组成 |
| base64 | TVNEUzQ1NkFTRDEyM3p6= | MSDS456ASD123zz | base64 的空格被加密成= |
| base 16 | 666C61677B6D795F6E616D655F482121487D | flag{my_name_H!!H} | 由数字和大写字母组成 |
| unicode | \u0066\u006c\u0061\u0067\u007b\u0069\u005f\u0077 \u0069\u006c\u006c\u005f\u006b\u0069\ u006c\u006c\u005f\u0079\u006f\u0075 \u0021\u007d
|
flag{i_will_kill_you!} | 万国码:每一字符都用一个5位字符编码表示,并用\分割 |
72:grep:
grep命令(Global Regular Expression Print)是 Linux系统中一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来 。
grep 是linux中最为常用的三大文本(awk,sed,grep)处理工具之一
搜索的字符串可以直接用正则表达的形式表示
grep 'oo' 12.xt 搜索oo
grep -n 'oo' 12.txt 显示oo所在的行和行号
grep -v 'oo' 12.txt 查看非oo的字符
grep -i 'oo' 12.txt 忽略大小写
grep -o 'oo' 12.txt 只显示匹配到的字符串
grep -c 'oo' 12.txt 统计匹配到的行数
下面还有一些有意思的命令行参数:
grep -i pattern files :不区分大小写地搜索。默认情况区分大小写,
grep -l pattern files :只列出匹配的文件名,
grep -L pattern files :列出不匹配的文件名,
grep -w pattern files :只匹配整个单词,而不是字符串的一部分(如匹配’magic’,而不是’magical’),
grep -C number pattern files :匹配的上下文分别显示[number]行,
grep pattern1 | pattern2 files :显示匹配 pattern1 或 pattern2 的行,
grep pattern1 files | grep pattern2 :显示既匹配 pattern1 又匹配 pattern2 的行。
72
在linux下打不开,可能是宽高有问题:
扔进winhex,文件头数据块IHDR(headerchunk):

一共7个块:分别是宽、高、图像深度、颜色类型、压缩方法、滤波器方法、隔行扫描方法(1隔行,0非隔行)
73
1常用压缩解压缩命令:
1.命令:gzip (压缩文件)
压缩文件后缀.gz
ps: gzip test.txt 结果:生成文件test.txt.gz,原文件test.txt消失。
注意:只能压缩文件,不能压缩目录,压缩后不保留 原始文件,压缩比大概1/5
解压命令:gunzip
2.命令:tar (打包压缩目录) 严格意义上来说此命令为“打包”命令,将目录打包成一个*.tar文件
语法:tar 选项 压缩后文件名 目录
压缩文件后缀:*.tar.gz
选项:[-zcvf] -c 打包
-v 显示详细信息
-f 指定后文件名
-z 打包同时压缩
ps:#mkdir Japan 生成Japan目录
#tar -zcvf Japan.tar.gz Japan 生成Japan.tar.gz压缩文件
解压命令:tar [选项] 压缩文件.tar.gz
[-zxvf] -x 解包
-v 显示详细信息
-f 指定后文件名
-z 解压缩
ps:tar -zxvf Japan.tat.gz
3.命令:zip (压缩文件或目录)
压缩文件后缀 :*.zip
语法:zip [选项] 压缩后文件名 文件或目录
-r 压缩目录
ps:#zip -r Japan.zip Japan 压缩目录Japan,生成Japan.zip文件。
#zip test.txt.zip test.txt 压缩文件test.txt,生成test.txt.zip文件,保留原始文件
解压命令:unzip 文件名
注意:压缩后保留原始文件,压缩比不如gzip.
4.命令:bzip2 (gzip的升级版,压缩比惊人)
压缩文件后缀:*.bz2
语法:bzip2 [选项] 文件
-k 压缩后保留原始文件
ps: bzip2 -k test.txt 生成test.txt.bz2文件,原始文件test.txt保留着。
打包压缩 tar -cjvf 打包压缩后文件名 目录
解包解压 tar -xjvf 文件
2 查找文件内容 grep 命令:二、grep命令
基本格式:find expression
1.主要参数
[options]主要参数:
-c:只输出匹配行的计数。
-i:不区分大小写
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-n:显示匹配行及行号。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
pattern正则表达式主要参数:
\: 忽略正则表达式中特殊字符的原有含义。
^:匹配正则表达式的开始行。
$: 匹配正则表达式的结束行。
\<:从匹配正则表达 式的行开始。
\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求 。
[ - ]:范围,如[A-Z],即A、B、C一直到Z都符合要求 。
.:所有的单个字符。
* :有字符,长度可以为0。
(1) 用 gerp ‘flag’ flag.bin -a 进行查找
74 binwalk 常用命令:
(1)简单列出文件:
$ binwalk flag.bin(2)提取文件:
$ binwalk -e flag.bin(3)递归提取: (很多次,提取的数据可能需要进一步binwalk的分析,-M选项将提取的文件8层递归,且忽略外部提取工具可以创建任何目录)
$ binwalk -Me flag.bin(4)比较功能: ( Binwalk可以生成一个或多个文件的十六进制转储和差别。在文件当中相同字节的是绿色显示,不同的是红色显示,蓝色表示只是有些文件当中的不同部分)
$ binwalk -w flag.bin flag(1).bin(5)功能转换: ( binwalk使用 -C 选项来完成多个不用文件类型转换; 通常最好是使用-l选项来限制这种扫描:)
$ binwalk -l 32 -C flag.bin(6)包含过滤器:
( -y选项仅包括指定的搜索文本匹配的结果。搜索字符串(文本)应当使用小写,包括正则表达式,并且可以指定多个-Y选项。 下列搜索结果只包含文本“文件系统”中搜索出来的结果。(也就说使用了 filesystem的Y选项的话结果中只包含文本字符结果))
$ binwalk -y filesystem firmware.bin(7)排除过滤器:
( -x选项是排除搜索结果中的指定符合规则的文本(或者字符串)。 搜索字符串(文本)应当使用小写,包括正则表达式,并且可以指定多个-X选项。 下列例子中搜索时将排除“jffs2”字符串:)
$ binwalk -x jffs2 firmware.bin(8) 高级过滤器
(可以将包含和排除过滤两功能结合使用:
例子:下列搜索结果即包含文本“文件系统”中搜索出来的结果又排除jffs2字符串结果。)
$ binwalk -y filesystem -x jffs2 firmware.bin(9)扫描zlib压缩包
$ binwalk --enable-plugin=zlib firmware.bin(10)搜索字符串:
$ binwalk -R 'key' flag.bin75,
用 rm -rf 删除文件夹
rmdir 只能用来删除 空文件夹
76,JPEG (jpg),文件头:FFD8FFE0或FFD8FFE1或FFD8FFE8
77, PK 开头的文件是压缩包
78,明文攻击是一种较为高效的攻击手段,大致原理是当你不知道一个zip的密码,但是你有zip中的一个已知文件(文件大小要大于12Byte)或者已经通过其他手段知道zip加密文件中的某些内容时,因为同一个zip压缩包里的所有文件都是使用同一个加密密钥来加密的,所以可以用已知文件来找加密密钥,利用密钥来解锁其他加密文件
79
| 文件类型: | 文件头信息: | 文件尾信息: |
|---|---|---|
| JPEG (jpg) | FFD8FFE0或FFD8FFE1或FFD8FFE8 | FF |
| PNG (png) | 89 50 4E 47 | 00 3B |
| 25 50 44 46 2D 31 2E | ||
| Windows Password (pwl) | E3 82 85 96 | |
| RAR | 52 61 72 21 | |
| ZIP Archive (zip) | 50 4B 03 04 | 50 4B |
| 压缩包 | PK |
|
| Word/Excel (xls.or.doc) | D0 CF 11 E0 | |
| HTML (html) | 68 74 6D 6C 3E | |
| MIDI (mid) | 4D 54 68 64 | |
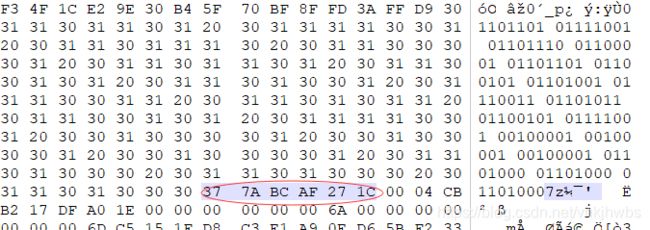
| 7z | 37 7A BC AF 27 1C | |
| GIF | 47 49 46 38 39 61 | |
| bmp | 42 4D 76 68 |
128个常见的文件头信息对照表: https://blog.csdn.net/ccj2020/article/details/87603903
80,chr() Python内置函数 (括号里可以是10进制,或16进制) 返回对应的ASCLL 码
int (i,base) i 为进制字符串,base 为对应的进制,返回对应的十进制
81,一定要注意 提示信息的 周围 还有没有 其他信息 比如文件头被修改的 压缩文件等
把文件头修改正确之后才能审查出来 压缩文件
82:正则表达匹配:
中文字符:
表达一: [\u4e00-\u9fa5]
表达二:[\x{4e00}-\x{9fa5}]
匹配 emali 地址:
function valid_email($address) {
if (ereg('^[a-zA-Z0-9_\.\-]+@[a-zA-Z0-9\-]+\.[a-zA-Z0-9\-\.]+$', $address)) {
return true;
} else {
return false;
}
}
function valid_email($address) {
if (preg_match('^[a-zA-Z0-9_\.\-]+@[a-zA-Z0-9\-]+\.[a-zA-Z0-9\-\.]+$^', $address)) {
return true;
} else {
return false;
}
}匹配国内电话号码:
\d{3}-\d{8}|\d{4}-\d{7}匹配IP地址:
//python
re.match(r'((([0-9]?\d)|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}(([0-9]?\d)|(1\d{2})|(2[0-4]\d)|(25[0-5]))',sd)匹配URL:
//调用 fopen()函数检查能否打开该 URL,来判断该URL是否有效
//匹配 URL的表达有很多,很乱,不如直接看是否能打开,能打开就是 有效的,不能打开的就是无效的83:php中也可以中 echo ,print,printf, 以及sprintf()
84: php 常用的读取文件函数 file()次函数读取文件并把文件的每一行做为数组的一个元素存入数组里面
");
}
?>85,id 和 class 选择器:
(1)HTML元素以id属性来设置id选择器,CSS 中 id 选择器以 "#" 来定义
(2)class 选择器有别于id选择器,class可以在多个元素中使用。class 选择器在HTML中以class属性表示, 在 CSS 中,类选择器以一个点"."号显示
86,外部式样,使用方法:
87,外部样式表可以在任何文本编辑器中进行编辑。文件不能包含任何的 html 标签。样式表应该以 .css 扩展名进行保存
88, 不要在属性值与单位之间留有空格
89,多重式样:css的式样可以重叠(继承),如:外部式样表和内部式样表可以同时定义一个属性,
优先级: 内联式样 > 内部式样 > 外部式样 > 浏览器默认式样
90,PHP中strrchr() 函数查找字符串在另一个字符串中最后一次出现的位置,并返回从该位置到字符串结尾的所有字符
91,PHP中 对文件操作的函数 如 file_get_concents(), file_put_concents() ,fopen() 的路径 中 win环境下可以用\\ 也可以用 /
Liunx 只能用 / ,尽量用 /
92 OSI参考模型 (开放系统互联参考模型):七层,
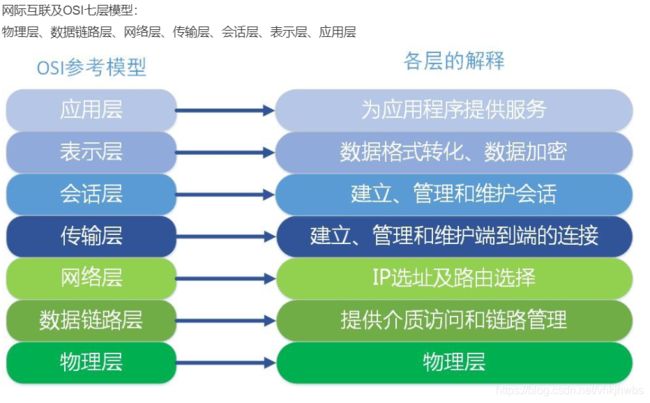
面向用户 面向数据传输
七、应用层:为应用软件提供接口,是应用程序能够使用网络服务
常见应用层协议: http(80)、发图片(20/21)、stmp(25)、pop3(110)、Telnet(23)、dns(53) 等
六、表示层: 数据的格式化如:数据的编码解码、加密解密、压缩解压缩
常见的表示层 协议:ASCII, JPEG. PNG, MP3. WAV, AVI,
五、会话层:向两个实体的表示层提供建立和使用连接的方法。将不同实体之间的表示层的连接称为会话。因此会话层的任务就 是组织和协调两个会话进程之间的通信,并对数据交换进行管理,(简单的说就是建立会话)
功能包括:会话管理、会话流量控制、寻址、出错控制
常见会话层协议:NFS, SQL, ASP, PHP, JSP, RSVP(资源源预留协议), windows
四、传输层:该层是通信子网和资源子网的接口和桥梁,起到承上启下的作用,
该层的主要任务是:向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输
常见的协议:TCP/IP中的TCP协议、Novell网络中的SPX协议和微软的NetBIOS/NetBEUI协议
三、网络层:它是OSI参考模型中最复杂的一层,也是通信子网的最高一层。它在下两层的基础上向资源子网提供服务
其主要任务是:通过路由选择算法,为报文或分组通过通信子网选择最适当的路径。该层控制数据链路层与传输层
之间的信息转发,建立、维持和终止网络的连接。具体地说,数据链路层的数据在这一层被转换为数据包,然后
通过路径选择、分段组合、顺序、进/出路由等控制,将信息从一个网络设备传送到另一个网络设备
典型协议:IP,IPX,ICMP,ARP(IP->MAC),IARP
二、数据链路层:负责建立和管理节点间的链路。层通常又被分为介质访问控制(MAC)和逻辑链路控制(LLC)两个子层 MAC子层的主要任务是解决共享型网络中多用户对信道竞争的问题,完成网络介质的访问控制;
LLC子层的主要任务是建立和维护网络连接,执行差错校验、流量控制和链路控制。
该层的主要功能是:通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。
典型协议:以太网,帧中继(古董级VPN)
一、物理层:是参考模型的最低层,也是OSI模型的第一层
主要功能是:利用传输介质为数据链路层提供物理连接,实现比特流的透明传输。
物理层的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使 其 上面的数据链路层不必考虑网络的具体传输介质是什么。
93、
什么是 TCP/IP?
TCP/IP 是供已连接因特网的计算机进行通信的通信协议。
TCP/IP 指传输控制协议/网际协议(Transmission Control Protocol / Internet Protocol)。
TCP/IP 定义了电子设备(比如计算机)如何连入因特网,以及数据如何在它们之间传输的标准。
94,TCP/IP 是基于 TCP 和 IP 这两个最初的协议之上的不同的通信协议的大集合
TCP 负责两个应用程序的通信,它会发送一个请求到确切的地址,在双方“握手”之后,建立一个 全双工 通信
IP 负责计算机之间的通信,TCP将数据分割为独立的小包 ,IP并通过 TCP建立的通信 ,将每个包 路由到它的目的地
他们协同工作
95,TCP/IP 使用 32 个比特(32比特=4字节)或者 4 组 0 到 255 之间的数字来为计算机编址, 32个比特分为4组,每组8个比特,所以最大值是 255
IPv6 地址的 128 位(16 个字节)写成 8 个 16 位的无符号整数,每个整数用 4 个十六进制位表示,这些数之间用冒号(:)分开,例如:
本地链接 IPv6 地址. . . . . . . . : fe80::ecc0:d78c:e6b2:6291%16
IPv4 地址 . . . . . . . . . . . . : 192.168.199.116
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : 192.168.199.1SMTP - 简单邮件传输协议
POP - 邮局协议
IMAP - 因特网消息访问协议
96,
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。HTTP默认端口号为80,但是你也可以改为8080或者其他端口
HTTP是一个基于TCP/IP通信协议来传递数据,浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。
Web服务器有:Apache服务器,IIS服务器(Internet Information Services)等。
97,
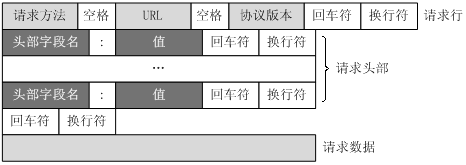
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
服务器响应消息
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文
98,HTTP 请求方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | get | 请求指定的页面信息,并返回实体主体。 |
| 2 | head | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | post | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | put | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | delete | 请求服务器删除指定的页面。 |
| 6 | connect | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | options | 允许客户端查看服务器的性能。 |
| 8 | trace | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | patch | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
99,
常见的HTTP状态码:
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
100,Content-Type,内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件, Servlet默认为text/plain,但通常需要显式地指定为text/html