30天精通Python(数据分析篇)——第2天:环境搭建之Windows下安装Anaconda及使用介绍
目录
- 一、为什么需要安装Anaconda?
- 二、下载Anaconda
-
- 2.1 从百度网盘链接中获取Anaconda安装包
- 2.2 从官网下载Anaconda安装包
- 三、安装Anaconda
- 四、Anaconda的使用
-
- 4.1 利用 Conda 管理 Python 环境
- 4.2 利用 Conda 管理 Python 包
- 4.3 文学式开发工具 Jupyter Notebook
- 4.4 Jupyter Notebook 中的单元格
- 4.5 Jupyter Notebook 中的命令模式与编辑模式键
- 4.6 科学计算工具 IPython
Anaconda 是适合数据分析的 Python 开发环境,在全球有超过1100万用户(网上看到的数据),它是一个开源的 Python 发行版本,其中包含了 conda(包管理和环境管理)、Python 等180多个科学包及其依赖项,本文为大家进行详细介绍。
一、为什么需要安装Anaconda?
相信一些具有 Python 基础的读者,Python 开发环境已经搭建好了,也学会了编写简单的程序。那我们为什么还要安装 Anaconda、学习 Anaconda 呢?原因有以下几点:
(1) 当我们使用 Python 一段时间后,便会遇到以下问题:
- 场景一:编写代码的过程经常出现提示缺少模块或版本的错误。
- 场景二:某程序员在 A 项目中用了 Python 2,而新项目 B 要求使用 Python 3,但同时安装两个版本的 Python 可能会造成许多混乱和错误。此时就需要为不同的项目建立不同的运行环境。
- 场景三:项目中可能会用到不同版本的包。例如,不同版本的 Pandas,那么不可能同时安装两个 Pandas 版本,此时需要为每个 Pandas 版本创建一个环境,然后使得项目可以在对应的环境中工作 (在工作中深有体会)。
针对以上3种情况,Anaconda 就可以充分发挥它的作用了。
(2) Anaconda 附带了常用的科学数据包,它附带了 conda、Python 和 180 多个科学包及其依赖项,因此我们可以立即开始处理数据。
(3) 管理包。在数据分析中,可能会用到很多第三方的包,Anaconda 附带的 conda(包管理器) 可以很好地帮助用户在计算机上安装和管理这些包,包括安装、卸载和更新包。
二、下载Anaconda
Anaconda 的下载文件比较大(大约1G左右),因为它附带了 Python 中最常用的数据科学包。如果计算机上已经安装了 Python,再安装时不会有任何影响。实际上,脚本和程序使用的默认 Python 是 Anaconda 附带的 Python,所以安装完 Anaconda 已经自带安装好了 Python,无需另外安装 (如果你的项目和学习需要使用到多个不同版本的 Python,建议直接安装 Anaconda)。
2.1 从百度网盘链接中获取Anaconda安装包
链接:https://pan.baidu.com/s/1Uk-uk2C4l3o-oyvQFPhE_g
提取码:610d
--来自百度网盘超级会员V9的分享
2.2 从官网下载Anaconda安装包
下面介绍如何下载 Anaconda,具体步骤如下:
- 首先查看计算机操作系统的位数,以决定下载哪个版本(现在都会自动检测系统,直接下载即可)。
- 下载 Anaconda。进入官网 https://www.anaconda.com/,单击右上角的
Free Download按钮,如下图所示:

- 向下拉动少许浏览器的滚动条,鼠标单击 Download 按钮,如下图所示:

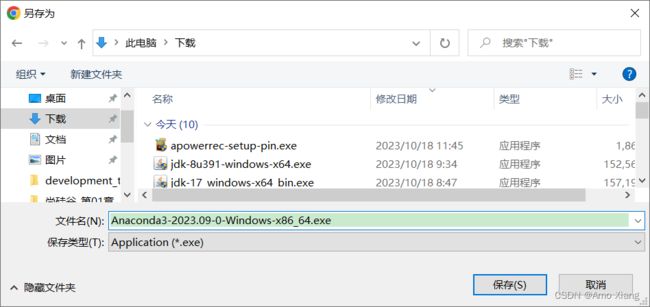
- 单击 Download 按钮之后,弹出
另存为对话框,选择你要存储安装包的位置(我这里默认保存到下载文件夹中),如下图所示:
- 鼠标单击保存按钮,开始下载 Anaconda,此时会弹出窗口,如下图所示:

耐心等待片刻,下载完成之后,保存安装包的路径下多出一个Anaconda3-2023.09-0-Windows-x86_64.exe文件,如下图所示:

三、安装Anaconda
下载完成后,开始安装 Anaconda,具体步骤如下:
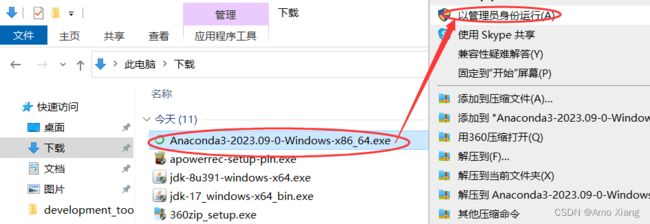
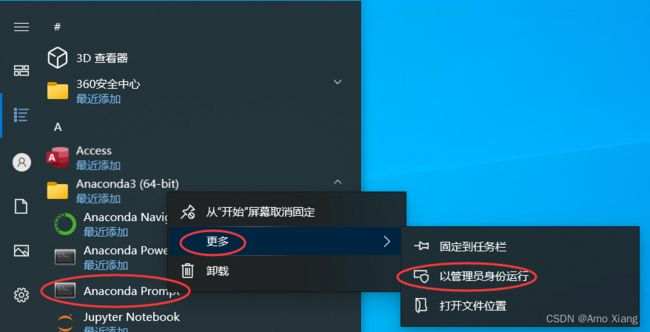
(1) 如果是 Windows 10 的操作系统,注意在安装 Anaconda 软件的时候,单击鼠标右键 以管理员的身份运行,如下图所示:
(2) 加载进度,加载完成之后,会进入到 Anaconda 欢迎界面,直接单击 Next 按钮即可,如下图所示:


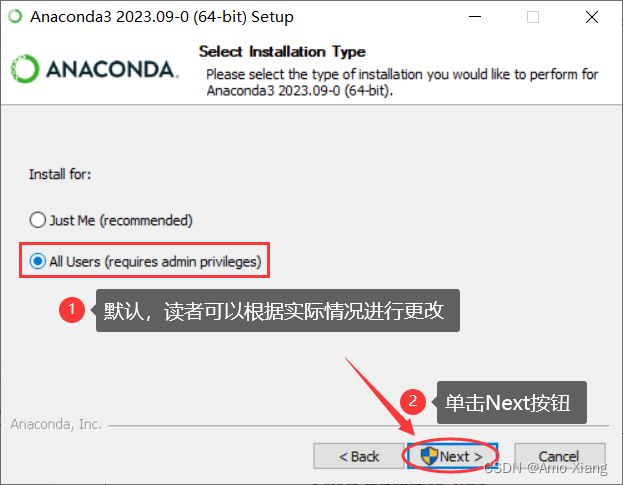
(3) 单击 I Agree 接受用户许可协议,接着选择安装类型是当前用户使用还是系统全部用户都可以使用。第二种情况需要具有 Windows 系统管理员权限。如下图所示,然后单击 Next 按钮。

(4) 安装路径选择默认路径即可(新手不建议更改安装路径),如下图所示:
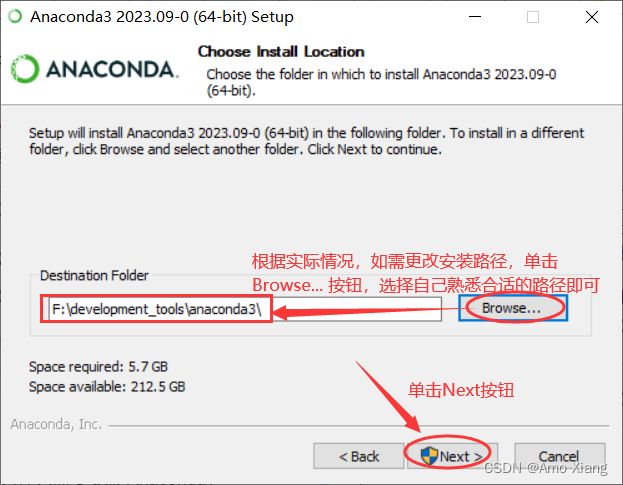
(5) 去掉复选框,选择是否把 Anaconda 注册为系统默认的 Python 环境,在学习和工作中我们可能在系统里面需要安装多个不同版本的 Anaconda 或 Python,此时使用 Anaconda 的命令创建不同的 Python 环境即可(更加灵活),因为默认注册的 Python 环境可能不符合我们的使用要求。单击 Install 按钮,开始安装 Anaconda。如下图所示:


当完成安装后,一直 Next 即可,如下图所示:
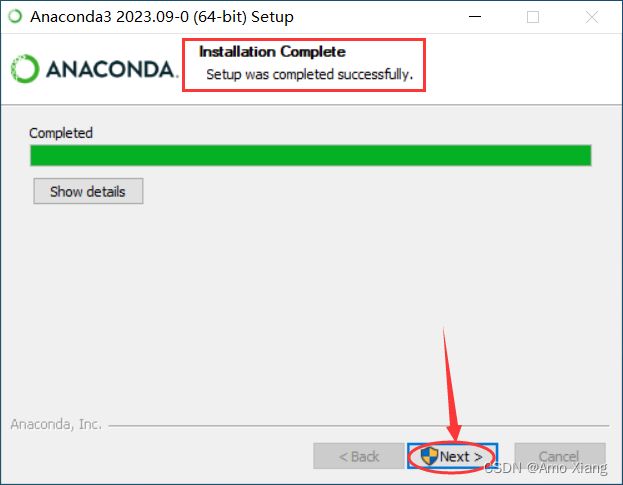

(6) 直接单击 Finish 按钮完成 Anaconda 安装,如下图所示:

安装完成后,系统开始菜单会显示增加的程序,如下图所示,这时就表示 Anaconda 已经安装成功了。
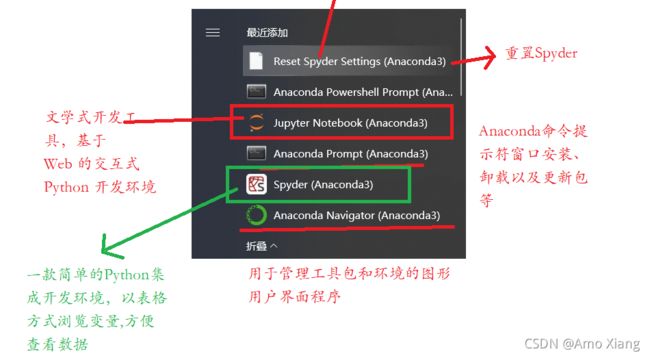
四、Anaconda的使用
4.1 利用 Conda 管理 Python 环境
Conda 是 Anaconda 提供的包及其依赖项和环境的管理工具,利用它可以:快速安装、运行和升级包及其依赖项;在计算机中便捷地创建、保存、加载和切换环境。有了 Anaconda 就可以利用它提供的 Conda 命令来管理环境,从而解决前面提到的 Python 版本问题和各种数据分析中用到的包管理问题。要使用 Conda,首先需要在系统菜单中单击 Anaconda Prompt 进入命令行模式,如下图所示(对 Linux/Mac OS,Conda 命令可以直接在命令行运行)。需要注意的是,这里是以管理员身份运行的 Anaconda Prompt。
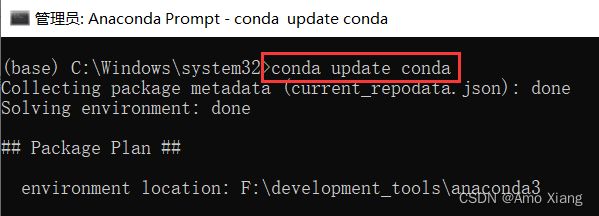
进入 Anaconda 命令行模式后的第一件事就是更新 Anaconda,在命令行输入:
conda update conda
并在提示是否更新的时候输入 y(Yes) 让更新继续。如下图所示:
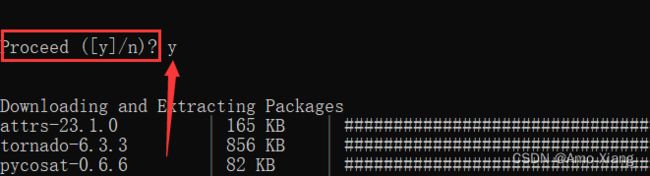
更新完成之后如下图所示:

1、创建环境。 完成了 Conda 更新,接下来就可以创建一个新的环境了,默认打开 Anaconda 命令行的时候进入的是系统的 base 环境,通常开发中会创建不同的环境以满足不同应用对各种 Python 版本以及第三方包的要求。要创建一个新的环境,可以在命令行输入:
conda create -n env_name package_names
上面的命令中,env_name 是设置环境的名称(-n 指该命令后面的 env_name 是要创建环境的名称),package_names 是要安装在所创建环境中的包名称,同时还可以指定版本。例如,要创建名为 test_py 的环境,并在其中安装最新的 Python 版本,可以在终端中输入:
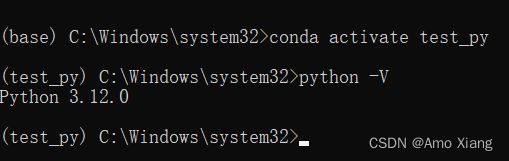
conda create -n test_py python=3
此时 Conda 将创建一个全新的环境,环境名为 test_py,使用的 Python 版本为 3,由于没有指定小版本号,此时系统将选择安装最新的 Python 3 版本,本文测试时最新版本是 3.12.0,如下图所示:
同样地,如果想创建一个环境,使用 Python 3.7,同时安装 Pandas 0.24.0 版本,以及 NumPy 包,可以通过如下命令完成:
conda create -n py37 python=3.7 numpy pandas=0.24.0
如果想在创建环境同时安装其他的包,只需要在创建环境时添加对应的包就可以了。
2、切换环境。 在 Windows 上,可以使用 conda activate my_env 进入对应的环境;而在 OS X/Linux 上则使用 source activate my_env 进入环境。进入环境后,用户会在终端提示符中看到环境名称。下图为进入前面创建的 py37 环境:

进入环境后可以通过命令 conda list 来列出当前环境已经安装的包,以及对应版本,如图所示:
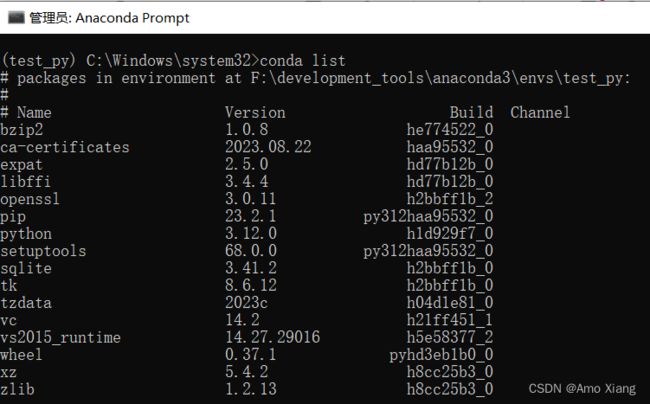
还可以用下面的命令来检查当前环境的 Python 版本:
python --version/python -V
这里要特别强调的是不同的环境类似于在系统里面建立了隔离沙箱,相互之间不影响,这样开发人员就可以通过切换不同环境满足不同的开发需求。
3、离开环境。 要离开当前环境,在命令行输入:
conda deactivate
4、环境共享。 环境共享是非常实用的功能,它能保证让整个项目的协作人员都使用相同的软件包,并确保这些包的版本正确。例如,当前数据分析员 Amo 正在进行网络促销数据分析,他需要提交应用给另一部门的 Jerry 来部署项目,但是 Jerry 并不知道数据分析时使用的是哪个 Python 版本,以及使用了哪些包和包的版本。这时应该怎么办呢?Amo 就可以在当前的环境终端输入:
conda env export > environment.yaml
将当前的环境的配置(包括 Python 版本和所有包的名称) 保存到一个 YAML 文件中。命令的第一部分 conda env export 用于输出环境中所有包的名称(包括 Python 版本),第二部分是对应的文件名。那么 Jerry 拿到了导出的环境文件,在其他电脑环境中如何使用呢?首先在 Conda 中进入当前的环境,如:
conda activate py37
然后再使用以下命令更新环境。
conda env update -f=/path/to/environment.yml
其中,-f 表示要使用的环境文件在本地的路径,读者将 /path/to/environment.yml 替换成本地的实际路径即可。
5、列出环境。 有时我们可能会忘记自己创建的环境名称,这时就可以用 conda env list 命令来列出本地创建的所有环境。用户会看到本地所有环境的列表,而当前所在环境的旁边会有一个星号,Anaconda 命令行默认的环境(即还没有选定环境时使用的环境)名为 base,如下图所示:

6、删除环境。 如果不再使用某个环境,可以使用以下命令删除指定的环境,这里的 env_name 为想删除的本地环境名。
conda env remove -n env_name
7、查看环境信息。 如果想了解当前环境,可以使用以下命令。
conda info
此命令会列出该环境的所有信息,如下图所示:

4.2 利用 Conda 管理 Python 包
创建好对应的工作环境后,通常还需要对环境中的包进行管理。利用 Conda 命令可以实现各种包的安装、升级以及卸载。
1、安装包。 例如,想安装 requests 这个包,进入创建好的 py37 环境后,在命令行模式下输入:
conda search requests
将在 Anaconda 提供的库(repository)里面搜索这个包是否存在,以及有哪些版本。之后可以利用如下命令来完成该包的安装。
conda install requests
在安装时用户也可以指定对应的 requests 版本。此外,如果在 Anaconda 提供的库里面找不到想安装的包,或者想安装更新的版本,那么也可以通过社区维护的 conda-forge 来安装。例如,如果想使用 conda-forge 来安装 Pandas,可以使用如下命令。
conda install -c conda-forge pandas
如果在上面的库都无法找到想安装的包,也可以用标准的 Python 包管理命令 pip 来完成在当前环境中第三方包的安装。例如,用来获取国内财经以及股票数据的 tushare 包,就可以通过在当前环境下使用如下命令来完成安装:
pip install tushare
2、包的卸载与升级。 包的卸载可以通过如下命令完成。
conda uninstall packages_name
这里的 packages_name 就是当前环境中要删除的包。如果想在当前环境中删除另一个环境中的包,可以通过如下命令完成。
conda uninstall my_env packages_name
这里的 my_env 就是对应的环境名。同时,对于任何 conda 命令都可以通过获取帮助的方式来详细了解命令的使用方法,如:
conda uninstall --help
conda install --help
如果想对已经安装的包进行升级,则可以输入:
conda update my_env packages_name
如果是对当前环境中包升级,则可以略去环境名。如果想对所有包升级,则可以输入:
conda update --all
3、为 Anaconda 添加新的库。 有时在国内使用 Anaconda 提供的库来安装包会比较缓慢,这时可以考虑添加国内镜像来解决这个问题。例如,通过如下命令可以使用中国科学技术大学的镜像。
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --show-sources
conda config --set show_channel_urls yes
上面的第二个命令是显示当前有哪些镜像地址。可以通过如下命令来将刚才添加的镜像地址移除,用 conda config --show 来确认该地址已经移除。
conda config --remove channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --show
4.3 文学式开发工具 Jupyter Notebook
为什么说 Jupyter Notebook 是文学式开发工具?因为 Jupyter Notebook 将代码、说明文本、数学方程式、数据可视化图表内容全部组合到一起并显示在一个共享的文档中,可以实现一边写代码一边记录的效果,而这些功能则是 Python 自带的 IDLE 和集成开发环境 PyCharm 无法比拟的。Jupyter Notebook 是一个在线编辑器、Web 应用程序,它可以在线编写代码,并创建和共享文档,并支持实时编写代码、数学方程式、说明文本和可视化数据分析图表等。Jupyter Notebook 的用途包括数据清理、数据转换、数值模拟、统计建模、机器学习等。目前,数据挖掘领域中最热门的比赛 Kaggle(它是举办机器学习竞赛、托管数据库、编写和分享代码的平台)里的资料都是 Jupyter 格式。对于机器学习新手来说,学会使用 Jupyter Notebook 非常重要。
在 py37 环境中已经安装了 Jupyter Notebook,要运行它,只需在进入 Anaconda 命令行模式后,输入:
conda activate py37
conda install scipy numpy statsmodels pandas scikit-learn matplotlib seaborn ipython jupyter
jupyter notebook
我们将看到下图所示的提示,此时只需要按照提示把箭头所指的那一行复制到浏览器,就可以看到 Jupyter Notebook 的启动页面:

每次都复制一遍会比较麻烦,所以我们通常会修改配置,采用密码方式启动 Jupyter Notebook,同时也会修改 Jupyter Notebook 从工作目录启动,具体方法如下:
1、生成一个 Notebook 配置文件。 默认情况下,配置文件 jupyter_notebook_config.py 是不存在的,使用如下命令生成配置文件。
jupyter notebook --generate-config
该命令将在当前计算机中生成一个新的配置文件,对于 Windows 用户,通常它位于 C:\Users\Administrator(电脑的用户名)\.jupyter (我电脑的用户名为 AmoXiang,所以此处 Administrator 替换为对应的用户名 AmoXiang);对于 Linux 用户,通常它位于 ~/.jupyter/jupyter_notebook_config.py(如果是以 Root 用户运行命令,需要使用 jupyter notebook --generate-config --allow-root)。

2、生成密码。 从 Jupyter Notebook 5.0 版本开始,Jupyter Notebook 提供了一个命令来设置密码,在 Anaconda 命令行模式输入:
jupyter notebook password
根据提示输入你的密码,假设这里输入的密码为 amoxiang,之后生成的密码存储在文件 jupyter_notebook_config.json 中,通常该文件和前面生成的配置文件位于同一目录。

打开该文件,可以发现文件中 password 后面有一段密码,例如笔者的 jupyter_notebook_config.json 文件内容为:
{
"NotebookApp": {
"password": "argon2:$argon2id$v=19$m=10240,t=10,p=8$BYR22mrXeEpaldf9YsVqIQ$KEvoMUDybnQoGYeFRvEQrHZMT4tTg8WCzgDh13y8o/Y"
}
}
3、修改配置文件。 在 jupyter_notebook_config.py 中找到 c.NotebookApp.password 所在行,取消注释,并将前面提到的密码复制到后面,代码如下:
![]()
此外还可通过修改 c.NotebookApp.port 来自行指定 Notebook 运行的端口。
4、修改 Notebook 启动时的工作目录。 在 jupyter_notebook_config.py 中找到下面的行:
## The directory to use for notebooks and kernels.
#c.NotebookApp.notebook_dir= ''
取消 c.NotebookApp.notebook_dir 行的注释,并将目录修改为想要的目录,例如笔者平时测试学习使用的目录为 D:\Code\DataAnalysis,那么需要将该行修改为:
c.NotebookApp.notebook_dir = 'D:\\Code\\DataAnalysis'
需要说明的是,在 Windows 系统下,由于转义符的原因需要使用 \\,对于 Linux 是不需要这样做的。现在我们已经为 Jupyter Notebook 设置了密码,并配置了默认的启动目录,再次在 Anaconda 命令行模式输入:
jupyter notebook
将看到浏览器启动,并提示输入密码,此时输入前面设置的密码 amoxiang 进入 Jupyter Notebook 界面,如下图所示:

由于当前工作目录 D:\Code\DataAnalysis 下面没有任何文件,所以没有任何 Notebook 显示出来。此时可以通过单击右侧 New 菜单,选择 Python 3 来创建新的 Notebook。细心的读者可能会发现,前面不是创建了一个 py37 的环境吗?为什么这里没有提供用该环境来创建 Notebook 的选项?要使 Jupyter Notebook 支持虚拟环境,还需要安装一个新的包:nb_conda。首先回到命令行窗口,连续按两次 Ctrl+C 组合键来退出 Jupyter Notebook,然后输入:
conda install nb_conda
完成 nb_conda 包的安装后,再次启动 Jupyter Notebook,在右侧菜单选择 New,就可以看到下图所示的界面:

下拉菜单中出现了之前创建的 py37 环境选项以及 Anaconda 安装时默认创建的环境选项。切换窗口回到 Anaconda 命令提示窗口,可以看到 Jupyter 启动时也确实使用的是前面设置的目录 D:\Code\DataAnalysis,如下图所示:

4.4 Jupyter Notebook 中的单元格
首先进入 py37 环境运行命令 jupyter notebook,单击右侧菜单 New,选择使用 py37 环境创建新的 Notebook,此时浏览器将在新的标签页中创建一个 Notebook。该 Notebook 的文件名为 Untitled,可以单击 Notebook 中的 Untitled 对文件名进行修改,如下图所示:
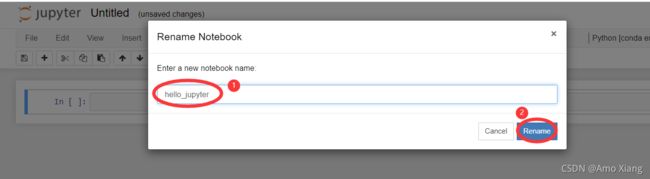
单击 Rename 按钮确认修改,就可以开始编辑这个名为 hello_jupyter 的文件了,如下图所示:
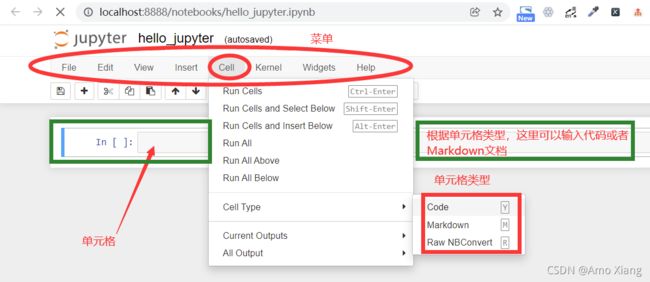
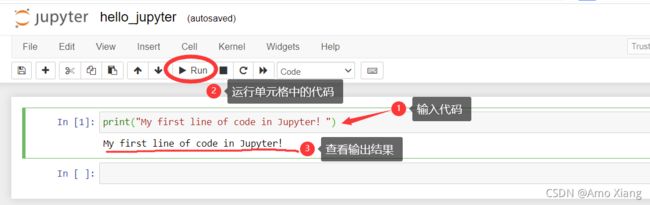
以看到最顶部是对应的 Notebook 的名称,接下来是菜单栏/工具栏,读者可以通过菜单栏/工具栏执行选择不同操作。接下来就是 Notebook 中最重要的部分——单元格(Cell),单元格可分为 3 种不同类型:Code、Markdown 和 Raw NBConvert,这里需要重点掌握前面两种。如果一个单元格为 Code类型,那么这意味着在这个单元格中可以输入一行或多行的 Python 代码,同时可以运行该代码。如下图所示,笔者在 Code 单元格中输入了一行代码,然后单击工具栏中的 运行 按钮,Notebook 中将打印输出:My first line of code in Jupyter!
而如果单元格类型为 Markdown,那么输入的就是 Markdown 格式的文档, Notebook 将按照 Markdown 文档的规范显示该段文档。例如,在新的单元格中输入如下内容:
# 数据分析的标准环境 Anaconda
## 为什么选择Python?
### 人生苦短,我用Python
选择运行单元格,将看到下图所示的内容:

关于 Markdown 语法更详细的说明可以参考网站:https://markdown-zh.readthedocs.io/en/latest/。另一种运行的方式:按下 Shfit+Enter 组合键运行该单元格,并自动在当前单元格下方创建一个新代码单元格(如果按 Ctrl+Enter 组合键将只运行单元格,不创建新单元格)。
4.5 Jupyter Notebook 中的命令模式与编辑模式键
Jupyter Notebook 有两种模式:编辑模式与命令模式。编辑模式下可以输入代码或文档,而命令模式下可以执行 Jupyter Notebook 命令。在编辑和命令模式之间切换,分别使用 Esc 键和 Enter 键。无论当前为何种模式,按下 Esc 键就可以进入命令模式,此时:
1. 按 Up 和 Down 键可以向上和向下移动单元格;
2. 按 A 键在活动单元格上方插入一个新单元格;
3. 按 B 键在活动单元格下方插入一个新单元格;
4. 按 M 键将活动单元格转换为Markdown单元格;
5. 按 Y 键将激活的单元格设置为一个代码单元格;
6. D+D(按两次 D 键) 将删除活动单元格;
7. 按 Z 键将撤销单元格删除;
8. 按住 Shift 键,同时按 Up 或 Down 键,一次选择多个单元格;
更多的快捷键命令可以通过在命令模式下按 H 键来获得帮助,即首先按 Esc 键,然后按 H 键,此时将看到 Jupyter 帮助页面,如下图所示:
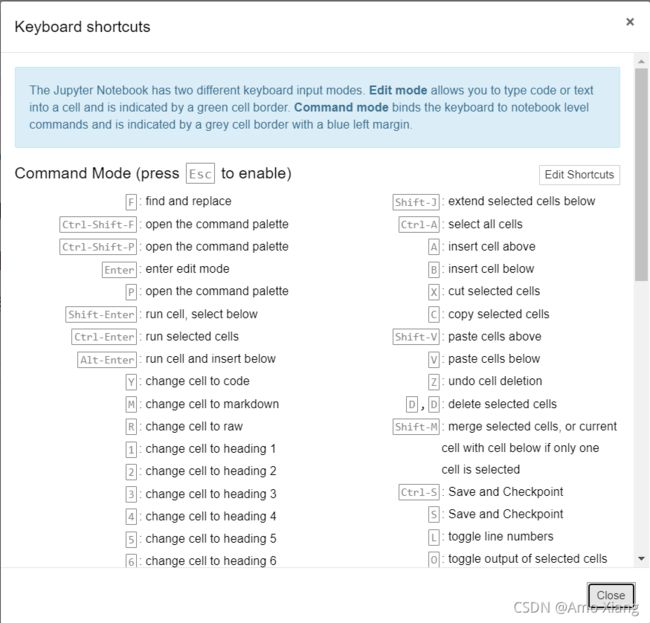
保存 Jupyter Notebook 文件。最后一步为保存 Jupyter Notebook 文件,也就是保存程序。常用格式有以下两种:一种是 Jupyter Notebook 的专属格式;另一种是 Python 文件。Jupyter Notebook 的专属格式:单击 File 菜单,选择 Save and Checkpoint 菜单项,将 Jupyter Notebook 文件保存在默认路径下,文件格式默认为 ipynb。Python 格式:它是我们常用的文件格式。单击 File 菜单,选择 Download as 菜单项,弹出的子菜单中选择 Python(.py) 子菜单项,如下图所示:

4.6 科学计算工具 IPython
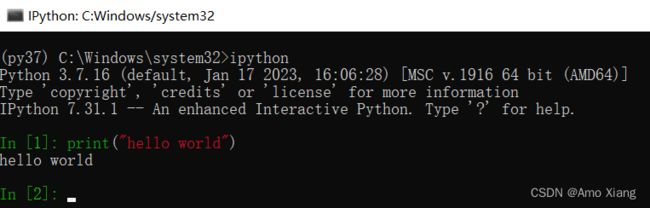
IPython 是公认的现代科学计算中最重要的 Python 工具之一,它是一个加强版的 Python 交互式命令行工具,与系统自带的 Python 交互环境相比,IPython 主要具有以下特点:与 Shell 紧密关联,可以在 IPython 开发环境下直接执行 Shell 指令。它是可以直接进行绘图操作的 Web GUI 环境,在机器学习领域、探索数据模式、可视化数据、绘制学习曲线时,功能都非常强大。更强大的交互功能,包括内省、Tab 键自动完成、魔术命令等。在前面已经安装了 ipython 这里我就不再进行赘述。进入 py37 环境,输入命令:ipython,然后在命令提示符下输入代码 print("Hello World"),按
在 shell 中输入表达式时,只要按下 Tab 键,与当前输入内容相匹配的方法、函数、对象等就会被找出来。例如,通过 Pandas 模块获取 Excel 数据时,读者突然忘记用哪个方法了,此时按下

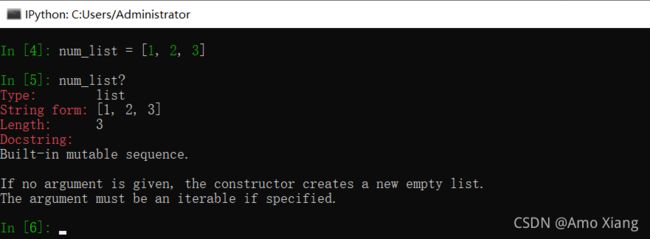
在变量的前面或者后面加上一个问号 ?,就可以将有关该对象的一些通用信息显示出来,这就叫作对象的内省。例如,创建一个列表 num_list,然后输入 num_list?,将输出列表 num_list 的相关信息,如类型、列表元素和长度等,如图所示:
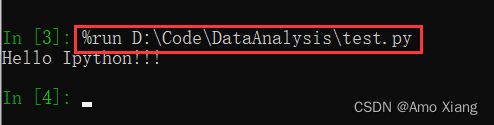
那么,如果使用两个问号 ??, 则显示该方法的源代码。另外,还可以使用通配符字符串查找所有与该通配符字符串相匹配的名称。IPython 常用的魔法命令如下:%run:运行外部 Python 文件。在 IPython 环境中,所有文件都可以通过 %run 命令当作 Python 程序来运行,输入 %run *.py 即可(默认是当前目录)。例如,运行 test.py 文件,效果下图所示:
%hist:历史命令。简单地使用上、下翻页键就可以查看所有的历史输入。%timeit:用于快速测试代码的运行时间。%debug:用于在程序异常点启动调试器,也可以使用 %pdb 命令激活 IPython 调试器。这样,每当异常抛出时,调试器就会自动运行。%pylab:魔法命令。它可以使得 Numpy 和 Matplotlib 中的科学计算功能生效,这些功能被称为基于向量和矩阵的高效操作,具有交互可视化的特性。它能够让我们在控制台进行交互式计算和动态绘图。%paste:用于直接粘贴一段代码,前提是先复制一段代码。%paste 的执行顺序是:先将代码打印出来,然后再执行该段代码。%lsmagic:用于获取更多的魔法命令。
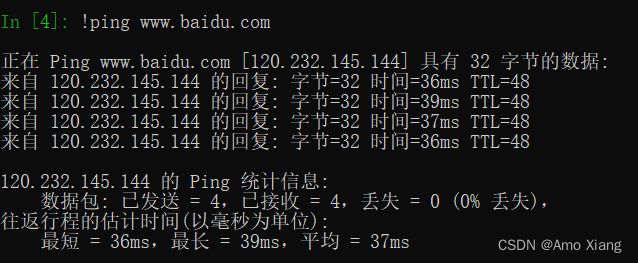
在 IPython 环境中可以直接执行 Shell 命令,在 Shell 命令前加上叹号 ! 即可。例如,测试百度网络连接(ping 百度,即 !ping baidu.com),效果如下图所示: